
Maison >Périphériques technologiques >IA >Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)
Revoir! Fusion profonde de modèles (LLM/modèle de base/apprentissage fédéré/mise au point, etc.)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-18 21:43:071105parcourir
Le 23 septembre, l'article « Deep Model Fusion : A Survey » a été publié par l'Université nationale de technologie de la défense, JD.com et l'Institut de technologie de Pékin.
La fusion/fusion de modèles profonds est une technologie émergente qui combine les paramètres ou les prédictions de plusieurs modèles d'apprentissage profond en un seul modèle. Il combine les capacités de différents modèles pour compenser les biais et les erreurs des modèles individuels pour de meilleures performances. La fusion profonde de modèles sur des modèles d'apprentissage profond à grande échelle (tels que le LLM et les modèles de base) est confrontée à certains défis, notamment un coût de calcul élevé, un espace de paramètres de grande dimension, l'interférence entre différents modèles hétérogènes, etc. Cet article divise les méthodes de fusion de modèles profonds existantes en quatre catégories : (1) « Connexion de modèle », qui relie les solutions dans l'espace de poids via un chemin de réduction des pertes pour obtenir une meilleure initialisation de fusion de modèles ; (2) « Alignement », correspondant aux unités entre ; des réseaux de neurones pour créer de meilleures conditions de fusion ; (3) la « moyenne des poids » est une méthode classique de fusion de modèles qui fait la moyenne des poids de plusieurs modèles pour obtenir des solutions optimales plus proches et des résultats plus précis ; (4) « l'apprentissage d'ensemble » combine les résultats ; de différents modèles, ce qui constitue une technologie de base pour améliorer la précision et la robustesse du modèle final. En outre, les défis rencontrés par la fusion profonde de modèles sont analysés et des orientations de recherche possibles pour la future fusion de modèles sont proposées.
La fusion approfondie de modèles suscite un intérêt croissant en raison de problèmes pratiques de confidentialité et de sauvegarde des données. Bien que le développement de la fusion profonde de modèles ait apporté de nombreuses avancées technologiques, il a également créé une série de défis, tels qu'une charge de calcul élevée, l'hétérogénéité des modèles et un alignement lent de l'optimisation combinatoire. Cela a incité les scientifiques à étudier les principes de la fusion de modèles dans différentes situations.
Certains travaux se concentrent uniquement sur la fusion de modèles depuis une seule perspective (comme la fusion de fonctionnalités, etc.) [45, 195] et des scènes spécifiques [213], plutôt que sur la fusion de paramètres. Avec les avancées récentes et les applications représentatives, telles que l'apprentissage fédéré (FL) [160] et le réglage fin [29], cet article les divise en quatre catégories basées sur des mécanismes et des objectifs internes. La figure montre un diagramme schématique de l'ensemble du processus de fusion de modèles, ainsi que la classification et la connexion de diverses méthodes.
Pour les modèles formés indépendamment et non adjacents les uns aux autres, "Mode Join" et "Align" rapprochent les solutions, ce qui entraîne de meilleures conditions brutes moyennes. Pour des modèles similaires présentant certaines différences dans les espaces de poids, la « moyenne des poids (WA) » a tendance à faire la moyenne des modèles directement pour obtenir une solution plus proche du point optimal dans la région de l'espace des paramètres avec des valeurs de fonction de perte plus faibles. De plus, pour les prédictions des modèles existants, « l’apprentissage d’ensemble » intègre les prédictions de différentes formes du modèle pour obtenir de meilleurs résultats.
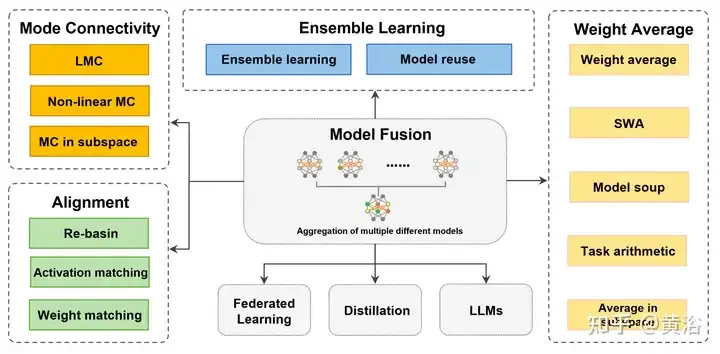
"La fusion de modèles, en tant que technique permettant d'améliorer la précision et la robustesse des modèles profonds, a favorisé des améliorations dans de nombreux domaines d'application. L'apprentissage fédéré [160] est un modèle qui regroupe les modèles clients sur un serveur central avec précision et applications de robustesse, permettant aux parties de contribuer aux données au calcul des fonctions (par exemple, diverses statistiques, classificateurs [177]) sans risque de fuite de confidentialité en « ajustant » celles pré-entraînées. De petits ajustements sont apportés au modèle et combinés avec. la fusion de modèles pour réduire les coûts de formation et s'adapter aux besoins d'une tâche ou d'un domaine spécifique. La fusion de modèles implique également la « distillation », c'est-à-dire la combinaison des connaissances de plusieurs modèles complexes (enseignants) pour en former un seul (étudiants) à adapter. à des besoins spécifiques. La « fusion de modèles sur base/LLM » inclut le travail sur de grands modèles de base ou de grands modèles de langage (LLM), tels que Transformer (ViT) [79], GPT [17], etc. Les applications convergées aident les développeurs à s'adapter aux besoins spécifiques. besoins de diverses tâches et domaines, favorisant le développement de l'apprentissage en profondeur. " Le nombre de mots est plein.
