
Maison >Périphériques technologiques >IA >DifFlow3D : Nouveau SOTA pour l'estimation du flux de scène, le modèle de diffusion connaît un autre succès !
DifFlow3D : Nouveau SOTA pour l'estimation du flux de scène, le modèle de diffusion connaît un autre succès !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-28 14:00:09418parcourir
Titre original : DifFlow3D : Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
Lien papier : https://arxiv.org/pdf/2311.17456.pdf
Lien code : https://github. com/IRMVLab/DifFlow3D
Affiliation de l'auteur : Shanghai Jiao Tong University Cambridge University Zhejiang University Intelligent Robot

Idée de thèse :
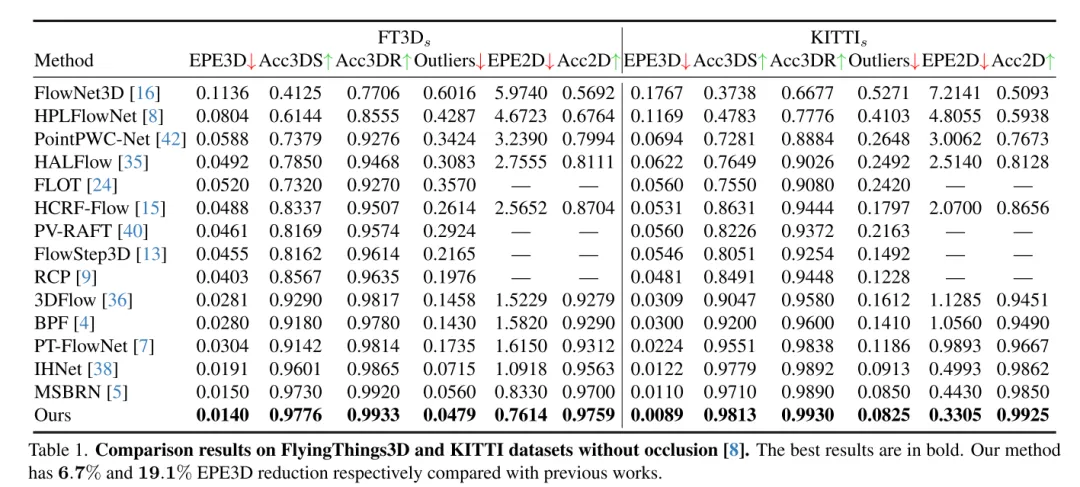
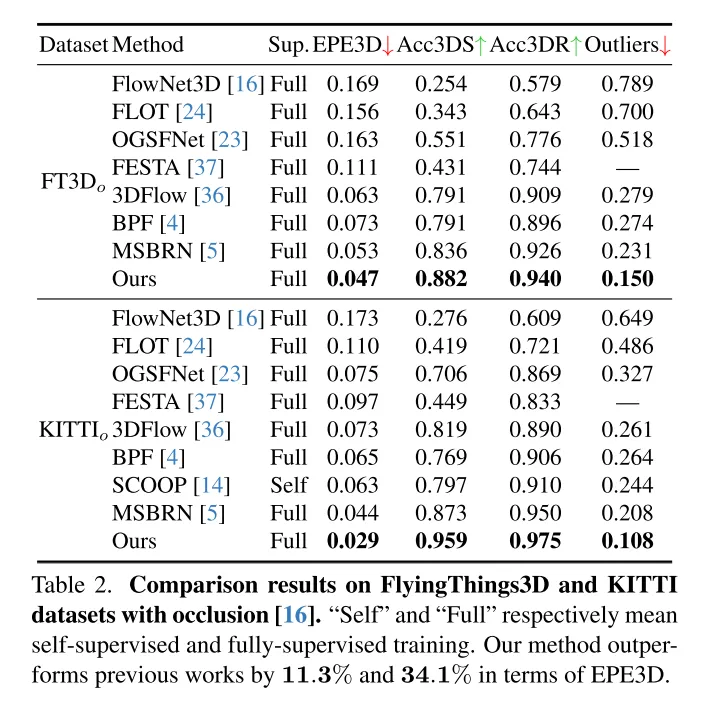
L'estimation du flux de scène vise à prédire le changement de déplacement 3D de chaque point dans une scène dynamique, c'est une tâche fondamentale dans le domaine de la vision par ordinateur. Cependant, les travaux antérieurs souffrent souvent de corrélations peu fiables causées par des plages de recherche localement contraintes et accumulent des inexactitudes dans les structures grossières à fines. Pour atténuer ces problèmes, cet article propose un nouveau réseau d'estimation de flux de scène tenant compte de l'incertitude (DifFlow3D), qui adopte un modèle probabiliste de diffusion. Le raffinement itératif basé sur la diffusion est conçu pour améliorer la robustesse de la corrélation et avoir une forte adaptabilité aux situations difficiles (telles que la dynamique, les entrées bruyantes, les modèles répétés, etc.). Pour limiter la diversité des générations, trois caractéristiques clés liées au flux sont exploitées comme conditions dans notre modèle de diffusion. De plus, cet article développe un module d'estimation de l'incertitude en diffusion pour évaluer la fiabilité du flux de scène estimé. Le