
Maison >Périphériques technologiques >IA >APISR, un modèle d'IA dédié bidimensionnel super-résolution : disponible en ligne, sélectionné par CVPR
APISR, un modèle d'IA dédié bidimensionnel super-résolution : disponible en ligne, sélectionné par CVPR

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-07 17:07:091198parcourir
Les œuvres d'animation telles que "Dragon Ball", "Pokémon", "Neon Genesis Evangelion" et d'autres animations diffusées au siècle dernier font partie des souvenirs d'enfance de nombreuses personnes. Elles nous ont apporté des visions pleines de passion, d'amitié et de rêves. voyage de. À un moment donné, nous aurons soudain envie de revisiter ces souvenirs d'enfance, mais nous constaterons peut-être avec regret que le taux de reconnaissance de ces souvenirs d'enfance est très faible et qu'il est impossible de créer une bonne expérience visuelle sur un téléviseur grand écran, de sorte que cela nous gêne. Partagez ces souvenirs d'enfance avec des enfants qui grandissent dans un monde numérique avec une résolution HD.
Pour ce genre de concurrence vicieuse (et de marché potentiel), une solution consiste à demander à une société d'animation de produire un remake. Cette tâche sera coûteuse en termes humains et financiers, mais elle vaut peut-être mieux que d’ignorer le problème et de perdre des parts de marché.
Les performances de l'intelligence artificielle multimodale deviennent de plus en plus puissantes, et l'utilisation de la technologie de super-résolution basée sur l'IA pour améliorer la résolution de l'animation est devenue une direction qui mérite d'être explorée. Cette technologie peut reconstruire des images haute résolution à partir d’un petit nombre d’images basse résolution, rendant ainsi les images d’animation plus claires et plus détaillées. Cette méthode utilise la profondeur en entraînant un grand nombre d'échantillons de données.
Récemment, une équipe conjointe de l'Université du Michigan, de l'Université de Yale et de l'Université du Zhejiang a créé un ensemble de nouvelles méthodes très pratiques pour les tâches d'animation en super-résolution en analysant le processus de production d'animation. . méthode. Cela inclut des ensembles de données, des modèles et quelques améliorations. Cette recherche a été acceptée dans la conférence CVPR 2024. L'équipe a également ouvert le code correspondant et lancé un modèle d'essai sur Huggingface.

Titre de l'article : APISR : Anime Production Inspired Real-World Anime Super-Resolution
Adresse de l'article : https://arxiv.org/pdf/2403.01598.pdf
Adresse du code : https ://github.com/Kiteretsu77/APISR
Modèle d'essai : https://huggingface.co/spaces/HikariDawn/APISR
L'image ci-dessous est ce que ce site a essayé en utilisant la capture d'écran du premier épisode de "Dragon Ball" En conséquence, l'effet est visible à l'œil nu.

De plus, certaines personnes ont essayé d'utiliser cette technologie pour améliorer la résolution vidéo, et les résultats sont excellents :
Processus de production d'animation
Afin de comprendre l'innovation de cette nouvelle méthode, Voyons d'abord comment les animes sont généralement créés.
Tout d'abord, un croquis humain sur papier, qui est ensuite coloré et amélioré grâce au traitement d'images générées par ordinateur (CGI). Ces croquis traités sont ensuite connectés pour créer une vidéo.
Cependant, étant donné que le processus de dessin demande beaucoup de travail et que l'œil humain n'est pas sensible au mouvement, lors de la composition de vidéos, la pratique standard de l'industrie consiste à réutiliser une seule image pour plusieurs images consécutives.
En analysant ce processus, l'équipe commune n'a pu s'empêcher de se demander s'il est nécessaire d'utiliser des modèles vidéo et des ensembles de données vidéo pour entraîner des modèles d'animation en super-résolution : il est tout à fait possible d'effectuer une super-résolution sur des images puis de se connecter ces images !
Ils ont donc décidé d'utiliser des méthodes et des ensembles de données basés sur des images pour créer un cadre unifié de super-résolution et de restauration adapté aux images et aux vidéos.
