
Maison >Périphériques technologiques >IA >Comment utiliser le transformateur pour corréler efficacement les caractéristiques visuelles du radar à ondes lidar-millimétriques ?
Comment utiliser le transformateur pour corréler efficacement les caractéristiques visuelles du radar à ondes lidar-millimétriques ?

- PHPzavant
- 2024-04-19 16:01:24554parcourir
L'auteur comprend personnellement
L'une des tâches fondamentales de la conduite autonome est la détection de cibles tridimensionnelles, et de nombreuses méthodes sont désormais mises en œuvre sur la base de méthodes de fusion multi-capteurs. Alors pourquoi la fusion multicapteurs est-elle nécessaire ? Qu'il s'agisse de fusion lidar et caméra, ou de fusion radar à ondes millimétriques et caméra, l'objectif principal est d'utiliser la connexion complémentaire entre les nuages de points et les images pour améliorer la précision de la détection des cibles. Avec l'application continue de l'architecture Transformer dans le domaine de la vision par ordinateur, les méthodes basées sur les mécanismes d'attention ont amélioré la précision de la fusion entre plusieurs capteurs. Les deux articles partagés sont basés sur cette architecture et proposent de nouvelles méthodes de fusion pour mieux utiliser les informations utiles de leurs modalités respectives et réaliser une meilleure fusion.
TransFusion :
Contribution principale
Le lidar et la caméra sont deux capteurs de détection de cible tridimensionnelle importants dans la conduite autonome. Cependant, dans la fusion de capteurs, ils sont principalement confrontés au problème d'une faible précision de détection causée par une mauvaise bande d'image. conditions. . La méthode de fusion basée sur des points consiste à fusionner le lidar et les caméras via une association dure, ce qui entraînera certains problèmes : a) le simple épissage du nuage de points et des caractéristiques de l'image, en présence de caractéristiques d'image de faible qualité, les performances de détection seront sérieusement dégradées. ;b) La recherche de corrélations strictes entre des nuages de points clairsemés et des images gaspille des caractéristiques d'image de haute qualité et est difficile à aligner. Pour résoudre ce problème, une méthode d’association douce est proposée. Cette méthode traite le lidar et la caméra comme deux détecteurs indépendants, coopérant l'un avec l'autre et tirant pleinement parti des avantages des deux détecteurs. Tout d’abord, un détecteur d’objets traditionnel est utilisé pour détecter les objets et générer des cadres englobants, puis les cadres englobants et les nuages de points sont mis en correspondance pour obtenir un score pour lequel le cadre englobant auquel chaque point est associé. Enfin, les caractéristiques de l'image correspondant aux cases de bord sont fusionnées avec les caractéristiques générées par le nuage de points. Cette méthode peut efficacement éviter la baisse de la précision de détection causée par de mauvaises conditions de bande d'image. Dans le même temps, cet article présente TransFusion, un cadre de fusion pour le lidar et les caméras pour résoudre le problème de corrélation entre les deux capteurs. Les principales contributions sont les suivantes :
Proposer un modèle de fusion de détection 3D basé sur un transformateur du lidar et de la caméra, qui montre une excellente robustesse face à une mauvaise qualité d'image et au désalignement du capteur- Introduit plusieurs méthodes d'interrogation d'objets Ajustements simples mais efficaces pour améliorer ; la qualité des prédictions initiales du cadre de délimitation pour la fusion d'images et un module d'initialisation de requêtes guidées par image conçu pour gérer les objets difficiles à détecter dans les nuages de points
- implémente non seulement une détection 3D avancée dans les performances de nuScenes, mais a également étendu le modèle à ; tâches de suivi tridimensionnel et obtenu de bons résultats.