DifFlow3D de cet article atteint respectivement une réduction de 6,7 % et 19,1 % des erreurs de point final tridimensionnel (EPE3D) sur les ensembles de données FlyingThings3D et KITTI 2015, et atteint une précision millimétrique sans précédent sur l'ensemble de données KITTI (0,0089 mètres pour EPE3D). De plus, notre paradigme de raffinement basé sur la diffusion peut être facilement intégré aux réseaux de flux de scènes existants en tant que module plug-and-play, améliorant considérablement la précision de leur estimation.
Principales contributions :
Pour obtenir une estimation robuste du flux de scène, cette étude propose un nouveau processus de raffinement plug-and-play basé sur la diffusion. À notre connaissance, c'est la première fois qu'un modèle probabiliste de diffusion est utilisé dans une tâche de flux de scène.
L'auteur combine des techniques telles que l'intégration de flux grossiers, l'encodage géométrique et les volumes de coûts inter-images pour concevoir une méthode de guidage conditionnel efficace pour contrôler la diversité des résultats générés.
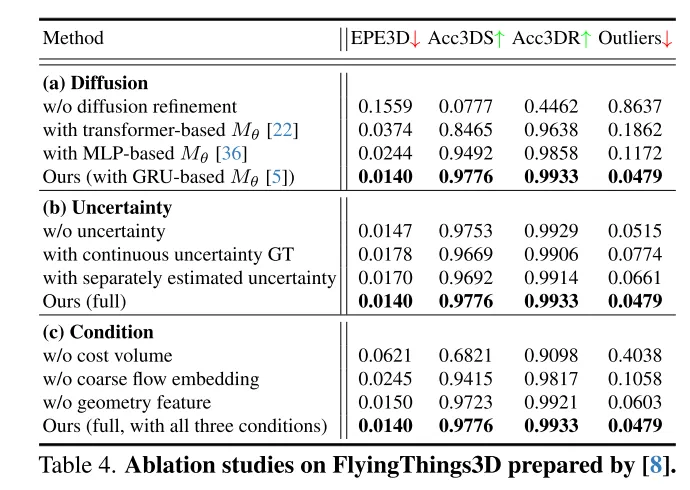
Pour évaluer la fiabilité des flux dans cet article et identifier les correspondances de points inexactes, les auteurs introduisent également des estimations d'incertitude pour chaque point du modèle de diffusion.
Les résultats de la recherche montrent que la méthode proposée dans cet article fonctionne bien sur les ensembles de données FlyingThings3D et KITTI, surpassant les autres méthodes existantes. En particulier, DifFlow3D atteint pour la première fois une erreur de point final au niveau millimétrique (EPE3D) sur l’ensemble de données KITTI. Par rapport aux recherches précédentes, notre méthode est plus robuste dans la gestion de situations difficiles, telles que des entrées bruyantes et des changements dynamiques.
