
Maison >Périphériques technologiques >IA >Un article pour comprendre les défis techniques et les stratégies d'optimisation pour affiner les grands modèles de langage
Un article pour comprendre les défis techniques et les stratégies d'optimisation pour affiner les grands modèles de langage

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-20 23:01:021089parcourir
Bonjour à tous, je m'appelle Luga. Aujourd'hui, nous continuerons à explorer les technologies de l'écosystème de l'intelligence artificielle, en particulier le LLM Fine-Tuning. Cet article continuera à analyser en profondeur la technologie LLM Fine-Tuning pour aider chacun à mieux comprendre son mécanisme de mise en œuvre afin qu'elle puisse être mieux appliquée au développement du marché et à d'autres domaines.

Les LLM (Large Language Models) sont à la tête de la nouvelle vague de technologies d'intelligence artificielle. Cette IA avancée simule les capacités cognitives et linguistiques humaines en analysant d’énormes quantités de données à l’aide de modèles statistiques pour apprendre des modèles complexes entre des mots et des phrases. Les puissantes fonctions des LLM ont suscité un vif intérêt de la part de nombreuses grandes entreprises et passionnés de technologie, qui se précipitent pour adopter ces solutions innovantes pilotées par l'intelligence artificielle, dans le but d'améliorer l'efficacité opérationnelle, de réduire la charge de travail, de réduire les dépenses et, à terme, d'inspirer. des idées plus innovantes qui créent de la valeur commerciale.
Cependant, pour réellement réaliser le potentiel des LLM, la clé réside dans la « personnalisation ». Autrement dit, comment les entreprises peuvent transformer des modèles généraux pré-entraînés en modèles exclusifs qui répondent à leurs propres besoins commerciaux et scénarios d'utilisation grâce à des stratégies d'optimisation spécifiques. Compte tenu des différences entre les différentes entreprises et scénarios d'application, il est particulièrement important de choisir une méthode d'intégration LLM appropriée. Par conséquent, évaluer avec précision les exigences spécifiques des cas d’utilisation et comprendre les différences subtiles et les compromis entre les différentes options d’intégration aidera les entreprises à prendre des décisions éclairées.
Qu'est-ce que le réglage fin ?
À l'ère actuelle de vulgarisation des connaissances, il n'a jamais été aussi facile d'obtenir des informations et des opinions sur l'IA et le LLM. Cependant, trouver des réponses professionnelles pratiques et spécifiques au contexte reste un défi. Dans notre vie quotidienne, nous sommes souvent confrontés à un malentendu si courant : on pense généralement que les modèles de réglage fin (réglage fin) sont le seul (ou peut-être le meilleur) moyen pour le LLM d'acquérir de nouvelles connaissances. En fait, que vous ajoutiez des assistants collaboratifs intelligents à vos produits ou que vous utilisiez LLM pour analyser de grandes quantités de données non structurées stockées dans le cloud, vos données réelles et votre environnement commercial sont des facteurs clés pour choisir la bonne approche LLM.
Dans de nombreux cas, il est souvent plus efficace d'adopter des stratégies alternatives moins complexes à mettre en œuvre, plus robustes aux ensembles de données qui changent fréquemment et qui produisent des résultats plus fiables et plus précis que les méthodes traditionnelles de réglage fin. Bien que le réglage fin soit une technique de personnalisation LLM courante qui effectue une formation supplémentaire sur un modèle pré-entraîné sur un ensemble de données spécifique pour mieux l'adapter à une tâche ou un domaine spécifique, elle présente également des compromis et des limites importants.
Alors, qu'est-ce que le réglage fin ?
