La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
Dans les activités quotidiennes, les mouvements des personnes provoquent souvent un mouvement secondaire des vêtements et produisent ainsi différents plis de vêtements, ce qui nécessite une compréhension de la géométrie et du mouvement du corps humain et des vêtements (posture humaine et dynamique de vitesse, etc. .) et l'apparence sont modélisées dynamiquement simultanément. Étant donné que ce processus implique des interactions physiques complexes et non rigides entre les personnes et les vêtements, la représentation tridimensionnelle traditionnelle est souvent difficile à gérer. L'apprentissage du rendu humain numérique dynamique à partir de séquences vidéo a fait de grands progrès ces dernières années. Les méthodes existantes considèrent souvent le rendu comme une cartographie neuronale de la posture humaine à l'image, en utilisant le paradigme « encodeur de mouvement-caractéristiques de mouvement-apparence » décodeur. Ce paradigme est basé sur la perte d'image pour la supervision. Il se concentre trop sur la reconstruction de chaque image et manque de modélisation de la continuité du mouvement. Il est donc difficile de modéliser efficacement des mouvements complexes tels que « le mouvement du corps humain et celui lié aux vêtements ». ". Pour résoudre ce problème, l'équipe S-Lab de l'Université technologique de Nanyang à Singapour a proposé un nouveau paradigme de reconstruction dynamique du corps humain avec apprentissage conjoint mouvement-apparence, et a proposé une représentation du mouvement à trois plans basée sur le surface du corps humain (triplan basé sur la surface), qui unifie la modélisation de la physique du mouvement et la modélisation de l'apparence dans un seul cadre, ouvrant ainsi la voie à de nouvelles idées pour améliorer la qualité du rendu dynamique du corps humain. Ce nouveau paradigme modélise efficacement le mouvement attaché aux vêtements et peut être utilisé pour apprendre la reconstruction dynamique du corps humain à partir de vidéos en mouvement rapide (comme la danse) et restituer les ombres liées au mouvement. L'efficacité du rendu est 9 fois plus rapide que la méthode de rendu voxel 3D et la qualité de l'image LPIPS est améliorée d'environ 19 points de pourcentage.
- Titre de l'article : SurMo : Modélisation de mouvements 4D basée sur une surface pour le rendu humain dynamique
- Adresse de l'article : https://arxiv.org/pdf/2404.01225.pdf
- Page d'accueil du projet : https ://taohuumd.github.io/projects/SurMo
- Lien Github : https://github.com/TaoHuUMD/SurMo
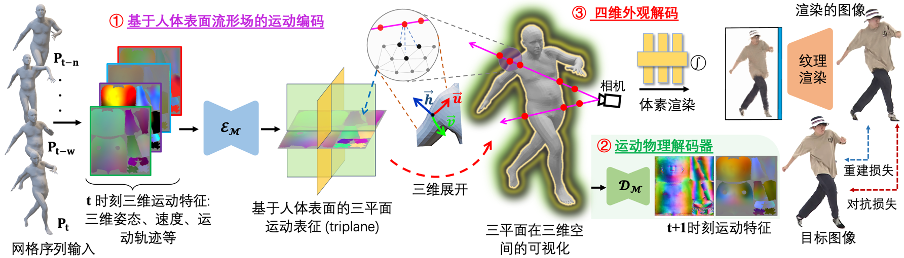
Visant aux lacunes du paradigme existant "Motion Encoder-Motion Features-Appearance Decoder" qui se concentre uniquement sur la reconstruction de l'apparence et ignore la modélisation de la continuité du mouvement, un nouveau paradigme SurMo est proposé : "①Motion Encoder-Motion Features-②Motion Decoder, ③ apparence décodeur". Comme le montre la figure ci-dessus, le paradigme est divisé en trois étapes :
- Différent des méthodes existantes qui modélisent le mouvement dans un espace tridimensionnel clairsemé, SurMo propose basé sur le champ multiple de la surface humaine (ou compact espace UV texturé bidimensionnel) modélisation du mouvement en quatre dimensions (XYZ-T), et représente le mouvement à travers un à trois plans (triplan basé sur la surface) défini sur la surface du corps humain.