Conception de réseau :
En tant que tâche de base en vision par ordinateur, le flux de scène fait référence à l'estimation d'un champ de mouvement tridimensionnel à partir d'images continues ou de nuages de points. Il fournit des informations pour la perception de bas niveau de scènes dynamiques et a diverses applications en aval, telles que la conduite autonome [21], l'estimation de pose [9] et la segmentation de mouvement [1]. Les premiers travaux se sont concentrés sur l'utilisation d'images stéréo [12] ou RVB-D [10] comme entrée. Avec la popularité croissante des capteurs 3D, tels que le lidar, les travaux récents prennent souvent les nuages de points directement en entrée.
En tant que travail pionnier, FlowNet3D[16] utilise PointNet++[25] pour extraire des caractéristiques hiérarchiques, puis régresse de manière itérative le flux de la scène. PointPWC [42] l’améliore encore grâce à des structures pyramidales, de déformation et de volume de coûts [31]. HALFlow [35] les suit et introduit un mécanisme d'attention pour une meilleure intégration des flux. Cependant, ces travaux basés sur la régression souffrent souvent d'une corrélation peu fiable et de problèmes d'optima locaux [17]. Il y a deux raisons principales : (1) Dans leur réseau, K voisins les plus proches (KNN) sont utilisés pour rechercher des correspondances de points, ce qui ne prend pas en compte les paires de points correctes mais distantes, et il existe également un bruit de correspondance [7] . (2) Un autre problème potentiel vient de la structure grossière à fine largement utilisée dans les travaux antérieurs [16, 35, 36, 42]. Fondamentalement, le flux initial est estimé au niveau de la couche la plus grossière, puis affiné de manière itérative dans des résolutions plus élevées. Cependant, les performances du raffinement du flux dépendent fortement de la fiabilité du flux grossier initial, puisque les raffinements ultérieurs sont généralement limités à une petite étendue spatiale autour de l'initialisation.
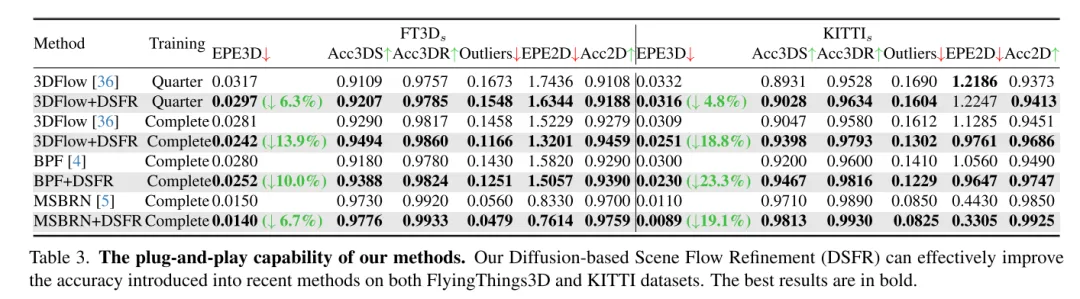
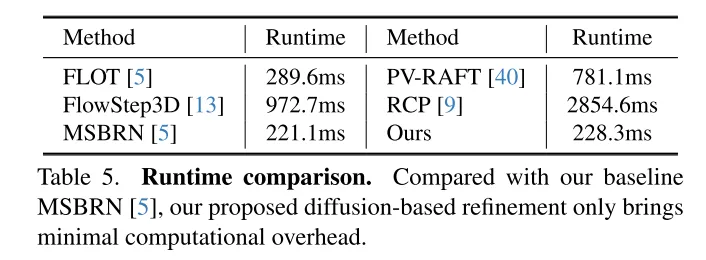
Afin de résoudre le problème du manque de fiabilité, 3DFlow[36] a conçu un module de collecte de points tout-à-tout et ajouté une vérification inverse. De même, Bi-PointFlowNet [4] et son extension MSBRN [5] proposent un réseau bidirectionnel avec corrélation avant-arrière. IHNet [38] utilise un réseau récurrent avec un schéma d'amorçage et de rééchantillonnage haute résolution. Cependant, la plupart de ces réseaux souffrent d’un coût de calcul dû à leurs corrélations bidirectionnelles ou à leurs itérations de boucles. Cet article révèle que les modèles de diffusion peuvent également améliorer la fiabilité des corrélations et la résilience au bruit d'adaptation, grâce à leur nature débruitante (illustré sur la figure 1). Inspiré par la découverte de [30] selon laquelle l'injection de bruit aléatoire permet de sortir de l'optimum local, cet article reconstruit la tâche de régression de flux déterministe en utilisant un modèle de diffusion probabiliste, comme le montre la figure 2. De plus, notre méthode peut être utilisée comme module plug-and-play pour servir le réseau de flux de scène précédent, qui est plus général et n’ajoute presque aucun coût de calcul (Section 4.5).
