
Maison >Périphériques technologiques >IA >Quelles technologies ByteDance a-t-il derrière la « version chinoise de Sora » incomprise ?
Quelles technologies ByteDance a-t-il derrière la « version chinoise de Sora » incomprise ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-12 22:55:021113parcourir
Début 2024, OpenAI a sorti un blockbuster dans le domaine de l'IA générative : Sora.
Ces dernières années, les itérations technologiques dans le domaine de la génération vidéo ont continué de s'accélérer, et de nombreuses entreprises technologiques ont également annoncé des progrès technologiques et des résultats de mise en œuvre pertinents. Avant cela, Pika et Runway avaient lancé des produits similaires, mais la démo publiée par Sora a clairement élevé à elle seule les standards dans le domaine de la génération vidéo.
Dans le futur concours, on ne sait toujours pas quelle entreprise sera la première à créer un produit qui surpasse Sora.
Ici, en Chine, l'attention se porte sur un certain nombre de grands fabricants de technologies.
Auparavant, il a été rapporté que Bytedance avait développé un modèle de génération vidéo appelé Boximator avant la sortie de Sora.
Boximator fournit un moyen de contrôler précisément la génération d'objets dans les vidéos. Au lieu d'écrire des instructions textuelles complexes, les utilisateurs peuvent simplement dessiner une case dans l'image de référence pour sélectionner la cible, puis ajouter des cases et des lignes supplémentaires pour définir la position finale de la cible ou l'intégralité de la trajectoire de mouvement inter-images, comme indiqué ci-dessous :

ByteDance a fait profil bas à ce sujet. Les personnes concernées ont répondu aux médias que Boximator est leur projet de recherche de méthodes techniques pour contrôler le mouvement des objets dans le domaine de la génération vidéo. Il n'est pas encore entièrement terminé et il existe encore un grand écart entre lui et les principaux modèles étrangers de génération vidéo en termes de qualité d'image, de fidélité et de durée de la vidéo.
Il est mentionné dans le document technique pertinent (https://arxiv.org/abs/2402.01566) que Boximator fonctionne comme un plug-in et peut être facilement intégré aux modèles de génération vidéo existants. En ajoutant des capacités de contrôle de mouvement, il maintient non seulement la qualité vidéo, mais améliore également la flexibilité et la convivialité.
La génération vidéo implique des technologies réparties en plusieurs subdivisions et est étroitement liée à la compréhension de l'image/vidéo, à la génération d'images, à la super-résolution et à d'autres technologies. Après des recherches approfondies, il a été constaté que ByteDance avait publié publiquement certains résultats de recherche dans plusieurs branches.
Cet article présentera 9 études de l'équipe de création intelligente de ByteDance, impliquant les derniers résultats des images de Vincent, des vidéos de Vincent, des vidéos des étudiants de Tu, de la compréhension des vidéos, etc. Autant suivre les progrès technologiques dans l’exploration des modèles visuels génératifs issus de ces études.
Concernant la génération vidéo, quels sont les acquis de Byte ?
Début janvier de cette année, ByteDance a publié un modèle de génération vidéo MagicVideo-V2, qui a déjà déclenché des discussions animées au sein de la communauté.