Pour déterminer si les résultats d'un réseau entraîné sont stables au bruit SGD, la barrière de perte (barrière d'erreur) est définie comme la différence maximale entre une interpolation linéaire de perte à deux points et une perte de connexion linéaire à deux points [50 ]. La barrière de perte précise si l'erreur est constante ou croissante le long du graphique d'optimisation du chemin entre W1 et W2 [56, 61]. S'il existe un tunnel entre deux réseaux avec une barrière approximativement égale à 0, cela équivaut à une connexion en mode [46, 59, 60]. En d’autres termes, les minima locaux obtenus par SGD peuvent être connectés via un chemin φ qui minimise la perte maximale.
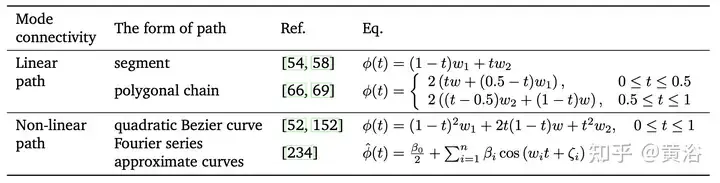
Les solutions obtenues à partir de l'optimisation basée sur le gradient peuvent être connectées via des chemins (connecteurs) sans barrières dans l'espace de poids, ce qui est appelé connexion de modèle[46, 50]. D'autres modèles plus adaptés à la fusion de modèles peuvent être obtenus via la voie à faibles pertes. Selon la forme mathématique du chemin et l'espace où se trouve le connecteur, il est divisé en trois parties : "Connexion en mode linéaire (LMC) [66]", "Connexion en mode non linéaire" et "Connexion par motif du sous-espace".
La connexion de modèles peut résoudre les problèmes d'optimisation locale pendant la formation. Les relations géométriques des chemins de connexion de modèles [61, 162] peuvent également être utilisées pour accélérer la convergence, la stabilité et la précision des processus d'optimisation tels que la descente de gradient stochastique (SGD). En résumé, la connexion de modèles offre une nouvelle perspective pour interpréter et comprendre le comportement de la fusion de modèles [66]. Cependant, la complexité informatique et les difficultés de réglage des paramètres doivent être prises en compte, en particulier lors de la formation de modèles sur de grands ensembles de données. Le tableau suivant est un résumé des procédures de formation standard pour la connexion en mode linéaire (LMC) et la connexion en mode non linéaire.
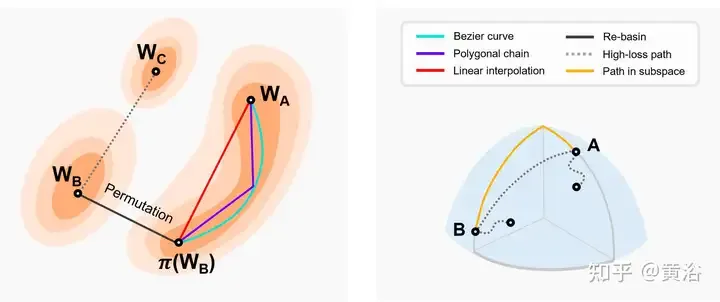
L'image montre la carte de perte bidimensionnelle et le schéma de connexion des motifs dans d'autres sous-espaces dimensionnels. Gauche : L'interpolation linéaire de deux minima de bassin aboutit à une barrière à pertes élevées [46]. Les deux valeurs optimales inférieures suivent des chemins à faibles pertes presque constants (par exemple, courbes de Bézier, chaînes polybox, etc.) [66]. π(W2) est le modèle équivalent de la symétrie d’arrangement de W2, qui est situé dans le même bassin que W1. Re-Basin fusionne les modèles en fournissant des solutions pour des bassins versants individuels [3]. À droite : les chemins à faibles pertes connectent plusieurs minima dans un sous-espace (par exemple, une variété à faibles pertes constituée de coins de dimension d [56], etc.).
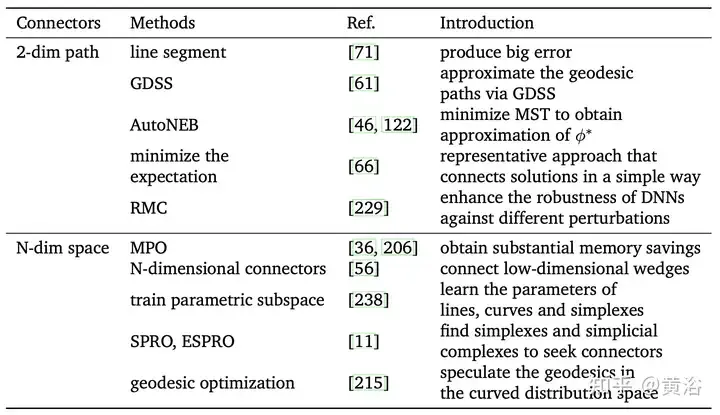
Le tableau suivant est une méthode pour trouver des tunnels entre différents minima locaux.
