
Maison >Périphériques technologiques >IA >Le grand modèle de texte long méta illimité est ici : seulement 7B de paramètres, open source
Le grand modèle de texte long méta illimité est ici : seulement 7B de paramètres, open source

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-18 15:40:011033parcourir
Après Google, Meta vient aussi rouler des contextes infiniment longs.
La complexité quadratique et la faible extrapolation de longueur des Transformers limitent leur capacité à s'adapter à de longues séquences. Bien que des solutions quadratiques telles que les modèles d'attention linéaire et d'espace d'état existent, d'après l'expérience passée, elles fonctionnent mal en termes d'efficacité de pré-entraînement. et la précision des tâches en aval.
Récemment, Infini-Transformer proposé par Google a attiré l'attention des gens en introduisant une méthode efficace qui peut étendre les grands modèles de langage (LLM) basés sur Transformer à des entrées infiniment longues sans augmenter les besoins de stockage et de calcul.
Presque au même moment, Meta proposait également une technologie de texte infiniment long.

Adresse de l'article : https://arxiv.org/pdf/2404.08801.pdf
Titre de l'article : MEGALODON : Pré-entraînement et inférence LLM efficaces avec une longueur de contexte illimitée
Code : https:/ /github.com/XuezheMax/megalodon
Dans un article soumis le 12 avril, des institutions de Meta, de l'Université de Californie du Sud, de la CMU, de l'UCSD et d'autres institutions ont présenté MEGALODON, un réseau neuronal pour une modélisation efficace des séquences et de la longueur du contexte. n'est pas limité.
MEGALODON développe davantage la structure de MEGA (Exponential Moving Average with Gated Attention) et introduit une variété de composants techniques pour améliorer ses capacités et sa stabilité, notamment la moyenne mobile exponentielle complexe (CEMA), la couche de normalisation du pas de temps, le mécanisme d'attention normalisé et le pré -connexion résiduelle normalisée avec deux fonctionnalités.

En comparaison directe avec LAMA2, MEGALODON atteint une meilleure efficacité que Transformer à une échelle de 7 milliards de paramètres et 2 000 milliards de jetons d'entraînement. La perte d'entraînement de MEGALODON atteint 1,70, soit entre LAMA2-7B (1,75) et 13B (1,67). Les améliorations de MEGALODON par rapport à Transformers montrent de solides performances sur une gamme de tests de performances et sur différentes tâches et modalités.
MEGALODON est essentiellement une architecture MEGA améliorée (Ma et al., 2023), qui utilise le mécanisme d'attention fermée et la méthode classique de moyenne mobile exponentielle (EMA). Afin d'améliorer encore les capacités et l'efficacité de MEGALODON dans le cadre d'une pré-formation à grande échelle en contexte long, les auteurs ont proposé une variété de composants techniques. Premièrement, MEGALODON introduit un composant de moyenne mobile exponentielle complexe (CEMA) qui étend l'EMA amortie multidimensionnelle dans MEGA au domaine complexe. Deuxièmement, MEGALODON propose une couche de normalisation par pas de temps, qui généralise les couches de normalisation de groupe aux tâches de modélisation de séquence autorégressive pour permettre la normalisation le long de la dimension séquentielle.
Afin d'améliorer la stabilité du pré-entraînement à grande échelle, MEGALODON propose en outre une attention normalisée, ainsi qu'une pré-normalisation avec une configuration résiduelle à deux sauts en modifiant les méthodes de pré-normalisation et de post-normalisation largement adoptées. En découpant simplement la séquence d'entrée en morceaux fixes, comme cela est fait dans MEGA-chunk, MEGALODON atteint une complexité de calcul et de mémoire linéaire dans la formation et l'inférence de modèles.
Dans une comparaison directe avec LAMA2, tout en contrôlant les données et les calculs, MEGALODON-7B surpasse considérablement la variante de pointe du Transformer utilisée pour entraîner LLAMA2-7B en termes de perplexité d'entraînement. Les évaluations sur la modélisation de contextes longs, y compris la perplexité dans diverses longueurs de contexte allant jusqu'à 2 M et les tâches d'assurance qualité à contexte long dans Scrolls, démontrent la capacité de MEGALODON à modéliser des séquences de longueur infinie. Des résultats expérimentaux supplémentaires sur des benchmarks de petite et moyenne taille, notamment LRA, ImageNet, Speech Commands, WikiText-103 et PG19, démontrent les capacités de MEGALODON en termes de volume et de multimodalité.