Cependant, exploiter les modèles génératifs dans le cadre de cet article est assez difficile en raison de la diversité générative inhérente aux modèles de diffusion. Contrairement à la tâche de génération de nuages de points qui nécessite divers échantillons de sortie, la prédiction du flux de scène est une tâche déterministe qui calcule des vecteurs de mouvement précis par point. Pour résoudre ce problème, cet article utilise des informations conditionnelles fortes pour limiter la diversité et contrôler efficacement le flux généré. Plus précisément, un flux de scène clairsemé est d'abord initialisé, puis les résidus de flux sont générés de manière itérative par diffusion. Dans chaque couche de raffinement basée sur la diffusion, nous utilisons comme conditions l'intégration du flux grossier, le volume des coûts et le codage géométrique. Dans ce cas, la diffusion est appliquée pour réellement apprendre une cartographie probabiliste à partir des entrées conditionnelles vers les résidus de flux.
De plus, peu de travaux antérieurs ont exploré la confiance et la fiabilité de l'estimation du flux de scène. Cependant, comme le montre la figure 1, la correspondance de flux dense est sujette à des erreurs en présence de bruit, de changements dynamiques, de petits objets et de motifs répétés. Il est donc très important de savoir si chaque correspondance ponctuelle estimée est fiable. Inspirés par le récent succès de l'estimation de l'incertitude dans les tâches de flux optique [33], nous proposons une incertitude ponctuelle dans le modèle de diffusion pour évaluer la fiabilité de notre estimation du flux de scène.
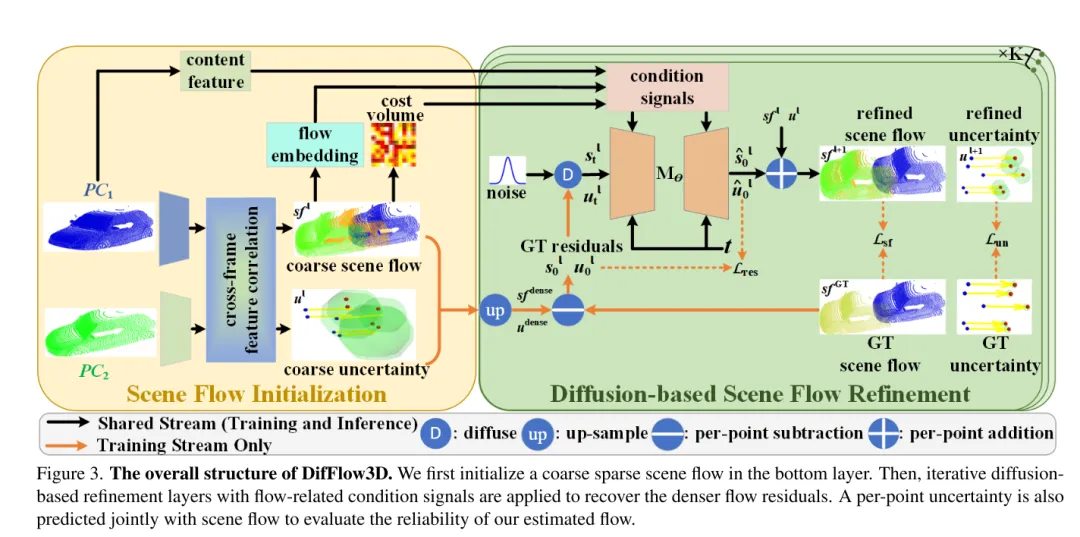
Photo 3. La structure globale de DifFlow3D. Cet article initialise d’abord un flux de scène clairsemé dans la couche inférieure. Des couches de raffinement de diffusion itératives sont ensuite utilisées en conjonction avec des signaux conditionnels liés au flux pour récupérer des résidus de flux plus denses. Pour évaluer la fiabilité des flux estimés dans cet article, l'incertitude en chaque point sera également prédite conjointement avec le flux de scène.
