
Maison >Périphériques technologiques >IA >Au-delà de GPT-4, le grand modèle de l'équipe de Stanford qui peut être exécuté sur les téléphones mobiles est devenu populaire, avec plus de 2 000 téléchargements du jour au lendemain.
Au-delà de GPT-4, le grand modèle de l'équipe de Stanford qui peut être exécuté sur les téléphones mobiles est devenu populaire, avec plus de 2 000 téléchargements du jour au lendemain.

- 王林avant
- 2024-04-07 16:19:011466parcourir
Dans le processus de mise en œuvre de grands modèles, l'IA end-side est une direction très importante.
Récemment, Octopus v2 lancé par des chercheurs de l'Université de Stanford est devenu populaire et a reçu une grande attention de la part de la communauté des développeurs. Le modèle a été téléchargé plus de 2 000 fois du jour au lendemain.
Les 2 milliards de paramètres Octopus v2 peuvent fonctionner sur les smartphones, les voitures, les PC, etc., dépassant GPT-4 en termes de précision et de latence, et réduisant la longueur du contexte de 95 %. De plus, Octopus v2 est 36 fois plus rapide que le schéma Llama7B + RAG. 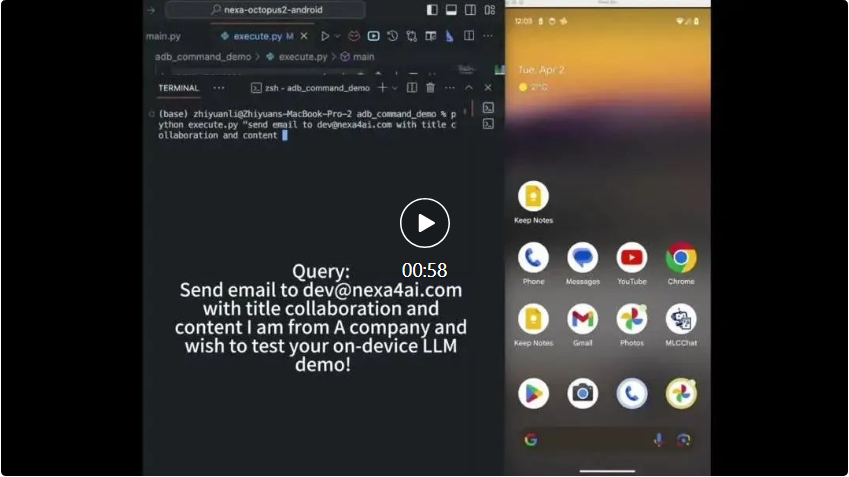

Papier : Octopus v2 : Modèle de langage sur appareil pour super agent
Adresse papier : https://arxiv.org/abs/2404.01744
Page d'accueil du modèle : https://huggingface .co/NexaAIDev/Octopus-v2
Présentation du modèle
Octopus-V2-2B+ est un modèle de langage open source avec 2 milliards de paramètres, adapté à l'API Android. Il fonctionne de manière transparente sur les appareils Android et étend son utilité à une variété d'applications, de la gestion du système Android à l'orchestration de plusieurs appareils.
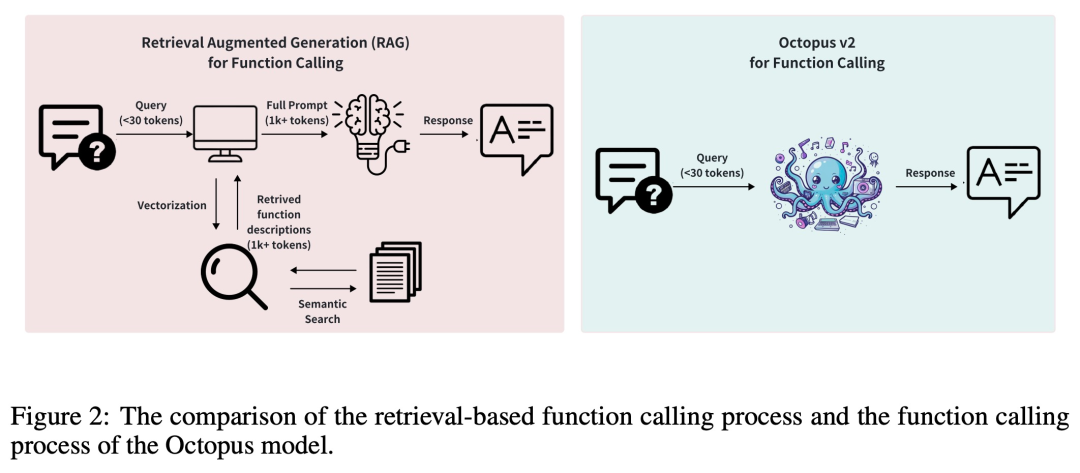
En règle générale, les méthodes de génération augmentée de récupération (RAG) nécessitent des descriptions détaillées des paramètres de fonction potentiels (nécessitant parfois jusqu'à des dizaines de milliers de jetons d'entrée). Sur cette base, Octopus-V2-2B introduit une stratégie de jeton de fonction unique dans les phases de formation et d'inférence, ce qui lui permet non seulement d'atteindre un niveau de performance comparable à GPT-4, mais améliore également considérablement la vitesse d'inférence, dépassant celle basée sur RAG. Cela le rend particulièrement avantageux pour les appareils informatiques de pointe.