Introduction à la méthode
Tout d'abord, l'article passe brièvement en revue les composants clés de l'architecture MEGA (Moving Average Equipé Gated Attention) et aborde les problèmes existant dans MEGA.
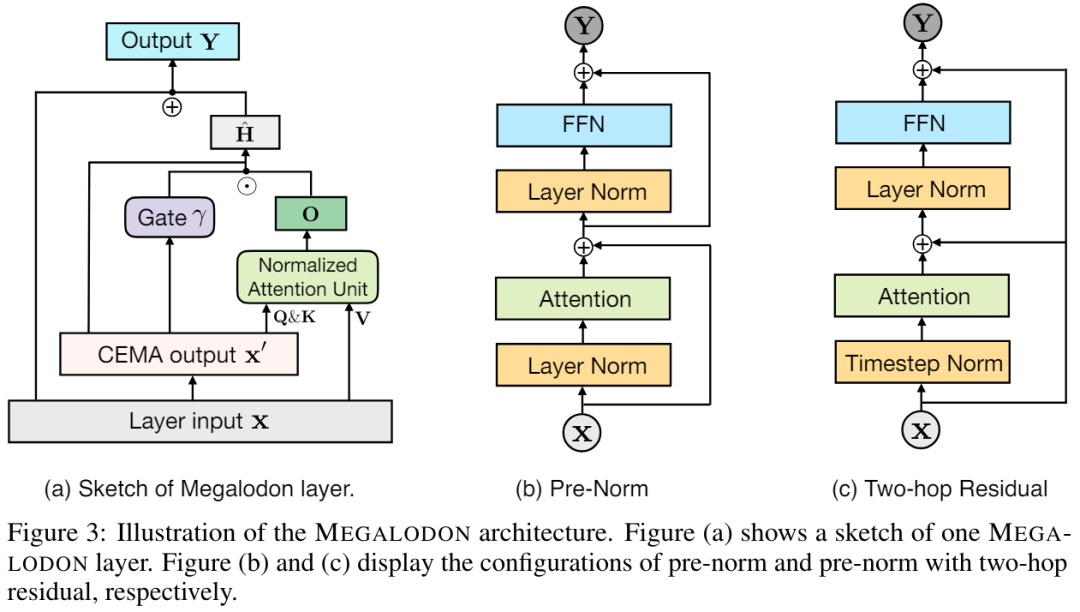
MEGA intègre un composant EMA (moyenne mobile exponentielle) dans le calcul de la matrice d'attention pour intégrer un biais inductif sur toutes les dimensions du pas de temps. Plus précisément, l'EMA amorti multidimensionnel élargit d'abord chaque dimension de la séquence d'entrée. La forme est la suivante : 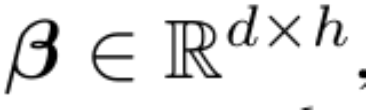
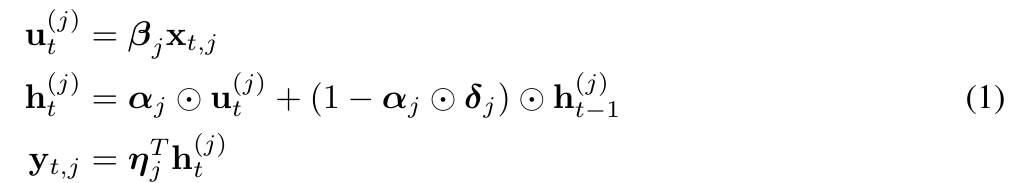
Techniquement parlant, la sous-couche EMA de MEGA permet de capturer des informations contextuelles locales à proximité de chaque jeton, atténuant ainsi le problème de perte d'informations dans le contexte au-delà des limites des blocs. Bien que MEGA obtienne des résultats impressionnants, il est confronté aux problèmes suivants :
i) En raison de la puissance d'expression limitée de la sous-couche EMA dans MEGA, les performances de MEGA avec une attention au niveau du bloc sont toujours en retard par rapport à celles de MEGA à pleine attention.
ii) Pour différentes tâches et types de données, il peut y avoir des différences architecturales dans l'architecture MEGA finale, telles que différentes couches de normalisation, modes de normalisation et fonctions d'attention f (・).
iii) Il n'existe aucune preuve empirique que MEGA s'adapte à la pré-formation à grande échelle.


