Ce modèle utilise le framework DiT comme Sora.
Comme nous le savons tous, développer des modèles T2I de haut niveau nécessite beaucoup de ressources, il est donc fondamentalement impossible pour les chercheurs individuels disposant de ressources limitées de se le permettre. C'est également devenu l'AIGC (Artificial Intelligence Content). Generation) communauté Un frein majeur à l’innovation. Dans le même temps, au fil du temps, la communauté AIGC sera en mesure d’obtenir des ensembles de données continuellement mis à jour et de meilleure qualité ainsi que des algorithmes plus avancés. Voici donc la question clé : comment pouvons-nous intégrer efficacement ces nouveaux éléments dans le modèle existant et rendre le modèle plus puissant avec des ressources limitées ? Afin d'explorer ce problème, une équipe de recherche d'institutions de recherche telles que le laboratoire Noah's Ark de Huawei a proposé une nouvelle méthode d'entraînement : l'entraînement faible à fort. 
Titre de l'article : PixArt-Σ : Formation faible à forte du transformateur de diffusion pour la génération de texte en image 4KAdresse de l'article : https://arxiv.org/pdf/2403.04692.pdfProjet Page : https://pixart-alpha.github.io/PixArt-sigma-project/ Leur recherche est basée sur PixArt-α, une méthode de formation lexicographique efficace qu'ils ont proposée en octobre dernier, merci de vous référer à ce site Reportage "PixArt, un modèle graphique basé sur du texte à coût de formation ultra faible, est là, avec des résultats comparables à MJ et ne nécessite que 10 % de temps de formation SD". PixArt-α est une première tentative du framework DiT (Diffusion Transformer). Aujourd'hui, avec Sora sur la recherche à chaud et la diffusion stable émergeant dans des applications infinies, l'efficacité de l'architecture DiT a été vérifiée par de plus en plus de travaux dans la communauté de recherche, tels que PixArt, Dit-3D, GenTron, etc. [1] . L'équipe a utilisé le modèle de base pré-entraîné de PixArt-α et intégré des éléments avancés pour promouvoir son amélioration continue, aboutissant finalement à un modèle PixArt-Σ plus puissant. La figure 1 montre quelques exemples de résultats générés.
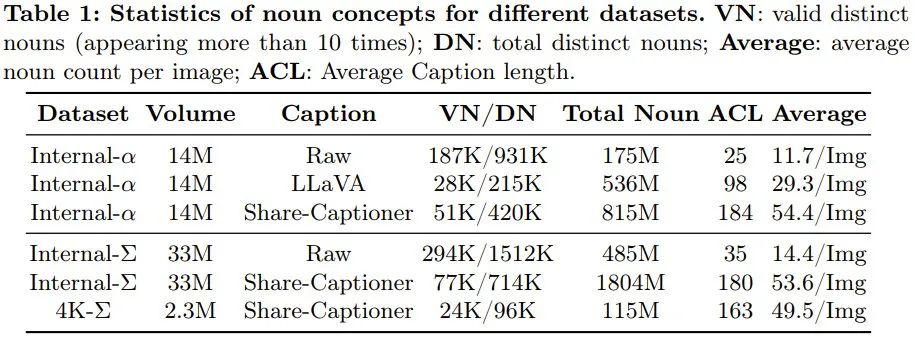
PixArt-Σ Comment le réaliser ? Plus précisément, afin de réaliser une formation de faible à fort et de créer PixArt-Σ, l'équipe a adopté les mesures d'amélioration suivantes. Données d'entraînement de meilleure qualitéL'équipe a collecté un ensemble de données de haute qualité Internal-Σ, qui se concentre principalement sur deux aspects : (1) Images de haute qualité : L'ensemble de données contient 33 millions d'images haute résolution provenant d'Internet, toutes d'une résolution supérieure à 1K, dont 2,3 millions d'images à une résolution d'environ 4K. Les principales caractéristiques de ces images sont leur grande esthétique et couvrent un large éventail de styles artistiques. (2) Description dense et précise : Afin de fournir une description plus précise et détaillée de l'image ci-dessus, l'équipe a remplacé le LLaVA utilisé dans PixArt-α par un descripteur d'image plus puissant, Share-Captioner . De plus, afin d'améliorer la capacité du modèle à aligner les concepts textuels et les concepts visuels, l'équipe a étendu la longueur du jeton de l'encodeur de texte (c'est-à-dire Flan-T5) à environ 300 mots. Ils ont observé que ces améliorations éliminent efficacement la tendance du modèle à halluciner, permettant ainsi un alignement texte-image de meilleure qualité. Le tableau 1 ci-dessous montre les statistiques de différents ensembles de données.