Le réglage fin LLM (Large Language Model) est l'une des technologies qui a attiré beaucoup d'attention dans le domaine du NLP (Natural Language Processing) ces dernières années. Il permet au modèle de mieux s'adapter à un domaine ou une tâche spécifique en effectuant une formation supplémentaire sur un modèle déjà entraîné. Cette méthode permet au modèle d'acquérir plus de connaissances liées à un domaine spécifique, obtenant ainsi de meilleures performances dans ce domaine ou cette tâche. L'avantage du réglage fin du LLM est qu'il tire parti des connaissances générales acquises par le modèle pré-entraîné, puis les affine davantage sur un domaine spécifique pour obtenir une précision et des performances plus élevées sur des tâches spécifiques. Cette méthode a été largement utilisée dans diverses tâches de PNL et a obtenu des résultats significatifs. Le concept principal du réglage fin du LLM est d'utiliser les paramètres du modèle pré-entraîné comme base pour de nouvelles tâches et d'affiner le modèle. une petite quantité de données de domaine ou de tâche spécifiques. Capacité à s'adapter rapidement à de nouvelles tâches ou ensembles de données. Cette méthode permet d'économiser beaucoup de temps et de ressources de formation tout en améliorant les performances du modèle sur de nouvelles tâches. La flexibilité et l’efficacité du réglage fin du LLM en font l’une des méthodes privilégiées dans de nombreuses tâches de traitement du langage naturel. En ajustant avec précision un modèle pré-entraîné, le modèle peut apprendre plus rapidement les fonctionnalités et les modèles de nouvelles tâches, améliorant ainsi les performances globales. Ceci
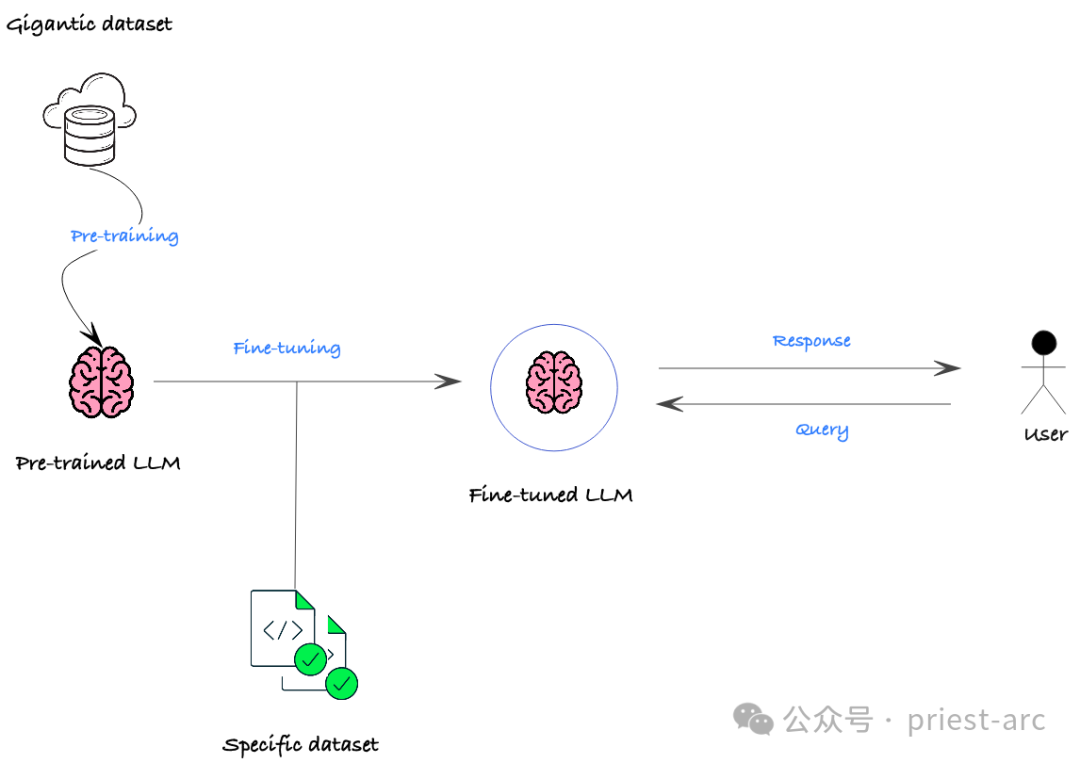 Dans les scénarios commerciaux réels, les principaux objectifs du réglage fin incluent généralement les points suivants :
Dans les scénarios commerciaux réels, les principaux objectifs du réglage fin incluent généralement les points suivants :
(1) Adaptation du domaine
LLM est généralement formé sur des données générales dans tous les domaines, mais lorsqu'il est appliqué à des champs spécifiques tels que des scénarios financiers, médicaux, juridiques et autres, les performances peuvent être considérablement compromises. Grâce à un réglage fin, le modèle pré-entraîné peut être ajusté et adapté au domaine cible afin qu'il puisse mieux capturer les caractéristiques linguistiques et les relations sémantiques d'un domaine spécifique, améliorant ainsi les performances dans ce domaine.
