
Maison >Périphériques technologiques >IA >Tsinghua NLP Group a publié InfLLM : Aucune formation supplémentaire requise, « 1024K contexte ultra-long » rappel à 100 % !
Tsinghua NLP Group a publié InfLLM : Aucune formation supplémentaire requise, « 1024K contexte ultra-long » rappel à 100 % !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-11 14:40:04980parcourir
Les grands modèles ne peuvent mémoriser et comprendre qu'un contexte limité, ce qui est devenu une limitation majeure dans leurs applications pratiques. Par exemple, les systèmes d'IA conversationnelle sont souvent incapables de mémoriser de manière persistante le contenu des conversations de la veille, ce qui se traduit par des agents construits à l'aide de grands modèles présentant un comportement et une mémoire incohérents.
Pour permettre aux grands modèles de mieux gérer des contextes plus longs, les chercheurs ont proposé une nouvelle méthode appelée InfLLM. Cette méthode, proposée conjointement par des chercheurs de l'Université Tsinghua, du MIT et de l'Université Renmin, permet aux grands modèles linguistiques (LLM) de traiter des textes extrêmement longs sans formation supplémentaire. InfLLM utilise une petite quantité de ressources informatiques et de mémoire graphique pour obtenir un traitement efficace de textes très longs.

Adresse papier : https://arxiv.org/abs/2402.04617
Référentiel de codes : https://github.com/thunlp/InfLLM
Les résultats expérimentaux montrent qu'InfLLM peut être efficace Il élargit considérablement la fenêtre de traitement du contexte de Mistral et LLaMA et atteint un rappel à 100 % dans la tâche de recherche d'une aiguille dans une botte de foin de 1024 000 contextes.
Contexte de recherche
Les modèles linguistiques pré-entraînés (LLM) à grande échelle ont fait des progrès révolutionnaires dans de nombreuses tâches ces dernières années et sont devenus le modèle de base pour de nombreuses applications.
Ces applications pratiques posent également des défis plus importants quant à la capacité des LLM à traiter de longues séquences. Par exemple, un agent piloté par LLM doit traiter en permanence les informations reçues de l’environnement externe, ce qui nécessite qu’il dispose de capacités de mémoire plus puissantes. Dans le même temps, l’IA conversationnelle doit mieux mémoriser le contenu des conversations avec les utilisateurs afin de générer des réponses plus personnalisées.
Cependant, les modèles à grande échelle actuels ne sont généralement pré-entraînés que sur des séquences contenant des milliers de jetons, ce qui entraîne deux défis majeurs lorsqu'ils sont appliqués à des textes très longs :
1. length : L'application directe de LLM à des textes plus longs nécessite souvent que les LLM traitent l'encodage de position au-delà de la plage de formation, ce qui entraîne des problèmes de non-distribution et un échec de généralisation
2. Un contexte trop long entraînera une distraction excessive de l'attention du modèle vers des informations non pertinentes, rendant impossible la modélisation efficace des dépendances sémantiques à long terme dans le contexte. Introduction à la méthode
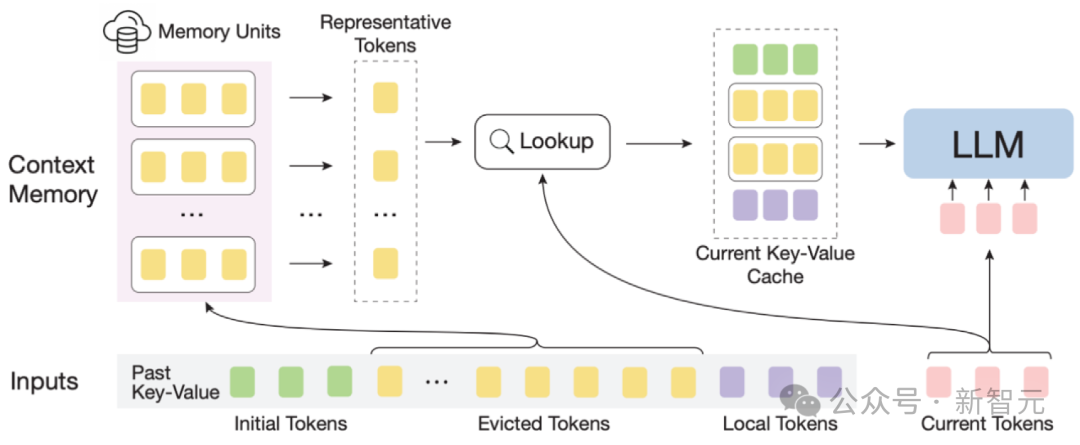 Schéma InfLLM
Schéma InfLLM
Afin d'atteindre efficacement la capacité de généralisation de la longueur des grands modèles, l'auteur a proposé une méthode d'amélioration de la mémoire sans formation, InfLLM, pour le traitement en streaming de séquences super longues.