- Titre de l'article : MagicVideo-V2 : Génération vidéo multi-étapes à haute esthétique
- Lien de l'article : https://arxiv.org/abs/2401.04468
- Adresse du projet : https://magicvideov2.github.io/
L'innovation de MagicVideo-V2 consiste à intégrer un modèle de texte en image, un générateur de mouvement vidéo, un module d'intégration d'image de référence et un module d'interpolation d'image dans le end Dans le pipeline de génération vidéo de bout en bout. Grâce à cette conception architecturale, MagicVideo-V2 peut maintenir des performances stables de haut niveau en termes « d'esthétique », générant non seulement de belles vidéos haute résolution, mais ayant également une fidélité et une fluidité relativement bonnes.
Plus précisément, les chercheurs ont d'abord utilisé le module T2I pour créer une image 1024×1024 qui encapsulait la scène décrite. Le module I2V anime ensuite cette image statique pour générer une séquence d'images de 600 × 600 × 32, le bruit sous-jacent assurant la continuité de l'image initiale. Le module V2V améliore ces images à une résolution de 1048×1048 tout en affinant le contenu vidéo. Enfin, le module d'interpolation étend la séquence à 94 images pour obtenir une vidéo de résolution 1048×1048, et la vidéo générée présente une qualité esthétique et une fluidité temporelle élevées.
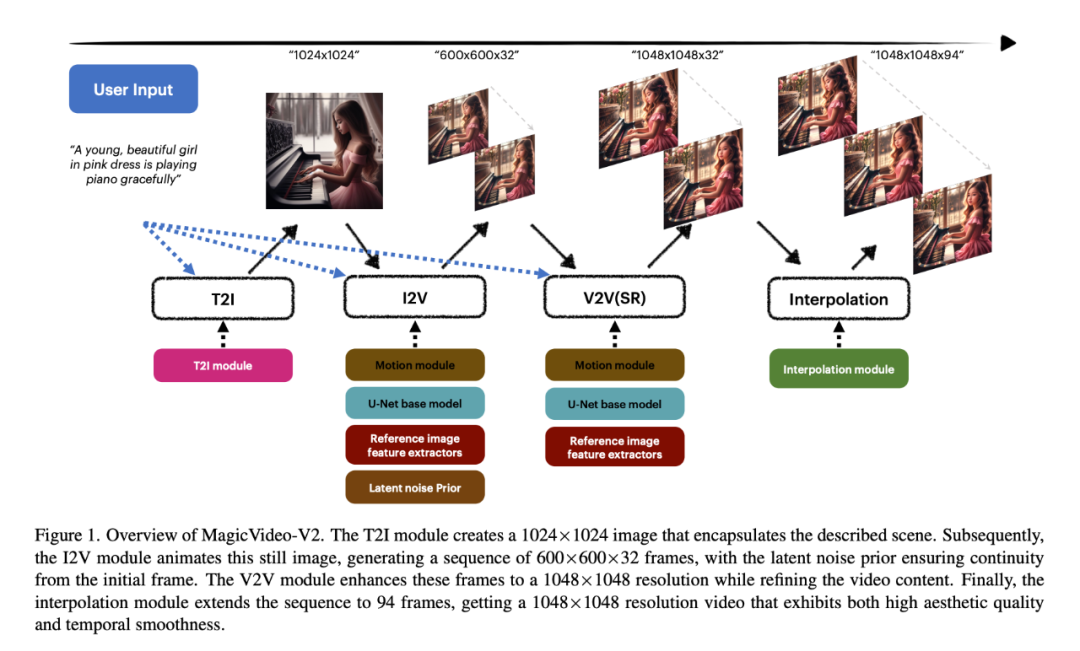
Une évaluation des utilisateurs à grande échelle menée par des chercheurs a prouvé que MagicVideo-V2 est plus populaire que certaines méthodes T2V bien connues (les barres vertes, grises et roses représentent que MagicVideo-V2 est évalué comme meilleur, équivalent ou meilleur respectivement) Différence).

