
Maison >Périphériques technologiques >IA >Rendez les grands modèles « minces » de 90 % ! L'Université Tsinghua et l'Institut de technologie de Harbin ont proposé une solution de compression extrême : une quantification sur 1 bit, tout en conservant 83 % de la capacité.
Rendez les grands modèles « minces » de 90 % ! L'Université Tsinghua et l'Institut de technologie de Harbin ont proposé une solution de compression extrême : une quantification sur 1 bit, tout en conservant 83 % de la capacité.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-11 12:04:151087parcourir
Les opérations de
Quantification, d'élagage et autres compressionsur de grands modèles sont la partie la plus courante du déploiement.
Cependant, quelle est la taille de cette limite ?
Une étude conjointe de l'Université Tsinghua et de l'Institut de technologie de Harbin a donné la réponse :
90 %.
Ils ont proposé un cadre de compression extrême 1 bit grand modèle OneBit, qui pour la première fois atteint une compression de poids grand modèle supérieure à 90 % et conserve la plupart des capacités (83 %) .
On peut dire que jouer, c'est "vouloir et vouloir"~

Jetons un coup d'oeil.
La méthode de quantification 1 bit pour les grands modèles est ici
De l'élagage et de la quantification à la distillation des connaissances et à la décomposition du poids de bas rang, les grands modèles peuvent déjà compresser un quart du poids sans presque aucune perte.
La quantification pondérale convertit généralement les paramètres d'un grand modèle en une représentation à faible largeur de bits. Ceci peut être réalisé en transformant un modèle entièrement formé (PTQ) ou en introduisant une étape de quantification pendant la formation (QAT). Cette approche permet de réduire les exigences de calcul et de stockage du modèle, améliorant ainsi l'efficacité et les performances du modèle. En quantifiant les poids, la taille du modèle peut être considérablement réduite, ce qui le rend plus adapté au déploiement dans des environnements aux ressources limitées, tout en
Cependant, les méthodes de quantification existantes sont confrontées à de graves pertes de performances en dessous de 3 bits, principalement dues à :
- La méthode de représentation de paramètres à faible largeur de bit existante présente une perte de précision importante à 1 bit. Lorsque les paramètres basés sur la méthode Round-To-Nearest sont exprimés sur 1 bit, le coefficient d'échelle converti s et le point zéro z perdront leur signification pratique.
- La structure du modèle 1 bit existante ne prend pas pleinement en compte l'importance de la précision en virgule flottante. L'absence de paramètres à virgule flottante peut affecter la stabilité du processus de calcul du modèle et réduire considérablement sa propre capacité d'apprentissage.
Afin de surmonter les obstacles de la quantification à largeur de bit ultra-faible de 1 bit, l'auteur propose un nouveau cadre de modèle 1 bit : OneBit, qui comprend une nouvelle structure de couche linéaire 1 bit, une méthode d'initialisation des paramètres basée sur SVID. et un apprentissage par transfert profond basé sur la distillation des connaissances prenant en compte la quantification.
Cette nouvelle méthode de quantification de modèle 1 bit peut conserver la plupart des capacités du modèle d'origine avec une vaste plage de compression, une occupation d'espace ultra faible et un coût de calcul limité. Ceci est d’une grande importance pour le déploiement de grands modèles sur PC et même sur smartphones.
Cadre global
Le cadre OneBit peut généralement inclure : une structure de modèle 1 bit nouvellement conçue, une méthode d'initialisation des paramètres de modèle quantifiés basée sur le modèle d'origine et une migration approfondie des capacités basée sur la distillation des connaissances.
Cette structure de modèle 1 bit nouvellement conçue peut surmonter efficacement le grave problème de perte de précision dans la quantification 1 bit lors des travaux de quantification précédents, et montre une excellente stabilité pendant l'entraînement et la migration.
La méthode d'initialisation du modèle quantitatif peut établir un meilleur point de départ pour la distillation des connaissances, accélérer la convergence et obtenir de meilleurs effets de transfert de capacités.
1. Structure du modèle 1 bit
1 bit nécessite que chaque valeur de poids ne puisse être représentée que par 1 bit, il n'y a donc que deux états possibles au maximum.
L'auteur choisit ±1 comme ces deux états. L'avantage est qu'il représente deux symboles dans le système numérique, a des fonctions plus complètes et peut être facilement obtenu grâce à la fonction Sign(·).