- Proposer un décodeur physique du mouvement pour prédire l'état de mouvement de l'image suivante en fonction des caractéristiques du mouvement actuel (telles que la posture tridimensionnelle, la vitesse, la trajectoire du mouvement, etc.), telles que la déviation spatiale du mouvement – surface vecteur normal et déviation temporelle - vitesse, pour modéliser la continuité des caractéristiques de mouvement.
- Décodage d'apparence en quatre dimensions, décodage temporel des caractéristiques de mouvement pour restituer une vidéo tridimensionnelle à point de vue libre, principalement mis en œuvre via un rendu neuronal hybride à texture de voxel (Hybrid Volumetric-Textural Rendering, HVTR [Hu et al. 2022]) .
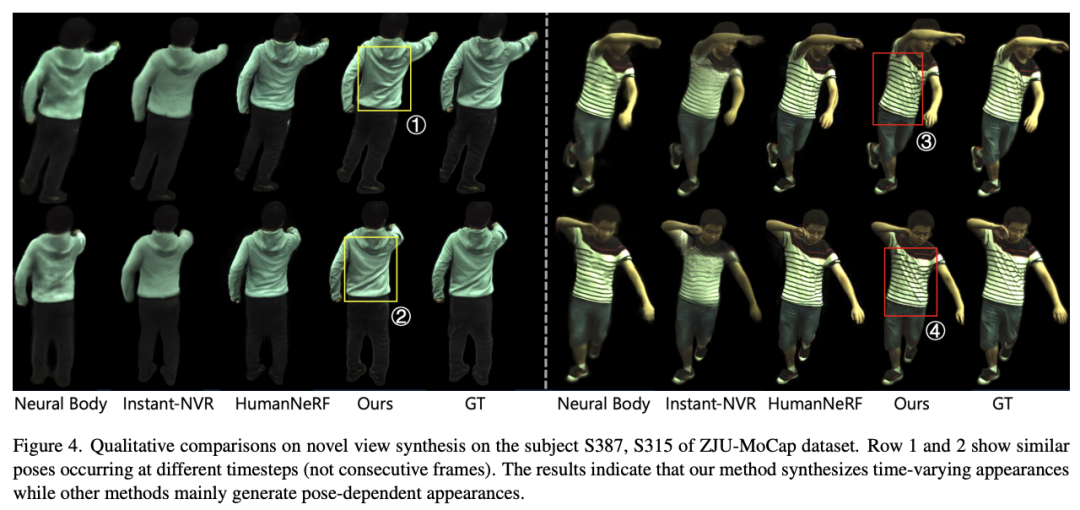
SurMo peut apprendre le rendu humain dynamique à partir de vidéos basées sur la perte de reconstruction et la formation de bout en bout sur les pertes contradictoires. Cette étude a mené des évaluations expérimentales sur 3 ensembles de données avec un total de 9 séquences vidéo humaines dynamiques : ZJU-MoCap [Peng et al. 2021], AIST++ [Li, Yang et al. .Nouveau rendu temporel du point de vueCette étude explore les performances du nouveau point de vue sur l'ensemble de données ZJU-MoCap. L'effet d'une séquence temporelle (apparitions variables dans le temps), notamment de 2 séquences, est étudié, comme le montre la figure ci-dessous. Chaque séquence contient des gestes similaires mais apparaissent dans des trajectoires de mouvement différentes, telles que ①②, ③④, ⑤⑥. SurMo peut modéliser des trajectoires de mouvement et donc générer des effets dynamiques qui évoluent dans le temps, tandis que les méthodes associées génèrent des résultats qui dépendent uniquement de la posture, les plis des vêtements étant presque les mêmes selon les différentes trajectoires.