CEMA : Extension de l'amortissement multidimensionnel EMA au domaine complexe
Pour résoudre les problèmes rencontrés par MEGA, cette recherche propose MEGALODON.
Plus précisément, ils ont proposé de manière créative la moyenne mobile exponentielle complexe CEMA (moyenne mobile exponentielle complexe), en réécrivant l'équation ci-dessus (1) sous la forme suivante :
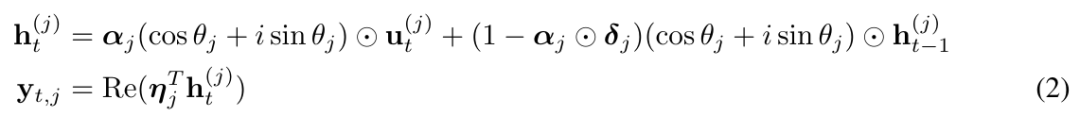
et en paramétrant θ_j dans (2) comme :
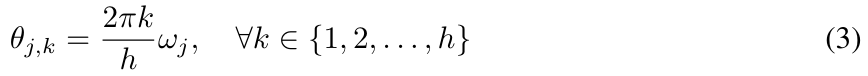
Normalisation du pas de temps
Bien que les performances de la normalisation des couches combinées avec Transformer soient impressionnantes, il est évident que la normalisation des couches ne peut pas réduire directement le long de la dimension spatiale (le décalage de covariable interne est également appelé pas de temps ou dimension de séquence).
Dans MEGALODON, cette étude étend la normalisation de groupe au cas autorégressif en calculant la moyenne et la variance cumulées.
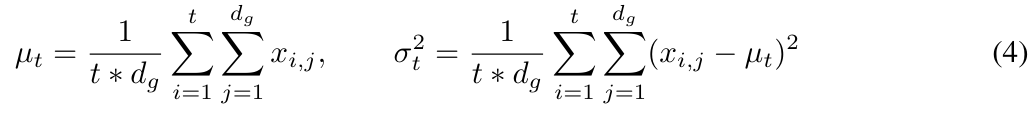
La figure 2 illustre la normalisation des couches et la normalisation des pas de temps.
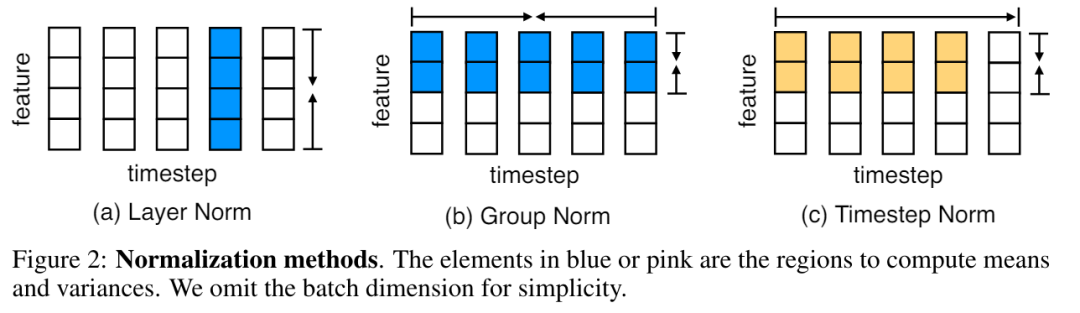
Attention normalisée chez MEGALODON
De plus, la recherche propose également un mécanisme d'attention normalisé spécifiquement personnalisé pour MEGA afin d'améliorer sa stabilité. La forme est la suivante :

Ensuite, l'opération d'attention dans l'équation (17) ci-dessus est modifiée en :