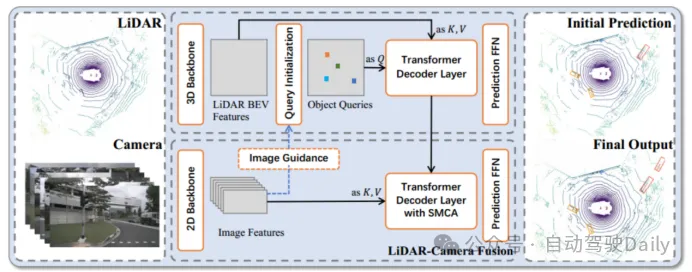 Figure 1 Le cadre global de TransFusion
Figure 1 Le cadre global de TransFusion
Afin de résoudre les problèmes de différence d'entrée d'image et de corrélation entre différents capteurs, un cadre de fusion basé sur un transformateur - TransFusion est proposé . Le modèle s'appuie sur des réseaux fédérateurs 3D et 2D standard pour extraire les caractéristiques LiDAR BEV et les caractéristiques d'image, puis se compose de deux couches de décodeurs Transformer : le décodeur de première couche utilise des nuages de points clairsemés pour générer des cadres de délimitation initiaux, le décodeur de deuxième couche convertit le premier ; couche La requête d'objet est combinée avec la requête de caractéristiques d'image pour obtenir de meilleurs résultats de détection. Le mécanisme d'attention à modulation spatiale (SMCA) et la stratégie de requête guidée par l'image sont également introduits pour améliorer la précision de la détection. Grâce à la détection de ce modèle, de meilleures caractéristiques d'image et une meilleure précision de détection peuvent être obtenues.
Initialisation de la requête
Si un objet ne contient qu'un petit nombre de points lidar, alors seul le même nombre de caractéristiques d'image peut être obtenu, gaspillant ainsi des informations sémantiques d'image de haute qualité . Par conséquent, cet article conserve toutes les caractéristiques de l'image et utilise le mécanisme d'attention croisée et la méthode adaptative de Transformer pour effectuer la fusion de caractéristiques, afin que le réseau puisse extraire de manière adaptative l'emplacement et les informations de l'image. Afin d'atténuer le problème de désalignement spatial des caractéristiques du LiDAR BEV et des caractéristiques d'image provenant de différents capteurs, un
Module d'attention croisée modulé spatialement (SMCA)est conçu, qui fait passer une gaussienne circulaire 2D autour du centre 2D de chaque projection de requête. les poids des masques attirent l’attention.
Initialisation de requête guidée par image (Initialisation de requête guidée par image)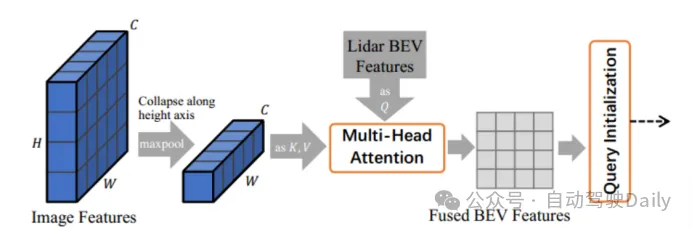 Figure 2 Module de requête guidée par image
Figure 2 Module de requête guidée par image
Ce module utilise simultanément les informations lidar et d'image comme requêtes d'objets, en envoyant des caractéristiques d'image et des caractéristiques lidar BEV dans le réseau de mécanismes d'attention croisée, en les projetant sur le plan BEV et en générant des caractéristiques BEV fusionnées. Comme le montre la figure 2, les caractéristiques de l'image multi-vues sont d'abord repliées le long de l'axe de la hauteur en tant que valeur clé du réseau de mécanismes d'attention croisée, et les caractéristiques lidar BEV sont envoyées au réseau d'attention sous forme de requêtes pour obtenir les caractéristiques BEV fusionnées. qui sont utilisés pour la prédiction de la carte thermique et moyennés avec la carte thermique lidar uniquement Ŝ pour obtenir la carte thermique finale Ŝ afin de sélectionner et d'initialiser la requête cible. De telles opérations permettent au modèle de détecter des cibles difficiles à détecter dans les nuages de points lidar.