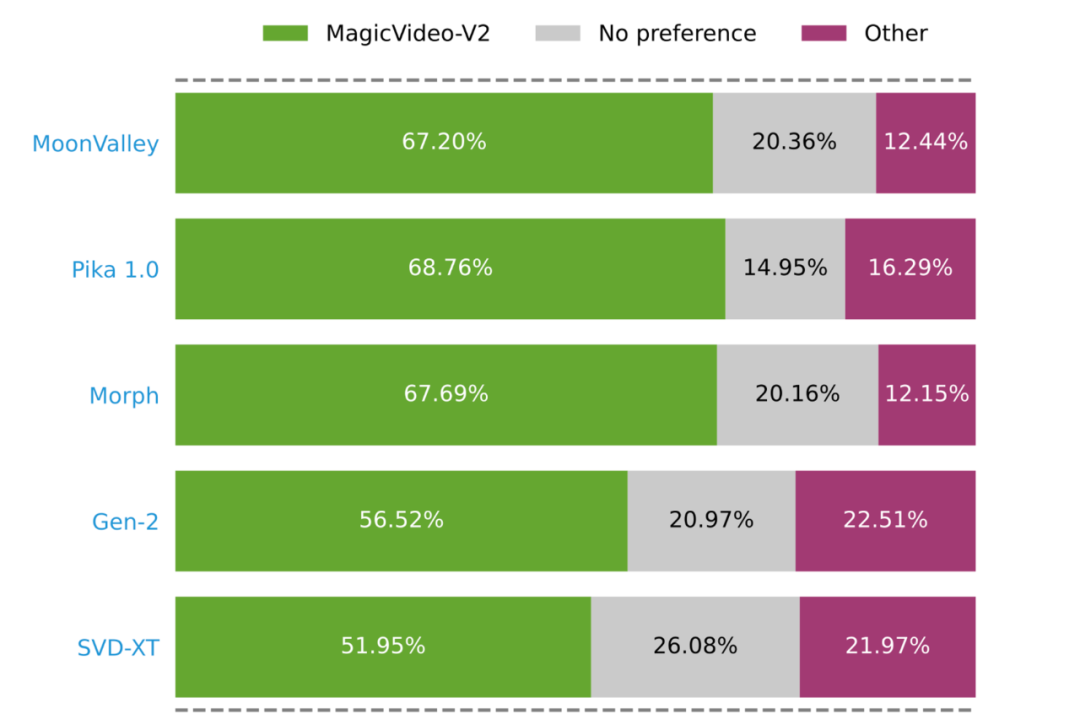
Derrière la génération vidéo de haute qualité
Le paradigme de recherche qui unifie la vision et l'apprentissage des langues
De l'article MagicVideo-V2, nous pouvons voir que les progrès de la technologie de génération vidéo sont indissociables Ouvrir la voie aux technologies AIGC telles que Wenshengtu et Tushengvideo. La base pour générer un contenu de haute esthétique réside dans la compréhension, en particulier l'amélioration de la capacité du modèle à apprendre et à intégrer des modalités visuelles et linguistiques.
Ces dernières années, l'évolutivité et les capacités générales des grands modèles linguistiques ont donné naissance à un paradigme de recherche qui unifie la vision et l'apprentissage des langues. Afin de combler le fossé naturel entre les deux modalités du « visuel » et du « langage », les chercheurs connectent les représentations de grands modèles de langage et de modèles visuels pré-entraînés, extraient des caractéristiques intermodales et accomplissent des tâches telles que la réponse visuelle à des questions, Tâches telles que le sous-titrage d'images, le raisonnement visuel et le dialogue.
Dans ces directions, ByteDance a également réalisé des explorations pertinentes.
Par exemple, pour relever le défi du raisonnement et de la segmentation multi-objectifs dans les tâches de vision en monde ouvert, ByteDance s'est associé à des chercheurs de l'Université Jiaotong de Pékin et de l'Université des sciences et technologies de Pékin pour proposer un pixel- modèle de raisonnement de niveau, PixelLM, et l'a rendu open source.

- Titre de l'article : PixelLM : Pixel Reasoning with Large Multimodal Model
- Lien de l'article : https://arxiv.org/pdf/2312.02228.pdf
- Adresse du projet : https://pixellm.github.io/
PixelLM peut gérer habilement des tâches avec un certain nombre d'objectifs ouverts et différentes complexités de raisonnement. La figure ci-dessous montre PixelLM dans diverses tâches de segmentation. La capacité de générer. masques cibles de haute qualité.