En bref, la connexion de modèles offre une perspective plus récente et plus flexible pour la fusion profonde de modèles. La formation des réseaux de neurones peut facilement tomber dans l'optimalité locale, entraînant une dégradation des performances. Sur la base de la connexion des modèles, d'autres modèles offrant de meilleures performances peuvent être trouvés et utilisés comme point de départ pour une optimisation et une fusion ultérieures. Le modèle déjà entraîné peut être utilisé pour se déplacer dans l'espace des paramètres afin d'atteindre un nouveau modèle cible, ce qui permet d'économiser du temps et des coûts de calcul et convient aux situations où les données sont limitées. Cependant, lors de la connexion de différents modèles, une complexité et une flexibilité supplémentaires peuvent être introduites, augmentant ainsi le risque de surajustement. Par conséquent, les hyperparamètres pertinents et le degré de variation doivent être soigneusement contrôlés. De plus, la concaténation de modèles nécessite un réglage précis ou des modifications de paramètres, ce qui peut augmenter le temps de formation et la consommation de ressources. En résumé, la connectivité des modèles présente de nombreux avantages dans la fusion de modèles, notamment en aidant à surmonter les problèmes optimaux locaux et en offrant de nouvelles perspectives pour expliquer le comportement du réseau. À l’avenir, la connexion de modèles devrait aider à comprendre les mécanismes internes des réseaux de neurones et fournir des conseils pour des conceptions de fusion de modèles plus efficaces à l’avenir.
En raison du caractère aléatoire des canaux et des composants des différents réseaux, les composants actifs du réseau interfèrent les uns avec les autres [204]. Par conséquent, des moyennes pondérées mal alignées peuvent ignorer la correspondance entre les unités de différents modèles et corrompre les informations utiles. Par exemple, il existe une relation entre deux neurones dans des modèles différents qui peuvent être complètement différents mais fonctionnellement similaires. L'alignement consiste à faire correspondre les unités de différents modèles afin d'obtenir de meilleures conditions initiales pour une fusion profonde de modèles. L'objectif est de réduire les différences entre plusieurs modèles, améliorant ainsi l'effet de fusion profonde des modèles. De plus, l’alignement peut être essentiellement considéré comme un problème d’optimisation combinatoire. Un mécanisme représentatif "Re-basin" qui fournit des solutions pour des bassins individuels, en fusionnant des modèles avec de meilleures conditions d'origine. Selon que la cible d'alignement est basée sur les données ou non, l'alignement est divisé en deux types : « correspondance d'activation » et « correspondance de poids », comme indiqué dans le tableau.
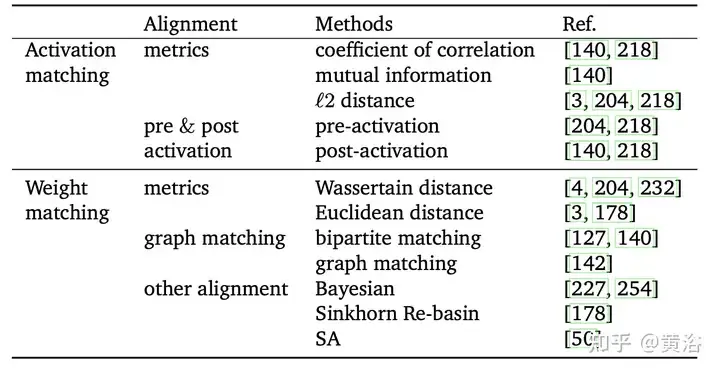
De manière générale, même pour les réseaux de neurones peu profonds, le nombre de points selle et d'optima locaux augmente de façon exponentielle avec le nombre de paramètres [10, 66]. Il a été constaté qu'il existe une invariance dans l'entraînement, ce qui fait que certains points de ces optima locaux ont la même représentation (22, 81, 140). Plus précisément, si les unités de la couche cachée sont échangées par permutation, la fonctionnalité du réseau ne change pas, ce que l'on appelle la symétrie de permutation[43, 50].
La symétrie de permutation apportée par ces invariants permet de mieux comprendre la structure du graphe de perte [22, 66]. L'invariance peut également être considérée comme une source de points selle dans le graphique de perte [14]. [68] étudient la structure algébrique des symétries dans les réseaux de neurones et comment cette structure se manifeste dans la géométrie des graphes de pertes. [14] ont introduit des points de permutation dans des plates-formes de grande dimension où les neurones peuvent être échangés sans augmenter les pertes ni les sauts de paramètres. Effectuez une descente de gradient sur la perte, en ajustant les vecteurs de paramètres θm et θn des neurones m et n jusqu’à ce que les vecteurs atteignent le point d’alignement.
Sur la base de la symétrie de l'arrangement, les solutions dans différentes régions de l'espace de poids peuvent générer des solutions équivalentes. La solution équivalente est située dans la même région que la solution originale, avec une barrière (bassin) à faibles pertes, appelée « Re-bassin » [3]. Comparé aux connexions de modèle, le rebassin a tendance à transporter les points dans le bassin via un alignement plutôt que par un tunnel à faibles pertes. Actuellement, l'alignement est la méthode représentative du Re-basin [3, 178]. Cependant, comment rechercher efficacement toutes les possibilités de symétries de permutation telles que toutes les solutions pointent vers le même bassin est un défi actuel.
L'image est un diagramme schématique de [14] introduisant des neurones à échange de points alignés. Gauche : Processus général d’alignement, le modèle A est transformé en modèle Ap en référence au modèle B, puis la combinaison linéaire de Ap et B produit C. À droite : Ajustez les vecteurs paramètres θm et θn de deux neurones dans différentes couches cachées proches du point d'alignement [14] θ′m = θ′n, les deux neurones calculent la même fonction, ce qui signifie que les deux. les neurones peuvent être échangés.