Experiments
Datasets and Metrics
nuScenes est un ensemble de données de conduite autonome à grande échelle pour la détection et le suivi 3D, contenant 700, 150 et 150 scènes, utilisé pour la formation, la validation et les tests. Chaque image contient un nuage de points lidar et six images d'étalonnage couvrant un champ de vision horizontal de 360 degrés. Pour la détection 3D, les principales mesures sont la précision moyenne moyenne (mAP) et le score de détection nuScenes (NDS). mAP est défini par la distance centrale BEV plutôt que par l'IoU 3D, et le mAP final est calculé en faisant la moyenne des seuils de distance de 0,5 m, 1 m, 2 m, 4 m pour 10 catégories. NDS est une mesure complète de mAP et d'autres mesures d'attributs, notamment la translation, l'échelle, l'orientation, la vitesse et d'autres propriétés de boîte. .
L'ensemble de données Waymo comprend 798 scènes pour l'entraînement et 202 scènes pour la validation. Les indicateurs officiels sont mAP et mAPH (mAP pondéré par la précision du cap). mAP et mAPH sont définis sur la base de seuils 3D IoU, qui sont de 0,7 pour les véhicules et de 0,5 pour les piétons et les cyclistes. Ces métriques sont ensuite divisées en deux niveaux de difficulté : LEVEL1 pour les boîtes englobantes avec plus de 5 points lidar et LEVEL2 pour les boîtes englobantes avec au moins un point lidar. Contrairement aux caméras à 360 degrés de nuScenes, les caméras de Waymo ne couvrent qu'environ 250 degrés horizontalement.
Formation Sur l'ensemble de données nuScenes, utilisez DLA34 comme réseau fédérateur 2D de l'image et figez ses poids, définissez la taille de l'image sur 448 × 800 ; sélectionnez VoxelNet comme réseau fédérateur 3D du lidar. Le processus de formation est divisé en deux étapes : la première étape utilise uniquement les données LiDAR comme entrée et entraîne le squelette 3D 20 fois avec le décodeur de première couche et le réseau de rétroaction FFN pour générer des prédictions initiales du cadre de délimitation 3D ; la deuxième étape entraîne le LiDAR ; -Caméra Les modules de fusion et d'initialisation des requêtes guidées par image sont entraînés 6 fois. L'image de gauche est l'architecture de la couche de décodeur de transformateur utilisée pour la prédiction initiale de la boîte englobante ; l'image de droite est l'architecture de la couche de décodeur de transformateur utilisée pour la fusion LiDAR-Caméra.
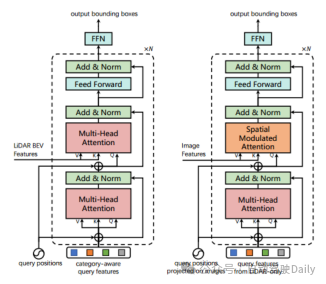
Figure 3 Conception de la couche de décodeur
Comparaison avec les méthodes de pointe
Comparez d'abord les performances de TransFusion et d'autres méthodes SOTA sur les tâches de détection d'objets 3D. Le tableau 1 ci-dessous montre les résultats dans le. Ensemble de test nuScenes, on peut voir que cette méthode a atteint les meilleures performances à l'époque (mAP est de 68,9 %, NDS est de 71,7 %). TransFusion-L utilise uniquement le lidar pour la détection, et ses performances de détection sont nettement meilleures que les méthodes de détection monomodales précédentes, et dépassent même certaines méthodes multimodales. Cela est principalement dû au nouveau mécanisme d'association et à la stratégie d'initialisation des requêtes. Le tableau 2 montre les résultats du mAPH NIVEAU 2 sur l'ensemble de validation Waymo.
