
Maison >Périphériques technologiques >IA >CLRNet : un algorithme de réseau raffiné hiérarchiquement pour la détection autonome des voies de circulation
CLRNet : un algorithme de réseau raffiné hiérarchiquement pour la détection autonome des voies de circulation

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-08 12:00:05620parcourir
Dans les systèmes de navigation visuelle, la détection de voie est une fonction cruciale. Il a non seulement un impact significatif sur des applications telles que la conduite autonome et les systèmes avancés d’aide à la conduite (ADAS), mais joue également un rôle clé dans l’auto-positionnement et la conduite sûre des véhicules intelligents. Par conséquent, le développement de la technologie de détection de voie revêt une grande importance pour améliorer l’intelligence et la sécurité du système de circulation.
Cependant, la détection de voie présente des modèles locaux uniques, nécessite une prédiction précise des informations sur les voies dans les images réseau et s'appuie sur des fonctionnalités détaillées de bas niveau pour obtenir une localisation précise. Par conséquent, la détection de voie peut être considérée comme une tâche importante et difficile en vision par ordinateur.
L'utilisation de différents niveaux de fonctionnalités est très importante pour une détection précise des voies, mais le travail de remise en est encore au stade exploratoire. Cet article présente le réseau de raffinement multicouche (CLRNet), qui vise à exploiter pleinement les fonctionnalités de haut niveau et de bas niveau dans la détection de voie. Tout d’abord, en détectant les voies présentant des caractéristiques sémantiques de haut niveau, puis en les affinant en fonction des caractéristiques de bas niveau. Cette approche peut utiliser davantage d'informations contextuelles pour détecter les voies tout en utilisant des caractéristiques locales détaillées des voies pour améliorer la précision du positionnement. De plus, la représentation des caractéristiques des voies peut être encore améliorée en collectant le contexte global via ROIGather. En plus de concevoir un tout nouveau réseau, une perte IoU de ligne est également introduite, qui régresse les lignes de voie dans leur ensemble pour améliorer la précision du positionnement.
Comme mentionné précédemment, étant donné que Lane a une sémantique de haut niveau, mais qu'il possède des modèles locaux spécifiques, des fonctionnalités détaillées de bas niveau sont nécessaires pour le localiser avec précision. Comment utiliser efficacement les différents niveaux de fonctionnalités dans les CNN reste un problème. Comme le montre la figure 1(a) ci-dessous, les points de repère et les lignes de voie ont une sémantique différente, mais ils partagent des caractéristiques similaires (par exemple, de longues lignes blanches). Sans sémantique de haut niveau et contexte global, il est difficile de les distinguer. D'un autre côté, la régionalité est également importante, les ruelles sont longues et fines et le schéma local est simple.
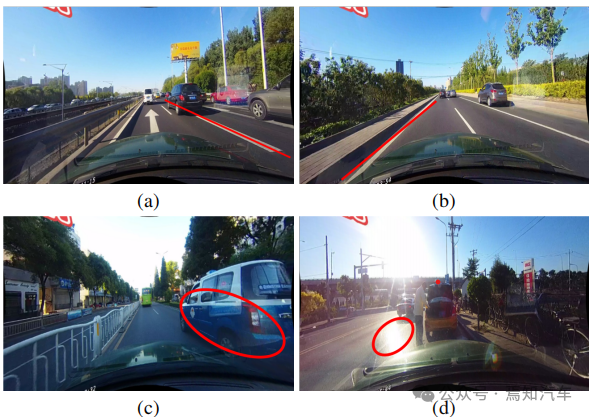
montre les résultats de détection des fonctionnalités de haut niveau dans la figure 1 (b). Bien que la voie soit détectée avec succès, sa précision doit être améliorée. Par conséquent, la combinaison d’informations de bas niveau et de haut niveau peut se compléter, ce qui permet une détection de voie plus précise.
Un autre problème courant dans la détection de voie est le manque d'informations visuelles sur la présence de voie. Dans certains cas, les voies peuvent être occupées par d’autres véhicules, ce qui rend la détection des voies difficile. De plus, la reconnaissance des voies peut devenir difficile dans des conditions d’éclairage extrêmes.
Travail associé
Les travaux précédents modélisent la géométrie locale de la voie et l'intègrent dans les résultats globaux, ou construisent une couche entièrement connectée avec des caractéristiques globales pour prédire la voie. Ces détecteurs ont démontré l'importance des caractéristiques locales ou globales pour la détection de voie, mais n'exploitent pas les deux caractéristiques simultanément, produisant ainsi potentiellement des performances de détection inexactes. Par exemple, SCNN et RESA proposent un mécanisme de transmission de messages pour collecter le contexte global, mais ces méthodes effectuent une prédiction au niveau des pixels et ne traitent pas les voies comme une unité entière. En conséquence, leurs performances sont en retard par rapport à celles de nombreux détecteurs de pointe.