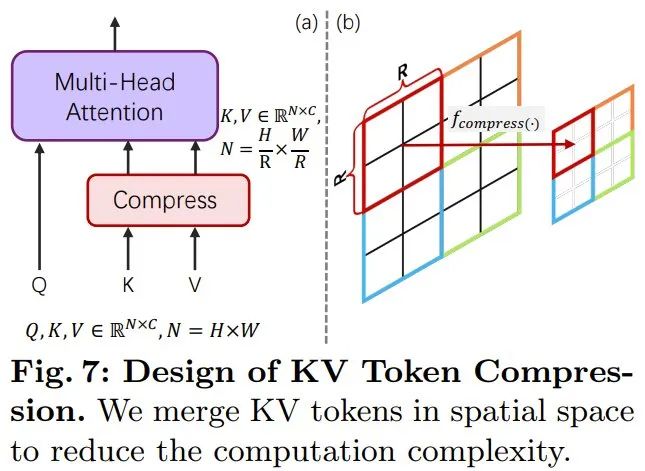
Compression efficace des jetonsPour améliorer PixArt-α, l'équipe a augmenté sa résolution de génération de 1K à 4K. Afin de générer des images à ultra haute résolution (telles que 2K/4K), le nombre de jetons augmentera considérablement, ce qui entraînera une augmentation significative des besoins informatiques. Pour résoudre ce problème, ils ont introduit un module d'auto-attention spécialement adapté au framework DiT, qui utilise la compression de clés et de jetons de valeur. Plus précisément, ils ont utilisé des convolutions groupées avec la foulée 2 pour effectuer une agrégation locale de clés et de valeurs, comme le montre la figure 7 ci-dessous.
De plus, l'équipe a adopté un schéma d'initialisation de poids spécialement conçu qui permet une adaptation en douceur à partir de modèles pré-entraînés sans utiliser de compression KV (valeur clé). Cette conception réduit efficacement le temps de formation et d'inférence pour la génération d'images haute résolution d'environ 34 %. Stratégie de formation faible à forteL'équipe a proposé une variété de techniques de réglage fin pour ajuster rapidement et efficacement les modèles faibles aux modèles forts. Ceux-ci incluent : (1) Remplacement à l’aide d’un auto-encodeur variationnel (VAE) plus puissant : remplacement du VAE de PixArt-α par le VAE de SDXL. (2) Pour passer de la basse résolution à la haute résolution, afin de résoudre le problème de dégradation des performances, ils utilisent la méthode d'interpolation Position Embedding (PE). (3) Évolue d'un modèle qui n'utilise pas la compression KV à un modèle qui utilise la compression KV. Les résultats expérimentaux ont vérifié la faisabilité et l'efficacité de la méthode d'entraînement faible à fort. Grâce aux améliorations ci-dessus, PixArt-Σ peut générer des images en résolution 4K de haute qualité avec le coût de formation le plus bas possible et le moins de paramètres de modèle possible. Plus précisément, en commençant avec un modèle déjà pré-entraîné et en l'affinant, l'équipe a pu produire un modèle capable de générer des images haute résolution 1K en utilisant seulement 9 % supplémentaires du temps GPU requis par PixArt-α. Cette performance est remarquable car elle utilise également de nouvelles données d’entraînement et une VAE plus performante. De plus, la quantité de paramètres de PixArt-Σ n'est que de 0,6B. En comparaison, la quantité de paramètres de SDXL et SD Cascade est respectivement de 2,6B et 5,1B. La beauté des images générées par PixArt-Σ est comparable aux meilleurs produits de pixel art actuels, tels que DALL・E 3 et MJV6. De plus, PixArt-Σ démontre également d'excellentes capacités d'alignement précis avec les invites de texte.
La figure 2 montre le résultat de PixArt-Σ générant une image 4K haute résolution. On peut voir que le résultat généré suit bien les instructions textuelles complexes et riches en informations.
Détails de la formation : Pour l'encodeur de texte qui effectue l'extraction conditionnelle de caractéristiques, l'équipe a utilisé l'encodage de T5 en suivant les pratiques d'Imagen et PixArt- appareil α (c'est-à-dire Flan-T5-XXL). Le modèle de diffusion de base est PixArt-α. Contrairement à la pratique consistant à extraire un nombre fixe de 77 jetons de texte dans la plupart des études, la longueur des jetons de texte est augmentée de 120 dans PixArt-α à 300 car les informations de description organisées en Interne-Σ sont plus denses et peuvent fournir des détails très fins. . De plus, VAE utilise une version gelée pré-entraînée de VAE de SDXL. Les autres détails d'implémentation sont les mêmes que ceux de PixArt-α. Le modèle est affiné à partir du point de contrôle de pré-entraînement de 256 pixels de PixArt-α et utilise la technologie d'interpolation d'intégration positionnelle. Le modèle final (y compris la résolution 1K) a été entraîné sur 32 GPU V100. Ils ont également utilisé 16 GPU A100 supplémentaires pour former des modèles de génération d'images 2K et 4K. Métriques d'évaluation : Pour mieux démontrer l'esthétique et les capacités sémantiques, l'équipe a collecté 30 000 paires texte-image de haute qualité pour comparer les modèles graphiques Vincent les plus puissants. PixArt-Σ est évalué ici principalement en fonction des préférences humaines et de l'IA, car la métrique FID peut ne pas refléter de manière appropriée la qualité de la génération. Comparaison des performancesÉvaluation de la qualité de l'image : L'équipe a comparé qualitativement la qualité de génération de PixArt-Σ avec des produits de conversion texte-image (T2I) à source fermée et des modèles open source. Comme le montre la figure 3, par rapport au modèle open source SDXL et au précédent PixArt-α de l'équipe, les portraits générés par PixArt-Σ sont plus réalistes et ont de meilleures capacités d'analyse sémantique. PixArt-Σ suit mieux les instructions de l'utilisateur que SDXL.
