
Maison >Périphériques technologiques >IA >En utilisant de courtes vidéos IA pour « retourner » la compréhension de vidéos longues, le cadre MovieLLM de Tencent vise la génération d'images continues au niveau du film.
En utilisant de courtes vidéos IA pour « retourner » la compréhension de vidéos longues, le cadre MovieLLM de Tencent vise la génération d'images continues au niveau du film.

- PHPzavant
- 2024-03-11 13:10:10474parcourir
Dans le domaine de la compréhension vidéo, bien que les modèles multimodaux aient fait des percées dans l'analyse de vidéos courtes et démontré de fortes capacités de compréhension, ils semblent impuissants face à de longues vidéos de niveau film. Par conséquent, l’analyse et la compréhension de longues vidéos, en particulier la compréhension de contenus cinématographiques d’une heure, sont devenues aujourd’hui un énorme défi.
La difficulté du modèle à comprendre les vidéos longues provient principalement du manque de ressources de données vidéo longues, qui présentent des défauts de qualité et de diversité. De plus, la collecte et l’étiquetage de ces données nécessitent beaucoup de travail.
Face à un tel problème, l'équipe de recherche de Tencent et de l'Université de Fudan a proposé MovieLLM, un framework innovant de génération d'IA. MovieLLM adopte une méthode innovante qui génère non seulement des données vidéo diversifiées et de haute qualité, mais génère également automatiquement un grand nombre d'ensembles de données de questions et réponses associées, enrichissant considérablement la dimension et la profondeur des données, et l'ensemble du processus automatisé est également extrêmement Dadi réduit l'investissement humain.

- Adresse papier : https://arxiv.org/abs/2403.01422
- Adresse de la page d'accueil : https://deaddawn.github.io/MovieLLM/
Ce développement important améliore non seulement la compréhension du modèle des récits vidéo complexes, mais améliore également les capacités analytiques du modèle lors du traitement de contenus cinématographiques d'une durée de plusieurs heures. Dans le même temps, il surmonte les limites de rareté et de biais des ensembles de données existants et offre un moyen nouveau et efficace de comprendre le contenu vidéo ultra-long.
MovieLLM utilise intelligemment les puissantes capacités de génération de GPT-4 et des modèles de diffusion, et adopte une stratégie de génération de description de trame continue « en expansion d'histoire ». La méthode « d'inversion textuelle » est utilisée pour guider le modèle de diffusion afin de générer des images de scène cohérentes avec la description textuelle, créant ainsi des images continues d'un film complet.

Présentation de la méthode
MovieLLM combine GPT-4 et des modèles de diffusion pour améliorer la compréhension des grands modèles de vidéos longues. Cette combinaison intelligente produit des données vidéo longues et diversifiées de haute qualité ainsi que des questions et réponses d'assurance qualité, contribuant ainsi à améliorer les capacités génératives du modèle.
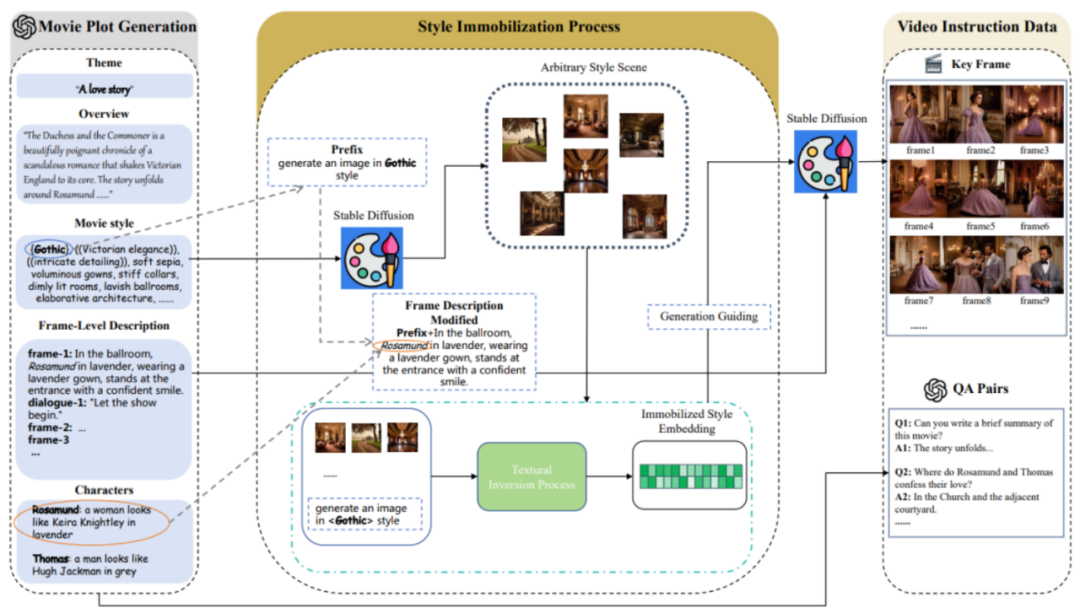
MovieLLM comprend principalement trois étapes :
1.
MovieLLM ne s'appuie pas sur le Web ou sur les ensembles de données existants pour générer des tracés, mais exploite pleinement la puissance de GPT-4 pour produire des données synthétiques. En fournissant des éléments spécifiques tels que le thème, la vue d'ensemble et le style, GPT-4 est guidé pour produire des descriptions d'images clés cinématographiques adaptées au processus de génération ultérieur.
2. Processus de fixation du style.
MovieLLM utilise intelligemment la technologie "d'inversion textuelle" pour fixer la description de style générée dans le script à l'espace latent du modèle de diffusion. Cette méthode guide le modèle pour générer des scènes avec un style fixe et maintenir la diversité tout en conservant une esthétique unifiée.
3. Génération de données de commande vidéo.
Sur la base des deux premières étapes, une intégration de style fixe et une description d'image clé ont été obtenues. Sur cette base, MovieLLM utilise l'intégration de styles pour guider le modèle de diffusion afin de générer des images clés conformes aux descriptions des images clés et génère progressivement diverses paires de questions et réponses pédagogiques en fonction de l'intrigue du film.