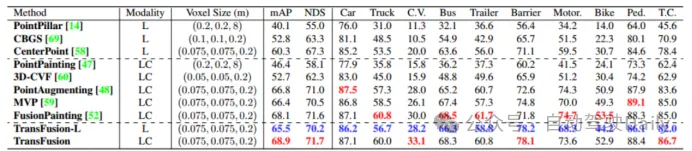
Tableau 1 Comparaison avec la méthode SOTA dans le test nuScenes
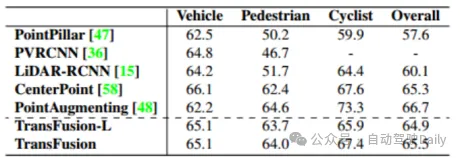
Tableau 2 NIVEAU 2 mAPH sur l'ensemble de validation Waymo
Robustesse aux conditions d'image difficiles
Avec TransFusion-L comme référence, différents cadres de fusion sont conçu pour vérifier la robustesse. Les trois cadres de fusion sont l'épissage point par point et la fusion des caractéristiques lidar et d'image (CC), la stratégie de fusion d'amélioration de points (PA) et TransFusion. Comme le montre le tableau 3, en divisant l'ensemble de données nuScenes en jour et nuit, la méthode TransFusion apportera une plus grande amélioration des performances la nuit. Pendant le processus d'inférence, les caractéristiques de l'image sont mises à zéro pour obtenir l'effet de rejet aléatoire de plusieurs images dans chaque image. Comme le montre le tableau 4, lorsque certaines images ne sont pas disponibles pendant le processus d'inférence, les performances de la détection sont affectées. diminuera considérablement, où le mAP de CC et PA a chuté de 23,8 % et 17,2 % respectivement, tandis que TransFusion est resté à 61,7 %. Le capteur non calibré affectera également grandement les performances de détection de cibles 3D. Le paramètre expérimental ajoute de manière aléatoire un décalage de translation à la matrice de transformation de la caméra vers le lidar, comme le montre la figure 4. Lorsque les deux capteurs sont décalés de 1 m, le mAP. de TransFusion Il n’a diminué que de 0,49 %, tandis que le mAP de PA et CC a diminué respectivement de 2,33 % et 2,85 %.
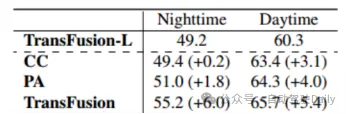
Tableau 3 mAP de jour comme de nuit

Tableau 4 mAP sous différents nombres d'images
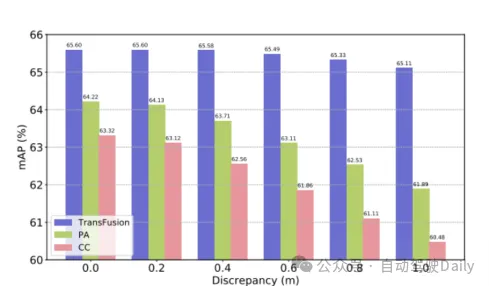
Figure 4 mAP sous désalignement du capteur
Expérience d'ablation
par tableau 5 d)-f) Il peut Les résultats montrent que sans initialisation de la requête, les performances de détection diminuent considérablement. Bien que l'augmentation du nombre de cycles d'entraînement et du nombre de couches de décodeur puisse améliorer les performances, elle ne peut toujours pas obtenir l'effet idéal, ce qui signifie également que c'est prouvé. du côté où la stratégie de requête d'initialisation proposée peut réduire le nombre de couches réseau. Comme le montre le tableau 6, la fusion de caractéristiques d'image et l'initialisation de requêtes guidées par image apportent des gains mAP de 4,8 % et 1,6 % respectivement. Dans le tableau 7, grâce à la comparaison de la précision dans différentes plages, les performances de détection de TransFusion dans les objets difficiles à détecter ou les zones éloignées ont été améliorées par rapport à la détection lidar uniquement.
