
Maison >Périphériques technologiques >IA >Explication détaillée de Latte : la première vidéo open source de Vincent au monde, DiT, lancée à la fin de l'année dernière
Explication détaillée de Latte : la première vidéo open source de Vincent au monde, DiT, lancée à la fin de l'année dernière

- WBOYavant
- 2024-03-27 15:30:341062parcourir
Avec le lancement réussi de Sora, le modèle vidéo DiT a attiré une large attention et de nombreuses discussions. La conception de réseaux de neurones stables et à très grande échelle a toujours été un axe de recherche dans le domaine de la génération de vision. Le succès du modèle DiT apporte de nouvelles possibilités de mise à l'échelle de la génération d'images.
Cependant, en raison de la nature hautement structurée et complexe des données vidéo, étendre DiT au domaine de la génération vidéo est une tâche difficile. Une équipe composée d'équipes de recherche du Laboratoire d'intelligence artificielle de Shanghai et d'autres institutions a répondu à cette question par le biais d'expériences à grande échelle.
En novembre de l'année dernière, l'équipe avait publié un modèle auto-développé appelé Latte, dont la technologie est similaire à celle de Sora. Latte est le premier DiT vidéo Wensheng open source au monde et a reçu une large attention. De nombreux frameworks open source tels que Open-Sora Plan (PKU) et Open-Sora (ColossalAI) utilisent et font référence à la conception du modèle de Latte.

- Lien open source : https://github.com/Vchitect/Latte
- Page d'accueil du projet : https://maxin-cn.github.io/latte_project/
- Lien papier : https://arxiv.org/pdf/2401.03048v1.pdf
Tout d'abord, jetons un coup d'œil à l'effet de génération vidéo de Latte.

Présentation de la méthode
En général, Latte contient deux modules clés : la VAE pré-formée et le DiT vidéo. Dans le VAE pré-entraîné, l'encodeur est chargé de compresser la vidéo de l'espace des pixels à l'espace latent image par image, tandis que le DiT vidéo est chargé d'extraire les jetons et d'effectuer une modélisation spatio-temporelle pour traiter la représentation latente. Enfin, les cartes du décodeur VAE. les fonctionnalités récupèrent l'espace Pixel pour générer de la vidéo. Afin d'obtenir la meilleure qualité vidéo, les chercheurs se sont concentrés sur deux aspects importants de la conception Latte, à savoir la conception structurelle globale du modèle DiT vidéo et les détails des meilleures pratiques de formation du modèle.
(1) Recherche sur la conception globale de la structure du modèle Latte
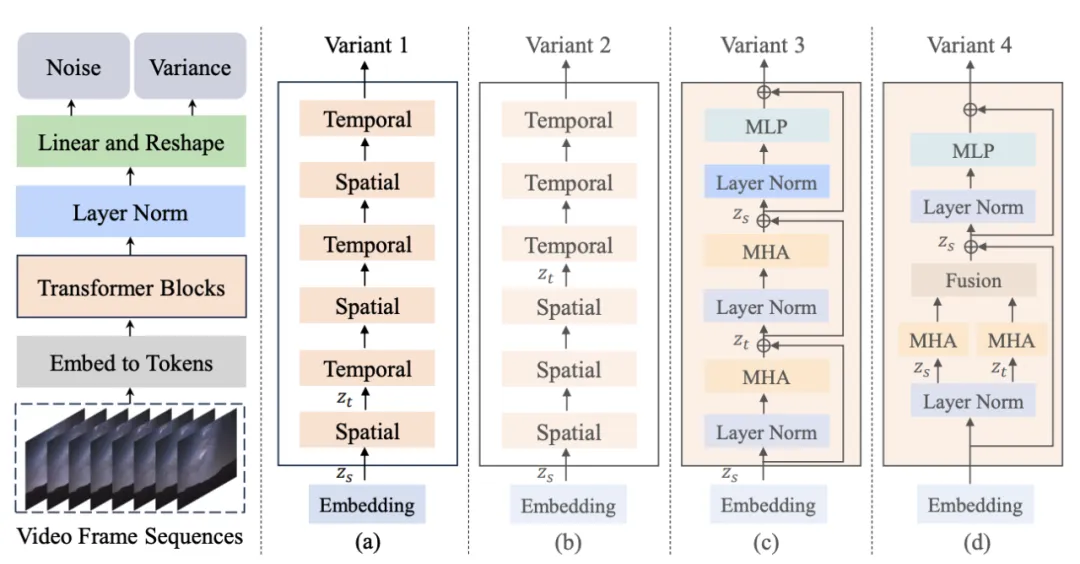
Figure 1. Structure du modèle Latte et ses variantes
L'auteur a proposé 4 variantes différentes de Latte (Figure 1), deux Transformer les modules ont été conçus du point de vue du mécanisme d'attention spatio-temporelle, et deux variantes (Variante) ont été étudiées dans chaque module :