(2) Personnalisation des tâches
Même dans le même domaine, différentes tâches spécifiques peuvent avoir des exigences différenciées. Par exemple, les tâches PNL telles que la classification de texte, la réponse aux questions, la reconnaissance d'entités nommées, etc. mettront en avant différentes exigences en matière de compréhension du langage et de capacités de génération. Grâce à un réglage fin, les indicateurs de performance du modèle sur des tâches spécifiques, telles que la précision, le rappel, la valeur F1, etc., peuvent être optimisés en fonction des besoins spécifiques des tâches en aval.
(3) Amélioration des performances
Même sur une tâche spécifique, le modèle pré-entraîné peut présenter des goulots d'étranglement en termes de précision, de vitesse, etc. Grâce à un réglage fin, nous pouvons encore améliorer les performances du modèle dans cette tâche. Par exemple, pour les scénarios d'application en temps réel qui nécessitent une vitesse d'inférence élevée, le modèle peut être compressé et optimisé ; pour les tâches clés qui nécessitent une plus grande précision, la capacité de jugement du modèle peut également être améliorée grâce à un réglage fin.
Quels sont les avantages et les difficultés rencontrés par le Fine-Tuning (fine-tuning) ?
D'une manière générale, le principal avantage du Fine-Tuning (fine-tuning) est qu'il peut améliorer efficacement les performances des modèles pré-entraînés existants dans des scénarios d'application spécifiques. Grâce à une formation continue et à l'ajustement des paramètres du modèle de base dans le domaine ou la tâche cible, il peut mieux capturer les caractéristiques et les modèles sémantiques dans des scénarios spécifiques, améliorant ainsi considérablement les indicateurs clés du modèle dans ce domaine ou cette tâche. Par exemple, en affinant le modèle Llama 2, les performances de certaines fonctionnalités peuvent être meilleures que l'implémentation du modèle de langage d'origine de Meta.
Bien que le réglage fin apporte des avantages significatifs au LLM, il existe également certains inconvénients à prendre en compte. Alors, quels sont les dilemmes auxquels est confronté le Fine-Tuning (fine-tuning) ?
Défis et limites :
- Oubli catastrophique : Le réglage fin peut conduire à un "oubli catastrophique", c'est-à-dire que le modèle oublie une partie du bon sens appris. pendant la pré-formation. Cela peut se produire si les données de nudge sont trop spécifiques ou se concentrent principalement sur une zone étroite.
- Exigences en matière de données : bien que le réglage fin nécessite moins de données que la formation à partir de zéro, des données pertinentes et de haute qualité sont toujours nécessaires pour la tâche spécifique. Des données insuffisantes ou mal étiquetées peuvent entraîner de mauvaises performances.
- Ressources informatiques : le processus de réglage fin reste coûteux en termes de calcul, en particulier pour les modèles complexes et les grands ensembles de données. Pour les petites organisations ou celles disposant de ressources limitées, cela peut constituer un obstacle.
- Expertise requise : la mise au point nécessite souvent une expertise dans des domaines tels que l'apprentissage automatique, la PNL et la tâche spécifique à accomplir. Choisir le bon modèle pré-entraîné, configurer les hyperparamètres et évaluer les résultats peut être compliqué pour ceux qui ne possèdent pas les connaissances nécessaires.
Problèmes potentiels :
- Amplification des biais : les modèles pré-entraînés peuvent hériter des biais de leurs données d'entraînement. Si les données nudged reflètent des biais similaires, le nudge peut par inadvertance amplifier ces biais. Cela peut conduire à des résultats injustes ou discriminatoires.