Pré-norme avec résidu à deux sauts
L'enquête révèle que, L'augmentation de la taille du modèle peut entraîner une instabilité de prénormalisation. La pré-normalisation basée sur le bloc Transformer peut être exprimée comme suit (illustré sur la figure 3 (b)) :

Dans l'architecture MEGA originale, φ (19) est utilisé pour la connexion résiduelle fermée (21 ) pour atténuer ce problème. Cependant, la porte de mise à jour φ introduit davantage de paramètres de modèle et le problème d'instabilité persiste lorsque la taille du modèle est étendue à 7 milliards. MEGALODON introduit une nouvelle configuration appelée pré-norme avec des résidus à deux sauts, qui réorganise simplement les connexions résiduelles dans chaque bloc, comme le montre la figure 3(c) :
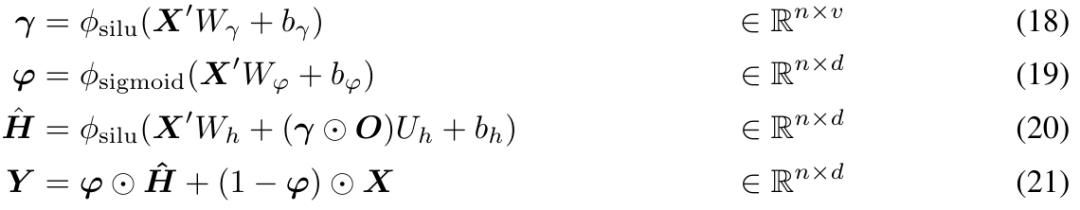
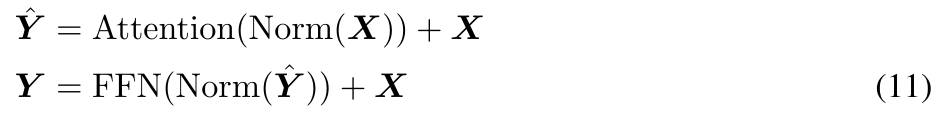
Expériences
Afin de Évaluant l'évolutivité et l'efficacité de MEGALODON dans la modélisation de séquences à contexte long, cet article étend MEGALODON à une échelle de 7 milliards.
Pré-formation LLM
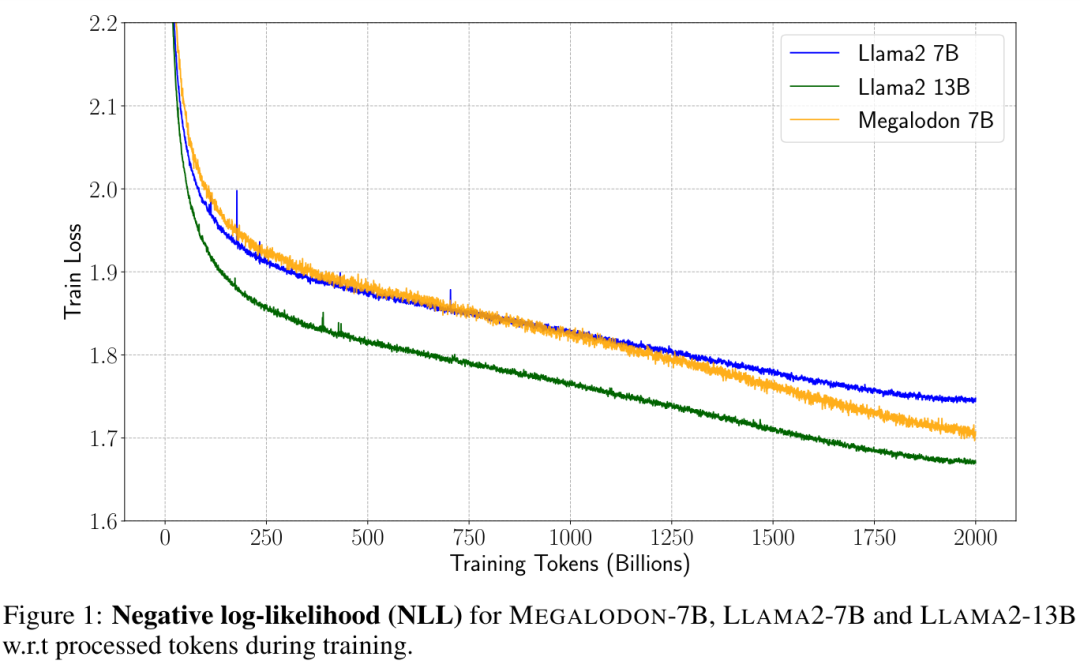
Afin d'améliorer l'efficacité des données, les chercheurs ont montré la vraisemblance log négative (NLL) de MEGALODON-7B, LAMA2-7B et LAMA2-13B pendant le processus de formation, comme le montre la figure 1.
Avec le même nombre de jetons d'entraînement, MEGALODON-7B a obtenu un NLL nettement meilleur (inférieur) que LLAMA2-7B, montrant une meilleure efficacité des données.
