

 Périphériques technologiquesIA1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Périphériques technologiquesIA1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT


Adresse papier : https://arxiv.org/abs/2307.09283
Adresse code : https://github.com/THU-MIG/RepViT

RepViT sur le mobile côté Excellentes performances dans l'architecture ViT, montrant des avantages significatifs. Ensuite, nous explorons les contributions de cette étude.
- Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leurs modules d'auto-attention multi-têtes (
MSHA) permet au modèle d'apprendreGlobal. représentation. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. - 在这项研究中,作者们通过整合轻量级 ViTs 的有效架构选择,逐步提升了标准轻量级 CNN(特别是
MobileNetV3的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。 - 实验结果表明,
RepViT超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT在iPhone 12上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。
MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。好了,接下来大家应该关心的应该时“如何设计到如此低延迟但精度还很6的模型”出来呢?
方法
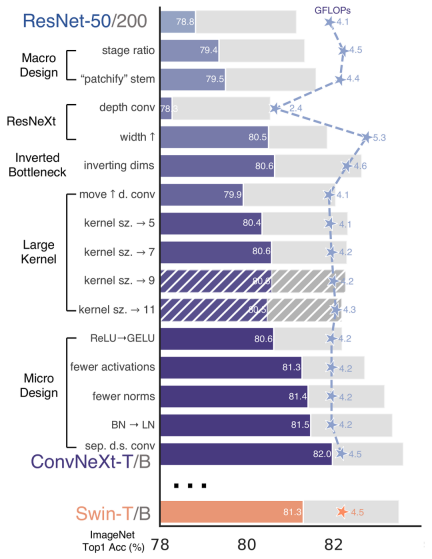
再 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级 ViTs 的架构设计逐步整合到标准轻量级 CNN,即MobileNetV3-LDans cette étude, les auteurs ont progressivement amélioré le CNN léger standard (en particulier MobileNetV3. Cela en découle La naissance d'une nouvelle famille CNN pure et légère, à savoir RepViT. Il est à noter que bien que RepViT ait une structure MetaFormer, elle est entièrement composée de convolutions.
RepViT Surpasse les ViT légers de pointe existants et affiche des performances supérieures et efficacité par rapport aux ViT légers de pointe existants sur diverses tâches de vision, notamment la classification ImageNet, la détection d'objets COCO-2017 et la segmentation d'instances, ainsi que la segmentation sémantique sur ADE20k, en particulier dans ImageNet, RepViT code> dans <code style="background-color: rgb(231, 243, 237); padding: 1px 3px; border-radius: 4px; overflow-wrap: break-word; text-indent: 0px; display: inline- block;">iPhone 12 a atteint une latence de près de 1 ms et une précision Top-1 de plus de 80 %, ce qui constitue la première avancée pour les modèles légers. 🎜D'accord, ce qui devrait préoccuper tout le monde ensuite, c'est "Comment concevoir un modèle avec une latence aussi faible mais une précision élevée" ? 🎜Méthode
🎜🎜🎜à nouveau ConvNeXt, les auteurs sont basés sur ResNet50 grâce à une théorie et une expérience rigoureuses. nous en avons finalement conçu un très excellent, comparable à L'architecture de réseau neuronal convolutif pur de Swin-Transformer. De même, RepViT consiste également principalement à intégrer progressivement la conception architecturale des ViT légers dans un CNN léger standard, c'est-à-dire MobileNetV3-L pour effectuer une transformation ciblée (modification magique) ). Au cours de ce processus, les auteurs ont examiné les éléments de conception à différents niveaux de granularité et ont atteint leurs objectifs d'optimisation grâce à une série d'étapes. 🎜
Alignement des recettes de formation
Dans le document, une nouvelle métrique est introduite pour mesurer la latence sur les appareils mobiles et garantit que la stratégie de formation est cohérente avec les ViT légers actuellement populaires. Le but de cette initiative est d'assurer la cohérence de la formation sur modèle, ce qui implique deux concepts clés que sont la mesure des délais et l'ajustement de la stratégie de formation.
Metrique de latence