Le cœur de PixelLM est un nouveau décodeur de pixels et un livre de codes de segmentation : le livre de codes contient des jetons apprenables qui codent le contexte et les connaissances liées aux références cibles à différentes échelles visuelles, et le décodeur de pixels est basé sur des intégrations cachées de les jetons de livre de codes et les fonctionnalités d'image génèrent des masques cibles. Tout en conservant la structure de base de LMM, PixelLM peut générer des masques de haute qualité sans modèles de segmentation visuelle supplémentaires et coûteux, améliorant ainsi l'efficacité et la transférabilité vers différentes applications.
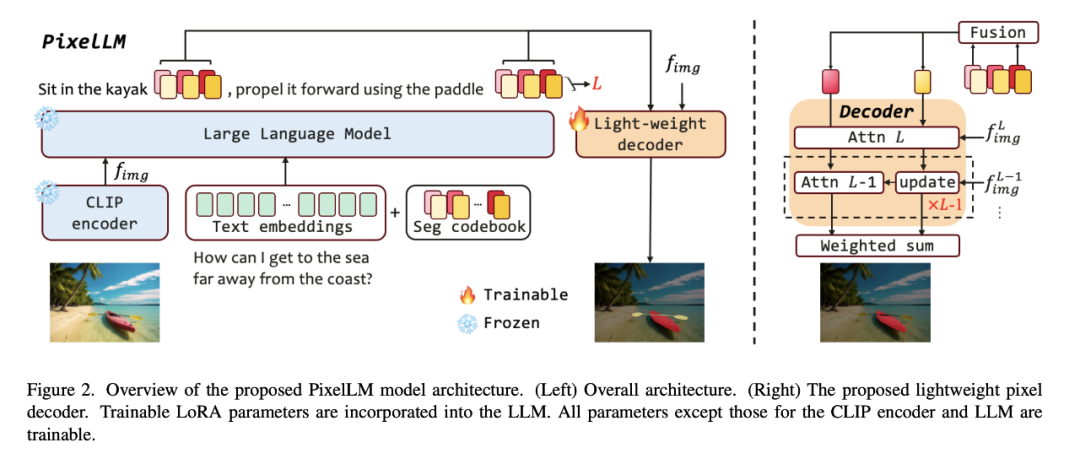
Il convient de noter que les chercheurs ont construit un ensemble complet de données de segmentation d'inférence multi-objectifs MUSE. Ils ont sélectionné un total de 910 000 masques de segmentation d’instance de haute qualité et des descriptions textuelles détaillées basées sur le contenu des images de l’ensemble de données LVIS, et les ont utilisés pour construire 246 000 paires question-réponse.
Par rapport aux images, si du contenu vidéo est impliqué, le modèle sera confronté à beaucoup plus de défis. Parce que la vidéo contient non seulement des informations visuelles riches et variées, mais implique également des changements dynamiques dans les séries temporelles.
Lorsque les grands modèles multimodaux existants traitent du contenu vidéo, ils convertissent généralement les images vidéo en une série de jetons visuels et les combinent avec des jetons de langage pour générer du texte. Cependant, à mesure que la longueur du texte généré augmente, l'influence du contenu vidéo s'affaiblira progressivement, ce qui amènera le texte généré à s'écarter de plus en plus du contenu vidéo original, produisant ce que l'on appelle des « illusions ».
Face à ce problème, Bytedance et l'Université du Zhejiang ont proposé Vista-LLaMA, un grand modèle multimodal spécialement conçu pour la complexité des contenus vidéo.