- Défi d'interprétabilité : les modèles affinés sont plus difficiles à interpréter que les modèles pré-entraînés. Comprendre comment un modèle atteint ses résultats peut être difficile, ce qui entrave le débogage et la confiance dans la sortie du modèle.
- Risque de sécurité : les modèles affinés peuvent être vulnérables aux attaques contradictoires, dans lesquelles des acteurs malveillants manipulent les données d'entrée, ce qui amène le modèle à produire des sorties incorrectes.
Comment le réglage fin se compare-t-il aux autres méthodes de personnalisation ?
De manière générale, le réglage fin n'est pas le seul moyen de personnaliser la sortie du modèle ou d'intégrer des données personnalisées. En fait, cela peut ne pas convenir à nos besoins et cas d'utilisation spécifiques, il existe d'autres alternatives qui méritent d'être explorées et considérées, comme suit :
1. Prompt Engineering (Prompt Engineering)
Prompt Engineering est une méthode qui est envoyée à Processus consistant à fournir des instructions détaillées ou des données contextuelles dans les conseils d'un modèle d'IA pour augmenter la probabilité d'obtenir le résultat souhaité. L'ingénierie des invites est beaucoup moins complexe à mettre en œuvre que le réglage fin, et les invites peuvent être modifiées et redéployées à tout moment sans aucune modification du modèle sous-jacent.
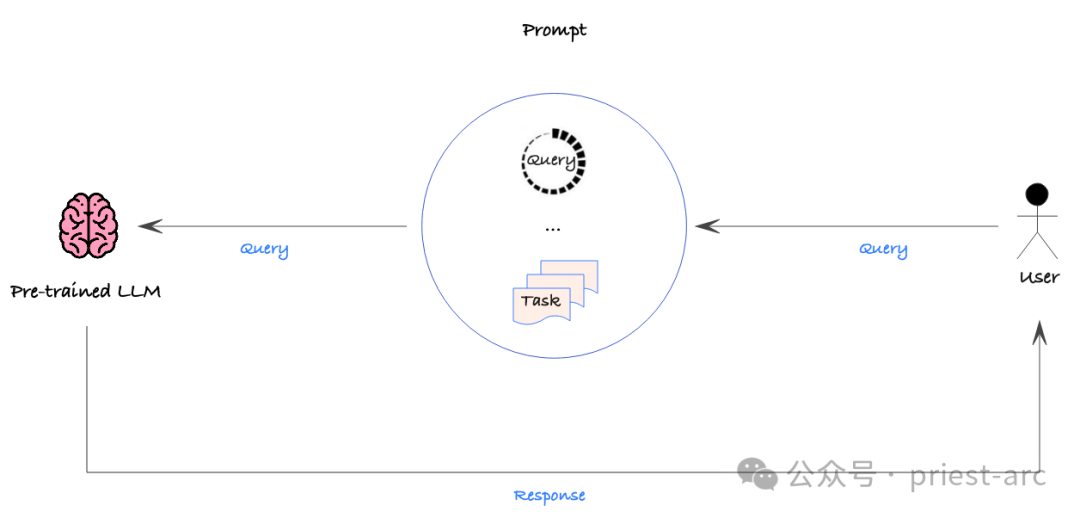
Cette stratégie est relativement simple, mais une approche basée sur les données doit toujours être utilisée pour évaluer quantitativement l'exactitude des différents conseils afin de garantir les performances souhaitées. De cette façon, nous pouvons systématiquement affiner les indices pour trouver le moyen le plus efficace de guider le modèle pour produire le résultat souhaité.
Cependant, Prompt Engineering n’est pas sans défauts. Premièrement, il ne peut pas intégrer directement de grands ensembles de données car les invites sont généralement modifiées et déployées manuellement. Cela signifie que Prompt Engineering peut sembler moins efficace lors du traitement de données à grande échelle.
De plus, Prompt Engineering ne peut pas permettre au modèle de générer de nouveaux comportements ou fonctions qui n'existent pas dans les données d'entraînement de base. Cette limitation signifie que si nous avons besoin que le modèle ait des capacités complètement nouvelles, s'appuyer uniquement sur l'ingénierie des indices ne sera peut-être pas en mesure de répondre aux besoins, et d'autres méthodes devront peut-être être envisagées, comme un réglage fin ou une formation du modèle à partir de zéro.