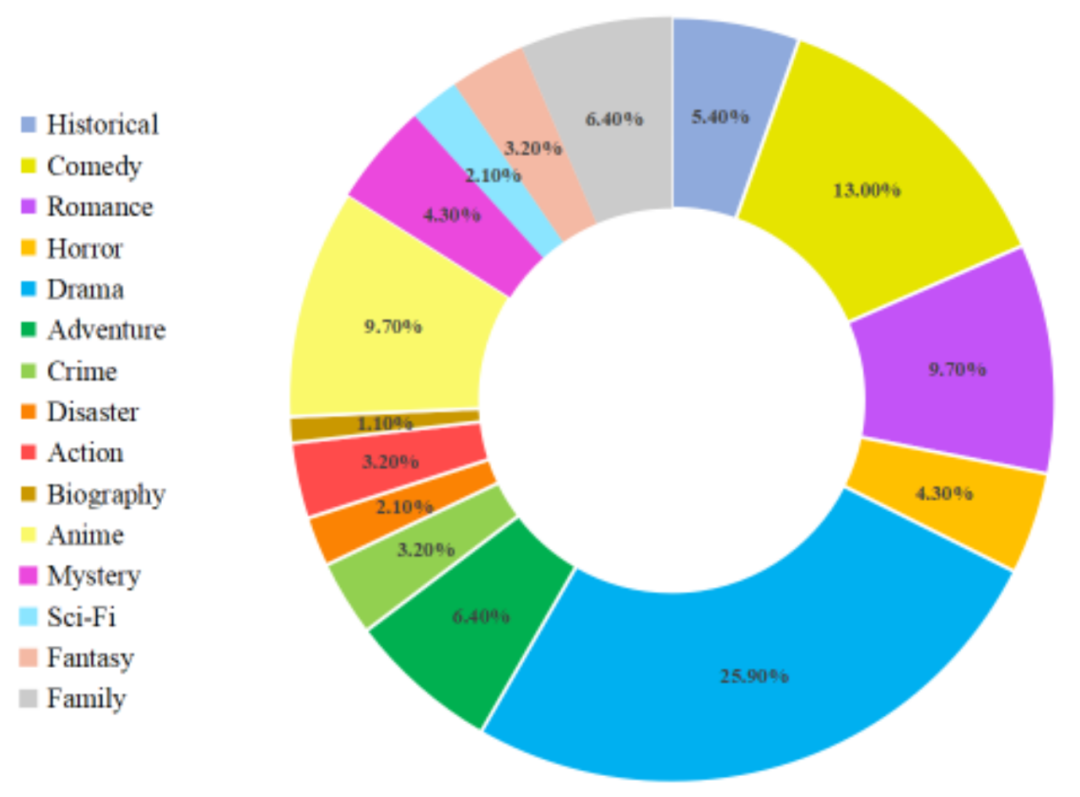
Après les étapes ci-dessus, MovieLLM a créé des styles variés et de haute qualité, des images de film cohérentes et des données de paires de questions et réponses correspondantes. La répartition détaillée des types de données de films est la suivante :
Résultats expérimentaux
En appliquant des données construites sur la base de MovieLLM pour un réglage fin sur LLaMA-VID, un grand modèle axé sur la compréhension de vidéos longues, cet article améliore considérablement la capacité du modèle à comprendre du contenu vidéo de différentes longueurs. Pour la compréhension des vidéos longues, il n'existe actuellement aucun travail proposant un benchmark de test, donc cet article propose également un benchmark pour tester les capacités de compréhension des vidéos longues.
Bien que MovieLLM n'ait pas construit spécifiquement de données vidéo courtes pour la formation, grâce à la formation, des améliorations de performances sur divers benchmarks vidéo courts ont quand même été observées :
Dans MSVD-QA et MSRVTT - Par rapport au. Dans le modèle de base, l'assurance qualité s'est considérablement améliorée sur ces deux ensembles de données de test.