La structure du modèle 1 bit de l'auteur est obtenue en remplaçant toutes les couches linéaires du modèle FP16 (à l'exception de la couche d'intégration et de lm_head) par des couches linéaires 1 bit.
En plus du poids de 1 bit obtenu grâce à la fonction Sign(·), la couche linéaire de 1 bit comprend également ici deux autres composants clés : le vecteur de valeur avec une précision FP16.
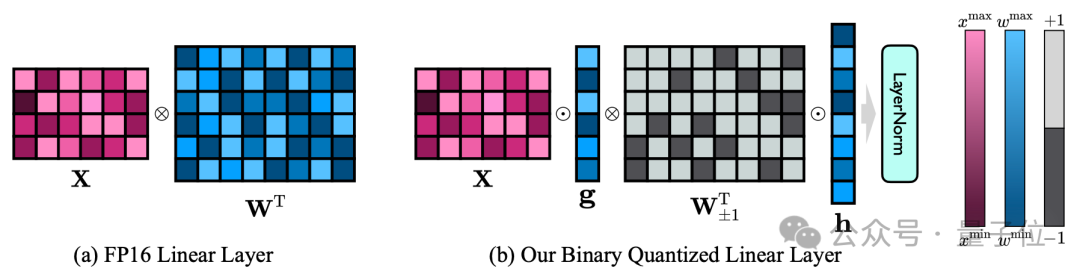
△Comparaison de la couche linéaire FP16 et de la couche linéaire OneBit
Cette conception maintient non seulement le rang élevé de la matrice de poids d'origine, mais fournit également la précision en virgule flottante nécessaire via le vecteur de valeur, ce qui est crucial pour assurer la stabilité et un apprentissage de haute qualité. Le processus est très significatif.
Comme le montre la figure ci-dessus, seuls les vecteurs de valeurs g et h restent au format FP16, tandis que la matrice de poids est entièrement composée de ±1.
L'auteur peut jeter un œil aux capacités de compression de OneBit à travers un exemple.
En supposant que soit compressé une couche linéaire 40964096 FP16, OneBit nécessite une matrice 40964096 1 bit et deux vecteurs de valeur 4096*1 FP16.
Le nombre total de bits est de 16 908 288, le nombre total de paramètres est de 16 785 408 et chaque paramètre n'occupe qu'environ 1,0073 bits en moyenne.
Une telle plage de compression est sans précédent et peut être considérée comme un véritable LLM 1 bit.
2. Initialisation des paramètres et apprentissage par transfert
Afin d'utiliser le modèle original entièrement entraîné pour mieux initialiser le modèle quantifié, l'auteur propose une nouvelle méthode de décomposition de matrice de paramètres appelée "décomposition de matrice indépendante de signe de valeur" (SVID) ".
Cette méthode de décomposition matricielle sépare les symboles et les valeurs absolues et effectue une approximation de rang 1 sur les valeurs absolues. Sa méthode d'approximation des paramètres matriciels d'origine peut être exprimée comme suit :
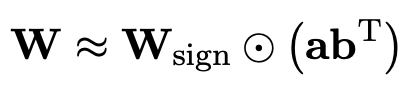
L'approximation de rang 1 peut être obtenue par des méthodes de factorisation matricielle courantes, telles que la décomposition en valeurs singulières (SVD) et la factorisation matricielle non négative (NMF).
L'auteur montre mathématiquement que cette méthode SVID peut correspondre au cadre du modèle 1 bit en échangeant l'ordre des opérations, réalisant ainsi l'initialisation des paramètres.
De plus, la contribution de la matrice symbolique à l'approximation de la matrice d'origine lors du processus de décomposition a également été prouvée. Voir l'article pour plus de détails.
L'auteur estime qu'un moyen efficace de résoudre la quantification à très faible largeur de bande des grands modèles pourrait être la formation QAT prenant en compte la quantification.
Par conséquent, après que SVID ait donné le paramètre point de départ du modèle quantitatif, l'auteur utilise le modèle original comme modèle d'enseignant et en tire des leçons grâce à la distillation des connaissances.
Plus précisément, le modèle étudiant reçoit principalement des conseils des logits et de l'état caché du modèle enseignant.
Pendant la formation, les valeurs du vecteur de valeur et de la matrice de paramètres seront mises à jour, et lors du déploiement, la matrice de paramètres quantifiée de 1 bit pourra être directement utilisée pour le calcul.