2. RAG (Retrieval Augmented Generation)
RAG (Retrieval Augmented Generation) est une méthode efficace pour combiner de grands ensembles de données non structurées (tels que des documents) avec LLM. Il exploite les technologies de recherche sémantique et de bases de données vectorielles, combinées à un mécanisme d'indication, pour permettre à LLM d'obtenir les connaissances et le contexte requis à partir d'informations externes riches afin de générer des résultats plus précis et plus perspicaces.
Bien que RAG en lui-même ne soit pas un mécanisme permettant de générer de nouvelles fonctionnalités de modèle, il s'agit d'un outil extrêmement puissant pour intégrer efficacement LLM à des ensembles de données non structurées à grande échelle. En utilisant RAG, nous pouvons facilement fournir aux LLM une grande quantité d’informations de base pertinentes, améliorant ainsi leurs connaissances et leur compréhension, améliorant ainsi considérablement les performances de génération.
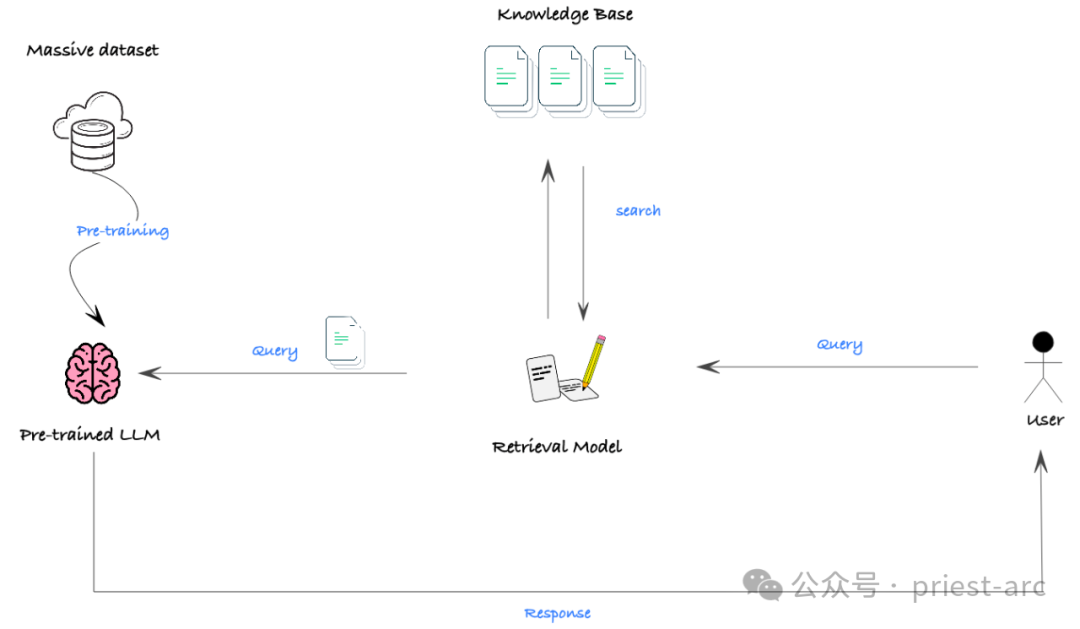
Dans les scénarios réels, le plus grand obstacle à l'efficacité de RAG est que de nombreux modèles ont une fenêtre contextuelle limitée, c'est-à-dire que la longueur maximale de texte que le modèle peut traiter en même temps est limitée. Dans certaines situations où des connaissances de base approfondies sont requises, cela peut empêcher le modèle d'obtenir suffisamment d'informations pour obtenir de bonnes performances.
Cependant, avec le développement rapide de la technologie, la fenêtre contextuelle du modèle s'étend rapidement. Même certains modèles open source sont capables de gérer des saisies de texte longues pouvant atteindre 32 000 jetons. Cela signifie que RAG aura des perspectives d'application plus larges à l'avenir et pourra fournir un soutien solide pour des tâches plus complexes.