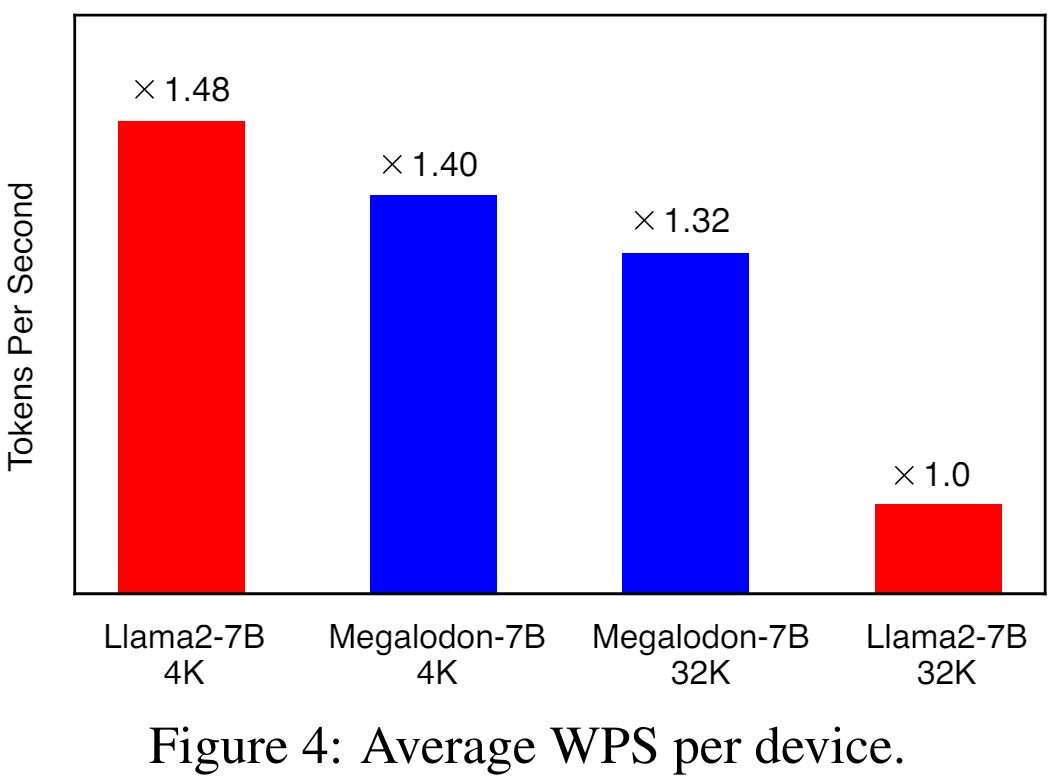
La figure 4 illustre le WPS moyen (mot/jeton par seconde) par appareil pour LAMA2-7B et MEGALODON-7B en utilisant respectivement des longueurs de contexte de 4K et 32K. Pour le modèle LLAMA2, l'étude utilise Flash-Attention V2 pour accélérer le calcul de la pleine attention. Avec une longueur de contexte 4K, MEGALODON-7B est légèrement plus lent (~ 6 %) que LLAMA2-7B en raison de l'introduction du CEMA et de la normalisation du pas de temps. En étendant la longueur du contexte à 32 Ko, MEGALODON-7B est nettement plus rapide que LAMA2-7B (environ 32 %), ce qui démontre l'efficacité informatique de MEGALODON pour le pré-entraînement à long contexte.
Évaluation contextuelle courte
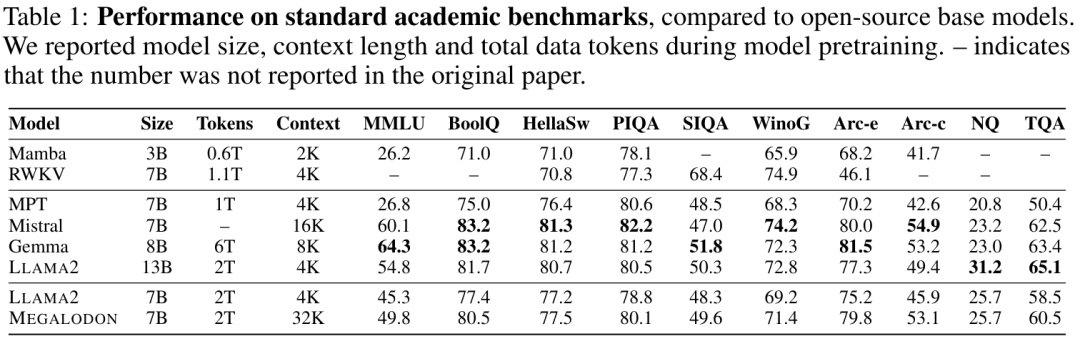
Le tableau 1 résume les résultats de MEGALODON et LLAMA2 sur des critères académiques, ainsi que les résultats de comparaison d'autres modèles de base open source, notamment MPT, RWKV, Mamba, Mistral et Gemma. Après un pré-entraînement sur les mêmes jetons 2T, MEGALODON-7B surpasse LLAMA2-7B sur tous les benchmarks. Sur certaines tâches, les performances de MEGALODON-7B sont comparables, voire meilleures, à celles de LAMA2-13B.