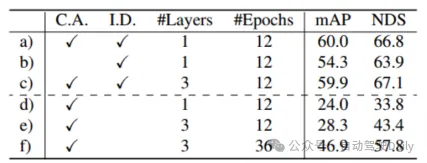
Tableau 5 Expérience d'ablation du module d'initialisation de requête
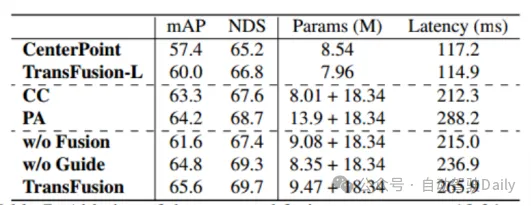
Tableau 6 Expérience d'ablation de la partie fusion

Tableau 7 Distance entre le centre de l'objet et le véhicule de l'ego (en mètres)
Conclusion
Un cadre de détection 3D de caméra lidar basé sur Transformer efficace et robuste est conçu avec un mécanisme de corrélation douce qui peut déterminer de manière adaptative l'emplacement et les informations qui doivent être obtenues à partir de l'image. TransFusion obtient des résultats de pointe dans les classements de détection et de suivi nuScenes et affiche des résultats compétitifs sur le benchmark de détection Waymo. De nombreuses expériences d'ablation démontrent la robustesse de cette méthode dans de mauvaises conditions d'image.
DeepInteraction :
Contribution principale :
Le principal problème résolu est que les stratégies de fusion multimodales existantes ignorent les informations utiles spécifiques à la modalité, ce qui entrave finalement les performances du modèle. Les nuages de points fournissent les informations de positionnement et géométriques nécessaires à basse résolution, et les images fournissent des informations d'apparence riches à haute résolution. La fusion d'informations multimodales est donc particulièrement importante pour améliorer les performances de détection de cibles 3D. Le module de fusion existant, comme le montre la figure 1 (a), intègre les informations des deux modalités dans un espace réseau unifié. Cependant, cela empêchera certaines informations d'être intégrées dans une représentation unifiée, ce qui réduira certaines informations spécifiques. . Avantages représentationnels de la modalité. Afin de surmonter les limitations ci-dessus, l'article propose un nouveau module d'interaction modale (Figure 1 (b)). L'idée clé est d'apprendre et de maintenir deux représentations spécifiques à une modalité pour réaliser une interaction entre les modalités. Les principales contributions sont les suivantes :
- propose une nouvelle stratégie d'interaction modale pour la détection de cibles 3D multimodale, visant à résoudre la limitation fondamentale des stratégies de fusion modale précédentes qui perdent des informations utiles dans chaque modalité
- a conçu une architecture DeepInteraction avec ; un codeur interactif de caractéristiques multimodales et un décodeur interactif de prédiction de caractéristiques multimodales.
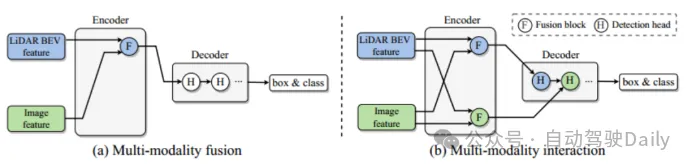
Figure 1 Différentes stratégies de fusion
Détails du module
Encodeur interactif à représentation multimodale Personnalisez l'encodeur dans une structure à entrées multiples et sorties multiples (MIMO) : séparez les dorsales du lidar et de la caméra. deux informations de scène spécifiques à une modalité extraites sont utilisées comme entrée, et deux informations de caractéristiques améliorées sont générées. Chaque couche d'encodeur comprend : i) une interaction de fonctionnalités multimodales (MMRI) ; ii) un apprentissage de fonctionnalités intra-modal iii) une intégration de représentation ;
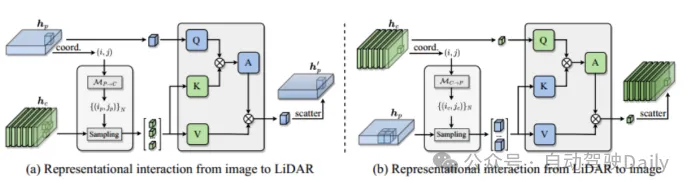
Figure 2 Module d'interaction de représentation multimodale

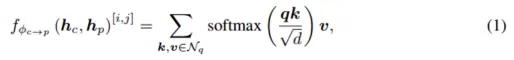
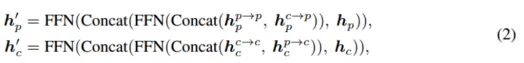

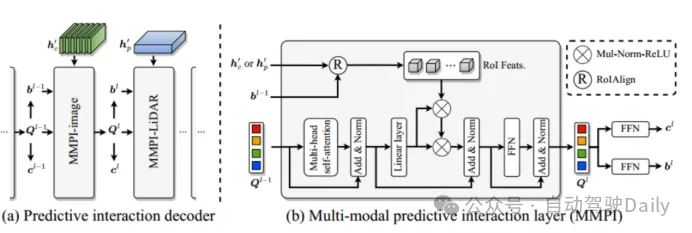
Figure 3 Module interactif de prédiction multimodale
Expérience
L'ensemble de données et les indicateurs sont les mêmes que l'ensemble de données nuScenes qui fait partie de TransFusion.