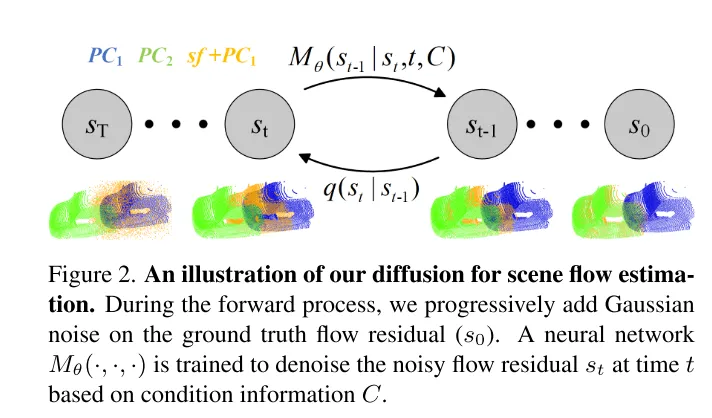
Photo 2. Diagramme schématique du processus de diffusion utilisé dans cet article pour l'estimation du flux de scène.
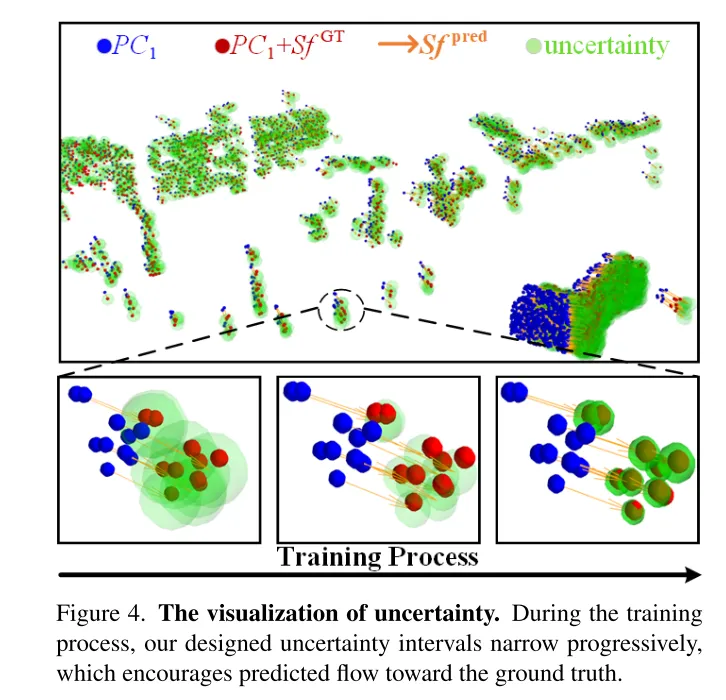
Photo 4. Visualiser l’incertitude. Au cours du processus de formation, l'intervalle d'incertitude conçu dans cet article diminue progressivement, ce qui permet au flux prédit de se rapprocher de la valeur réelle.