1 Module de mécanisme d'attention unique, dans chaque module Contient uniquement l'attention temporelle ou spatiale.
- Modélisation espace-temps entrelacée (Variante 1) : Le module temporel est inséré après chaque module spatial.
- Modélisation séquentielle espace-temps (Variante 2) : Le module temps est placé entièrement après le module espace.
2. Module de mécanismes d'attention multiples, chaque module contient à la fois des mécanismes d'attention temporels et spatiaux (variante de référence Open-sora).
- Mécanisme d'attention spatio-temporelle en série (Variante 3) : Modélisation en série du mécanisme d'attention spatio-temporelle.
- Mécanisme d'attention spatio-temporelle parallèle (Variante 4) : Modélisation parallèle et fusion de fonctionnalités du mécanisme d'attention spatio-temporelle.
Les expériences montrent (Figure 2) qu'en définissant les mêmes quantités de paramètres pour les quatre variantes du modèle, la variante 4 présente une différence significative en FLOPS par rapport aux trois autres variantes, elle a donc également le FVD le plus élevé. La performance globale de les trois autres variantes sont similaires. La variante 1 a obtenu les meilleures performances. L'auteur prévoit de mener une discussion plus détaillée sur les données à grande échelle à l'avenir.
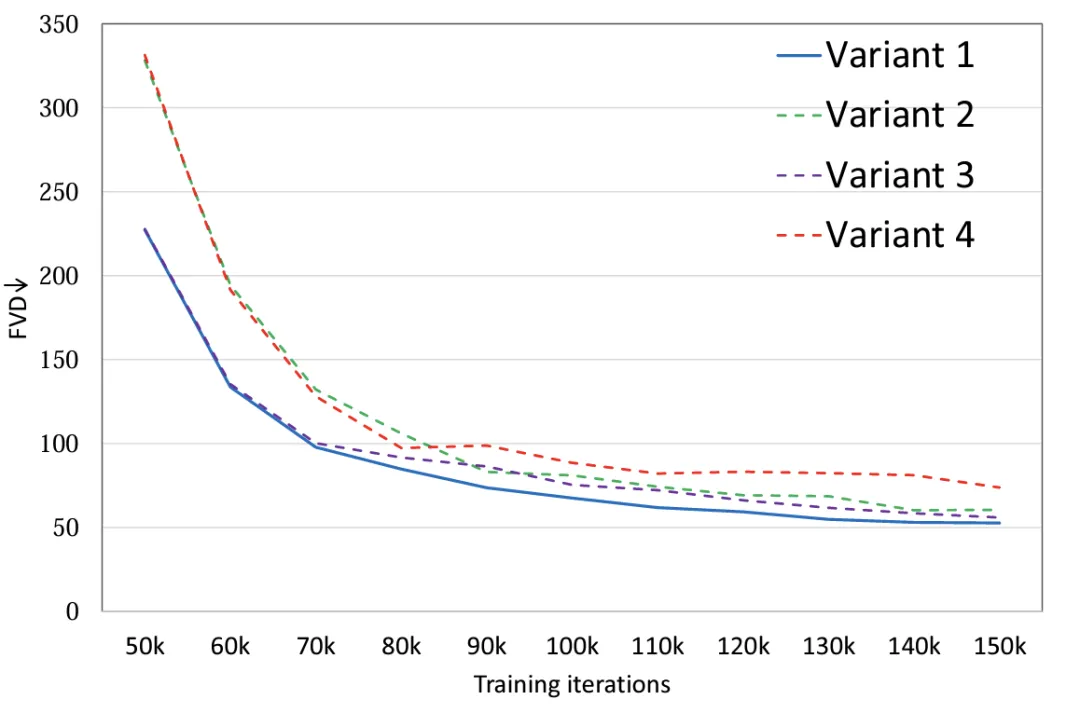
Figure 2. Structure du modèle FVD
(2) Recherche sur la conception optimale du modèle Latte et les détails de la formation (les meilleures pratiques)
En plus de la conception globale de la structure de Dans le modèle, l'auteur a également exploré les facteurs qui affectent l'effet de génération dans d'autres modèles et formations sont inclus.