Afin de mesurer plus précisément les performances du modèle sur de vrais appareils mobiles, l'auteur a choisi de mesurer directement la latence réelle du modèle sur l'appareil comme mesure de base. Cette méthode de mesure est différente des études précédentes, qui ont principalement réussi FLOPs ou la taille du modèle optimisent la vitesse d'inférence du modèle, et ces métriques ne reflètent pas toujours bien la latence réelle dans les applications mobiles. FLOPs或模型大小等指标优化模型的推理速度,这些指标并不总能很好地反映在移动应用中的实际延迟。
训练策略的对齐
这里,将 MobileNetV3-L 的训练策略调整以与其他轻量级 ViTs 模型对齐。这包括使用 AdamW 优化器【ViTs 模型必备的优化器】,进行 5 个 epoch 的预热训练,以及使用余弦退火学习率调度进行 300 个 epoch 的训练。尽管这种调整导致了模型准确率的略微下降,但可以保证公平性。
块设计的优化
接下来,基于一致的训练设置,作者们探索了最优的块设计。块设计是 CNN 架构中的一个重要组成部分,优化块设计有助于提高网络的性能。
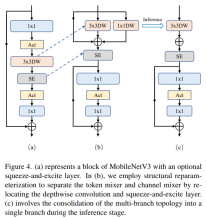
分离 Token 混合器和通道混合器
这块主要是对 MobileNetV3-LAlignement de la stratégie de formation
Ici, la stratégie de formation de MobileNetV3-L est ajustée pour s'aligner sur d'autres modèles ViT légers. Cela inclut l'utilisation de AdamW [optimiseur essentiel pour le modèle ViTs], effectue 5 époques d'entraînement d'échauffement et utilise la planification du taux d'apprentissage par recuit cosinus pour 300 époques d'entraînement. Bien que cet ajustement entraîne une légère diminution de la précision du modèle, l’équité est garantie.
Mélangeur de jetons séparé et mélangeur de canaux
Cette pièce est principalement destinée àMobileNetV3-L a été améliorée pour séparer le mélangeur de jetons et le mélangeur de canaux. La structure de bloc MobileNetV3 originale se compose d'une convolution dilatée 1x1, suivie d'une convolution en profondeur et d'une couche de projection 1x1, puis connecte l'entrée et la sortie via des connexions résiduelles. Sur cette base, RepViT fait progresser la convolution en profondeur afin que le mélangeur de canaux et le mélangeur de jetons puissent être séparés. Pour améliorer les performances, un reparamétrage structurel est également introduit pour introduire une topologie multi-branches pour les filtres profonds pendant la formation. Enfin, les auteurs ont réussi à séparer le mélangeur de jetons et le mélangeur de canaux dans le bloc MobileNetV3 et ont nommé ce bloc le bloc RepViT.
est également introduit pour introduire une topologie multi-branches pour les filtres profonds pendant la formation. Enfin, les auteurs ont réussi à séparer le mélangeur de jetons et le mélangeur de canaux dans le bloc MobileNetV3 et ont nommé ce bloc le bloc RepViT.
Les ViT utilisent généralement une opération "patchify" qui divise l'image d'entrée en patchs qui ne se chevauchent pas comme tige. Cependant, cette approche pose des problèmes d’optimisation de la formation et de sensibilité aux recettes de formation. Par conséquent, les auteurs ont plutôt adopté une convolution précoce, une approche qui a été adoptée par de nombreux ViT légers. En revanche, MobileNetV3-L utilise une tige plus complexe pour un sous-échantillonnage 4x. De cette façon, bien que le nombre initial de filtres soit porté à 24, la latence totale est réduite à 0,86 ms, tandis que la précision du top 1 augmente à 73,9 %.
Couche de sous-échantillonnage plus profonde
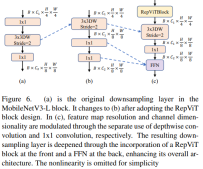
Dans les ViT, le sous-échantillonnage spatial est généralement implémenté via une couche de fusion de correctifs distincte. Nous pouvons donc ici adopter une couche de sous-échantillonnage distincte et plus profonde pour augmenter la profondeur du réseau et réduire la perte d'informations due à la réduction de la résolution. Plus précisément, les auteurs ont d'abord utilisé une convolution 1x1 pour ajuster la dimension du canal, puis ont connecté l'entrée et la sortie de deux convolutions 1x1 via le résidu pour former un réseau à action directe. De plus, ils ont ajouté un bloc RepViT devant pour approfondir davantage la couche de sous-échantillonnage, une étape qui a amélioré la précision du top 1 à 75,4 % avec une latence de 0,96 ms.