Résultats expérimentaux :
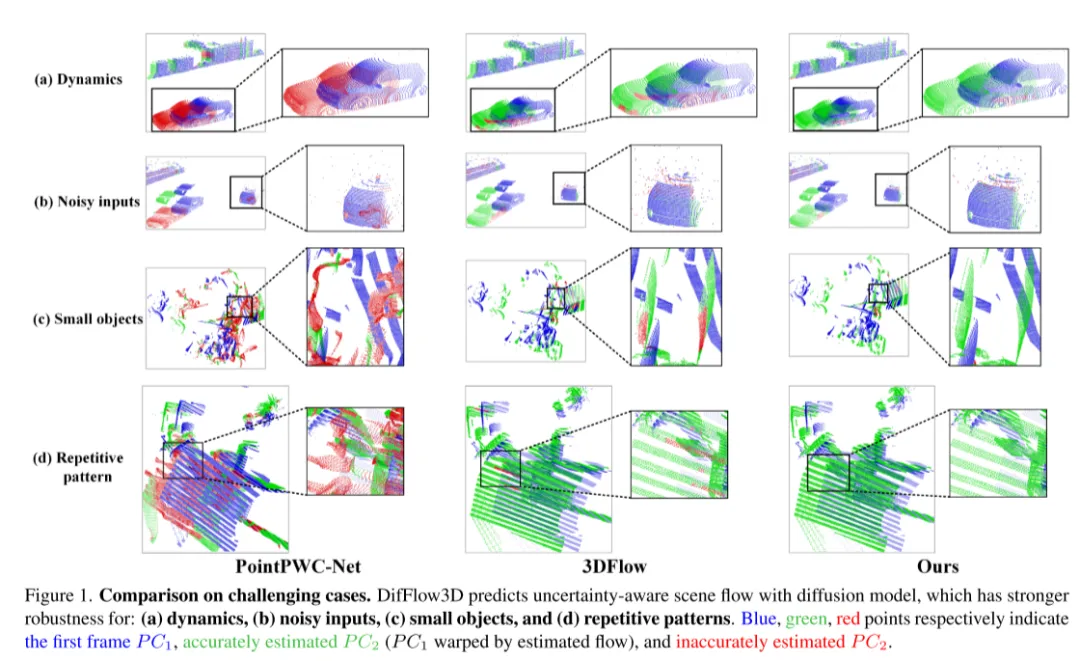
Figure 1. Comparaison dans des situations difficiles. DifFlow3D prédit le flux de scène tenant compte de l'incertitude à l'aide d'un modèle de diffusion plus robuste face : (a) aux changements dynamiques, (b) aux entrées bruyantes, (c) aux petits objets et (d)) aux motifs répétitifs.
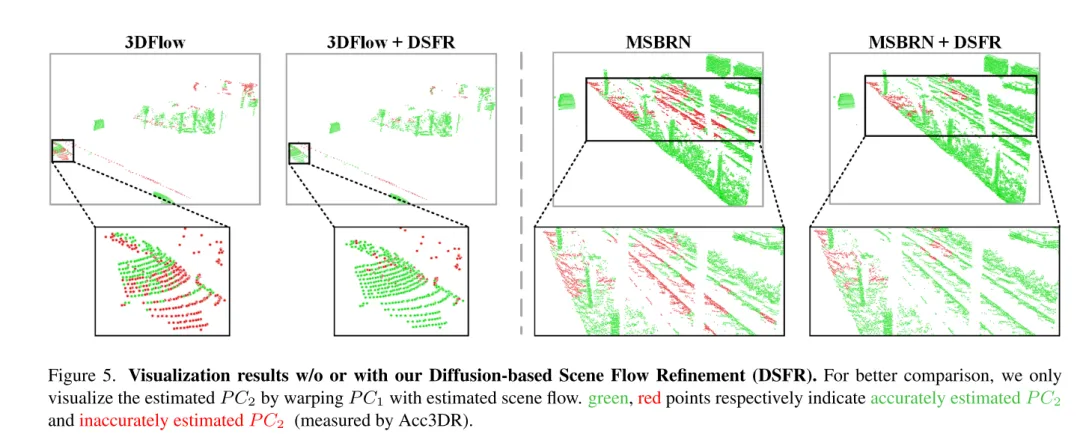
Figure 5. Résultats de visualisation sans ou avec raffinement du flux de scène basé sur la diffusion (DSFR).