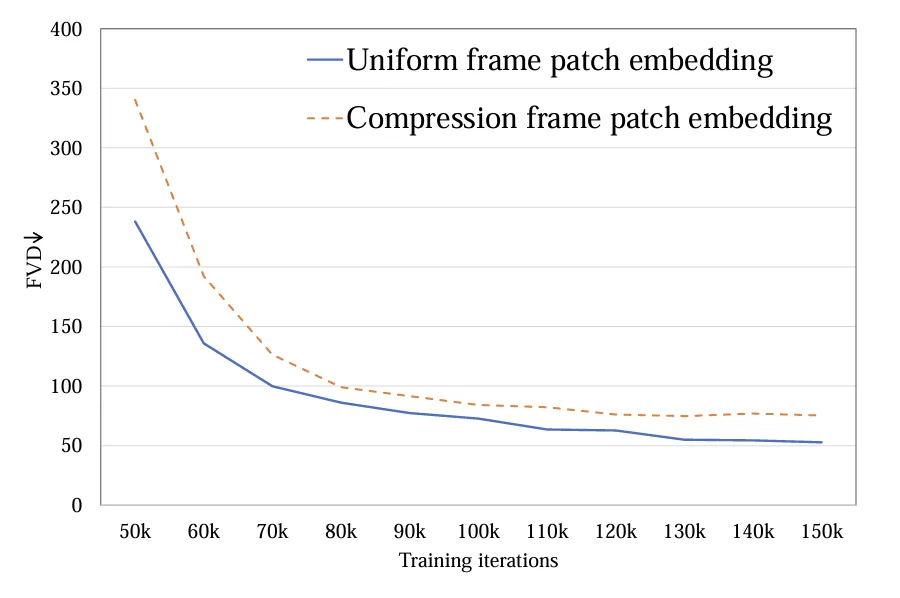
1.Extraction de jetons : Deux méthodes, le jeton à image unique (a) et le jeton spatio-temporel (b), ont été explorées. La première compresse uniquement les jetons au niveau spatial, tandis que la seconde compresse les informations spatio-temporelles au niveau spatial. le même temps. Les expériences montrent que les jetons à image unique sont meilleurs que les jetons spatio-temporels (Figure 4). En comparaison avec Sora, l'auteur spécule que le jeton spatio-temporel proposé par Sora est pré-compressé dans la dimension temporelle via la vidéo VAE et est similaire à la conception de Latte dans l'espace latent, ne traitant que les jetons à image unique.
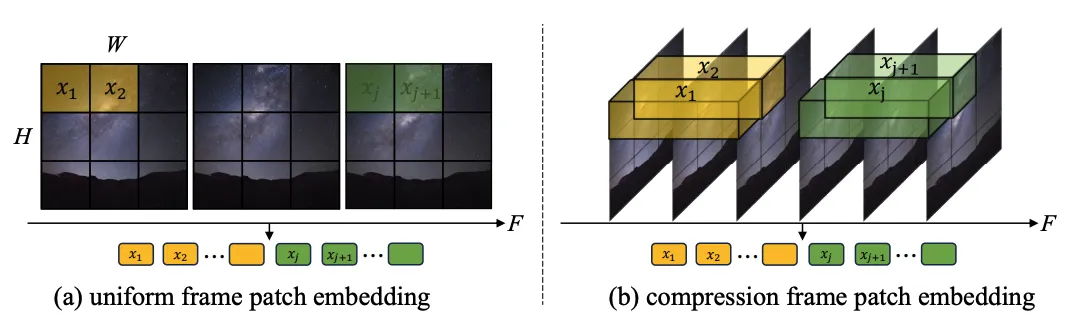
2. mode
: Deux méthodes, (a) S-AdaLN et (b) tous les jetons, ont été explorées (Figure 5). S-AdaLN convertit les informations de condition en variables lors de la normalisation et les injecte dans le modèle via MLP. Le formulaire Tous les jetons convertit toutes les conditions en un jeton unifié en entrée du modèle. Des expériences ont prouvé que la méthode S-AdaLN est plus efficace pour obtenir des résultats de haute qualité que tous les jetons (Figure 6). En effet, S-AdaLN permet d'injecter des informations directement dans chaque module. Cependant, tous les jetons doivent transmettre des informations conditionnelles de l'entrée à la fin couche par couche, et il y a une perte dans le processus de flux d'informations.