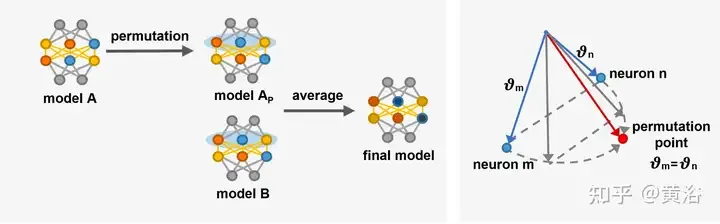
L'alignement rend les modèles plus similaires en ajustant les paramètres des modèles, ce qui peut améliorer le partage d'informations entre les modèles, améliorant ainsi la capacité de généralisation du modèle de fusion. De plus, l’alignement contribue à améliorer les performances et la robustesse du modèle sur des tâches complexes. Cependant, les méthodes d’alignement sont confrontées au problème d’une optimisation combinatoire lente. L'alignement nécessite une surcharge de calcul supplémentaire pour ajuster les paramètres du modèle, ce qui peut conduire à un processus de formation plus complexe et plus long, en particulier dans les modèles à grande profondeur [142, 204].
Pour résumer, l'alignement peut améliorer la cohérence et l'effet global entre les différents modèles. Avec la diversification des scénarios d’application DL, l’alignement deviendra l’une des méthodes clés pour optimiser la fusion approfondie des modèles et améliorer les capacités de généralisation. À l’avenir, l’alignement pourra jouer un rôle dans l’apprentissage par transfert, l’adaptation au domaine [63], la distillation des connaissances et d’autres domaines. Par exemple, l’alignement peut réduire la différence entre les domaines source et cible dans l’apprentissage par transfert et améliorer l’apprentissage de nouveaux domaines.
En raison de la forte redondance des paramètres des réseaux neuronaux, il n'y a généralement pas de correspondance biunivoque entre les poids des différents réseaux neuronaux. Par conséquent, la moyenne pondérée (WA) n’est généralement pas garantie de bons résultats par défaut. La moyenne ordinaire fonctionne mal pour les réseaux formés avec de grandes différences de poids [204]. D'un point de vue statistique, WA permet de contrôler les paramètres individuels du modèle dans le modèle, réduisant ainsi la variance du modèle final et ayant ainsi un impact fiable sur les propriétés de régularisation et les résultats de sortie (77, 166).
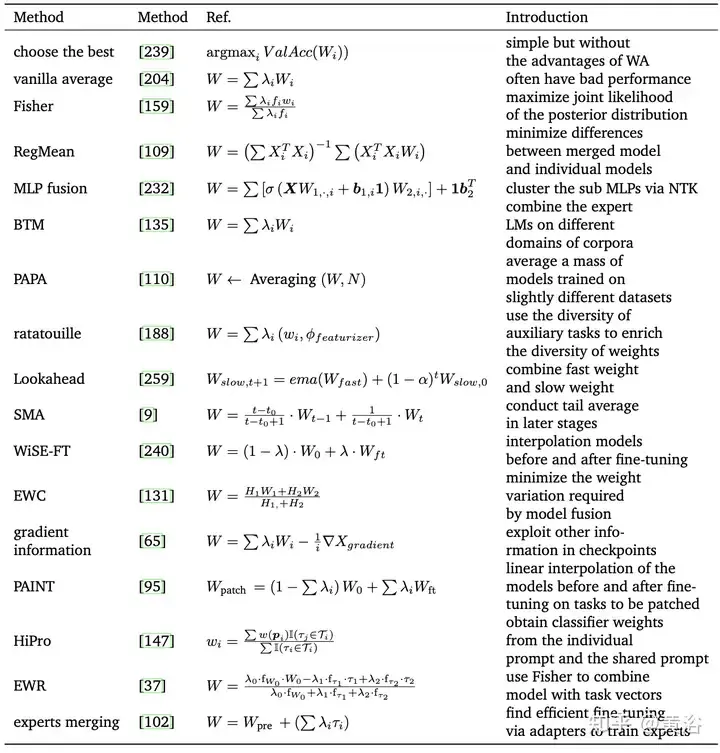
Le tableau suivant est une méthode représentative de WA :
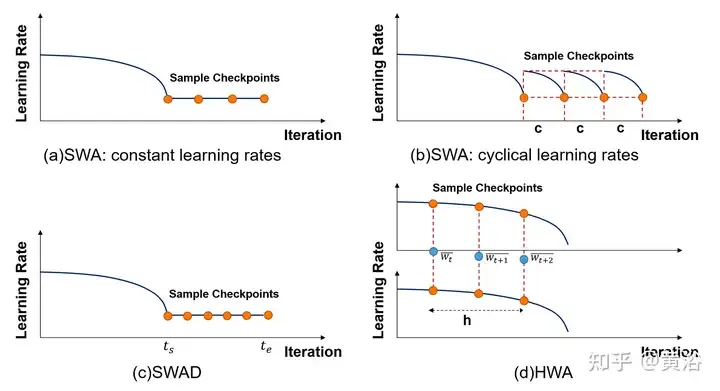
Inspiré par Fast Geometry Ensemble(FGE) [66] et la moyenne des points de contrôle [149], [99] exploite la constante ou la périodicité L'apprentissage Le taux est calculé en moyenne sur plusieurs points de la trajectoire SGD, ce qui est connu sous le nom de moyenne de poids stochastique (SWA). SWA améliore la formation sur une gamme de références importantes, offrant une meilleure évolutivité temporelle. Au lieu de former une collection de modèles (comme une fusion normale), SWA entraîne un seul modèle pour trouver une solution plus fluide que SGD. Les méthodes liées à SWA sont répertoriées dans le tableau suivant. De plus, SWA peut être appliqué à n'importe quelle architecture ou ensemble de données et démontre de meilleures performances que Snapshot Ensemble (SSE) [91] et FGE. À la fin de chaque période, le modèle SWA est mis à jour en faisant la moyenne des poids nouvellement obtenus avec les poids existants.