Nouvelle méthode proposée
Ensemble de données d'image de super-résolution (API SR) pour la production d'animation
L'équipe a proposé l'ensemble de données API SR Voici une brève introduction à sa méthode de collecte et d'organisation. Cette méthode tire parti des caractéristiques des vidéos d'animation (voir Figure 2) et peut sélectionner les images les moins compressées et les plus informatives de la vidéo.

Collection d'images basée sur I-frame : la compression vidéo implique un compromis entre la qualité de la vidéo et la taille des données. Il existe désormais de nombreuses normes de compression vidéo, chacune avec son propre système d'ingénierie complexe, mais elles ont toutes une conception de base similaire.
Ces caractéristiques font que la qualité de compression de chaque image est différente. Le processus de compression vidéo désigne un certain nombre d’images clés (c’est-à-dire les images I) comme unités de compression individuelles. En pratique, la I-frame est la première image lorsque la scène change. Ces images I peuvent occuper une grande quantité de données. Les images non I (c'est-à-dire les images P et B) ont des taux de compression plus élevés. Elles doivent utiliser l'image I comme référence pendant le processus de compression pour introduire des changements au fil du temps. Comme le montre la figure 3a, dans les vidéos d'animation collectées par l'équipe, la taille des données des images I est généralement supérieure à celle des images non-I, et la qualité des images I est en effet supérieure. Par conséquent, l’équipe a utilisé l’outil de traitement vidéo ffmpeg pour extraire toutes les images I de la source vidéo et les utiliser comme pool de données initial.
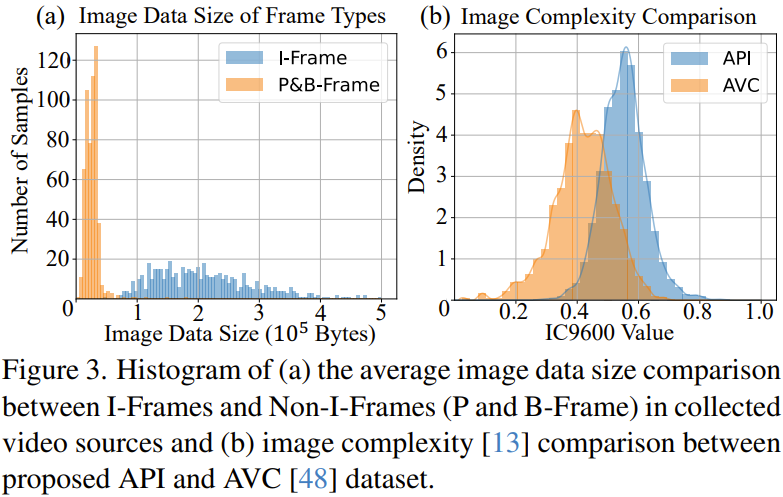
Sélection basée sur la complexité de l'image : l'équipe a examiné le pool initial d'images I sur la base de l'évaluation de la complexité de l'image (ICA), qui est une métrique plus adaptée à l'animation, voir Figure 4.

Ensemble de données API : l'équipe a collecté manuellement 562 vidéos d'anime de haute qualité. Les 10 images les plus performantes de chaque vidéo ont ensuite été collectées sur la base des deux étapes ci-dessus. Ensuite, un certain filtrage a été effectué pour supprimer les images inappropriées, et finalement un ensemble de données contenant 3 740 images de haute qualité a été obtenu. La figure 5 montre quelques exemples d'images. De plus, nous pouvons également voir les avantages de l'ensemble de données API en termes de complexité d'image à partir de la figure 3b.

Retour à la résolution originale 720P : En étudiant le processus de production d'animation, nous pouvons voir que la plupart des productions d'animation utilisent le format 720P (c'est-à-dire que l'image fait 720 pixels de haut). Cependant, dans des scénarios réels, les dessins animés sont souvent convertis par erreur en 1080P ou dans d’autres formats dans le but de standardiser les formats multimédias. L’équipe a découvert expérimentalement que le redimensionnement de toutes les images d’anime en 720P natif fournissait la densité de fonctionnalités envisagée par les créateurs, ainsi que des lignes d’anime plus serrées dessinées à la main et des informations CGI.