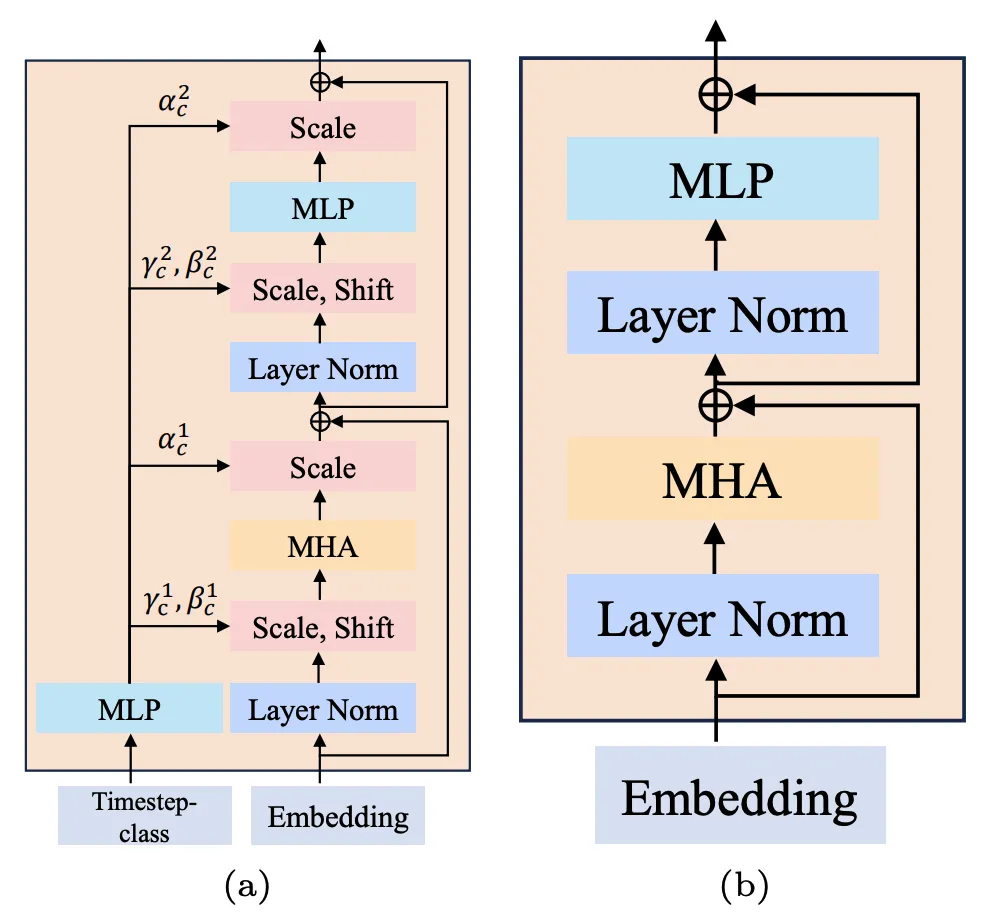 Figure 5. (a) S-AdaLN et (b) tous les jetons.
Figure 5. (a) S-AdaLN et (b) tous les jetons.