Plus le modèle est grand, meilleur est l'effet
Les lignes de base sélectionnées par l'auteur sont FP16 Transformer, GPTQ, LLM-QAT et OmniQuant.
Les trois derniers sont tous des lignes de base solides classiques dans le domaine de la quantification, en particulier OmniQuant, qui est la méthode de quantification 2 bits la plus puissante depuis l'auteur.
Comme il n'y a actuellement aucune recherche sur la quantification de poids 1 bit, l'auteur utilise uniquement la quantification de poids 1 bit pour le framework OneBit et adopte des paramètres de quantification 2 bits pour d'autres méthodes.
Pour les données distillées, l'auteur a suivi le LLM-QAT et a utilisé l'auto-échantillonnage du modèle d'enseignant pour générer des données.
L'auteur utilise des modèles de différentes tailles de 1,3B à 13B, OPT et LLaMA-1/2 dans différentes séries pour prouver l'efficacité de OneBit. En termes d'indicateurs d'évaluation, la perplexité de l'ensemble de vérification et la précision sans faille du raisonnement de bon sens sont utilisées. Voir le document pour plus de détails.
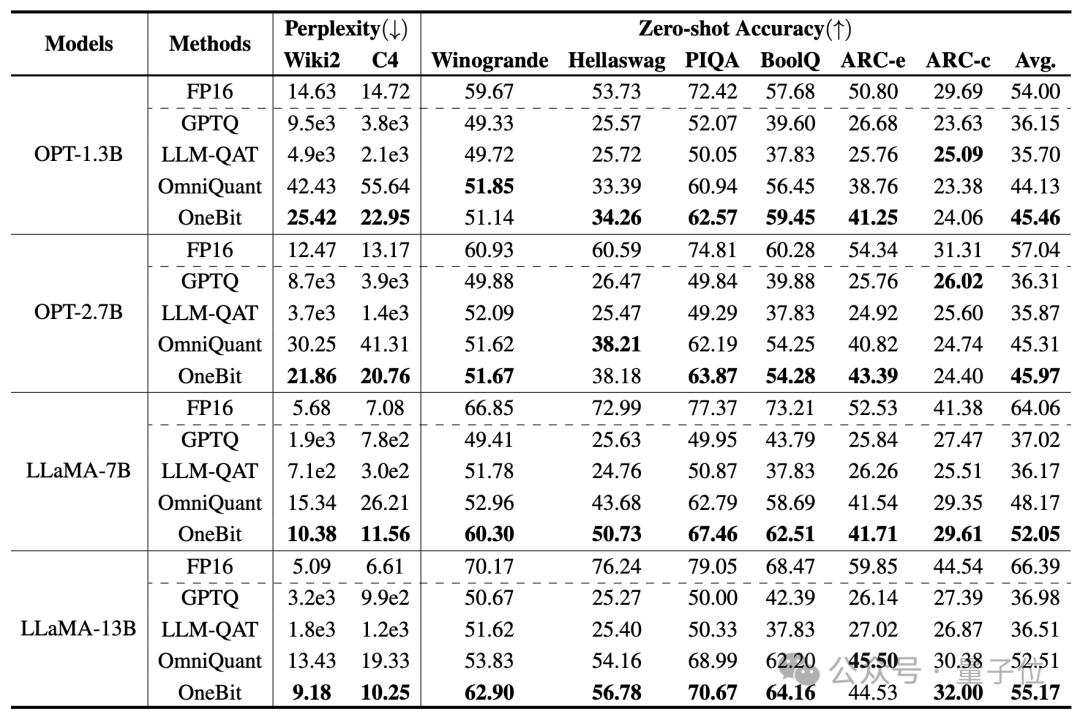
Le tableau ci-dessus montre les avantages de OneBit par rapport aux autres méthodes de quantification 1 bit. Il convient de noter que l'effet OneBit a tendance à être meilleur lorsque le modèle est plus grand.
À mesure que la taille du modèle augmente, le modèle quantifié OneBit réduit davantage la perplexité que le modèle FP16.
