Le 11 mars, Lingyiwu a annoncé le lancement d'une nouvelle base de données vectorielle "Descartes" basée sur des graphiques de navigation complets, qui a remporté la première place dans 6 évaluations d'ensembles de données de la liste faisant autorité ANN-Benchmarks. La base de données vectorielles, également connue sous le nom de technologie de récupération d'informations à l'ère de l'IA, est l'une des technologies de base de la génération de récupération augmentée (RAG). Pour les développeurs d'applications de grands modèles, la base de données vectorielles est une infrastructure très importante, qui affecte dans une certaine mesure les performances des grands modèles. Dans le test hors ligne de la plateforme d'évaluation internationale faisant autorité ANN-Benchmarks, la base de données vectorielles Zero One Descartes s'est classée première dans l'évaluation de 6 ensembles de données, ce qui est mieux que la première place de l'industrie sur la liste précédente . Amélioration significative des performances, l'amélioration des performances sur certains ensembles de données dépasse même 2 fois. Zero One Everything signifie que la base de données vectorielles cartésiennes sera utilisée dans les produits d'IA qui seront officiellement lancés dans un avenir proche, et sera également fournie aux développeurs en combinaison avec des outils dans le futur. La base de données vectorielles devient une infrastructure AI 2.0A gagné les faveurs du marché des capitauxAvec l'arrivée de l'ère de l'IA 2.0 représentée par de grands modèles, des informations multimodales telles que images, vidéos et langages naturels La quantité de données non structurées a fortement augmenté, ce qui diffère des bases de données traditionnelles utilisées pour traiter des données structurées. La base de données vectorielle est spécialement utilisée pour stocker, gérer, interroger et récupérer des données vectorisées non structurées ; elle s'apparente à un disque mémoire externe qui peut être appelé à tout moment par les grands modèles pour former une « mémoire à long terme », également surnommée mémoire des grands modèles. hippocampe". Les grands modèles ont naturellement quatre défauts. Les bases de données vectorielles sont comme des « médicaments spéciaux » sur mesure qui peuvent résoudre avec précision chaque problème.
- Informations en temps réel : la formation des grands modèles prend beaucoup de temps, se met à jour lentement, ne peut pas refléter les dernières informations et ses connaissances sont confrontées au défi du « délai ». La base de données vectorielles adopte un mécanisme de mise à jour léger qui peut rapidement compléter les dernières informations.
- Protection de la vie privée : les données sécurisées et privées des utilisateurs ne doivent pas être fournies directement à la formation de grands modèles, sinon il y aura un risque de fuite. Les données vectorielles résolvent la difficulté de la protection de la vie privée en agissant comme support intermédiaire pour la transmission des informations. l’étape d’inférence.