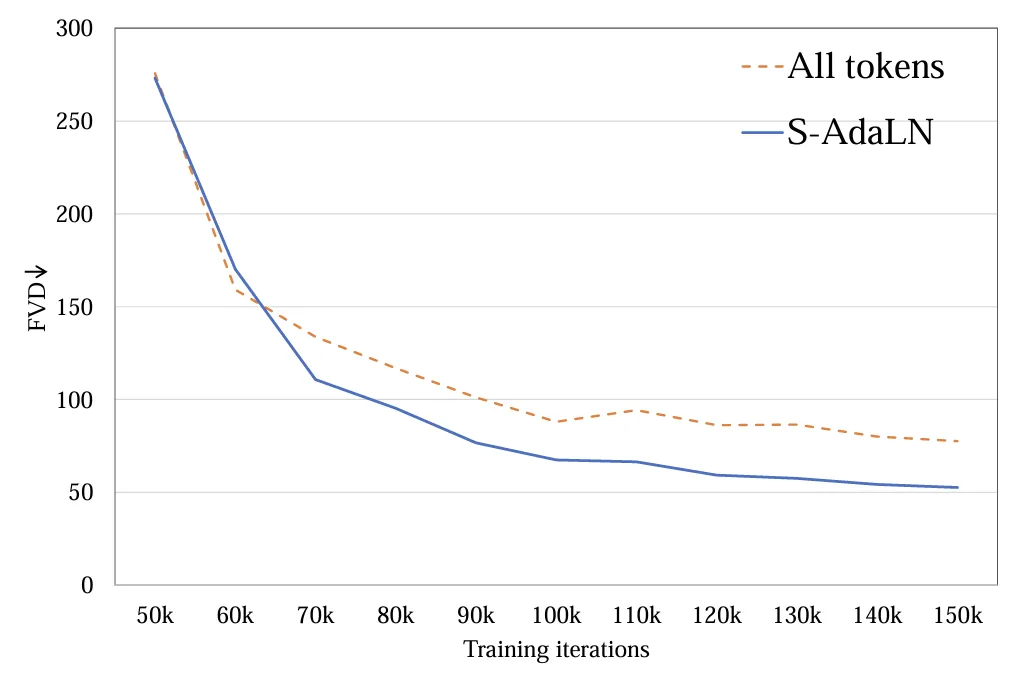 Figure 6. Méthode d'injection conditionnelle FVD
Figure 6. Méthode d'injection conditionnelle FVD
3
Encodage de position spatiale et temporelle: Explorez l'encodage de position absolue et l'encodage de position relative. Différents encodages de position ont peu d'impact sur la qualité vidéo finale (Figure 7). En raison de la courte durée de génération, la différence de codage de position n'est pas suffisante pour affecter la qualité vidéo. Pour une génération vidéo longue, ce facteur doit être reconsidéré.
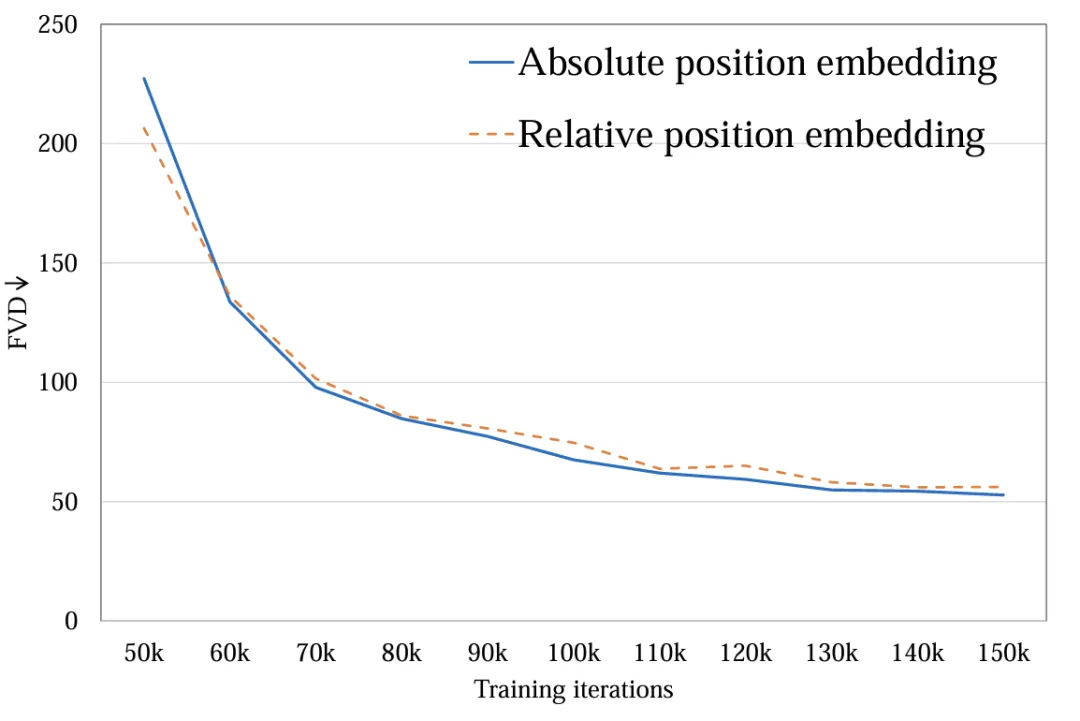 Figure 7. Méthode de codage de position FVD
Figure 7. Méthode de codage de position FVD
4.