Octopus-V2-2B est capable de générer des appels de fonctions individuels, imbriqués et parallèles dans une variété de scénarios complexes.
Dataset
Afin d'adopter des ensembles de données de haute qualité pour les phases de formation, de validation et de test, et surtout d'obtenir une formation efficace, l'équipe de recherche a créé l'ensemble de données en trois étapes clés :
Générer des requêtes pertinentes et leurs arguments d'appel de fonction associés ;
Génération de requêtes non pertinentes par les composants de fonction appropriés ;
Prise en charge de la vérification binaire via Google Gemini.
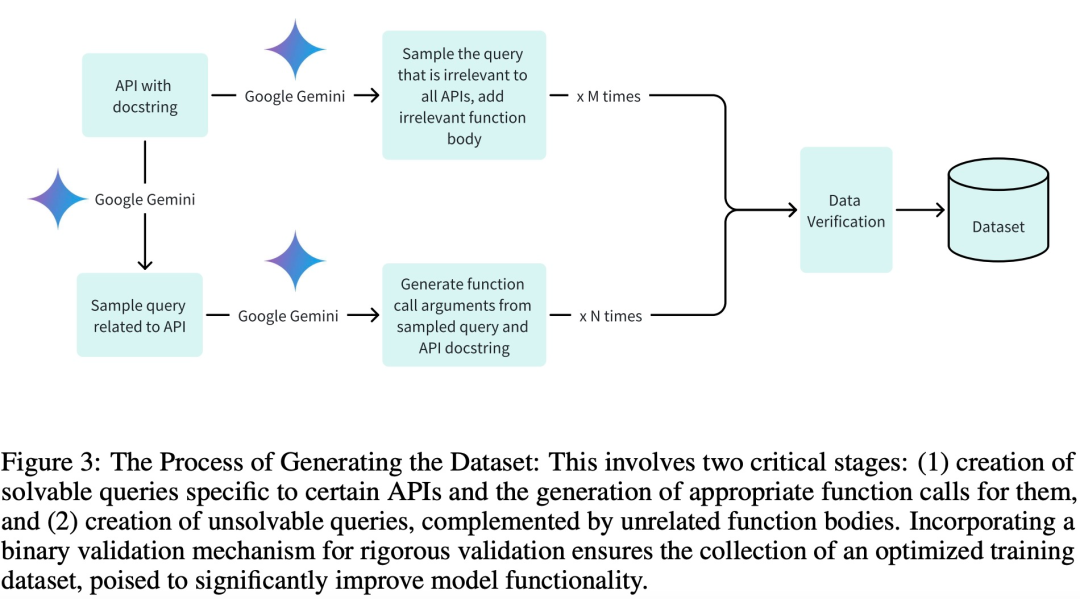
L'équipe de recherche a rédigé 20 descriptions d'API Android pour les modèles de formation. Voici un exemple de description de l'API Android :
def get_trending_news (category=None, region='US', language='en', max_results=5):"""Fetches trending news articles based on category, region, and language.Parameters:- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.Returns:- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL. """
Développement et formation de modèles
Cette étude utilise le modèle Google Gemma-2B comme modèle pré-entraîné dans le cadre et adopte deux méthodes de formation différentes : modèle complet formation et formation sur le modèle LoRA.
Dans la formation complète du modèle, cette étude utilise l'optimiseur AdamW, le taux d'apprentissage est défini sur 5e-5, le nombre d'étapes d'échauffement est défini sur 10 et un planificateur de taux d'apprentissage linéaire est utilisé.