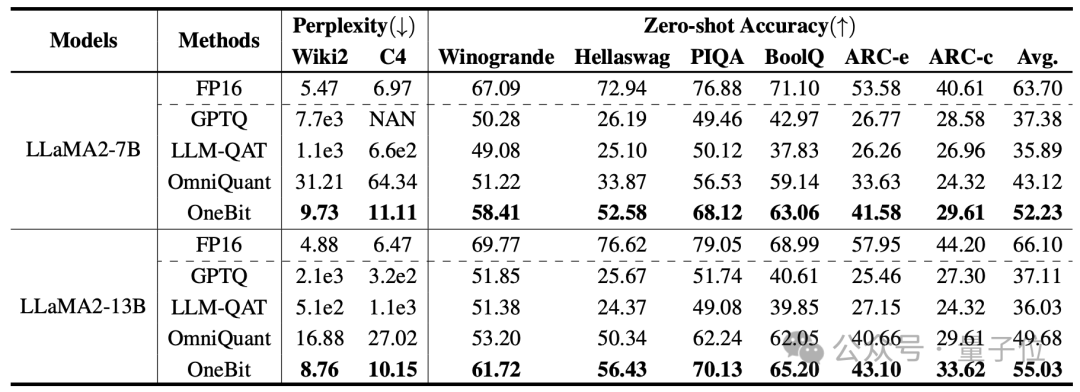
Ce qui suit est le raisonnement de bon sens, la connaissance du monde et l'occupation de l'espace de plusieurs petits modèles différents :
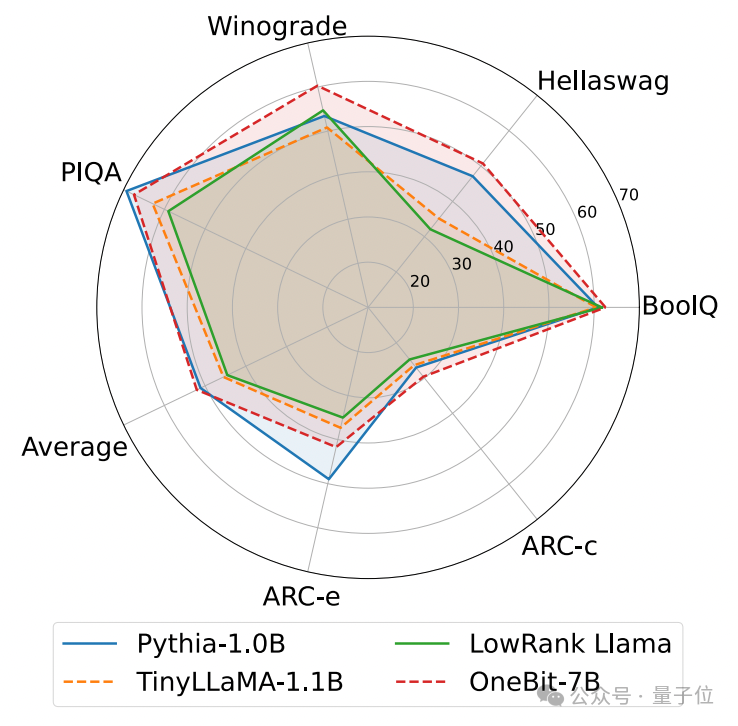
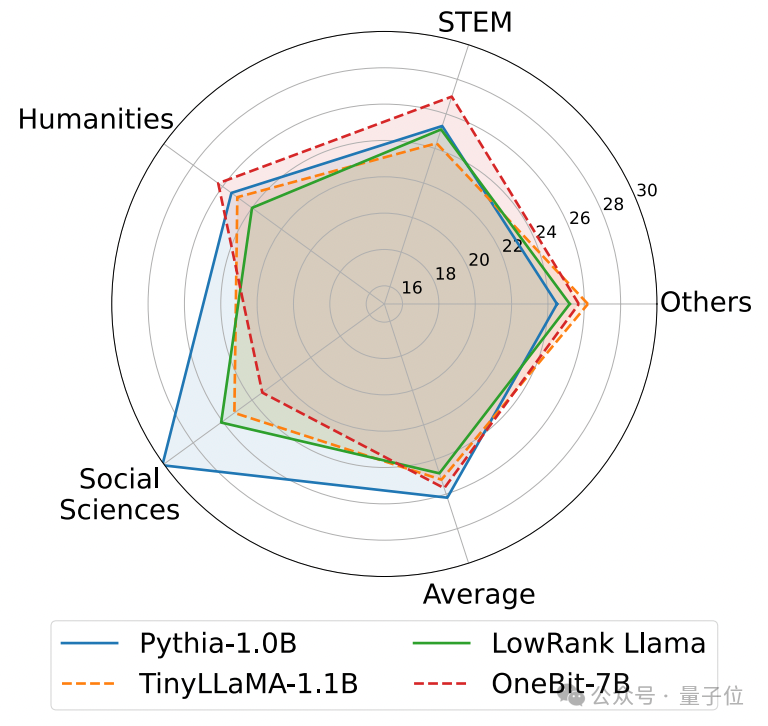
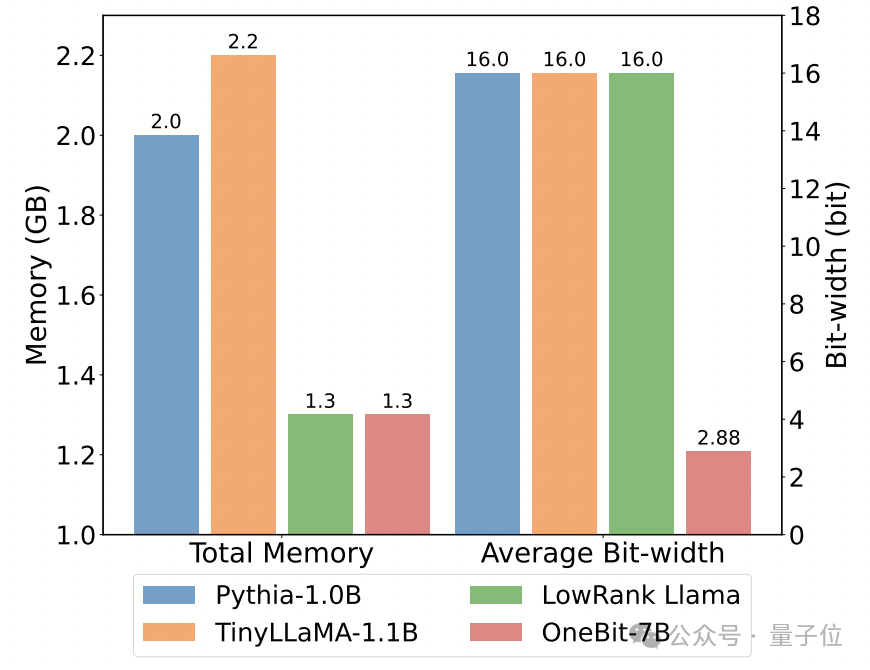
L'auteur a également comparé la taille et les capacités réelles de plusieurs types différents de petits modèles.
L'auteur a découvert que bien que OneBit-7B ait la plus petite largeur de bit moyenne, occupe le plus petit espace et nécessite relativement peu d'étapes de formation, il n'est pas inférieur aux autres modèles en termes de capacités de raisonnement de bon sens.
Dans le même temps, l'auteur a également constaté que le modèle OneBit-7B entraîne de sérieux oublis de connaissances dans le domaine des sciences sociales.