Ensuite, comprenons et comparons les performances spécifiques de ces trois technologies en termes de confidentialité des données. Pour plus de détails, veuillez vous référer à ce qui suit :
(1) Fine-Tuning (fine-tuning)
Fine-Tuning (. réglage fin) ) est que les informations utilisées lors de la formation du modèle sont codées dans les paramètres du modèle. Cela signifie que même si la sortie du modèle est privée pour l'utilisateur, les données d'entraînement sous-jacentes peuvent toujours être divulguées. Les recherches montrent que des attaquants malveillants peuvent même extraire des données d'entraînement brutes des modèles grâce à des attaques par injection. Par conséquent, nous devons supposer que toutes les données utilisées pour entraîner le modèle peuvent être accessibles aux futurs utilisateurs.
(2) Prompt Engineering
En comparaison, l'empreinte de sécurité des données de Prompt Engineering est beaucoup plus petite. Étant donné que les invites peuvent être isolées et personnalisées pour chaque utilisateur, les données contenues dans les invites vues par différents utilisateurs peuvent être différentes. Mais nous devons toujours nous assurer que toutes les données contenues dans l'invite ne sont pas sensibles ou sont autorisées à tout utilisateur ayant accès à l'invite.
(3) RAG (Retrieval Augmentation Generation)
La sécurité de RAG dépend du contrôle d'accès aux données dans son système de récupération sous-jacent. Nous devons nous assurer que la base de données vectorielles sous-jacente et les modèles d'invite sont configurés avec des contrôles de confidentialité et de données appropriés pour empêcher tout accès non autorisé. Ce n’est qu’ainsi que RAG pourra véritablement garantir la confidentialité des données.
Dans l'ensemble, Prompt Engineering et RAG présentent des avantages évidents par rapport au réglage fin en matière de confidentialité des données. Mais quelle que soit la méthode adoptée, nous devons gérer très soigneusement l’accès aux données et la protection de la vie privée pour garantir que les informations sensibles des utilisateurs sont entièrement protégées.
Donc, dans un sens, que l'on choisisse finalement Fine-Tuning, Prompt Engineering ou RAG, l'approche adoptée doit être cohérente avec les objectifs stratégiques de l'organisation, les ressources disponibles, les compétences professionnelles et le retour sur investissement attendu. Il ne s’agit pas seulement de capacités techniques pures, mais également de la façon dont ces approches s’intègrent à notre stratégie commerciale, nos délais, nos flux de travail actuels et les besoins du marché.
Comprendre les subtilités de l'option de réglage fin est essentiel pour prendre des décisions éclairées. Les détails techniques et la préparation des données impliqués dans le réglage fin sont relativement complexes et nécessitent une compréhension approfondie du modèle et des données. Il est donc crucial de travailler en étroite collaboration avec un partenaire possédant une vaste expérience en matière de mise au point. Ces partenaires doivent non seulement disposer de capacités techniques fiables, mais également être capables de comprendre pleinement nos processus et objectifs commerciaux et de choisir les solutions technologiques personnalisées les plus appropriées pour nous.
De même, si nous choisissons d'utiliser Prompt Engineering ou RAG, nous devons également évaluer soigneusement si ces méthodes peuvent correspondre aux besoins de notre entreprise, aux conditions des ressources et aux effets attendus. En fin de compte, le succès ne peut être atteint qu’en garantissant que la technologie personnalisée choisie peut réellement créer de la valeur pour notre organisation.
Référence :
- [1] https://medium.com/@younesh.kc/rag-vs-fine-tuning-in-large-lingual-models-a-comparison-c765b9e21328
- [2] https ://kili-technology.com/large-lingual-models-llms/the-ultimate-guide-to-fine-tuning-llms-2023
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Opérations liées à la couche d'abstraction d'accès aux données PDO en PHP
- La compréhension du langage naturel est un domaine d'application important de l'intelligence artificielle. Quel est son objectif ?
- Quelle est la touche de raccourci pour fusionner des calques dans AI ?
- Quelles sont les principales manifestations de l'intégration de l'intelligence artificielle et de l'éducation ?
- Les Airpods peuvent-ils être connectés à un ordinateur ?