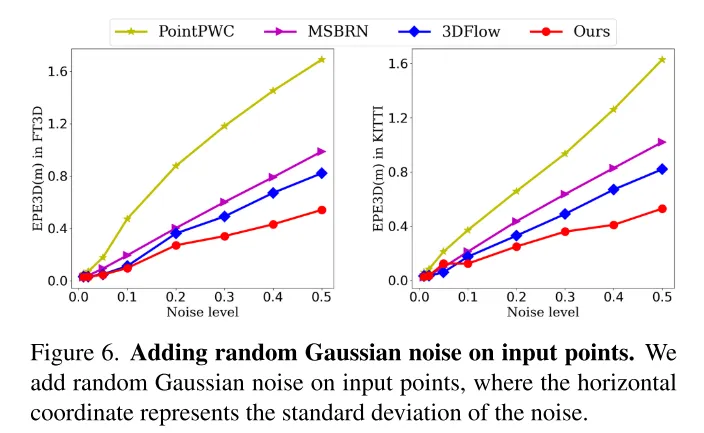
Photo 6. Ajoutez un bruit gaussien aléatoire aux points d’entrée.
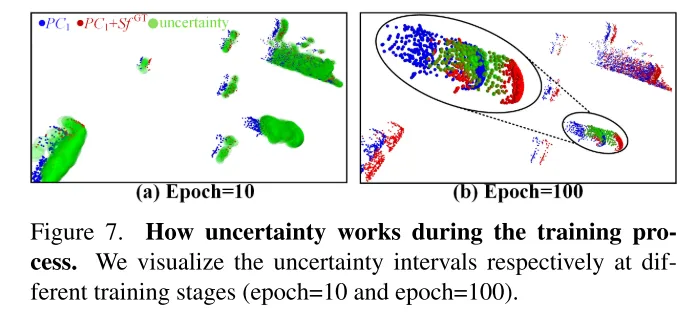
Photo 7. Le rôle de l'incertitude dans le processus de formation. Cet article visualise les intervalles d'incertitude à différentes étapes de formation (10e tour et 100e tour).
Résumé :
Cet article propose de manière innovante un réseau de raffinement de flux de scène basé sur la diffusion et conscient de l'incertitude d'estimation. Cet article adopte un raffinement de diffusion multi-échelle pour générer des résidus d’écoulement dense à grain fin. Pour améliorer la robustesse de l'estimation, cet article introduit également une incertitude ponctuelle générée conjointement avec le flux de scène. Des expériences approfondies démontrent la supériorité et les capacités de généralisation de notre DifFlow3D. Il convient de noter que le raffinement de cet article basé sur la diffusion peut être appliqué à des travaux antérieurs en tant que module plug-and-play et fournir de nouvelles implications pour les recherches futures.
Citation :
Liu J, Wang G, Ye W et al. DifFlow3D : Vers une estimation robuste du flux de scène tenant compte de l'incertitude avec le modèle de diffusion[J].
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qu'un tas ? Quel est le domaine de la méthode ? Introduction à la zone de tas et de méthode dans le modèle de mémoire JVM
- Quels sont les scénarios d'application des fermetures ?
- Explication détaillée des caractéristiques, principes, scénarios d'utilisation et cas d'application de MongoDB
- De quoi est indépendant le modèle conceptuel d'une base de données ?
- Quels sont les trois grands scénarios d'application de la 5g ?