Détails expérimentaux Le réseau fédérateur de l'image est ResNet50 Afin de réduire les coûts de calcul, l'image d'entrée est redimensionnée à la moitié de la taille d'origine avant d'entrer dans le réseau, et les poids des branches de l'image sont gelés pendant. entraînement. La taille du voxel est réglée sur (0,075 m, 0,075 m, 0,2 m), la plage de détection est réglée sur [-54 m, 54 m] pour l'axe X et l'axe Y, et [-5 m, 3 m] pour l'axe Z. Axe. Concevez 2 couches de couches d'encodeur et 5 couches de décodeur en cascade. De plus, deux modèles de test de soumission en ligne sont mis en place : l'augmentation du temps de test (TTA) et l'intégration du modèle, et les deux paramètres sont appelés respectivement DeepInteraction-large et DeepInteraction-e. Parmi eux, DeepInteraction-large utilise Swin-Tiny comme réseau fédérateur d'image et double le nombre de canaux du bloc de convolution dans le réseau fédérateur lidar. La taille du voxel est définie sur [0,5 m, 0,5 m, 0,2 m] et. retournement bidirectionnel et faites pivoter l'angle de lacet [0°, ±6,25°, ±12,5°] pour augmenter la durée du test. DeepInteraction-e intègre plusieurs modèles DeepInteraction-large, et les tailles de grille lidar BEV d'entrée sont [0,5 m, 0,5 m] et [1,5 m, 1,5 m].
Augmentation des données selon la configuration de TransFusion : utilisation d'une rotation aléatoire dans la plage [-π/4,π/4], de coefficients d'échelle aléatoires [0.9,1.1], d'une translation aléatoire sur trois axes et d'un retournement horizontal aléatoire avec un écart type de 0,5. , utilise également le rééchantillonnage équilibré par classes dans CBGS pour équilibrer la distribution des classes de nuScenes. La même méthode de formation en deux étapes que TransFusion est utilisée, en utilisant TransFusion-L comme base de référence pour la formation lidar uniquement. L'optimiseur Adam utilise une stratégie de taux d'apprentissage à cycle unique, avec un taux d'apprentissage maximum de 1 × 10−3, une atténuation de poids de 0,01, un élan de 0,85 à 0,95 et suit le CBGS. La formation de base lidar est de 20 tours, la fusion d'images lidar est de 6 tours, la taille du lot est de 16 et 8 GPU NVIDIA V100 sont utilisés pour la formation.