- Correction des illusions : les phénomènes de distorsion d'inférence ou d'hallucination souvent présentés par les grands modèles peuvent être efficacement corrigés et atténués grâce à la riche référence de connaissances fournie par la base de données vectorielles.
- Efficacité de l'inférence : les coûts d'inférence des grands modèles sont élevés et la base de données vectorielles peut être utilisée comme mécanisme de mise en cache pour éviter d'avoir à réexécuter des calculs d'inférence complexes pour chaque requête de requête, économisant ainsi considérablement les ressources informatiques.
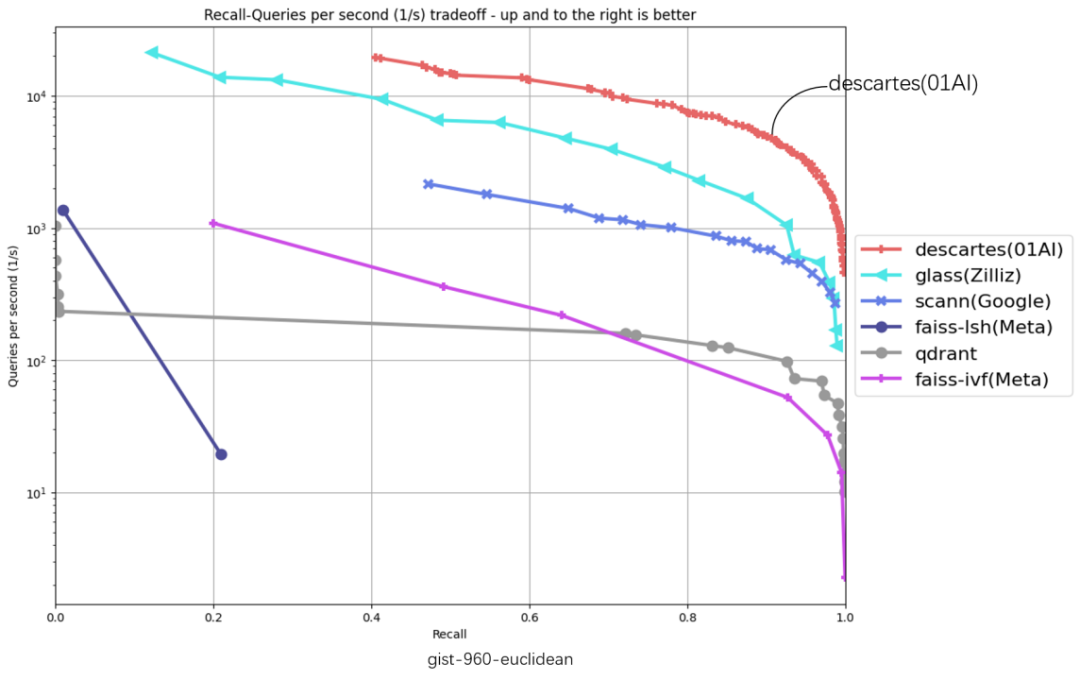
Les changements technologiques et les changements de plateforme initiés par l'IA 2.0 ont encore renforcé le rôle des bases de données vectorielles. Des produits connexes de grands fabricants tels que Google, Microsoft et Meta sont sortis les uns après les autres, et des startups telles que Zilliz, Pinecone, Weaviate et Qdrant ont également vu le jour. En 2023, Pinecone, partenaire de bases de données vectorielles d'OpenAI, a finalisé un financement de série B de 138 millions de dollars américains, et la start-up nationale Fabarta ArcNeural a également finalisé un cycle de financement pré-A de plusieurs centaines de millions de yuans. "Défiez la liste faisant autorité" algorithmes dans différentes situations réelles sur l’ensemble de données. Les 6 ensembles de données d'évaluation suivants couvrent le gant-25-angulaire, le gant-100-angulaire, le tamis-128-euclidien, le nytimes-256-angulaire, le fashion-mnist-784-euclidean, le gist-960-euclidean Six principaux ensembles de données, l'abscisse représente le rappel et l'ordonnée représente le QPS (nombre de requêtes traitées par seconde). Plus la position de la courbe est proche du coin supérieur droit, meilleures sont les performances de l'algorithme. dans 6 ensembles de données se situent au niveau le plus élevé de l’évaluation. 
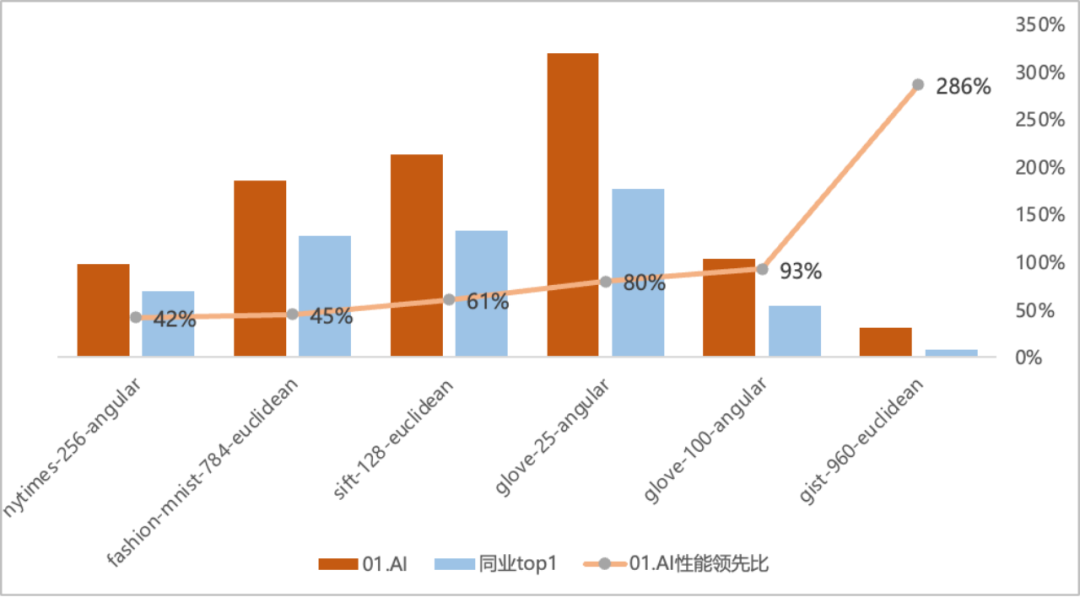
Le « débit QPS » est une mesure de la récupération d'informations. Un indicateur important des capacités de traitement des requêtes d'un système (tel qu'un moteur de recherche ou base de données). Sur la base du TOP1 de la liste originale, la base de données vectorielles cartésienne Zero-One Everything a obtenu des améliorations de performances significatives sur certains ensembles de données. Dans la dimension de l'ensemble de données Gist-960-euclidienne, elle est nettement en avance. du TOP1 original de la liste 286%.卡 0 million de bases de données vectorielles Sheccart et la liste originale Comparaison des performances TOP1 QPS Secrets techniques
Comment révéler comment Descartes atteint l'excellente performance ci-dessus ? Comme nous le savons tous, RAG est une technologie qui combine récupération et génération. Elle améliore les capacités de génération des modèles de langage en récupérant les informations interrogées à partir de données massives. Semblable aux méthodes de récupération traditionnelles, la récupération de vecteurs RAG résout principalement deux problèmes majeurs : 1 Réduire l'ensemble des candidats pour l'inspection de récupération en établissant une certaine structure d'index ; la complexité.