△Comparaison de la couche linéaire FP16 et de la couche linéaire OneBit Un exemple de génération de texte après réglage fin de l'instruction OneBit-7B
La figure ci-dessus montre également un exemple de génération de texte après réglage fin de l'instruction OneBit- Instruction 7B. On peut voir que OneBit-7B a effectivement acquis la capacité de l'étape SFT et peut générer du texte de manière relativement fluide, bien que les paramètres totaux ne soient que de 1,3 Go (comparable au modèle 0,6B du FP16). Dans l'ensemble, OneBit-7B démontre sa valeur d'application pratique.
Analyse et discussion
L'auteur montre le taux de compression de OneBit pour les modèles LLaMA de différentes tailles. On peut voir que le taux de compression de OneBit pour le modèle dépasse un étonnant 90 %.
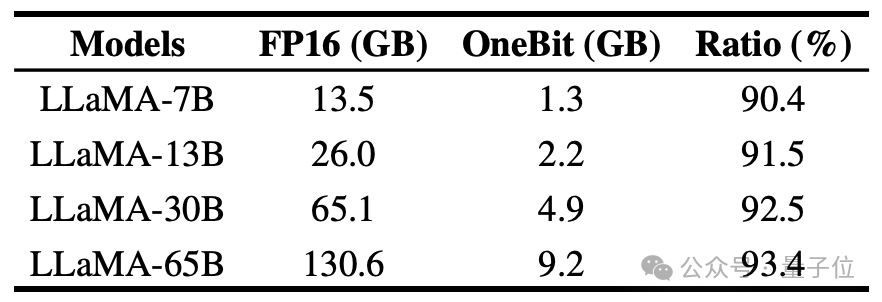
En particulier, à mesure que le modèle augmente, le taux de compression de OneBit devient plus élevé.