InfLLM vise à stimuler la capacité intrinsèque des LLM à capturer les dépendances sémantiques à longue distance dans des contextes ultra-longs avec un coût de calcul limité, permettant ainsi une compréhension efficace de textes longs.
Cadre global : compte tenu de la rareté de l'attention portée aux textes longs, le traitement de chaque jeton ne nécessite généralement qu'une petite partie de son contexte.
L'auteur a construit un module de mémoire externe pour stocker des informations contextuelles ultra longues ; à l'aide d'un mécanisme de fenêtre coulissante, à chaque étape de calcul, seuls les jetons (jetons locaux) proches du jeton actuel sont liés à une petite quantité dans les informations du module de mémoire externe sont impliquées dans le calcul de la couche d'attention, tandis que les autres bruits non pertinents sont ignorés.
Ainsi, les LLM peuvent utiliser une taille de fenêtre limitée pour comprendre l'intégralité de la longue séquence et éviter d'introduire du bruit.
Cependant, le contexte massif dans les séquences ultra-longues pose des défis importants en termes de localisation efficace des informations associées et d'efficacité de la recherche en mémoire dans le module de mémoire.
Afin de relever ces défis, chaque unité de mémoire du module de mémoire contextuelle est constituée d'un bloc sémantique, et un bloc sémantique est constitué de plusieurs Tokens consécutifs.
Plus précisément, (1) Afin de localiser efficacement les unités de mémoire pertinentes, la sémantique cohérente de chaque bloc sémantique peut répondre plus efficacement aux besoins des requêtes d'informations associées que les jetons fragmentés.
De plus, l'auteur sélectionne le Token sémantiquement le plus important de chaque bloc sémantique, c'est-à-dire le Token qui reçoit le score d'attention le plus élevé, comme représentation du bloc sémantique. Cette méthode permet d'éviter les inexactitudes dans le calcul de corrélation. . Interférence provenant de jetons importants.
(2) Pour une recherche de mémoire efficace, l'unité de mémoire au niveau du bloc sémantique évite les calculs de corrélation jeton par jeton et attention par attention, réduisant ainsi la complexité de calcul.
De plus, les unités de mémoire sémantiques au niveau des blocs garantissent un accès continu à la mémoire et réduisent les coûts de chargement de la mémoire.
Grâce à cela, l'auteur a conçu un mécanisme de déchargement efficace (Offloading) pour le module de mémoire contextuelle.
Considérant que la plupart des unités de mémoire sont rarement utilisées, InfLLM décharge toutes les unités de mémoire vers la mémoire du processeur et conserve dynamiquement les unités de mémoire fréquemment utilisées dans la mémoire du GPU, réduisant ainsi considérablement l'utilisation de la mémoire vidéo.
InfLLM peut être résumé comme suit :
1 Sur la base de la fenêtre coulissante, ajoutez un module de mémoire contextuelle à longue portée.
2. Divisez le contexte historique en morceaux sémantiques pour former des unités de mémoire dans le module de mémoire contextuelle. Chaque unité de mémoire détermine un jeton représentatif par l'intermédiaire de son score d'attention dans le calcul d'attention précédent, en tant que représentation de l'unité de mémoire. Évitant ainsi les interférences sonores dans le contexte et réduisant la complexité des requêtes de mémoire
Analyse expérimentale
L'auteur l'a appliqué sur les modèles Mistral-7b-Inst-v0.2 (32K) et Vicuna-7b-v1.5 (4K) InfLLM , utilise des tailles de fenêtre locales de 4K et 2K respectivement.