Comparaison avec les méthodes de pointe
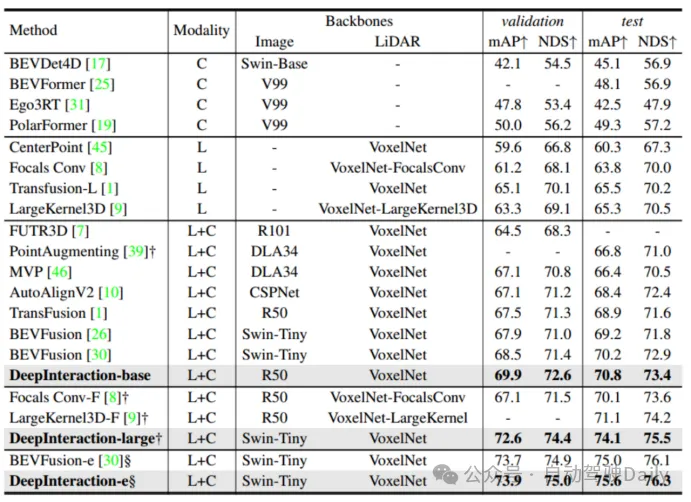
Tableau 1 Comparaison avec les méthodes de pointe sur l'ensemble de tests nuScenes
Comme le montre le tableau 1, DeepInteraction atteint l'état de l'art. des performances de pointe dans tous les contextes. Le tableau 2 compare les vitesses d'inférence testées respectivement sur NVIDIA V100, A6000 et A100. On peut voir que tout en atteignant des performances élevées, une vitesse d'inférence élevée est toujours maintenue, ce qui vérifie que cette méthode permet d'obtenir un compromis supérieur entre performances de détection et vitesse d'inférence.
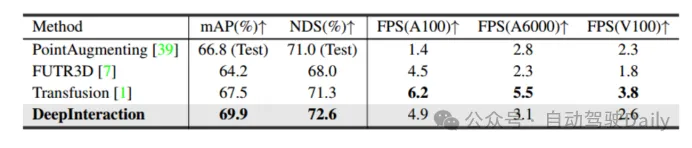
Tableau 2 Comparaison de la vitesse d'inférence
Expérience d'ablation
Expérience d'ablation du décodeur
Comparaison des couches de décodeur prédictif interactif multimodal et de décodeur DETR dans la conception et les utilisations du tableau 3 (a) une conception hybride : une couche de décodeur DETR normale est utilisée pour agréger les caractéristiques de la représentation lidar, et un décodeur prédictif interactif multimodal (MMPI) est utilisé pour agréger les caractéristiques de la représentation d'image (deuxième rangée). MMPI est nettement meilleur que DETR, améliorant 1,3 % de mAP et 1,0 % de NDS, avec une flexibilité de combinaison de conception. Le tableau 3 (c) explore plus en détail l'impact des différentes couches de décodeur sur les performances de détection. On peut constater que les performances continuent de s'améliorer lors de l'ajout de 5 couches de décodeurs. Enfin, différentes combinaisons de numéros de requêtes utilisées lors de la formation et des tests ont été comparées. Sous différents choix, les performances étaient stables, mais 200/300 a été utilisé comme paramètre optimal pour la formation/les tests.
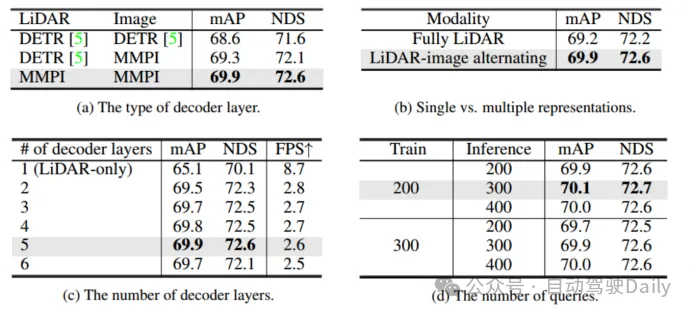
Tableau 3 Expérience d'ablation du décodeur
Expérience d'ablation du codeur
On peut l'observer à partir du tableau 4(a) : (1) Comparé à l'IML, l'encodeur interactif de représentation multimodale (MMRI) peut améliorer considérablement les performances ; (2) MMRI et IML peuvent bien fonctionner ensemble pour améliorer encore les performances. Comme le montre le tableau 4 (b), l’empilement de couches de codeurs pour le MMRI itératif est bénéfique.