Un modèle de dégradation pratique pour l'animation
Dans les tâches de super-résolution du monde réel, la conception du modèle de dégradation est très importante. Sur la base de modèles de dégradation d'ordre élevé et d'un récent modèle de récupération par compression vidéo basé sur l'image, l'équipe a proposé deux améliorations permettant de restaurer des lignes déformées dessinées à la main et divers artefacts de compression, et également d'améliorer la représentation du modèle de dégradation. La figure 6a illustre ce modèle de dégradation.
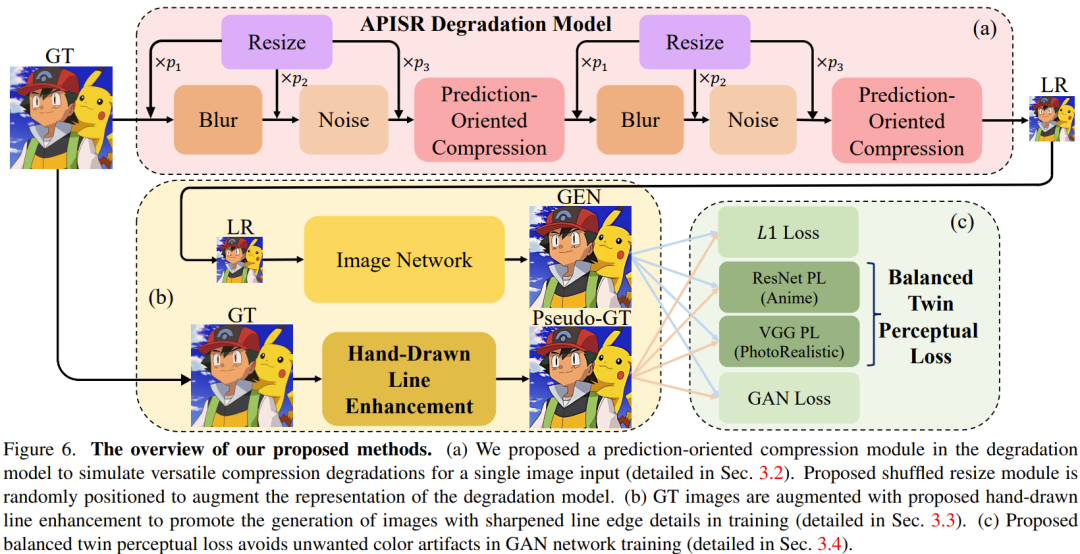
Compression orientée prédiction : pour la tâche de récupération d'animation d'artefacts de compression vidéo, l'utilisation de modèles de dégradation d'image pose un problème difficile. En effet, la méthode de compression du format d'image JPEG et le principe de compression vidéo sont différents.
Pour faire face à de telles difficultés, l'équipe a conçu un modèle de compression orienté prédiction utilisé dans le modèle de dégradation d'image. Ce module nécessite un algorithme de compression vidéo pour compresser une seule image d'entrée.
Avec cette approche, le modèle de dégradation d'image est capable de synthétiser des artefacts de compression similaires à ceux observés dans la compression vidéo multi-images typique, comme le montre la figure 7. Ensuite, en alimentant ces images synthétisées dans un réseau d’images à super-résolution, le système peut apprendre efficacement les modèles de divers artefacts de compression et les récupérer.

Mélangez l'ordre des modules de redimensionnement : les modèles dégénérés dans le domaine de la super-résolution du monde réel doivent prendre en compte les modules de flou, de redimensionnement, de bruit et de compression. Le flou, le bruit et la compression sont des artefacts du monde réel qui peuvent être synthétisés au moyen de modèles mathématiques ou d'algorithmes clairs. Cependant, la logique du module de redimensionnement est complètement différente. Le redimensionnement ne fait pas partie de la génération naturelle d'images mais est introduit spécifiquement pour la super-résolution des ensembles de données par paires. Par conséquent, le précédent module de redimensionnement à taille fixe n’était pas très adapté. L'équipe a proposé une solution plus robuste et plus efficace qui consiste à placer de manière aléatoire les opérations de redimensionnement dans différents ordres au sein du modèle dégénéré.