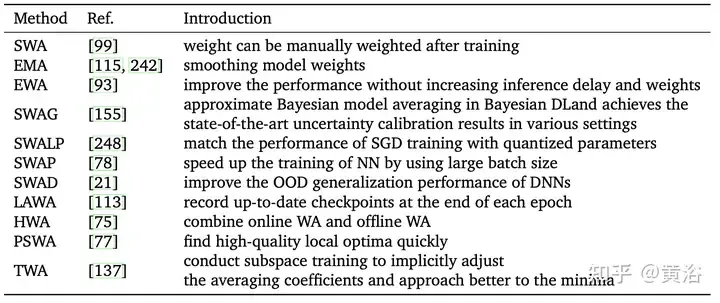
Cependant, SWA ne peut faire la moyenne que des points proches du point optimal local et obtient finalement une valeur minimale relative, mais ne peut pas se rapprocher avec précision de la valeur optimale. De plus, en raison de certains facteurs (tels qu'une mauvaise convergence précoce, un taux d'apprentissage élevé, un taux de changement de poids rapide, etc.), l'écart final de l'échantillon d'entrée peut être important ou insuffisant, ce qui entraîne des résultats globaux médiocres. De nombreux travaux tendent à modifier les méthodes d’échantillonnage SWA.
Comme le montre la figure, les dispositions de taux d'échantillonnage et d'apprentissage de différentes méthodes liées à SWA sont comparées. (a) SWA : taux d’apprentissage constant. (b)SWA : Taux d’apprentissage périodique. (c)SWAD : échantillonnage dense. (d) HWA : en utilisant WA en ligne et hors ligne, en échantillonnant à différentes périodes de synchronisation, la longueur de la fenêtre glissante est h.
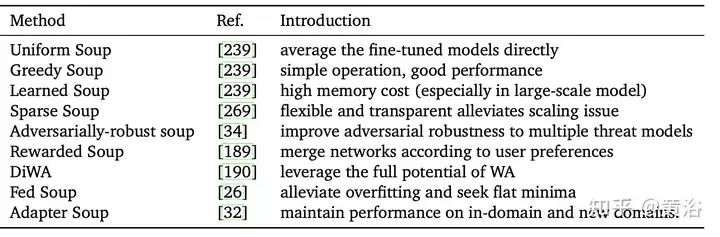
La soupe aux modèles [239] fait référence à une méthode de moyenne de modèles affinés avec différents hyperparamètres. Il est simple mais efficace, atteignant une précision de 90,94 % sur ImageNet-1K, surpassant les travaux précédents sur CoAtNet-7 (90,88 %) [38] et ViT-G (90,45 %) [255]. Le tableau résume les différentes méthodes de soupe modèle.
Dans l'apprentissage multitâche (MTL), le modèle pré-entraîné et le vecteur de tâches (c'est-à-dire τi = Wft − Wpre, la différence entre le modèle pré-entraîné et le modèle affiné) sont combinés pour obtenir de meilleures performances sur tous Tâches. Sur la base de cette observation, Task Arithmetic[94] améliore les performances du modèle sur les tâches en affinant les vecteurs de tâches grâce à l'addition et à la combinaison linéaire, ce qui est devenu une méthode flexible et efficace pour éditer directement des modèles pré-entraînés, comme le montre dans la figure : Adoption des tâches Arithmétique et LoraHub (Hub d'adaptations de bas rang).
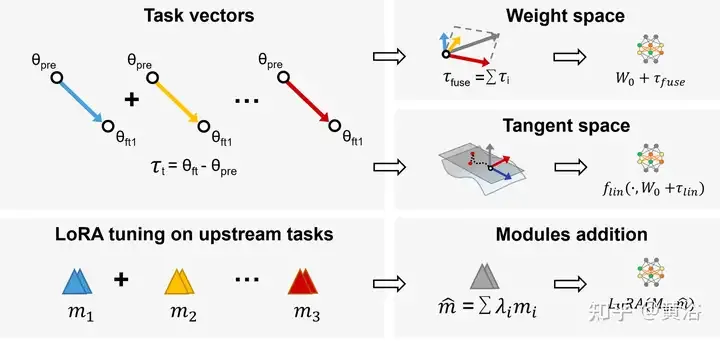
De plus, la fusion de modèles dans le sous-espace limite la trajectoire d'entraînement à un sous-espace de faible dimension, ce qui peut réduire la charge et la difficulté.
WA obtient le modèle final en faisant la moyenne des poids de différents modèles de profondeur sans complexité informatique ni processus de formation supplémentaires [109, 159]. En général, si les modèles aléatoires diffèrent considérablement en termes de capacités de représentation, de structure ou de données d'entraînement, les résultats de la fusion risquent de ne pas atteindre les performances attendues. L'interpolation linéaire d'un modèle à partir de zéro utilisant la même configuration d'hyperparamètres mais avec un ordre de données différent est encore moins efficace qu'un modèle stochastique [59]. Par conséquent, un grand nombre de méthodes proposées visent à optimiser le processus WA par d’autres moyens mathématiques.