Sur le benchmark de performances basé sur la génération vidéo, des améliorations de performances ont été obtenues dans les cinq domaines d'évaluation.
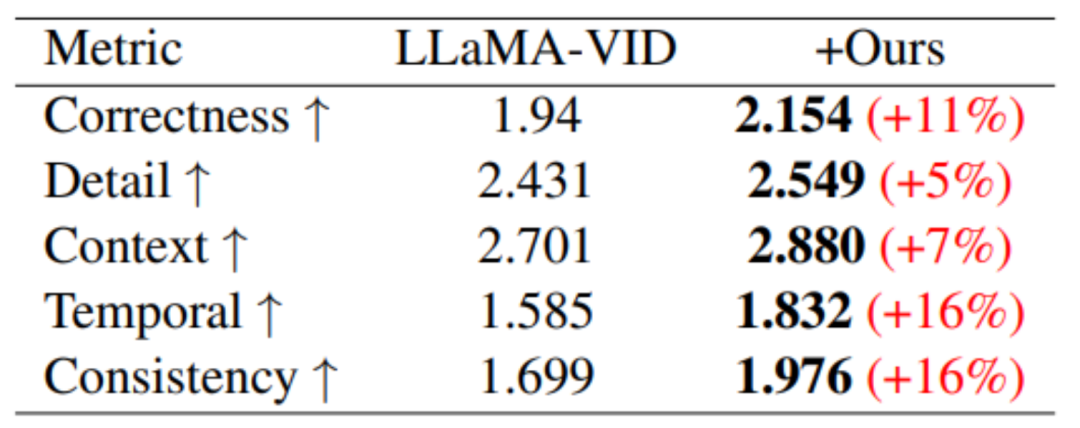
En termes de compréhension de vidéos longues, grâce à la formation de MovieLLM, la compréhension du modèle du résumé, de l'intrigue et du timing a été considérablement améliorée.

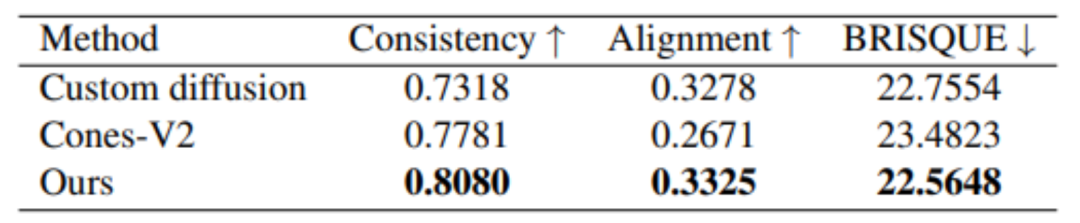
De plus, MovieLLM a également de meilleurs résultats en termes de qualité de génération par rapport à d'autres méthodes similaires de génération d'images de style fixe.
En bref, le workflow de génération de données proposé par MovieLLM réduit considérablement le défi de la production de données vidéo au niveau du film pour les modèles et améliore le contrôle et la diversité du contenu généré. Dans le même temps, MovieLLM améliore considérablement la capacité du modèle multimodal à comprendre les longues vidéos au niveau du film, fournissant ainsi une référence précieuse pour que d'autres domaines adoptent des méthodes de génération de données similaires.
Les lecteurs intéressés par cette recherche peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!