Améliorer les lignes dessinées à la main pour l'animation
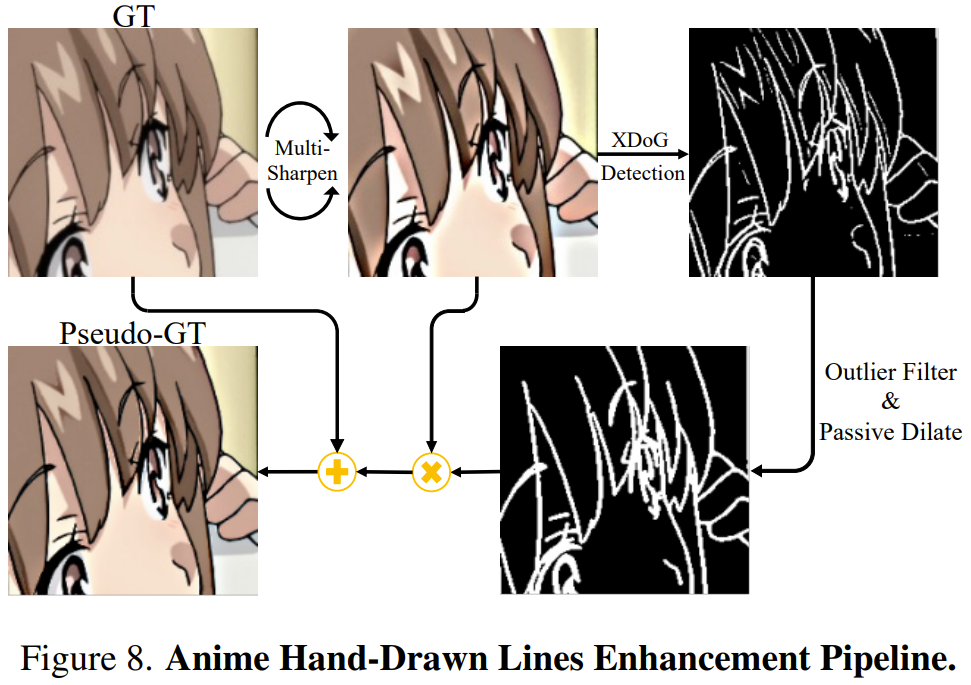
Le choix de l'équipe est d'extraire directement les informations de ligne dessinées à la main et de les fusionner avec la vérité terrain (GT/ground-truth) pour former une pseudo-GT. En introduisant ce pseudo-GT amélioré spécifiquement ciblé dans le processus de formation en super-résolution, le réseau peut générer des lignes nettes dessinées à la main sans introduire de modules de réseau neuronal supplémentaires ni de réseaux de post-traitement séparés.
Pour mieux extraire les lignes dessinées à la main, l'équipe a utilisé XDoG, un algorithme d'extraction de croquis basé sur un noyau gaussien pixel par pixel, qui peut extraire des cartes aux bords nets de GT.
Cependant, les cartes de contour XDoG souffrent d'un bruit excessif, contenant des pixels aberrants et des représentations en lignes brisées. Pour résoudre ce problème, l’équipe a proposé une technique de filtrage des valeurs aberrantes associée à une méthode de dilatation passive conçue sur mesure. De cette manière, une représentation plus cohérente et plus fluide des lignes dessinées à la main est obtenue.
L'équipe a découvert expérimentalement qu'un GT prétraité trop aiguisé peut rendre les bords de ligne dessinés à la main plus visibles que d'autres détails de bord d'ombre non pertinents, permettant ainsi au filtre aberrant de discerner plus facilement leurs différences. Pour ce faire, l’équipe a proposé d’effectuer d’abord trois séries d’opérations de masquage et de désaffûtage sur GT. La figure 8 donne une illustration simple de ce processus.
Double perte de perception équilibrée pour l'animation
Il existe également le problème des artefacts de couleur indésirables, principalement dus aux incohérences du domaine de données en formation entre le générateur et la perte de perception.