Classificateur plus simple
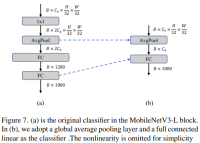
Dans les ViT légers, le classificateur se compose généralement d'une couche de regroupement moyenne globale suivie d'une couche linéaire. En revanche, MobileNetV3-L utilise un classificateur plus complexe. Étant donné que l'étape finale comporte désormais plus de canaux, les auteurs l'ont remplacée par un simple classificateur, une couche de pooling moyenne globale et une couche linéaire. Cette étape a réduit la latence à 0,77 ms tout en étant précise. Le taux est de 74,8 %.
Le rapport global des étapes
Le rapport des étapes représente le rapport du nombre de blocs dans les différentes étapes, indiquant ainsi la répartition des calculs dans chaque étape. Le document choisit un rapport d'étape plus optimal de 1:1:7:1, puis augmente la profondeur du réseau à 2:2:14:2, obtenant ainsi une mise en page plus profonde. Cette étape augmente la précision du top 1 à 76,9 % avec une latence de 1,02 ms.
Ajustement de la micro-conception
Ensuite, RepViT ajuste le CNN léger grâce à une micro-conception couche par couche, qui comprend la sélection de la taille de noyau de convolution appropriée et l'optimisation de la position de la couche de compression et d'excitation (SE). Les deux méthodes améliorent considérablement les performances du modèle.
Sélection de la taille du noyau de convolution
On sait que les performances et la latence des CNN sont généralement affectées par la taille du noyau de convolution. Par exemple, pour modéliser les dépendances de contexte à longue portée comme MHSA, ConvNeXt utilise de grands noyaux convolutifs, ce qui entraîne des améliorations significatives des performances. Cependant, les grands noyaux de convolution ne sont pas adaptés aux appareils mobiles en raison de leur complexité de calcul et de leur coût d'accès à la mémoire. MobileNetV3-L utilise principalement des convolutions 3x3, et des convolutions 5x5 sont utilisées dans certains blocs. Les auteurs les ont remplacés par des convolutions 3x3, ce qui a permis de réduire la latence à 1,00 ms tout en conservant une précision top-1 de 76,9 %.
Position de la couche SE
L'un des avantages du module d'auto-attention par rapport à la convolution est la possibilité d'ajuster les poids en fonction de l'entrée, ce que l'on appelle une propriété basée sur les données. En tant que module d'attention de canal, la couche SE peut compenser les limitations de convolution liées au manque de propriétés basées sur les données, conduisant ainsi à de meilleures performances. MobileNetV3-L ajoute des couches SE dans certains blocs, en se concentrant principalement sur les deux dernières étapes. Cependant, l'étage à basse résolution obtient des gains de précision moindres grâce à l'opération de mise en commun moyenne globale fournie par SE que l'étage à haute résolution. Les auteurs ont conçu une stratégie pour utiliser la couche SE de manière croisée à toutes les étapes afin de maximiser l'amélioration de la précision avec le plus petit incrément de retard. Cette étape a amélioré la précision du top 1 à 77,4 % tout en réduisant le retard à 0,87 ms. [En fait, Baidu a déjà fait des expériences et des comparaisons sur ce point et est arrivé à cette conclusion il y a longtemps. La couche SE est plus efficace lorsqu'elle est placée à proximité de la couche profonde]
.Architecture de réseau
Enfin, en intégrant les stratégies d'amélioration ci-dessus, nous obtenons le modèleRepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3. De même, les différentes variantes se distinguent principalement par le nombre de canaux et de blocs par étage.
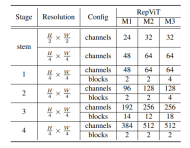
Expériences
Classification d'images