Par rapport au modèle original, à l'interpolation de codage positionnel, à Infinite-LM et à StreamingLLM, des améliorations significatives des performances ont été obtenues sur les données de texte long Infinite-Bench et Longbench.
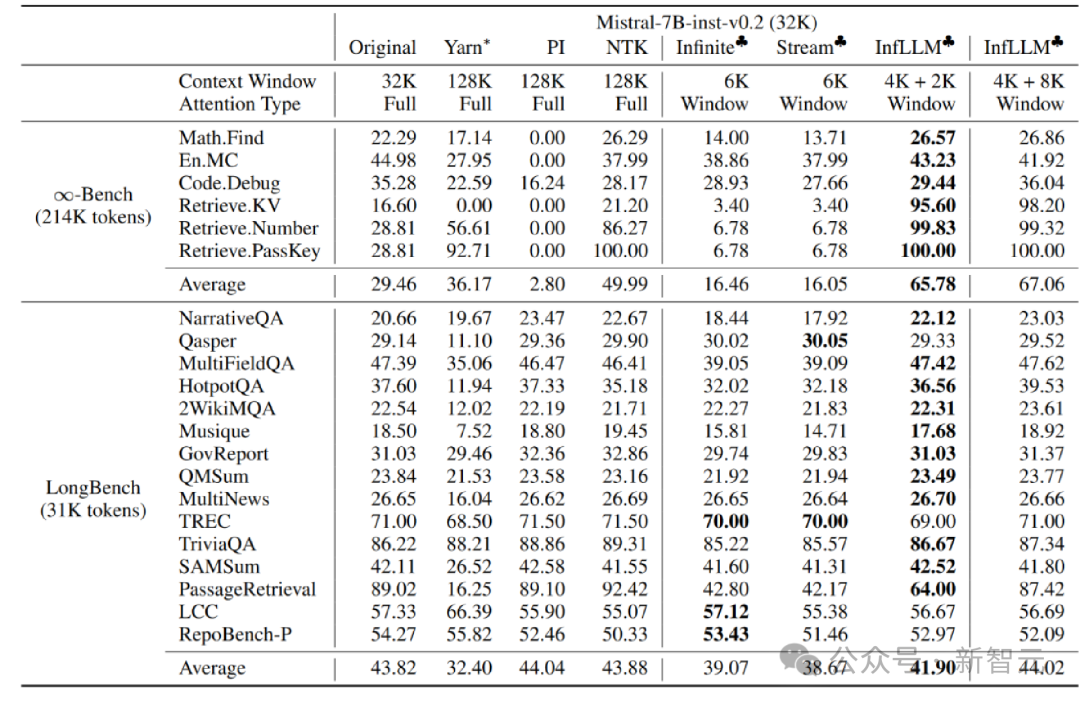
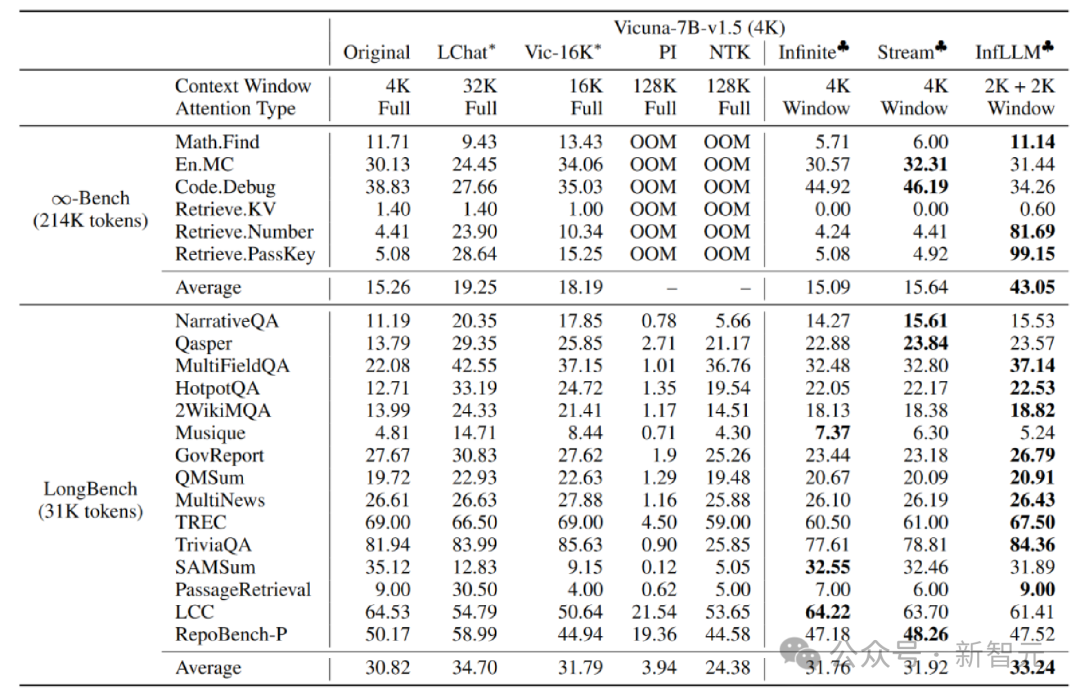
Expérience sur des textes très longs
De plus, l'auteur a continué à explorer la capacité de généralisation d'InfLLM sur des textes plus longs, et il peut toujours fonctionner dans le style "une aiguille dans une botte de foin". " tâche d'une longueur de 1 024 Ko Maintenir un taux de rappel de 100 %.