Cela montre l'avantage de la méthode de l'auteur sur des modèles plus grands : un gain marginal (perplexité) plus important à des taux de compression plus élevés. De plus, l’approche des auteurs permet d’obtenir un bon compromis entre taille et performances. 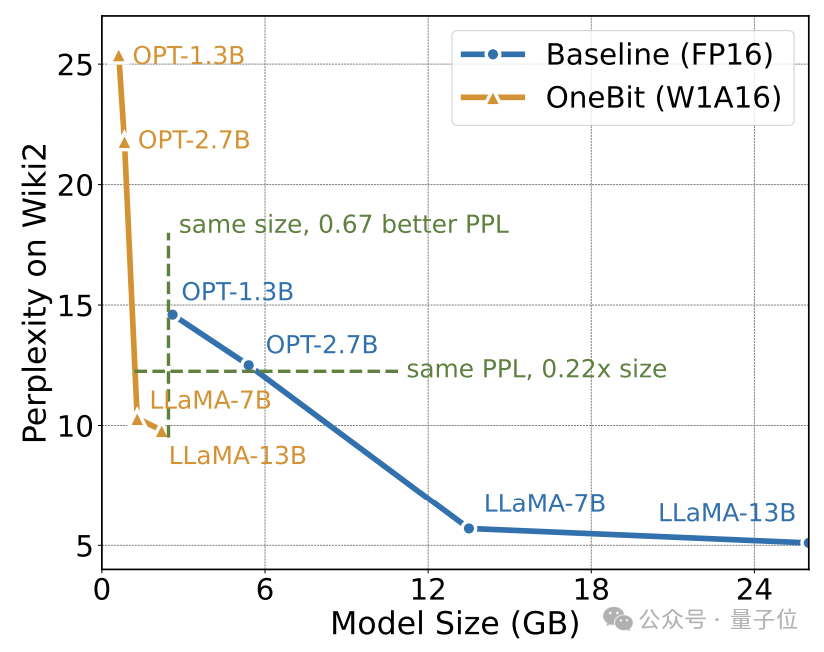
Le modèle quantitatif 1 bit présente des avantages informatiques et est d'une grande importance. La représentation binaire pure des paramètres peut non seulement économiser beaucoup d'espace, mais également réduire les exigences matérielles de la multiplication matricielle.
La multiplication d'éléments de la multiplication matricielle dans les modèles de haute précision peut être transformée en opérations de bits efficaces qui peuvent être complétées avec uniquement l'affectation et l'ajout de bits, ce qui offre de grandes perspectives d'application.
De plus, la méthode de l'auteur maintient d'excellentes capacités d'apprentissage stables pendant le processus de formation.
En fait, le problème d'instabilité, la sensibilité aux hyperparamètres et les difficultés de convergence de la formation des réseaux binaires ont toujours été préoccupés par les chercheurs.
L'auteur analyse l'importance des vecteurs de valeurs de haute précision dans la promotion d'une convergence stable du modèle.
Des travaux antérieurs ont proposé une architecture de modèle 1 bit et l'ont utilisée pour entraîner des modèles à partir de zéro (comme BitNet [1]), mais elle est sensible aux hyperparamètres et difficile de transférer l'apprentissage à partir de modèles de haute précision entièrement entraînés. L'auteur a également testé les performances de BitNet en matière de distillation des connaissances et a constaté que sa formation n'était pas suffisamment stable.
Résumé
L'auteur a proposé une structure de modèle pour la quantification de poids sur 1 bit et une méthode d'initialisation des paramètres correspondante.
Des expériences approfondies sur des modèles de différentes tailles et séries montrent que OneBit présente des avantages évidents sur des bases représentatives solides et atteint un bon compromis entre la taille du modèle et les performances.
En outre, l'auteur analyse plus en détail les capacités et les perspectives de ce modèle de quantification à bits extrêmement faibles et fournit des conseils pour les recherches futures.
Adresse papier : https://arxiv.org/pdf/2402.11295.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!