Détection et segmentation

Résumé
Cet article revisite la conception efficace des CNN légers en introduisant le choix architectural du ViT léger. Cela a conduit à l'émergence de RepViT, une nouvelle famille de CNN légers conçus pour les appareils mobiles aux ressources limitées. RepViT surpasse les ViT et CNN légers de pointe existants sur diverses tâches de vision, affichant des performances et une latence supérieures. Cela met en évidence le potentiel des CNN purement légers pour les appareils mobiles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Gemma Scope: le microscope de Google pour regarder dans le processus de pensée de l'IAApr 17, 2025 am 11:55 AM
Gemma Scope: le microscope de Google pour regarder dans le processus de pensée de l'IAApr 17, 2025 am 11:55 AMExplorer le fonctionnement interne des modèles de langue avec Gemma Scope Comprendre les complexités des modèles de langue IA est un défi important. La sortie de Google de Gemma Scope, une boîte à outils complète, offre aux chercheurs un moyen puissant de plonger
 Qui est un analyste de Business Intelligence et comment en devenir un?Apr 17, 2025 am 11:44 AM
Qui est un analyste de Business Intelligence et comment en devenir un?Apr 17, 2025 am 11:44 AMDéverrouiller le succès de l'entreprise: un guide pour devenir un analyste de Business Intelligence Imaginez transformer les données brutes en informations exploitables qui stimulent la croissance organisationnelle. C'est le pouvoir d'un analyste de Business Intelligence (BI) - un rôle crucial dans GU
 Comment ajouter une colonne dans SQL? - Analytique VidhyaApr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique VidhyaApr 17, 2025 am 11:43 AMInstruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Analyste d'entreprise vs analyste de donnéesApr 17, 2025 am 11:38 AM
Analyste d'entreprise vs analyste de donnéesApr 17, 2025 am 11:38 AMIntroduction Imaginez un bureau animé où deux professionnels collaborent sur un projet critique. L'analyste commercial se concentre sur les objectifs de l'entreprise, l'identification des domaines d'amélioration et la garantie d'alignement stratégique sur les tendances du marché. Simulé
 Que sont le comte et le coude à Excel? - Analytique VidhyaApr 17, 2025 am 11:34 AM
Que sont le comte et le coude à Excel? - Analytique VidhyaApr 17, 2025 am 11:34 AMExcel Counting and Analysis: Explication détaillée du nombre et des fonctions de compte Le comptage et l'analyse des données précises sont essentiels dans Excel, en particulier lorsque vous travaillez avec de grands ensembles de données. Excel fournit une variété de fonctions pour y parvenir, les fonctions Count et Count sont des outils clés pour compter le nombre de cellules dans différentes conditions. Bien que les deux fonctions soient utilisées pour compter les cellules, leurs cibles de conception sont ciblées sur différents types de données. Faisons des détails spécifiques du comptage et des fonctions de coude, mettons en évidence leurs caractéristiques et différences uniques et apprenez à les appliquer dans l'analyse des données. Aperçu des points clés Comprendre le nombre et le cou
 Chrome est là avec l'IA: vivre quelque chose de nouveau tous les jours !!Apr 17, 2025 am 11:29 AM
Chrome est là avec l'IA: vivre quelque chose de nouveau tous les jours !!Apr 17, 2025 am 11:29 AMLa révolution de l'IA de Google Chrome: une expérience de navigation personnalisée et efficace L'intelligence artificielle (IA) transforme rapidement notre vie quotidienne, et Google Chrome mène la charge dans l'arène de navigation Web. Cet article explore les exciti
 Côté humain de l'AI: le bien-être et le quadruple de basApr 17, 2025 am 11:28 AM
Côté humain de l'AI: le bien-être et le quadruple de basApr 17, 2025 am 11:28 AMRéinventuation d'impact: le quadruple bas Pendant trop longtemps, la conversation a été dominée par une vision étroite de l’impact de l’IA, principalement axée sur le résultat du profit. Cependant, une approche plus holistique reconnaît l'interconnexion de BU
 5 cas d'utilisation de l'informatique quantique qui change la donne que vous devriez connaîtreApr 17, 2025 am 11:24 AM
5 cas d'utilisation de l'informatique quantique qui change la donne que vous devriez connaîtreApr 17, 2025 am 11:24 AMLes choses évoluent régulièrement vers ce point. L'investissement affluant dans les prestataires de services quantiques et les startups montre que l'industrie comprend son importance. Et un nombre croissant de cas d'utilisation réels émergent pour démontrer sa valeur


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Version crackée d'EditPlus en chinois
Petite taille, coloration syntaxique, ne prend pas en charge la fonction d'invite de code

Version Mac de WebStorm
Outils de développement JavaScript utiles

Navigateur d'examen sécurisé
Safe Exam Browser est un environnement de navigation sécurisé permettant de passer des examens en ligne en toute sécurité. Ce logiciel transforme n'importe quel ordinateur en poste de travail sécurisé. Il contrôle l'accès à n'importe quel utilitaire et empêche les étudiants d'utiliser des ressources non autorisées.

SublimeText3 version anglaise
Recommandé : version Win, prend en charge les invites de code !

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

