
Maison >Périphériques technologiques >IA >Comprenez la tokenisation en un seul article !
Comprenez la tokenisation en un seul article !

- PHPzavant
- 2024-04-12 14:31:261112parcourir
Les modèles linguistiques raisonnent sur le texte, qui se présente généralement sous la forme de chaînes, mais l'entrée du modèle ne peut être que des nombres, le texte doit donc être converti sous forme numérique.
La tokenisation est une tâche de base du traitement du langage naturel. Elle peut diviser une séquence de texte continue (telle que des phrases, des paragraphes, etc.) en une séquence de caractères (telle que des mots, des phrases, des caractères, des signes de ponctuation, etc.) selon des critères spécifiques. besoins. Parmi eux L'unité est appelée un jeton ou un mot.
Selon le processus spécifique illustré dans la figure ci-dessous, divisez d'abord les phrases de texte en unités, puis numérisez les éléments individuels (mappez-les en vecteurs), puis entrez ces vecteurs dans le modèle pour l'encodage, et enfin envoyez-les vers des tâches en aval. pour obtenir davantage le résultat final.
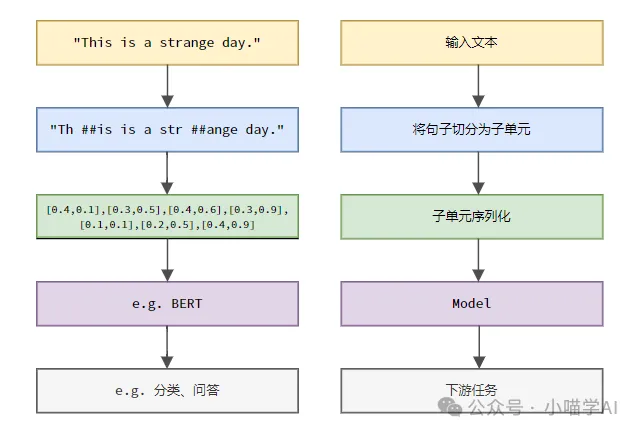
Segmentation de texte
Selon la granularité de la segmentation du texte, la tokenisation peut être divisée en trois catégories : la tokenisation granulaire des mots, la tokenisation granulaire des caractères et la tokenisation granulaire des sous-mots.
1. Tokenisation de la granularité des mots
Granularité des mots La tokenisation est la méthode de segmentation de mots la plus intuitive, ce qui signifie segmenter le texte en fonction des mots du vocabulaire. Par exemple :
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
Dans cet exemple, le texte est divisé en mots indépendants, chaque mot est utilisé comme un jeton et le signe de ponctuation '.' est également considéré comme un jeton indépendant.
Les textes chinois sont généralement segmentés sur la base de collections de vocabulaire standard collectées dans des dictionnaires ou des expressions, des expressions idiomatiques, des noms propres, etc. identifiées grâce à des algorithmes de segmentation de mots.
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
Ce texte chinois est divisé en cinq mots : "Je", "j'aime", "manger", "pomme" et point ".", chaque mot sert de jeton.
2. Tokenisation granulaire des caractères
La tokenisation granulaire des caractères divise le texte en unités de caractères les plus petites, c'est-à-dire que chaque caractère est traité comme un jeton distinct. Par exemple :
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
Granularité des caractères La tokenisation en chinois consiste à segmenter le texte en fonction de chaque caractère chinois indépendant.
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
3.subword granular Tokenization
subword granular Tokenization se situe entre la granularité des mots et la granularité des caractères. Elle divise le texte en sous-mots (sous-mots) entre les mots et les caractères en tant que jetons. Les méthodes courantes de tokenisation de sous-mots incluent le codage par paire d'octets (BPE), WordPièce, etc. Ces méthodes génèrent automatiquement un dictionnaire de segmentation de mots en comptant les fréquences de sous-chaînes dans les données texte, ce qui permet de résoudre efficacement le problème des mots hors service (OOV) tout en conservant une certaine intégrité sémantique.
helloworld
Supposons qu'après un entraînement avec l'algorithme BPE, le dictionnaire de sous-mots généré contienne les entrées suivantes :
h, e, l, o, w, r, d, hel, low, wor, orld
Granularité des sous-mots Résultats tokenisés :
['hel', 'low', 'orld']
Ici, "helloworld" est divisé en trois sous-mots" " hel", "low", "orld", ce sont toutes des combinaisons de sous-chaînes à haute fréquence qui apparaissent dans les dictionnaires. Cette méthode de segmentation peut non seulement gérer des mots inconnus (par exemple, « helloworld » n'est pas un mot anglais standard), mais également conserver certaines informations sémantiques (la combinaison de sous-mots peut restaurer le mot original).
En chinois, la tokenisation granulaire des sous-mots divise également le texte en sous-mots entre les caractères chinois et les mots en tant que jetons. Par exemple :
我喜欢吃苹果
Supposons qu'après un entraînement avec l'algorithme BPE, le dictionnaire de sous-mots généré contienne les entrées suivantes :
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
Granularité des sous-mots Résultats tokenisés :
['我', '喜欢', '吃', '苹果']
Dans cet exemple, "J'aime manger pommes" Il est divisé en quatre sous-mots "Je", "aimer", "manger" et "pomme", et ces sous-mots apparaissent tous dans le dictionnaire. Bien que les caractères chinois ne soient pas combinés comme les sous-mots anglais, la méthode de tokenisation des sous-mots a pris en compte des combinaisons de mots à haute fréquence, telles que « J'aime » et « manger des pommes » lors de la génération du dictionnaire. Cette méthode de segmentation conserve les informations sémantiques au niveau des mots tout en traitant les mots inconnus.
Indexation
Supposons qu'un corpus ou un vocabulaire ait été créé comme suit.
vocabulary = {'我': 0,'喜欢': 1,'吃': 2,'苹果': 3,'。': 4}peut retrouver l'index de chaque jeton dans la séquence dans le vocabulaire.
indexed_tokens = [vocabulary[token] for token in token_sequence]print(indexed_tokens)
Sortie : [0, 1, 2, 3, 4].
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Où se trouve l'emplacement de stockage des e-mails Foxmail ?
- Quel est l'emplacement de la fonction principale dans le programme source c ?
- Que signifie l'adresse e-mail ?
- Une revue récemment publiée des modèles linguistiques à grande échelle : la revue la plus complète de T5 à GPT-4, rédigée conjointement par plus de 20 chercheurs nationaux
- Meta AI ouvre plus de 600 millions de cartes de structure de protéines métagénomiques et 15 milliards de modèles de langage ont été réalisés en deux semaines