
Maison >Périphériques technologiques >IA >Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !
Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-15 09:01:011370parcourir
Ollama est un outil super pratique qui vous permet d'exécuter facilement des modèles open source tels que Llama 2, Mistral et Gemma localement. Dans cet article, je vais vous présenter comment utiliser Ollama pour vectoriser du texte. Si Ollama n’est pas installé localement, vous pouvez lire cet article.
Dans cet article, nous utiliserons le modèle nomic-embed-text[2]. Il s'agit d'un encodeur de texte qui surpasse OpenAI text-embedding-ada-002 et text-embedding-3-small sur les tâches à contexte court et à contexte long.
Démarrez le service nomic-embed-text
Après avoir installé avec succès ollama, utilisez la commande suivante pour extraire le modèle nomic-embed-text :
ollama pull nomic-embed-text
Après avoir réussi à extraire le modèle, entrez la commande suivante dans le terminal , démarrez le service ollama :
ollama serve
Après cela, nous pouvons utiliser curl pour vérifier si le service d'intégration fonctionne normalement :
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Utilisez le service nomic-embed-text
Ensuite, nous présenterons comment pour utiliser langchainjs et le service nomic -embed-text, qui implémente les opérations d'intégration sur les documents txt locaux. Le processus correspondant est illustré dans la figure ci-dessous :
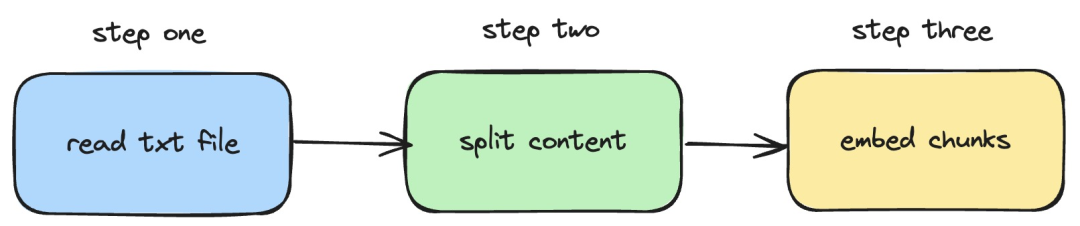 Pictures
Pictures
1. Lisez le fichier txt local
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}Dans le code ci-dessus, nous avons défini une fonction de chargement, qui utilise en interne le TextLoader fourni par langchainjs pour lire Obtenir le document txt local.
2. Divisez le contenu txt en blocs de texte
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}Dans le code ci-dessus, nous utilisons RecursiveCharacterTextSplitter pour couper le texte txt lu et définir la taille de chaque bloc de texte à 500.
3. Effectuer une opération d'intégration sur des blocs de texte
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}Dans le code ci-dessus, nous définissons une fonction d'intégration, dans laquelle les fonctions de chargement et de fractionnement précédemment définies sont appelées. Parcourez ensuite le bloc de texte généré et appelez le service d'intégration nomic-embed-text démarré localement. La fonction sendRequest est utilisée pour envoyer des requêtes d'intégration. Son code d'implémentation est très simple, qui consiste à utiliser l'API fetch pour appeler l'API REST existante.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Ensuite, nous continuons à définir une fonction embedTxtFile, appelons directement la fonction d'intégration existante à l'intérieur de la fonction et ajoutons la gestion des exceptions correspondante.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Enfin, nous utilisons la commande npx esno src/index.ts pour exécuter rapidement le fichier ts local. Si le code dans index.ts est exécuté avec succès, les résultats suivants seront affichés dans le terminal :
 Pictures
Pictures
En fait, en plus d'utiliser la méthode ci-dessus, nous pouvons également utiliser directement [OllamaEmbeddings dans le @ langchain/community module ](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings") objet, qui encapsule en interne la logique d'appel du service d'intégration ollama :
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);Le contenu introduit dans cet article implique le développement du système RAG, le processus d'établissement d'un index de contenu d'une base de connaissances. Si vous ne connaissez pas le système RAG, vous pouvez lire des articles connexes.
Références
[1]Ollama : https://ollama.com/
[2]nomic-embed-text : https://ollama.com/library/nomic-embed-text
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La différence entre has et with dans le modèle d'association Laravel (introduction détaillée)
- Qu'est-ce qu'un modèle de développement logiciel et quels sont les modèles de développement logiciels courants ?
- Quels sont les modèles courants de développement de logiciels ?
- À quel modèle la structure du réseau à 7 couches fait-elle référence ?
- Comment copier un modèle dans un autre fichier dans 3dmax