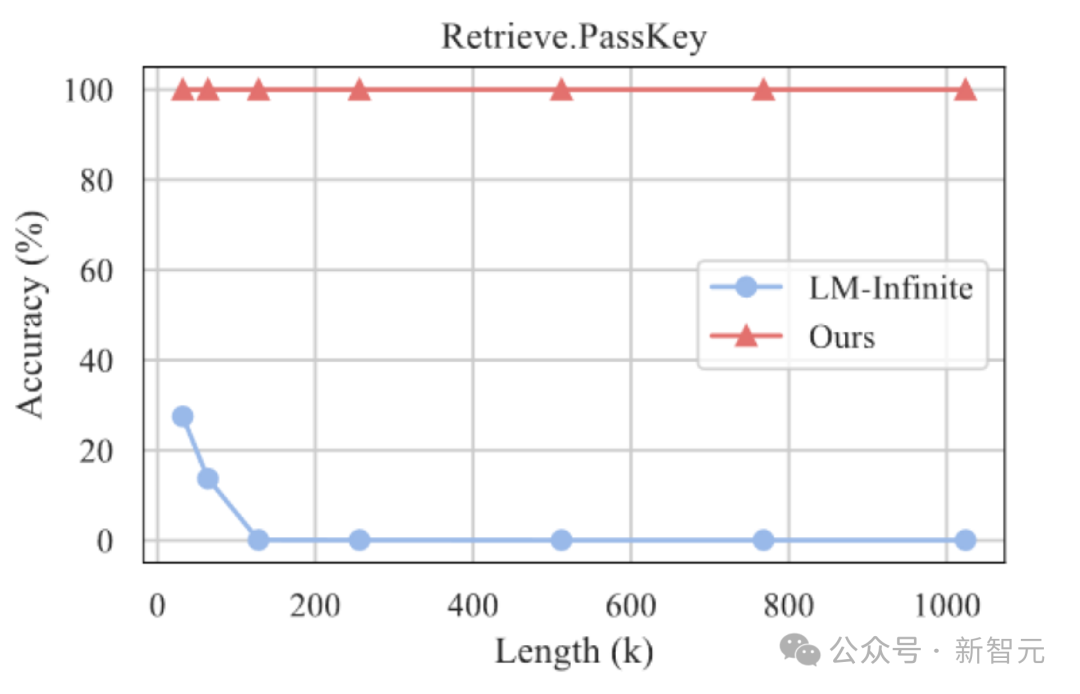
Résultats expérimentaux de la recherche d'une aiguille dans une botte de foin
Résumé
Dans cet article, l'équipe a proposé InfLLM, qui peut étendre le traitement de texte ultra-long de LLM sans formation et peut capturer la sémantique longue distance information .
InfLLM ajoute un module de mémoire contenant des informations contextuelles longue distance basées sur la fenêtre coulissante et utilise le mécanisme de cache et de déchargement pour implémenter un raisonnement de texte long en streaming avec une petite quantité de calcul et de consommation de mémoire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!