Pour la détection de voie, les fonctionnalités de bas niveau et de haut niveau sont complémentaires. Sur cette base, cet article propose une nouvelle architecture de réseau (CLRNet) pour exploiter pleinement les fonctionnalités de bas niveau et de haut niveau pour la détection de voie. Premièrement, le contexte global est collecté via ROIGather pour améliorer encore la représentation des caractéristiques des voies, qui peuvent également être insérées dans d'autres réseaux. Deuxièmement, une perte Line over Union (LIoU) adaptée à la détection de voie est proposée pour régresser la voie dans son ensemble et améliorer considérablement les performances. Afin de mieux comparer la précision de positionnement des différents détecteurs, un nouvel indicateur mF1 est également utilisé.
La détection de voies basée sur CNN est actuellement principalement divisée en trois méthodes : la méthode basée sur la segmentation, la méthode basée sur les ancres et la méthode basée sur les paramètres. Ces méthodes identifient en fonction de la représentation des voies.
1. Méthode basée sur la segmentation
Ce type d'algorithme adopte généralement une formule de prédiction pixel par pixel, c'est-à-dire que la détection de voie est considérée comme une tâche de segmentation sémantique. SCNN propose un mécanisme de transmission de messages pour résoudre le problème des objets non détectables visuellement, qui capture les fortes relations spatiales présentes dans les voies. SCNN améliore considérablement les performances de détection de voie, mais la méthode est lente pour les applications en temps réel. RESA propose un module d'agrégation de fonctionnalités en temps réel qui permet au réseau de collecter des fonctionnalités globales et d'améliorer les performances. Dans CurveLane-NAS, la recherche d'architecture neuronale (NAS) est utilisée pour trouver de meilleurs réseaux qui capturent des informations précises pour faciliter la détection des voies courbes. Cependant, le NAS est extrêmement coûteux en calcul et nécessite beaucoup de temps GPU. Ces méthodes basées sur la segmentation sont inefficaces et longues car elles effectuent des prédictions au niveau des pixels sur l’ensemble de l’image et ne considèrent pas la voie comme une unité entière.
2. Méthodes basées sur l'ancrage
Les méthodes basées sur l'ancrage dans la détection de voie peuvent être divisées en deux catégories, telles que les méthodes basées sur l'ancrage de ligne et les méthodes basées sur l'ancrage de ligne. Les méthodes basées sur l'ancrage de ligne utilisent des ancrages de ligne prédéfinis comme références pour régresser des voies précises. Line-CNN est un travail pionnier utilisant des lignes et des accords dans la détection de voies. LaneATT propose un nouveau mécanisme d'attention basé sur une ancre qui peut regrouper des informations mondiales. Il obtient des résultats de pointe et montre une efficacité et une efficience élevées. SGNet présente un nouveau générateur d'ancres guidées par point de fuite et ajoute plusieurs guides structurels pour améliorer les performances. Pour la méthode basée sur l’ancrage de ligne, elle prédit les cellules possibles pour chaque ligne prédéfinie de l’image. UFLD a d'abord proposé une méthode de détection de voie basée sur l'ancrage de voie et a adopté un réseau fédérateur léger pour atteindre une vitesse d'inférence élevée. Bien que simple et rapide, ses performances globales ne sont pas bonnes. CondLaneNet introduit une stratégie de détection de voie conditionnelle basée sur une convolution conditionnelle et une formule basée sur l'ancrage de ligne, c'est-à-dire qu'il localise d'abord le point de départ de la ligne de voie, puis effectue une détection de voie basée sur l'ancrage de ligne. Cependant, dans certains scénarios complexes, le point de départ est difficile à identifier, ce qui entraîne des performances relativement médiocres.
3. Méthode basée sur les paramètres
Différente de la régression ponctuelle, la méthode basée sur les paramètres utilise des paramètres pour modéliser la courbe de la voie et régresse ces paramètres pour détecter la voie. PolyLaneNet adopte un problème de régression polynomiale et atteint une efficacité élevée. LSTR prend en compte la structure de la route et la pose de la caméra pour modéliser la forme de la voie, puis introduit Transformer dans la tâche de détection de voie pour obtenir des caractéristiques globales.
Les méthodes basées sur des paramètres nécessitent moins de paramètres pour régresser, mais sont sensibles aux paramètres de prédiction. Par exemple, des prédictions incorrectes de coefficients d'ordre élevé peuvent entraîner des changements dans la forme des voies. Bien que les méthodes basées sur des paramètres aient une vitesse d’inférence rapide, elles ont encore du mal à atteindre des performances plus élevées.