Rendu des ombres liées au mouvement et des mouvements affiliés aux vêtements
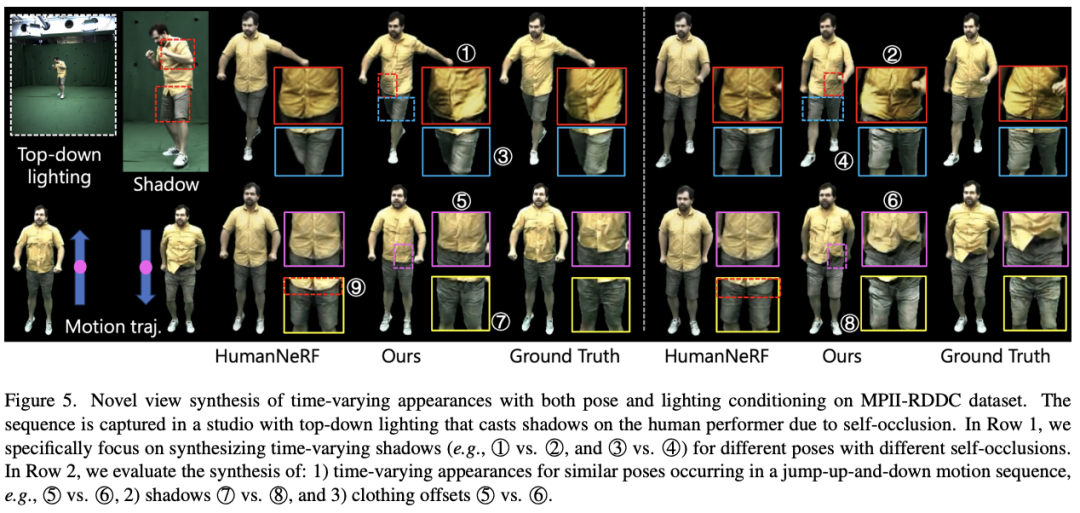
SurMo a exploré les ombres liées au mouvement et les mouvements affiliés aux vêtements sur l'ensemble de données MPII-RRDC, comme le montre la figure ci-dessous. La séquence a été tournée sur une scène sonore intérieure et les conditions d'éclairage ont produit des ombres liées au mouvement sur les artistes en raison de problèmes d'auto-occlusion. SurMo peut restaurer ces ombres, telles que ①②, ③④, ⑦⑧ sous un nouveau rendu de point de vue. La méthode de contraste HumanNeRF [Weng et al.] est incapable de récupérer les ombres liées au mouvement. De plus, SurMo peut reconstruire le mouvement des accessoires vestimentaires qui change avec la trajectoire du mouvement, comme différents plis lors des mouvements de saut ⑤⑥, tandis que HumanNeRF ne peut pas reconstruire cet effet dynamique.
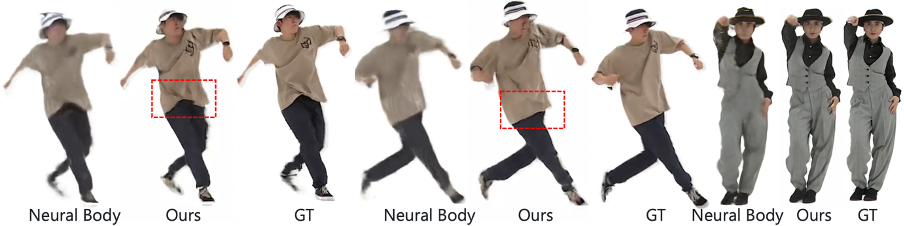
Rendu de corps humains en mouvement rapide SurMo restitue également les corps humains à partir de vidéos en mouvement rapide et récupère les détails des plis de vêtements liés au mouvement que les méthodes contrastées ne peuvent pas restituer.