De plus, lorsque les modèles partagent une partie de leur trajectoire d'optimisation (par exemple, moyenne de point de contrôle, moyenne de queue, SWA [99, 149], etc.) ou sont affinés sur le même modèle pré-entraîné (par exemple, soupe modèle [ 239], etc. ), la précision du modèle d'interpolation est plus performante [167]. De plus, Model Soup [239] fait la moyenne des modèles avec différentes configurations d'hyperparamètres pour obtenir le résultat final. De plus, le choix des pondérations appropriées dans la moyenne du modèle peut également être un défi, souvent lourd de subjectivité. Des mécanismes de sélection de poids plus complexes peuvent nécessiter des expériences et une validation croisée étendues et complexes.
WA est une technologie prometteuse en matière d'apprentissage profond. Elle peut être utilisée à l'avenir comme technologie d'optimisation de modèles pour réduire les fluctuations de poids entre les différentes itérations et améliorer la stabilité et la vitesse de convergence. WA peut améliorer l'étape d'agrégation de l'apprentissage fédéré (FL) pour mieux protéger la confidentialité et réduire les futurs coûts de communication. De plus, en implémentant la compression du réseau sur le périphérique final, cela devrait réduire l'espace de stockage et la surcharge de calcul du modèle sur les périphériques aux ressources limitées [250]. En bref, WA est une technologie DL prometteuse et rentable qui peut être appliquée dans des domaines tels que FL pour améliorer les performances et réduire les frais de stockage. L'apprentissage d'ensemble
, ou système multi-classificateur, est une technique qui intègre plusieurs modèles uniques pour générer une prédiction finale, y compris le vote, la moyenne [195], etc. Il améliore les performances globales et réduit la variance du modèle, résolvant ainsi des problèmes tels que le surajustement, l'instabilité et le volume de données limité.Basé sur des modèles sources pré-entraînés existants, Réutilisation de modèles
[266] fournit les modèles nécessaires pour être appliqués à de nouvelles tâches sans qu'il soit nécessaire de recycler un nouveau modèle à partir de zéro. Il permet d'économiser du temps et des ressources informatiques et offre de meilleures performances dans des conditions de ressources limitées [249]. De plus, puisque l’objectif de l’apprentissage par transfert est de résoudre la tâche de prédiction sur le domaine cible, la réutilisation de modèles peut être considérée comme un type d’apprentissage par transfert. Cependant, l'apprentissage par transfert nécessite des données étiquetées du domaine source et du domaine cible, tandis que dans la réutilisation de modèles, seules les données non étiquetées peuvent être collectées, mais les données du domaine source ne peuvent pas être utilisées (153).Contrairement à l'apprentissage d'ensemble multi-classificateur, la plupart des méthodes actuelles réutilisent les fonctionnalités, étiquettes ou modalités existantes pour obtenir des prédictions finales [176, 266] sans stocker de grandes quantités de données d'entraînement [245]. Un autre défi clé de la réutilisation des modèles consiste à identifier les modèles utiles à partir d'un ensemble de modèles pré-entraînés pour une tâche d'apprentissage donnée.
L'utilisation d'un modèle unique pour la réutilisation du modèle produit trop d'informations homogènes (par exemple, un modèle formé dans un domaine peut ne pas correspondre aux données d'un autre domaine), et il est difficile de trouver un seul modèle pré-entraîné parfaitement adapté à le domaine cible. De manière générale, l'utilisation d'un ensemble de modèles similaires pour produire de meilleures performances qu'un seul modèle est représentée par laRéutilisation de modèles multiples (MMR)
[153].Le tableau suivant compare les caractéristiques des différentes méthodes de réutilisation. En bref, la réutilisation de modèles peut réduire considérablement la quantité de données requise pour utiliser des modèles pré-entraînés et résoudre le problème de la consommation d'une grande quantité de bande passante lors de la transmission de données entre différentes extrémités. La réutilisation multimodèle a également un large éventail d'applications, telles que la reconnaissance vocale, les systèmes interactifs sécurisés et privés, la rétine numérique [64], etc.
Par rapport aux algorithmes de fusion de modèles associés tels que l'apprentissage fédéré [88, 89, 160] qui ont certaines exigences sur les paramètres et l'échelle du modèle, les 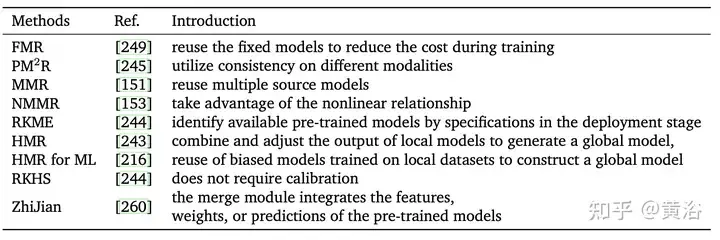 méthodes d'apprentissage d'ensemble
méthodes d'apprentissage d'ensemble
En raison de la diversité du cadre d'apprentissage d'ensemble, la diversité des modèles peut être obtenue et les capacités de généralisation peuvent être améliorées. À l’avenir, cela sera important pour gérer les modifications de données et les attaques contradictoires. L’apprentissage d’ensemble dans l’apprentissage profond devrait fournir des estimations de confiance et des mesures d’incertitude pour les prédictions des modèles, qui sont cruciales pour la sécurité et la fiabilité des systèmes d’aide à la décision, de la conduite autonome [74], du diagnostic médical, etc.