Aperçu méthodologique du réseau de raffinement multicouche (CLRNet)
Dans cet article, un nouveau cadre - le réseau de raffinement multicouche (CLRNet) est introduit, qui utilise pleinement les fonctionnalités de bas niveau et de haut niveau pour détection de détection de voie. Plus précisément, les caractéristiques sémantiques élevées sont d'abord détectées pour localiser approximativement les voies. Affinez ensuite progressivement la position de la voie et l'extraction des caractéristiques en fonction des caractéristiques détaillées pour obtenir des résultats de détection de haute précision (c'est-à-dire des positions plus précises). Afin de résoudre le problème des zones aveugles dans les voies qui ne peuvent pas être détectées visuellement, un collecteur ROI est introduit pour capturer des informations contextuelles plus globales en établissant la relation entre les caractéristiques des voies ROI et l'ensemble de la carte des caractéristiques. De plus, le rapport d'intersection sur union IoU des lignes de voie est également défini, et la perte de ligne IoU (LIoU) est proposée pour régresser la voie dans son ensemble, améliorant considérablement les performances par rapport à la perte standard (c'est-à-dire, lisse -l1 perte).
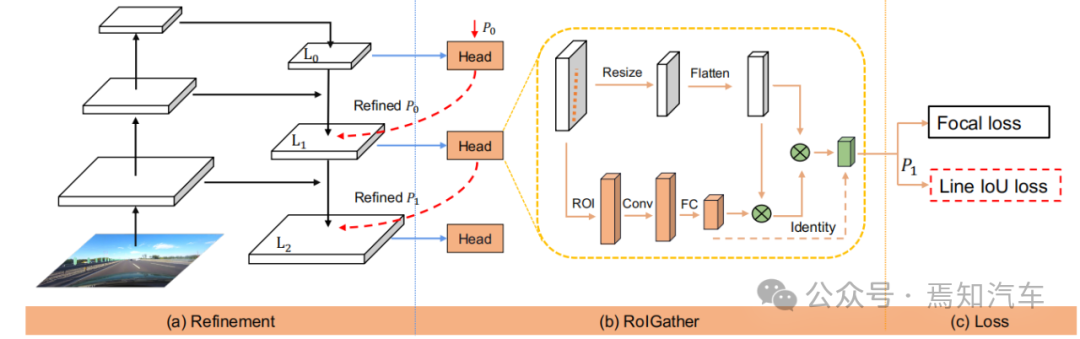
Figure 2. Présentation de CLRNet
La figure ci-dessus montre l'ensemble du réseau frontal pour le traitement IoU de ligne de voie à l'aide de l'algorithme CLRNet présenté dans cet article. Parmi eux, le réseau de la figure (a) génère des cartes de fonctionnalités à partir de la structure FPN. Par la suite, chaque voie avant sera affinée, passant des fonctionnalités de haut niveau aux fonctionnalités de bas niveau. La figure (b) indique que chaque responsable utilisera davantage d'informations contextuelles pour obtenir des caractéristiques antérieures pour la voie. La figure (c) montre la classification et la régression préalables des voies. La perte Line IoU proposée dans cet article contribue à améliorer encore les performances de régression.
Ce qui suit expliquera plus en détail le processus de fonctionnement de l'algorithme présenté dans cet article.
1. Représentation du réseau de voies
Comme nous le savons tous, les voies dans les routes réelles sont fines et longues. Cette représentation caractéristique a de fortes informations préalables de forme, de sorte que l'avant de voie prédéfini peut aider le réseau à mieux localiser la voie. Dans la détection d'objets conventionnelle, les objets sont représentés par des cases rectangulaires. Cependant, les cases rectangulaires, quelles qu’elles soient, ne conviennent pas pour représenter de longues lignes. Ici, des points 2D équidistants sont utilisés comme représentation de voie. Plus précisément, une voie est représentée comme une séquence de points, c'est-à-dire P = {(x1, y1), ···,(xN , yN )}. Les coordonnées y des points sont échantillonnées uniformément dans la direction verticale de l'image, c'est-à-dire 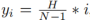 , où H est la hauteur de l'image. Par conséquent, la coordonnée x est associée au
, où H est la hauteur de l'image. Par conséquent, la coordonnée x est associée au 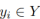 correspondant, et cette représentation est appelée ici Lane-first. Chaque voie préalable sera prédite par le réseau et se compose de quatre parties :
correspondant, et cette représentation est appelée ici Lane-first. Chaque voie préalable sera prédite par le réseau et se compose de quatre parties :
(1) Probabilités de premier plan et d'arrière-plan.
(2) La longueur des voies est prioritaire.
(3) L'angle entre le point de départ de la ligne de voie et l'axe x de la voie précédente (appelé x, y et θ).
(4) N décalages, c'est-à-dire la distance horizontale entre la prédiction et sa vraie valeur.