Initialisation du modèle: explorez l'impact de l'utilisation de l'initialisation des paramètres de pré-entraînement ImageNet sur les performances du modèle. Les expériences montrent que le modèle initialisé à l'aide d'ImageNet a une vitesse de convergence plus rapide. Cependant, à mesure que la formation progresse, le modèle initialisé aléatoirement obtient de meilleurs résultats (Figure 8). La raison possible est qu'il existe une différence de distribution relativement importante entre ImageNet et l'ensemble de formation FaceForensics, de sorte qu'il n'a pas réussi à promouvoir les résultats finaux du modèle. Pour la tâche vidéo Vincent, cette conclusion doit être reconsidérée. Dans la distribution des ensembles de données générales, la répartition spatiale du contenu des images et des vidéos est similaire, et l'utilisation de modèles T2I pré-entraînés peut grandement promouvoir le T2V.
Figure 8. Paramètre d'initialisation FVD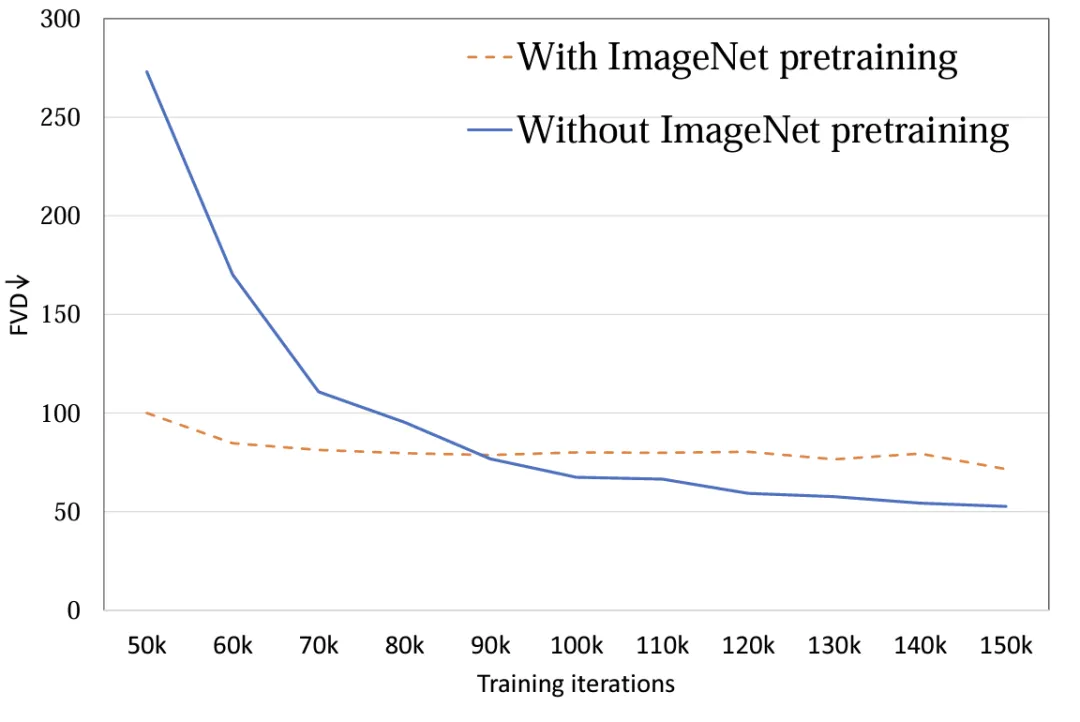
5. Entraînement conjoint image et vidéo
: Compressez les vidéos et les images dans un jeton unifié pour une formation conjointe. Le jeton vidéo est responsable de l'optimisation de tous les paramètres et. le jeton d'image est uniquement responsable de l'optimisation des paramètres spatiaux.La formation conjointe a considérablement amélioré les résultats finaux (Tableau 2 et Tableau 3). Le FID d'image et le FVD vidéo ont été réduits grâce à la formation conjointe. Ce résultat est cohérent avec le cadre basé sur UNet [2] [3] sont cohérents. 6. Tailles des modèles
: 4 tailles de modèles différentes ont été explorées, S, B, L et XL (Tableau 1).L'expansion de l'échelle du DiT vidéo contribuera considérablement à améliorer la qualité des échantillons générés (Figure 9). Cette conclusion prouve également l’exactitude de l’utilisation de la structure Transformer dans le modèle de diffusion vidéo pour une mise à l’échelle ultérieure.