PixArt-Σ surpasse non seulement les modèles open source, mais est également compétitif par rapport aux produits fermés actuels, comme le montre la figure 4.
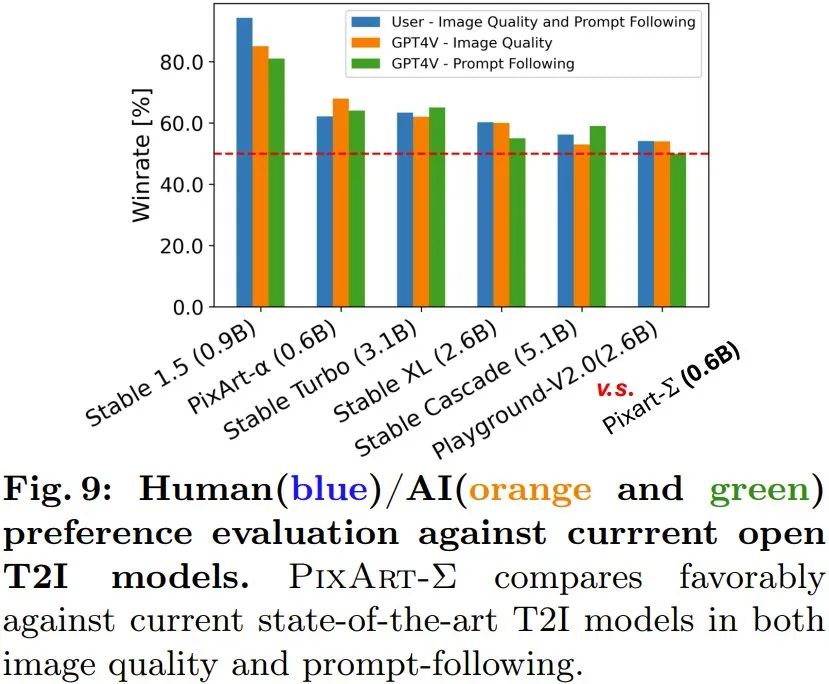
Générer des images haute résolution : la nouvelle méthode peut générer directement des images en résolution 4K sans aucun post-traitement. De plus, PixArt-Σ peut également se conformer avec précision aux textes longs complexes et détaillés fournis par les utilisateurs. Par conséquent, les utilisateurs n’ont pas besoin de se soucier de concevoir des invites pour obtenir des résultats satisfaisants. Étude des préférences humaines/IA (GPT-4V) : L'équipe a également étudié les préférences humaines et IA pour les résultats générés. Ils ont collecté les résultats de génération de 6 modèles open source, dont PixArt-α, PixArt-Σ, SD1.5, Stable Turbo, Stable XL, Stable Cascade et Playground-V2.0. Ils ont développé un site Web qui recueille les commentaires sur les préférences humaines en affichant des invites et des images correspondantes. Les évaluateurs humains peuvent classer les images en fonction de la qualité de la génération et de leur correspondance avec l'invite. Les résultats sont présentés dans le graphique à barres bleues de la figure 9. On constate que les évaluateurs humains préfèrent PixArt-Σ aux 6 autres générateurs. Par rapport aux modèles de diffusion de graphiques vincentiens précédents, tels que SDXL (paramètres 2,6B) et SD Cascade (paramètres 5,1B), PixArt-Σ peut générer une image de meilleure qualité et plus cohérente avec les invites de l'utilisateur avec beaucoup moins de paramètres (0,6B).
De plus, l'équipe a utilisé le modèle multimodal avancé GPT-4 Vision pour réaliser des études de préférences en matière d'IA. Ce qu'ils font, c'est alimenter GPT-4 Vision avec deux images et le laisser voter en fonction de la qualité de l'image et de l'alignement image-texte. Les résultats sont présentés dans les barres orange et vertes de la figure 9, et on peut voir que la situation est fondamentalement cohérente avec une évaluation humaine. L'équipe a également mené des études d'ablation pour vérifier l'efficacité de diverses mesures d'amélioration. Pour plus de détails, veuillez consulter le document original. Article de référence : 1. https://www.shoufachen.com/Awesome-Diffusion-Transformers/Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!