- Titre de l'article : Vista-LLaMA : Narrateur vidéo fiable via une distance égale aux jetons visuels
- Lien de l'article : https://arxiv.org/pdf/2312.08870.pdf
- Adresse du projet : https://jinxxian.github.io/Vista-LLaMA/
Vista-LLaMA adopte un mécanisme d'attention amélioré - Visual Equidistant Token Attention (EDVT) pour traiter la vision et le texte Le jeton supprime l'encodage de position relative traditionnel tout en conserver le codage de position relative entre le texte. Cette méthode améliore considérablement la profondeur et la précision de la compréhension du contenu vidéo par le modèle de langage.
En particulier, le projecteur visuel sérialisé introduit par Vista-LLaMA offre une nouvelle perspective sur les problèmes d'analyse de séries chronologiques dans les vidéos. Il encode le contexte temporel des jetons visuels via une couche de projection linéaire, améliorant la réponse du modèle aux changements dynamiques. la vidéo.
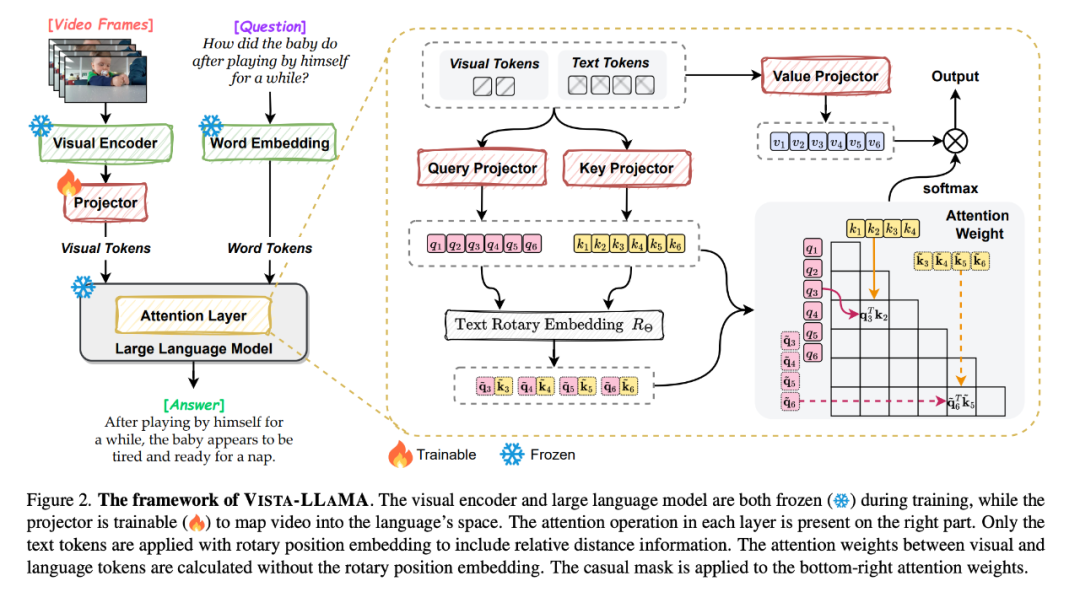
Dans une étude récemment acceptée par l'ICLR 2024, les chercheurs de ByteDance ont également exploré une méthode de pré-entraînement pour améliorer la capacité du modèle à apprendre du contenu vidéo.
En raison de l'échelle et de la qualité limitées du corpus de formation vidéo-texte, la plupart des modèles de base du langage visuel adoptent des ensembles de données image-texte pour la pré-formation et se concentrent principalement sur la modélisation de la représentation sémantique visuelle, tout en ignorant la représentation sémantique temporelle et le sexe de corrélation.
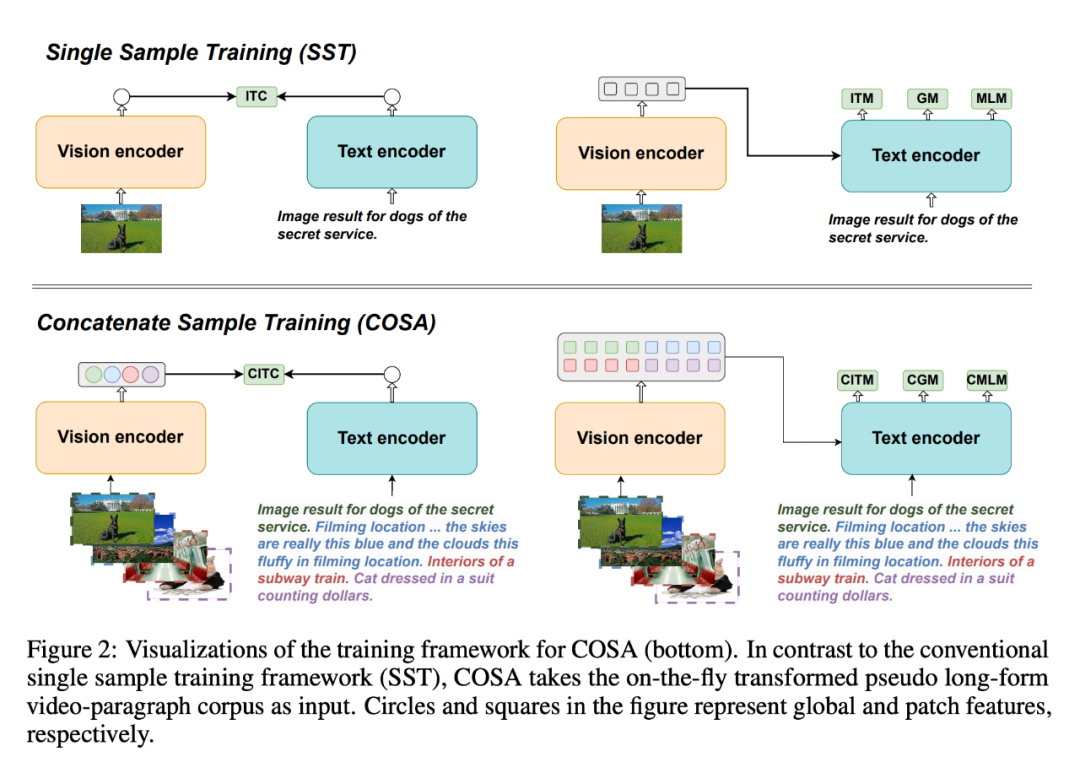
Pour résoudre ce problème, ils ont proposé COSA, un modèle de base de langage visuel pré-entraîné d'échantillons concaténés.