Tableau 1. Échelle de modèle Latte de différentes tailles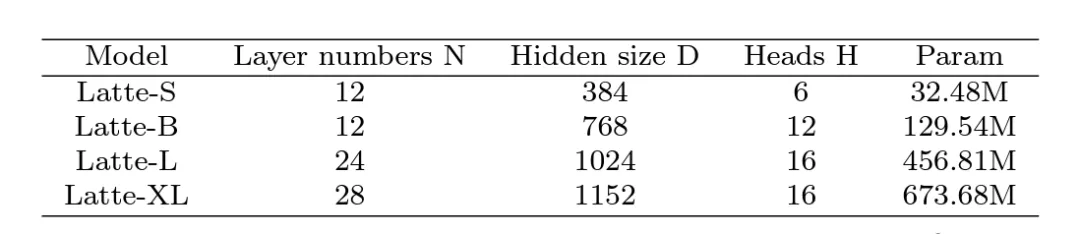
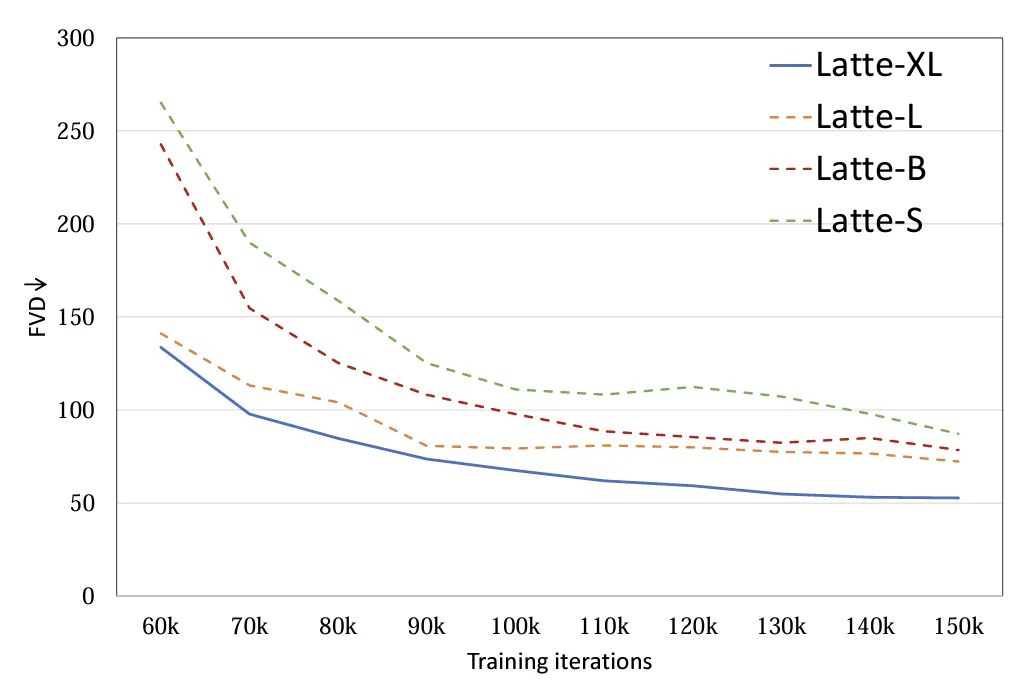
Figure 9. Analyse qualitative et quantitative de la taille du modèle FVD
L'auteur s'est formé sur 4 ensembles de données académiques (FaceForensics, TaichiHD, SkyTimelapse et UCF101) respectivement. Les résultats qualitatifs et quantitatifs (Tableau 2 et Tableau 3) montrent que Latte a obtenu les meilleures performances, ce qui prouve que la conception globale du modèle est excellente.