La formation du modèle LoRA utilise la même configuration d'optimiseur et de taux d'apprentissage que la formation complète du modèle, le rang LoRA est défini sur 16 et LoRA est appliqué aux modules suivants : q_proj, k_proj, v_proj, o_proj, up_proj, down_proj. Parmi eux, le paramètre alpha LoRA est fixé à 32.
Pour les deux méthodes d'entraînement, le nombre d'époques est fixé à 3.
Utilisez le code suivant pour exécuter le modèle Octopus-V2-2B sur un seul GPU.
from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport timedef inference (input_text):start_time = time.time ()input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)input_length = input_ids ["input_ids"].shape [1]outputs = model.generate (input_ids=input_ids ["input_ids"], max_length=1024,do_sample=False)generated_sequence = outputs [:, input_length:].tolist ()res = tokenizer.decode (generated_sequence [0])end_time = time.time ()return {"output": res, "latency": end_time - start_time}model_id = "NexaAIDev/Octopus-v2"tokenizer = AutoTokenizer.from_pretrained (model_id)model = GemmaForCausalLM.from_pretrained (model_id, torch_dtype=torch.bfloat16, device_map="auto")input_text = "Take a selfie for me with front camera"nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")Évaluation
Octopus-V2-2B a démontré une vitesse d'inférence supérieure dans les tests de référence, étant 36 fois plus rapide que la « solution Llama7B + RAG » sur un seul GPU A100. De plus, Octopus-V2-2B est 168 % plus rapide que GPT-4-turbo, qui repose sur des GPU A100/H100 en cluster. Cette avancée en termes d'efficacité est attribuée à la conception fonctionnelle du jeton d'Octopus-V2-2B.
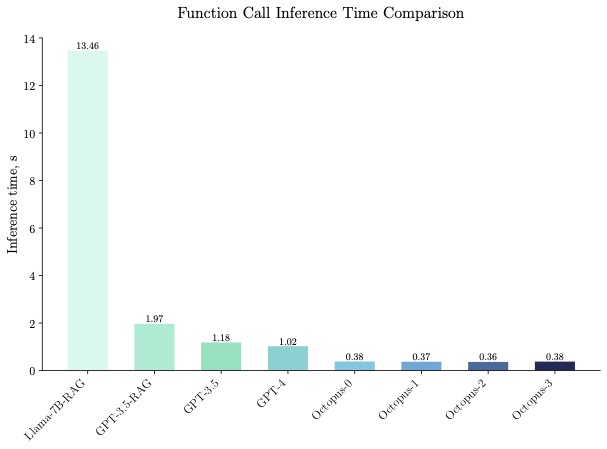
Octopus-V2-2B fonctionne non seulement bien en termes de vitesse, mais également en termes de précision, surpassant de 31 % la « solution Llama7B + RAG » en termes de précision des appels de fonction. Octopus-V2-2B atteint une précision d'appel de fonction comparable à GPT-4 et RAG + GPT-3.5.
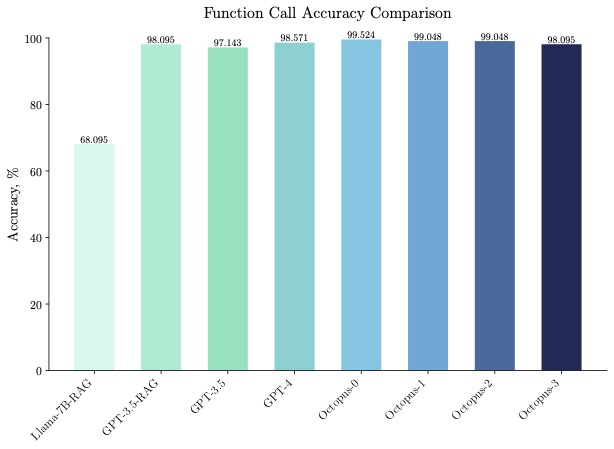
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les nouvelles règles pour octobre sont là ! Impliquant les nouveaux panneaux de signalisation routière, l'industrie de l'intelligence artificielle, etc.
- Les robots peuvent aussi ressentir : l'Université de Stanford construit une peau électronique capable de communiquer avec le cerveau
- En se concentrant sur l'écosystème commercial numérique et l'industrie des métaverses, Lujiazui Digital Intelligence World s'efforce de créer un cluster industriel d'éléments de données.
- [Trend Weekly] Tendance mondiale du développement de l'industrie de l'intelligence artificielle : OpenAI a soumis une demande de marque 'GPT-5' auprès de l'Office américain des brevets
- Xiaoyu Yilian est apparue à l'Exposition internationale de l'industrie intelligente de Chine