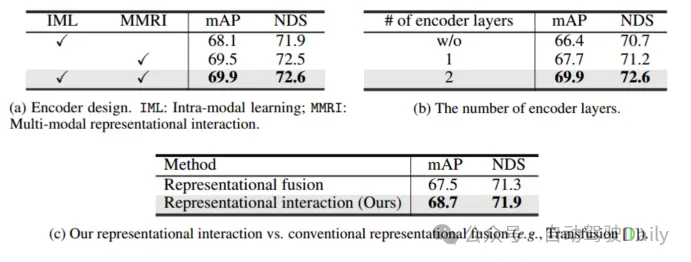
Tableau 4 Expérience d'ablation de l'encodeur
Expérience d'ablation du réseau fédérateur lidar
Utilisation de deux réseaux fédérateurs lidar différents : PointPillar et VoxelNet pour vérifier la généralité du cadre. Pour PointPillars, définissez la taille du voxel sur (0,2 m, 0,2 m) tout en conservant le reste des paramètres identiques à ceux de DeepInteraction-base. En raison de la stratégie d'interaction multimodale proposée, DeepInteraction montre des améliorations constantes par rapport à la ligne de base lidar uniquement lors de l'utilisation de l'un ou l'autre backbone (5,5 % de mAP pour le backbone basé sur le voxel et 4,4 % de mAP pour le backbone basé sur des piliers). Cela reflète la polyvalence de DeepInteraction parmi différents encodeurs de nuages de points.
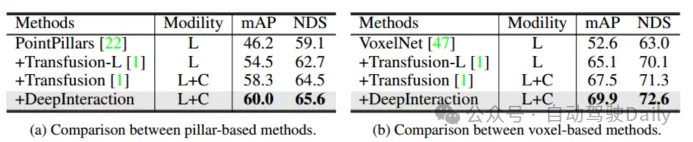
Tableau 5 Évaluation de différents squelettes lidar
Conclusion
Dans ce travail, une nouvelle méthode de détection d'objets 3D DeepInteraction est proposée pour explorer les propriétés complémentaires multimodales inhérentes. L'idée clé est de maintenir deux représentations spécifiques à une modalité et d'établir une interaction entre elles pour l'apprentissage des représentations et le décodage prédictif. Cette stratégie est spécifiquement conçue pour répondre à la limitation fondamentale des méthodes de fusion unilatérales existantes, à savoir que la représentation de l'image est sous-utilisée en raison de son traitement auxiliaire des caractères sources.
Résumé des deux articles :
Les deux articles ci-dessus sont tous deux une détection de cible tridimensionnelle basée sur la fusion lidar et caméra. On peut également voir dans DeepInteraction qu'il s'appuie sur des travaux ultérieurs de TransFusion. De ces deux articles, nous pouvons conclure qu’une direction de la fusion multi-capteurs consiste à explorer des méthodes de fusion dynamique plus efficaces afin de se concentrer sur des informations plus efficaces sur différentes modalités. Bien entendu, tout cela repose sur des informations de haute qualité dans les deux modalités. La fusion multimodale aura des applications très importantes dans des domaines futurs tels que la conduite autonome et les robots intelligents. À mesure que les informations extraites de différentes modalités s'enrichiront progressivement, de plus en plus d'informations seront disponibles. Il s'agit donc également de savoir comment les combiner plus efficacement. une question qui mérite réflexion.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Python dessine des graphiques 3D
- Quelle est la touche de raccourci pour afficher le bureau 3D sous Windows 7 ?
- Le système de détection d'intrusion actuel peut empêcher les attaques de pirates informatiques en temps opportun, n'est-ce pas ?
- Comment vérifier si nodejs est installé avec succès
- Pourquoi le microphone n'est-il pas détecté sur l'ordinateur ?