- Titre de l'article : COSA : Concatenated Sample Pretrained Vision-Language Foundation Model
- Lien de l'article : https://arxiv.org/pdf/2306.09085.pdf
- Page d'accueil du projet : https://github.com/TXH-mercury/COSA
COSA modélise conjointement le contenu visuel et les indices temporels au niveau de l'événement en utilisant uniquement des corpus image-texte. Les chercheurs ont concaténé plusieurs paires image-texte en séquence comme entrée pour la pré-formation. Cette transformation convertit efficacement un corpus image-texte existant en un corpus de paragraphes vidéo pseudo-longs, permettant des transitions de scène plus riches et des correspondances explicites de description d'événement. Les expériences démontrent que COSA peut améliorer systématiquement les performances sur une variété de tâches en aval, y compris les tâches de texte vidéo long/court et les tâches de texte image telles que la récupération, les sous-titres et la réponse aux questions.

De l'image à la vidéo
Le "modèle de diffusion" reconnu
En plus du modèle visuo-linguistique, le modèle de diffusion est également une technologie utilisée par la plupart des vidéos modèles de génération.
Grâce à une formation rigoureuse sur de grands ensembles de données appariés image-texte, les modèles de diffusion sont capables de générer des images détaillées entièrement basées sur des informations textuelles. En plus de la génération d'images, les modèles de diffusion peuvent également être utilisés pour la génération audio, la génération de séries chronologiques, la génération de nuages de points 3D, etc.
Par exemple, dans certaines applications vidéo courtes, les utilisateurs n'ont qu'à fournir une image pour générer une fausse vidéo d'action.
Mona Lisa, qui conserve un sourire mystérieux depuis des centaines d'années, peut commencer à courir immédiatement :

La technologie derrière cette application intéressante est le fruit d'un effort conjoint de chercheurs de l'Université nationale de Singapour et de ByteDance. "MagicAnimate" lancé.
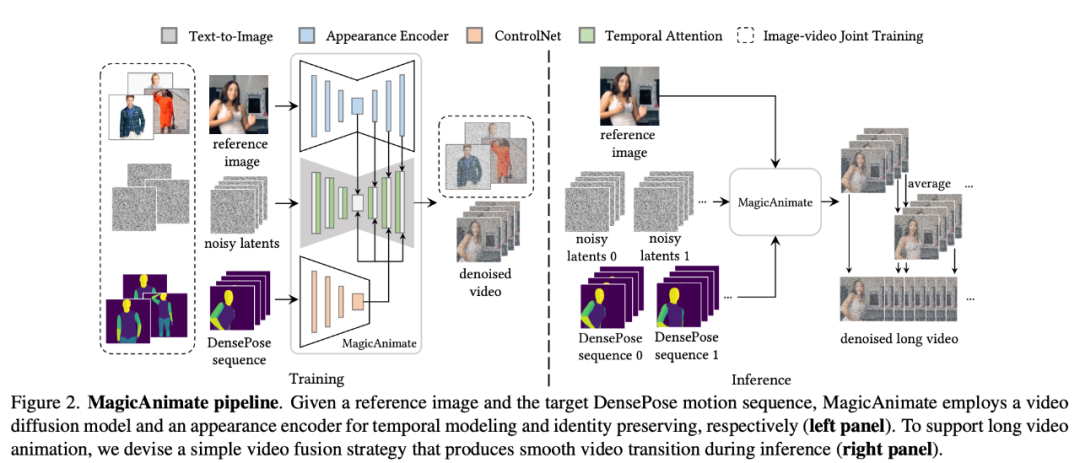
MagicAnimate est un cadre d'animation d'images humaines basé sur la diffusion qui peut bien garantir la cohérence temporelle de l'ensemble de l'animation et améliorer la fidélité de l'animation dans la tâche de génération de vidéos basées sur des séquences de mouvements spécifiques. De plus, le projet MagicAnimate est open source.

- Titre de l'article : MagicAnimate : Animation d'images humaines temporellement cohérentes à l'aide du modèle de diffusion
- Lien de l'article : https://arxiv.org/pdf/2311.16498.pdf
- Adresse du projet : https://showlab.github.io/magicanimate/
Afin de résoudre le problème courant de « scintillement » des animations générées, les chercheurs ont fusionné le bloc d'attention temporelle (attention temporelle) dans l'épine dorsale de diffusion network , pour construire un modèle de diffusion vidéo pour la modélisation temporelle.
MagicAnimate décompose la vidéo entière en segments qui se chevauchent et fait simplement la moyenne des prédictions des images qui se chevauchent. Enfin, les chercheurs ont également introduit une stratégie de formation conjointe image-vidéo pour améliorer encore la capacité de rétention d’image de référence et la fidélité d’une seule image. Bien que formé uniquement sur des données humaines réelles, MagicAnimate a démontré sa capacité à se généraliser à une variété de scénarios d'application, notamment l'animation de données de domaine invisibles, l'intégration avec des modèles de diffusion texte-image et l'animation multi-personnes.
Une autre recherche basée sur l'idée du modèle de diffusion "DREAM-Talk" résout le problème de générer des visages émotionnels parlants à partir d'une seule image de portrait.