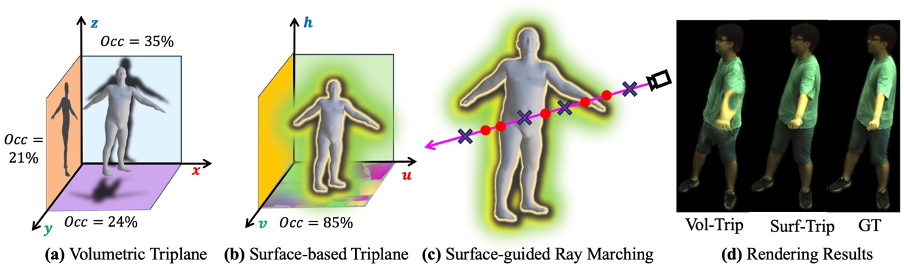
(1) Modélisation du mouvement de la surface humaineCette étude a comparé deux méthodes de modélisation de mouvement différentes : la modélisation de mouvement actuellement couramment utilisée dans l'espace voxel (espace volumétrique). , ainsi que la modélisation du mouvement du champ collecteur de surface humaine (Surface manifold) proposée par SurMo, comparant spécifiquement le triplan volumétrique et le triplan basé sur la surface, comme le montre la figure ci-dessous.
On peut constater que le triplan volumétrique est une expression clairsemée, avec seulement environ 21 à 35 % des fonctionnalités utilisées pour le rendu, tandis que l'utilisation des fonctionnalités du triplan basé sur la surface peut atteindre 85 %, il présente donc plus d'avantages dans la gestion de l'auto-occlusion, comme comme ( d) montré. Dans le même temps, le triplan basé sur surface peut obtenir un rendu plus rapide en filtrant les points éloignés de la surface dans le rendu voxel, comme le montre la figure (c).
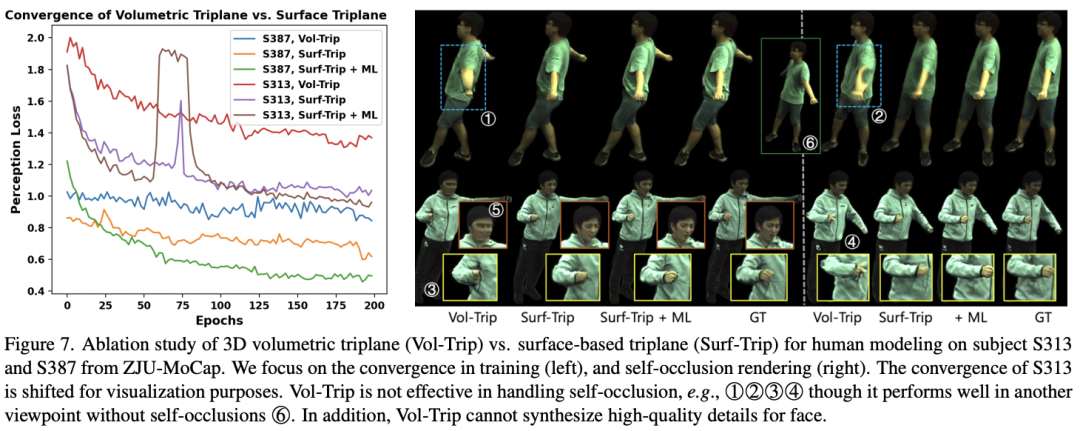
Dans le même temps, cette étude démontre que le triplan basé sur la surface peut converger plus rapidement que le triplan volumétrique pendant le processus d'entraînement et présente des avantages évidents en termes de détails de pliage des vêtements et d'auto-occlusion, comme le montre la figure ci-dessus. (2) Apprentissage dynamique SurMo a étudié l'effet de la modélisation du mouvement à travers des expériences d'ablation, comme le montre la figure ci-dessous. Les résultats montrent que SurMo peut découpler les caractéristiques statiques du mouvement (telles que la posture fixe à un certain cadre) et les caractéristiques dynamiques (telles que la vitesse). Par exemple, lorsque la vitesse change, les plis des vêtements près du corps restent inchangés, comme ①, tandis que les plis des vêtements amples sont fortement affectés par la vitesse, comme ②, ce qui est cohérent avec les observations quotidiennes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!