Ces dernières années, de nombreuses nouvelles recherches sont apparues dans le domaine de la fusion profonde de modèles, ce qui a également favorisé le développement de domaines d'application connexes.
Federated Learning
Pour relever les défis de sécurité et de centralisation du stockage des données, Federated Learning (FL) [160, 170] permet à de nombreux modèles participants de former en collaboration un modèle global partagé tout en protégeant la confidentialité des données sans avoir besoin de les collecter. est centralisé sur un serveur central. Cela peut également être considéré comme un problème d’apprentissage multipartite [177]. En particulier, l'agrégation est un processus important de FL, qui contient des mises à jour de modèles ou de paramètres formés par diverses parties (telles que des appareils, des organisations ou des individus). La figure montre deux méthodes d'agrégation différentes en FL centralisé et décentralisé. , À gauche : Apprentissage fédéré centralisé entre un serveur central et des terminaux clients, transférant des modèles ou des dégradés et enfin agrégeant sur le serveur. À droite : transferts d'apprentissage fédérés décentralisés et modèles d'agrégation entre les terminaux clients sans avoir besoin d'un serveur central.
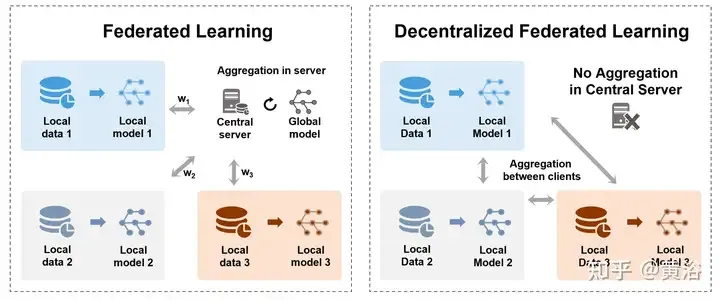
Le tableau suivant présente les différentes méthodes d'agrégation de l'apprentissage fédéré :
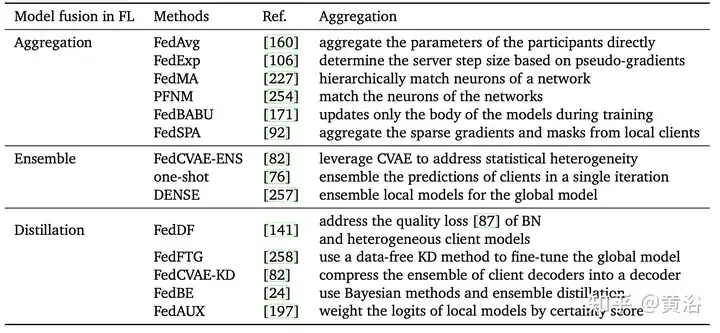
En bref, l'essence de l'étape d'agrégation en FL est une technique de fusion de modèles. Le choix d'une méthode raisonnable de fusion de modèles peut réduire l'impact de données spécifiques de participants ou individuelles sur le modèle final, améliorant ainsi la capacité de généralisation et l'adaptabilité du modèle à l'échelle mondiale. De bonnes méthodes d’agrégation devraient contribuer à relever toute une série de défis liés à l’apprentissage fédéré à l’avenir. Les méthodes d'agrégation de haute qualité et évolutives devraient faire face à une série de défis de FL, tels que l'hétérogénéité des clients, les données hétérogènes non-IID, les ressources informatiques limitées [141], etc. FL devrait montrer son potentiel dans davantage de domaines, tels que le traitement du langage naturel, les systèmes de recommandation [146], l'analyse d'images médicales [144], etc.
Réglage fin
Le réglage fin est un modèle de base (tel qu'un modèle pré-entraîné) et constitue un moyen efficace d'ajuster le modèle pour effectuer des tâches en aval [23, 41], ce qui permet d'obtenir une meilleure généralisation en utilisant données moins étiquetées et sortie plus précise. Les modèles pré-entraînés sont entraînés avec un ensemble de données relativement spécifiques à une tâche, ce qui constitue toujours un meilleur point de départ pour les critères d'entraînement qu'une initialisation aléatoire. malgré cela. En moyenne, les modèles affinés existants [28, 29] sont des modèles de base encore meilleurs que les modèles pré-entraînés ordinaires pour affiner les tâches en aval.
De plus, il existe de nombreux travaux récents qui combinent WA et réglage fin, comme le montre la figure, comme model soup [239], DiWA [190], etc. Un réglage fin améliore la précision de la distribution cible, mais entraîne souvent une robustesse réduite aux changements de distribution. Les stratégies de moyenne des modèles affinés sont peut-être simples, mais elles n’exploitent pas pleinement les liens entre chaque modèle affiné. Par conséquent, la formation sur les tâches intermédiaires avant la formation sur la tâche cible peut explorer les capacités du modèle de base [180, 185, 224]. Inspirés par la stratégie de formation mutuelle [185], [188] affinent le modèle des tâches auxiliaires pour exploiter différentes tâches auxiliaires et améliorer les capacités de généralisation hors distribution (OOD).