- Titre de l'article : DREAM-Talk : Méthode audio émotionnelle réaliste basée sur la diffusion pour la génération de visages parlants à image unique
- Lien de l'article : https://arxiv.org /pdf/2312.13578.pdf
- Adresse du projet : https://dreamtalkemo.github.io/
Nous savons que dans cette tâche, il est difficile d'atteindre simultanément un dialogue émotionnel expressif et une synchronisation labiale précise , généralement afin d'assurer la précision de la synchronisation labiale, l'expressivité est souvent considérablement réduite.
« DREAM-Talk » est un cadre audio basé sur la diffusion, divisé en deux étapes : Premièrement, les chercheurs ont proposé un nouveau module de diffusion EmoDiff, qui peut générer une variété de modèles hautement dynamiques basés sur l'audio et référencer des émotions. styles. Expressions émotionnelles et posture de la tête. Compte tenu de la forte corrélation entre les mouvements des lèvres et l'audio, les chercheurs ont ensuite amélioré la dynamique en utilisant des fonctionnalités audio et des styles émotionnels pour améliorer la précision de la synchronisation labiale, et ont également déployé un module de rendu vidéo à vidéo pour transférer les expressions et les mouvements des lèvres vers n'importe quel portrait.
Du point de vue des effets, DREAM-Talk est effectivement bon en termes d'expressivité, de précision de synchronisation labiale et de qualité perçue :

Mais qu'il s'agisse de génération d'images ou de génération de vidéos, le modèle de diffusion actuel La recherche se heurte encore à des défis fondamentaux qui doivent être relevés.
Par exemple, de nombreuses personnes s'inquiètent de la qualité du contenu généré (correspondant à SAG, DREAM-Talk). Cela peut être lié à certaines étapes du processus de génération du modèle de diffusion, comme l'échantillonnage guidé.
L'échantillonnage guidé dans les modèles de diffusion peut être grossièrement divisé en deux catégories : ceux qui nécessitent une formation et ceux qui ne nécessitent pas de formation. L'échantillonnage guidé sans formation utilise des réseaux pré-entraînés prêts à l'emploi (tels que des modèles d'évaluation esthétique) pour guider le processus de génération, dans le but d'obtenir des connaissances à partir des modèles pré-entraînés avec moins d'étapes et une plus grande précision. Les algorithmes d'échantillonnage non guidés par entraînement actuels sont basés sur une estimation en une étape d'images propres pour obtenir la fonction d'énergie de guidage. Cependant, étant donné que le réseau pré-entraîné est formé sur des images propres, le processus d'estimation en une étape pour les images propres peut être inexact, en particulier dans les premiers stades du modèle de diffusion, ce qui entraîne un guidage inexact aux premiers pas de temps.
En réponse à ce problème, des chercheurs de ByteDance et de l'Université nationale de Singapour ont proposé conjointement le Symplectic Adjoint Guidance (SAG).

- Titre de l'article : Vers un échantillonnage par diffusion guidée précis grâce à la méthode adjointe symplégique
- Lien de l'article : https://arxiv.org/pdf/2312.12030.pdf
SAG Le guidage du gradient est calculé en deux étapes internes : premièrement, SAG estime une image propre via n appels de fonction, où n sert de paramètre flexible qui peut être ajusté en fonction des exigences spécifiques de qualité d'image. Deuxièmement, SAG utilise la méthode double symétrique pour obtenir des gradients par rapport aux besoins en mémoire avec précision et efficacité. Cette approche peut prendre en charge diverses tâches de génération d'images et de vidéos, notamment la génération d'images guidées par le style, l'amélioration esthétique et la stylisation vidéo, et améliore efficacement la qualité du contenu généré.
Un article récemment sélectionné pour l'ICLR 2024 se concentre sur la "méthode de sensibilité critique de la rétropropagation du gradient du modèle de probabilité de diffusion".