Évaluation du contexte long
La figure 5 montre la perplexité (PPL) de l'ensemble de données de validation sous différentes longueurs de contexte allant de 4K à 2M. On peut observer que le PPL diminue de façon monotone avec la longueur du contexte, validant l'efficacité et la robustesse de MEGALODON dans la modélisation de séquences extrêmement longues.
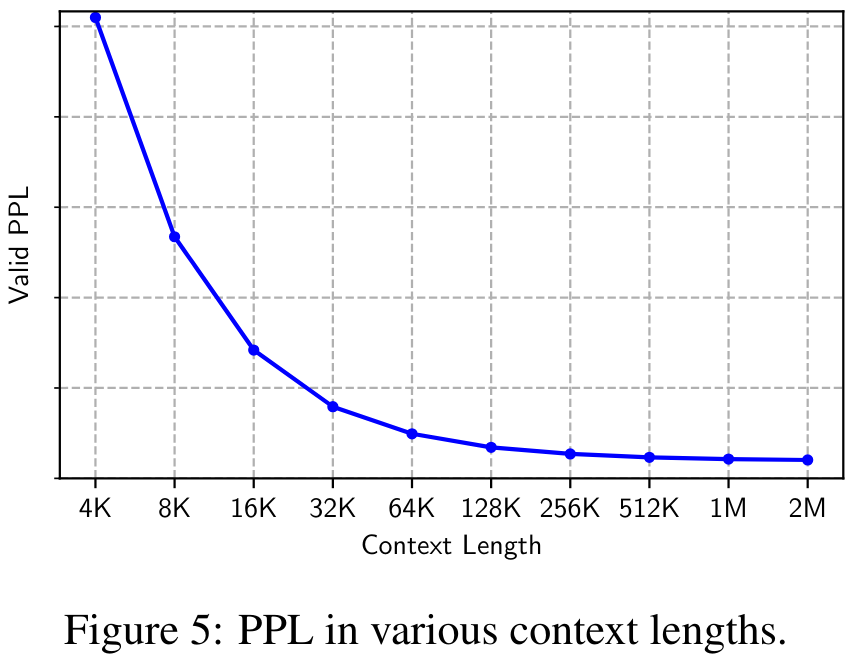
Réglage fin des instructions
Le tableau 3 résume les performances du modèle 7B sur MT-Bench. MEGALODON présente des performances supérieures sur MT-Bench par rapport à Vicuna et est comparable à LLAMA2-Chat, qui utilise RLHF pour un réglage plus précis de l'alignement.