Afin de résoudre ce problème et de combler les lacunes des méthodes précédentes, l'approche de l'équipe a consisté à utiliser un ResNet pré-entraîné, qui a été formé sur la tâche de classification des cibles d'animation sur l'ensemble de données Danbooru. L'ensemble de données Danbooru est une base de données d'illustrations d'anime contenant des annotations volumineuses et riches. Étant donné que ce réseau pré-entraîné est ResNet50 au lieu de VGG, l'équipe a également proposé une comparaison similaire de couche intermédiaire.
Cependant, si vous utilisez uniquement des pertes basées sur ResNet, vous risquez de souffrir de mauvais résultats visuels. Cela est dû au biais inhérent à l'ensemble de données Danbooru : la plupart des images de cet ensemble de données sont des visages humains ou des illustrations relativement simples. Par conséquent, l’équipe a pris la décision d’utiliser des fonctionnalités du monde réel comme auxiliaire pour guider la perte de perception basée sur ResNet pendant l’entraînement. Cette méthode produit des images visuellement agréables tout en résolvant le problème des couleurs indésirables.
Expérience
Détails de mise en œuvre
Dans l'expérience, l'équipe a utilisé l'ensemble de données API nouvellement proposé comme ensemble de données de formation pour le réseau d'images. Quant au réseau d’images, une petite version de GRL est utilisée avec un module de suréchantillonnage convolutif le plus proche.
Veuillez vous référer au document original pour plus de détails et de paramètres.
Comparaison avec les meilleures méthodes actuelles
L'équipe a comparé quantitativement et qualitativement l'APISR nouvellement proposé avec d'autres méthodes avancées, notamment Real-ESRGAN, BSRGAN, RealBasicVSR, AnimeSR et VQD-SR.
Comparaison quantitative
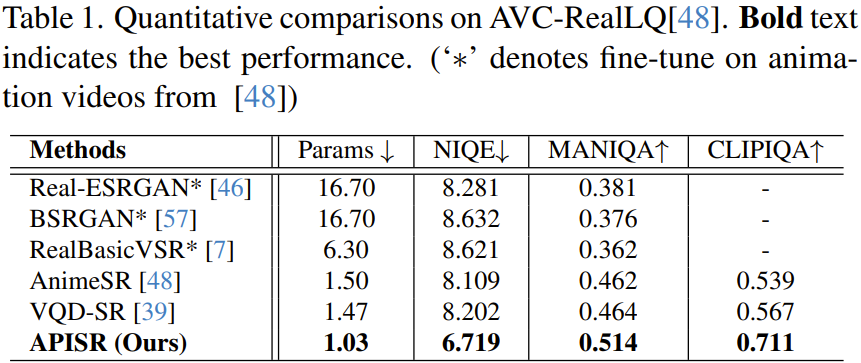
Comme le montre le tableau 1, le nouveau modèle a la plus petite taille de réseau, avec seulement 1,03 million de paramètres, mais ses performances sur tous les indicateurs dépassent toutes les autres méthodes.
L'équipe a particulièrement souligné le rôle des modèles de compression orientés prédiction.
De plus, il convient de souligner que la nouvelle méthode n'a obtenu de tels résultats qu'avec une complexité d'échantillon d'entraînement de 13,3 % et 25 % pour AnimeSR et VQDSR respectivement. Cela est principalement dû à l'introduction de l'évaluation de la complexité des images dans le processus de tri des ensembles de données, ce qui peut améliorer l'effet de l'apprentissage de la représentation des images d'animation en sélectionnant des images riches en informations. De plus, grâce au nouveau modèle de dégradation explicite, aucune formation n'est requise du côté du modèle de dégradation.
Comparaison qualitative
Comme le montre la figure 10, la qualité visuelle obtenue par APISR est bien meilleure que les autres méthodes.

L'équipe a également mené une étude d'ablation pour vérifier l'efficacité du nouvel ensemble de données, du modèle de dégradation et de la conception des pertes. Veuillez consulter l'article original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!