- Titre de l'article : Méthode de sensibilité adjointe pour la rétropropagation par gradient des modèles probabilistes de diffusion
- Lien de l'article : https://arxiv.org/pdf/2307.107 1 1.pdf
Étant donné que le processus d'échantillonnage du modèle de probabilité de diffusion implique des appels récursifs au U-Net de débruitage, la rétropropagation naïve du gradient doit stocker les états intermédiaires de toutes les itérations, ce qui entraîne une consommation de mémoire extrêmement élevée.
Dans cet article, l'AdjointDPM proposé par les chercheurs génère d'abord de nouveaux échantillons à partir du modèle de diffusion en résolvant l'ODE de flux probabiliste correspondant. Ensuite, le gradient de perte des paramètres du modèle (y compris les signaux de conditionnement, les poids du réseau et le bruit initial) est rétropropagé à l'aide de la méthode de sensibilité de contiguïté en résolvant une autre ODE augmentée. Afin de réduire les erreurs numériques lors de la génération directe et de la rétropropagation du gradient, les chercheurs ont reparamétré davantage l'ODE à flux probabiliste et l'ODE amélioré en ODE simples non rigides utilisant l'intégration exponentielle.
Les chercheurs soulignent qu'AdjointDPM est extrêmement utile dans trois tâches : convertir les effets visuels en intégrations de texte reconnues, affiner les modèles probabilistes de diffusion pour des types spécifiques de stylisation et optimiser le bruit initial pour générer des exemples contradictoires pour les audits de sécurité afin de réduire le coût des travaux d'optimisation.
Pour les tâches de perception visuelle, la méthode d'utilisation du modèle de diffusion texte-image comme extracteur de caractéristiques a également reçu de plus en plus d'attention. Dans ce sens, les chercheurs de ByteDance ont proposé une solution simple et efficace dans leur article.

- Exploiter les modèles de diffusion pour la perception visuelle avec des méta-invites
- Lien de l'article : https://arxiv.org/pdf/2312.14733.pdf
Ceci L'innovation principale de cet article est l'introduction d'intégrations apprenables (méta-indices) dans des modèles de diffusion pré-entraînés pour extraire des caractéristiques perceptuelles, sans s'appuyer sur des modèles multimodaux supplémentaires pour générer des légendes d'images, ni utiliser d'étiquettes de catégorie dans l'ensemble de données.
Les méta-indices servent à deux fins : premièrement, en remplacement direct des intégrations de texte dans les modèles T2I, ils peuvent activer des fonctionnalités pertinentes pour la tâche lors de l'extraction des fonctionnalités. Deuxièmement, ils seront utilisés pour réorganiser les fonctionnalités extraites, afin de garantir que le Le modèle se concentre sur les fonctionnalités les plus pertinentes pour la tâche à accomplir. En outre, les chercheurs ont également conçu une stratégie de formation de raffinement cyclique pour utiliser pleinement les caractéristiques du modèle de diffusion afin d’obtenir des caractéristiques visuelles plus fortes.
Jusqu'où reste-t-il à parcourir avant la naissance de la "version chinoise de Sora"
?
Dans ces nouveaux articles, nous avons découvert une série d'explorations actives dans la technologie de génération vidéo par des sociétés technologiques nationales comme ByteDance.
🎜Mais par rapport à Sora, qu'il s'agisse de ByteDance ou d'un certain nombre d'entreprises stars dans le domaine de la génération vidéo IA, il y a un écart visible à l'œil nu. Les avantages de Sora reposent sur sa croyance dans la loi de mise à l'échelle et sur une innovation technologique révolutionnaire : en unifiant les données vidéo via des correctifs, en s'appuyant sur des architectures techniques telles que Diffusion Transformer et les capacités de compréhension sémantique de DALL・E 3, il a véritablement atteint « une longueur d'avance ».
De l'explosion de Wenshengtu en 2022 à l'émergence de Sora en 2024, la vitesse d'itération technologique dans le domaine de l'intelligence artificielle a dépassé l'imagination de chacun. En 2024, je pense qu’il y aura davantage de « produits phares » dans ce domaine.
Byte intensifie évidemment également ses investissements dans la recherche et le développement technologique. Récemment, Jiang Lu, chef du projet Google VideoPoet, et Chunyuan Li, membre de l'équipe LLaVA de grands modèles multimodaux open source et ancien chercheur en chef de Microsoft Research, ont tous révélé avoir rejoint l'équipe de création intelligente de ByteDance. L'équipe recrute également vigoureusement et un certain nombre de postes liés aux algorithmes de grands modèles ont été publiés sur le site officiel.
Non seulement Byte, d'anciens géants tels que BAT ont également publié de nombreux résultats de recherche accrocheurs sur la génération vidéo, et un certain nombre de startups de grande envergure sont encore plus agressives. Quelles nouvelles avancées seront réalisées dans Vincent Video Technology ? Nous verrons.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment organiser les icônes dans Windows
- Raisons pour lesquelles l'IA ne peut pas colorier en temps réel
- Comment réorganiser les identifiants dans MySQL
- Quel modèle de données la plupart des systèmes de gestion de bases de données utilisent-ils actuellement ?
- Quelle est la différence entre raid 0 1 5 10