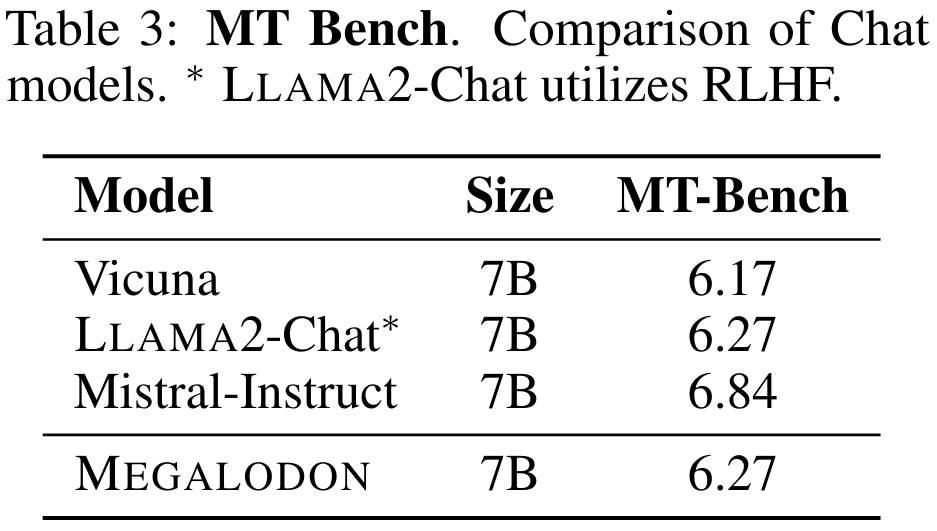
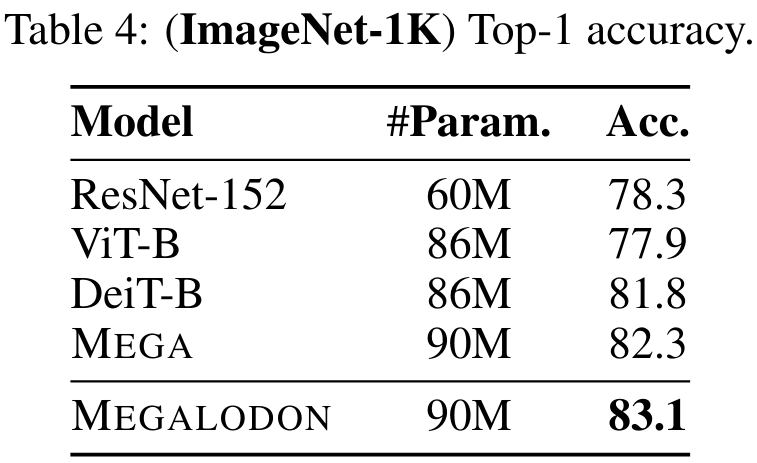
Évaluation de référence à moyenne échelle
Pour évaluer les performances de MEGALODON sur les tâches de classification d'images, l'étude a mené des expériences sur l'ensemble de données Imagenet-1K. Le tableau 4 indique la précision Top-1 sur l'ensemble de validation. La précision de MEGALODON est 1,3 % supérieure à celle de DeiT-B et 0,8 % supérieure à celle de MEGA.
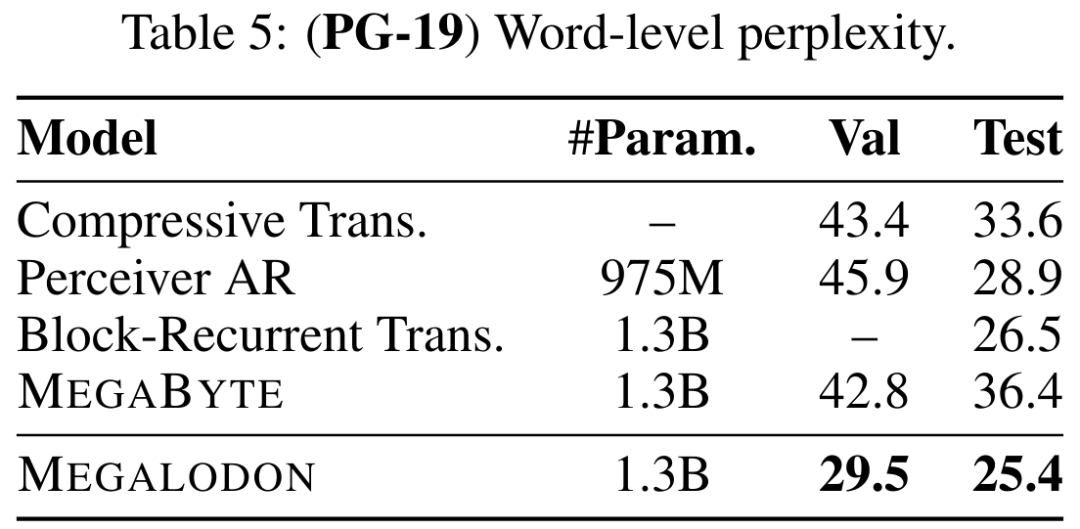
Le Tableau 5 illustre la perplexité au niveau des mots (PPL) de MEGALODON sur PG-19 et la comparaison avec les modèles de pointe précédents, notamment Compressive Transformer, Perceiver AR, Perceiver AR, Block Loop Transformer. et MÉGABYTE, etc. Les performances de MEGALODON sont clairement en avance.
Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!