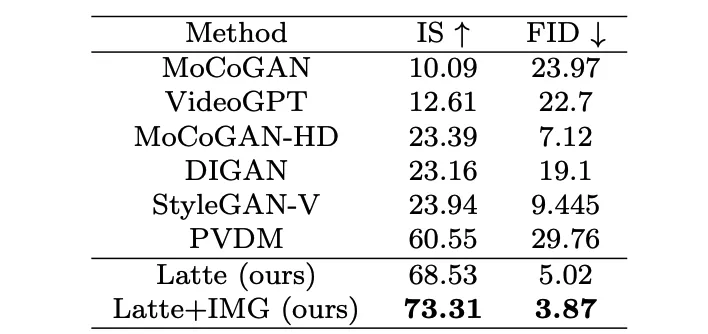
Tableau 2. Évaluation de la qualité d'image UCF101
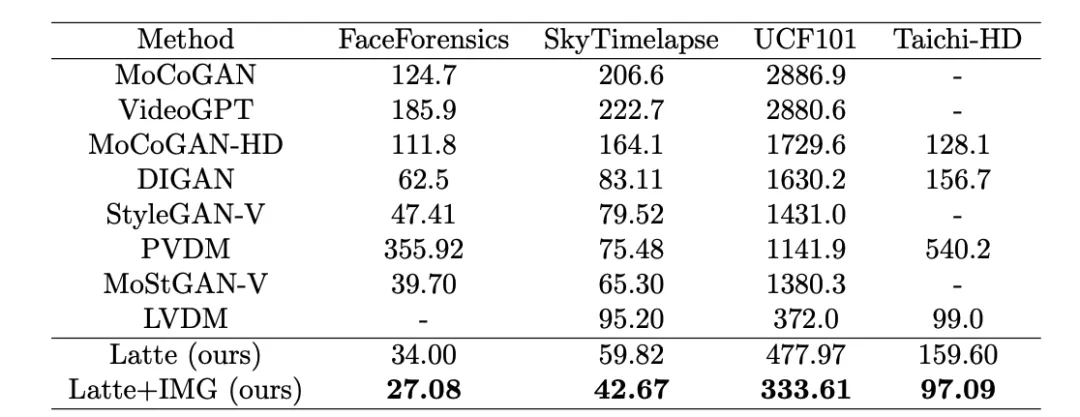
Tableau 3. Évaluation de la qualité vidéo Latte et SoTA
Vincent Video Extension
Pour une preuve supplémentaire Pour la performance générale de Latte, l'auteur a étendu Latte à la tâche vidéo Vincent, en utilisant le modèle PixArt-alpha [4] pré-entraîné comme initialisation des paramètres spatiaux. Selon le principe de conception optimale, après une période de formation, Latte. a initialement réalisé la tâche vidéo de Vincent. Les plans de suivi visent à vérifier la limite supérieure des capacités de génération de Latte en les augmentant.
Discussion et résumé
Latte, en tant que première vidéo DiT open source de Vincent au monde, a obtenu des résultats prometteurs. Cependant, en raison de l'énorme différence dans les ressources informatiques, il existe des problèmes de clarté, de fluidité et de durée de génération. Il y a encore un gros écart par rapport à Sora. L'équipe accueille et recherche activement des coopérations de toutes sortes, dans l'espoir d'utiliser la puissance de l'open source pour créer un modèle de génération vidéo universelle à grande échelle auto-développé avec d'excellentes performances.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment construire un modèle mathématique en utilisant Python
- Quelles sont les couches du modèle de référence TCP/IP ?
- En quoi la norme ieee802 divise-t-elle le modèle hiérarchique du réseau local en
- Pas satisfait du dialogue homme-machine ! Microsoft a été exposé à utiliser ChatGPT pour former des robots à servir les humains dans la vie quotidienne
- Premier article : Un nouveau paradigme pour la formation de modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D