La base de données vectorielles cartésiennes Zero-One présente des avantages comparatifs significatifs par rapport à l'industrie dans le traitement de requêtes complexes, l'amélioration de l'efficacité de la récupération et l'optimisation du stockage des données. Concernant la première question, l'équipe Zero One World compte deux tueurs majeurs :
- Technologie de pointe de navigation complète. La situation actuelle dans l'industrie est principalement due au hachage, au KD-Tree, au VP-Tree et à d'autres méthodes. L'effet de navigation n'est pas assez précis et la force de recadrage n'est pas suffisante. La technologie globale de navigation par vignettes multicouches développée par Zero One. Wanwu et la navigation par système de coordonnées sur la carte peuvent à la fois garantir la précision et couper un grand nombre de vecteurs non pertinents.
- La première stratégie de sélection adaptative des voisins pour combler le vide de l'industrie. La stratégie de sélection adaptative des voisins développée par 01Wuxing dépasse les limites du recours aux stratégies de sélection de topk réels ou de bords fixes dans le passé. La nouvelle stratégie permet à chaque nœud de sélectionner dynamiquement les meilleurs bords voisins en fonction de ses caractéristiques de distribution. et ses voisins, converge plus rapidement vers le vecteur cible, améliorant ainsi les performances de récupération du vecteur RAG de 15 à 30 %.
Pour la deuxième question, Zero One Wish adopte un schéma de quantification à deux niveaux RAG amélioré. Zero One Thousand utilise une quantification à deux niveaux pour réduire la complexité de calcul. Dans le même temps, le stockage en colonnes utilise pleinement les capacités de concurrence de SIMD pour exploiter davantage les capacités matérielles. Par rapport à la recherche de table PQ traditionnelle, les performances sont considérablement améliorées, jusqu'à 2 à 3 fois. . De plus, Zero One Wish propose également des solutions technologiques vectorielles full-stack telles que l'optimisation de la structure d'index et la garantie de connectivité pour améliorer les performances des bases de données vectorielles cartésiennes. Technologie vectorielle full stack : une plus grande précision et des performances plus fortesAvec le support de la technologie vectorielle full stack ci-dessus, la base de données de vecteurs cartésiens Zero One Thousand n'est pas seulement en tête de la liste faisant autorité ANN - Classée première dans 6 revues de références. Il présente également des avantages essentiels tels qu’une plus grande précision et des performances plus élevées dans des scénarios d’application pratiques. Zero One Everything Cartesian Vector Database se concentre actuellement sur les bases de données vectorielles hautes performances. Les bases de données vectorielles hautes performances font généralement référence à des ensembles de données vectorielles avec des échelles de dizaines de millions ou moins (comme 20 millions de vecteurs à virgule flottante de 128 dimensions. De manière générale, les bases de données vectorielles hautes performances peuvent facilement gérer 80 à 90 % des données quotidiennes). Par exemple, il aide les entreprises clientes à créer des bases de connaissances dans le domaine privé et des systèmes de service client intelligents ; dans le domaine de la conduite autonome, l'utilisation de bases de données vectorielles hautes performances peut accélérer la formation des modèles de conduite autonome, etc. La base de données vectorielles haute performance Zero One Thousand présente les avantages suivants :
- Ultra-haute précision : Basée sur des vignettes et des systèmes de coordonnées multicouches, une navigation inter-couches et sur la carte la navigation d'orientation est réalisée, la connectivité est garantie et la précision est supérieure à 99 %. Avec les mêmes performances, la précision est nettement en avance sur le niveau de l'industrie.
- Super haute performance : Technologie efficace de sélection des bords et de recadrage, des dizaines de millions de réponses ms de base de données.
Prenons comme exemple le scénario de recommandation du commerce électronique. Le nombre de produits en rayon peut atteindre des dizaines de millions, et chaque produit peut être exprimé par un vecteur. Même si le nombre de vecteurs dans la bibliothèque n'est pas très important, si la base d'utilisateurs du commerce électronique est très importante et que le nombre de requêtes des utilisateurs par seconde aux heures de pointe est très important, il peut atteindre des centaines de milliers, voire des millions de QPS. . L'utilisation de bases de données vectorielles hautes performances peut améliorer efficacement l'effet de recommandation des services de recherche et de publicité dans les scénarios de commerce électronique, rendant tout le monde incapable de s'empêcher de continuer à acheter. Zero One Everything Representation, base de données vectorielles cartésiennes, est la première tentative de l'équipe basée sur RAG et sera utilisée efficacement dans les produits de productivité d'IA publiés dans un avenir proche. À l'avenir, une fois que chaque modèle majeur aura été optimisé dans une certaine mesure, les capacités de la base de données vectorielles pourront déterminer le plafond de chaque modèle majeur. Zero One Wish continuera à se concentrer sur la R&D et le partage à l'avenir pour offrir une meilleure technologie et une meilleure expérience aux utilisateurs. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!