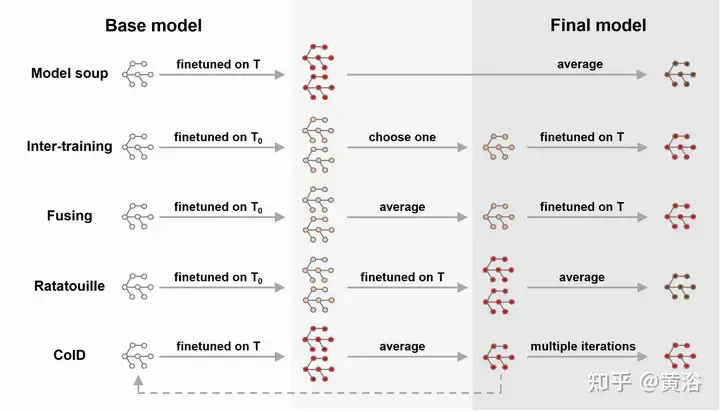
Le réglage fin de la moyenne du modèle réduit le temps de formation nécessaire pour atteindre l'objectif [28] et produit un modèle plus précis et mieux généralisé. Essentiellement, différentes méthodes de réglage fin (par exemple, le réglage fin de la couche gelée, le réglage fin de haut niveau, etc.) auront également un certain impact sur la précision finale et le changement de distribution [240]. Cependant, la combinaison de WA et de réglage fin est coûteuse et présente certaines limites sur des applications spécifiques. De plus, il peut être confronté au problème de l'explosion des points de contrôle sauvegardés ou de l'oubli catastrophique [121], en particulier lorsqu'il est appliqué à l'apprentissage par transfert.
Knowledge Distillation
Knowledge Distillation (KD) [83] est une méthode importante pour intégrer plusieurs modèles, impliquant les deux types de modèles suivants. Modèle enseignant fait référence à un modèle vaste et puissant formé sur des données à grande échelle, avec des capacités prédictives et expressives élevées. Le modèle étudiant est un modèle relativement petit avec moins de paramètres et de ressources de calcul [18, 199]. En utilisant les connaissances de l'enseignant (telles que la distribution de probabilité de sortie, la représentation des couches cachées, etc.) pour guider la formation, les étudiants peuvent atteindre des capacités de prédiction proches des grands modèles avec moins de ressources et une vitesse plus rapide [2, 119, 124, 221]. Considérant que plusieurs enseignants ou étudiants devraient obtenir de meilleurs résultats qu'un seul modèle [6], KD est divisé en deux catégories en fonction de l'objectif d'agrégation, comme le montre la figure.
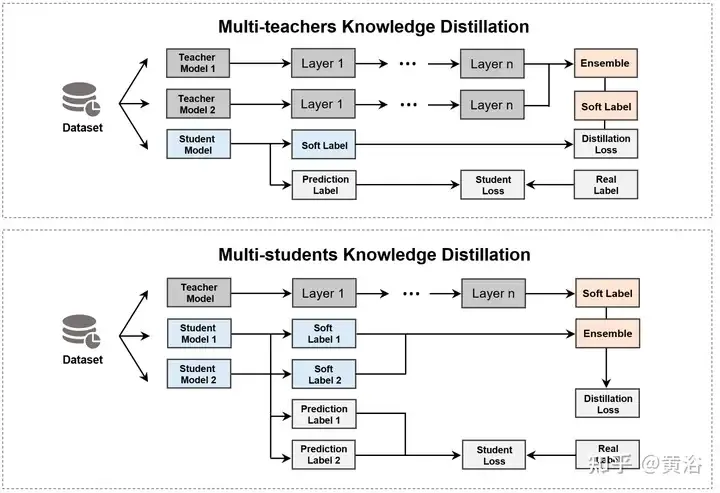
Le premier type de méthode consiste à fusionner plusieurs modèles d'enseignant et à extraire directement le modèle d'élève, comme indiqué dans le tableau. Actuellement, les travaux récents intègrent principalement les résultats des enseignants (par exemple, logits [6, 49, 252] ou connaissances de base de fonctionnalités [143, 241], etc.).

Une autre approche consiste à utiliser un modèle d'enseignant pour extraire plusieurs étudiants, puis à fusionner ces modèles d'étudiants. Cependant, la fusion de plusieurs étudiants pose également certains problèmes, tels que des besoins en ressources informatiques élevés, une mauvaise interprétabilité et une dépendance excessive à l'égard du modèle d'origine.
Fusion de modèles de modèles de base/LLM
Les modèles de base montrent de fortes performances et des capacités émergentes lors du traitement de tâches complexes. Les grands modèles de base se caractérisent par leur énorme échelle, contenant des milliards de paramètres, aidant à apprendre des modèles de données complexes. Surtout, avec l'émergence récente de nouveaux LLM [200, 264], tels que les applications GPT-3 [17, 172], T5 [187], BERT [41], Megatron-LM, WA [154, 212, 256 ] ] LLM a attiré plus d'attention.
De plus, des travaux récents [120, 256] tendent à concevoir de meilleurs frameworks et modules à adapter pour appliquer le LLM. En raison des performances élevées et des faibles ressources de calcul, le réglage fin des modèles de grande base peut améliorer la robustesse aux changements de distribution [240].
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Méthode de mise en œuvre de l'algorithme de permutation et de combinaison complète JS
- Quelles sont les deux manières d'écrire le tri à bulles ? Utilisez le tri à bulles pour organiser 10 nombres.
- Comment trier un tableau PHP par ordre décroissant par nom de clé
- Quel est le modèle de boîte CSS ?
- Que sont les technologies de récupération informatique ?