2. Motivation de raffinement multicouche
Dans les réseaux de neurones, les fonctionnalités profondes de haut niveau affichent un retour plus fort sur les cibles routières avec plus de fonctionnalités sémantiques, tandis que les fonctionnalités peu profondes de bas niveau ont plus d'informations contextuelles locales. Les algorithmes permettant aux objets de voie d'accéder à des fonctionnalités de haut niveau peuvent aider à exploiter des informations contextuelles plus utiles, telles que la distinction des lignes de voie ou des points de repère. Dans le même temps, des fonctionnalités de détails fins aident à détecter les voies avec une grande précision de positionnement. Dans la détection d'objets, il crée une pyramide de fonctionnalités pour exploiter la forme pyramidale de la hiérarchie des fonctionnalités ConvNet et attribue des objets de différentes échelles à différents niveaux de pyramide. Cependant, il est difficile d’attribuer directement une voie à un seul niveau, puisque les fonctions de haut niveau et de bas niveau sont essentielles à la voie. Inspirés de Cascade RCNN, les objets de voie peuvent être attribués à tous les niveaux et détecter les voies individuelles de manière séquentielle.
En particulier, les voies dotées de fonctionnalités avancées peuvent être détectées pour localiser approximativement les voies. Sur la base des voies connues détectées, des fonctionnalités plus détaillées peuvent être utilisées pour les affiner.
3. Structure raffinée
Le but de l'ensemble de l'algorithme est d'exploiter la hiérarchie des fonctionnalités pyramidales de ConvNet (avec une sémantique du bas niveau au haut niveau) et de construire une pyramide des fonctionnalités qui a toujours un niveau élevé. sémantique au niveau. Le réseau résiduel ResNet est utilisé comme épine dorsale et {L0, L1, L2} est utilisé pour représenter les niveaux de fonctionnalités générés par FPN.
Comme le montre la figure 2, le raffinement inter-couches commence à partir du niveau le plus élevé L0 et se rapproche progressivement de L2. Le raffinement correspondant est représenté en utilisant {R0,R1,R2}. Vous pouvez ensuite procéder à la construction d'une série de structures raffinées :
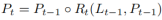
où t = 1, · · · , T, T est le nombre total de raffinements.
L'ensemble de la méthode effectue une détection à partir de la couche la plus élevée avec une sémantique élevée, Pt est le paramètre de la voie antérieure (coordonnées du point de départ x, y et angle θ), qui est inspiré et auto-apprenant. Pour la première couche L0, P0 est uniformément distribué sur le plan image, le raffinement Rt prend Pt comme entrée pour obtenir les caractéristiques de la voie ROI, puis effectue deux couches FC pour obtenir les paramètres de raffinement Pt. L'affinement progressif des informations préalables sur les voies et l'extraction des informations sur les caractéristiques sont très importants pour le raffinement inter-couches. Notez que cette méthode ne se limite pas aux structures FPN, seule l'utilisation de ResNet ou l'adoption de PAFPN convient également.
4. Collecte ROI
Après avoir attribué des informations préalables à la voie à chaque carte de caractéristiques, le module ROI Align peut être utilisé pour obtenir les caractéristiques préalables à la voie. Cependant, les informations contextuelles de ces fonctionnalités sont encore insuffisantes. Dans certains cas, les instances de voie peuvent être occupées ou obscurcies dans des conditions d'éclairage extrêmes. Dans ce cas, il se peut qu’il n’y ait pas de données de suivi visuelles locales en temps réel pour indiquer la présence de la voie. Afin de déterminer si un pixel appartient à une voie, il faut examiner les entités à proximité. Certaines recherches récentes ont également montré que les performances peuvent être améliorées si les dépendances distantes sont pleinement exploitées. Par conséquent, des informations contextuelles plus utiles peuvent être collectées pour mieux connaître les caractéristiques des voies.
Pour ce faire, des calculs de convolution sont d'abord effectués le long de la voie, afin que chaque pixel de la voie précédente puisse collecter des informations sur les pixels proches, et que la partie occupée puisse être améliorée en fonction de ces informations. De plus, la relation entre les caractéristiques antérieures de voie et l'ensemble de la carte de caractéristiques est établie. Par conséquent, davantage d’informations contextuelles peuvent être exploitées pour apprendre de meilleures représentations de fonctionnalités.
L'ensemble de la structure du module de collecte ROI est léger et facile à mettre en œuvre. Étant donné qu'il prend en entrée les cartes de caractéristiques et les priorités de voie, chaque priorité de voie a N points. Différent du ROI Align de la boîte englobante, pour chaque collecte d'informations préalables à la voie, il est nécessaire d'abord d'obtenir les caractéristiques du ROI antérieur à la voie (Xp ∈ RC×Np) en fonction du ROI Align. Échantillonnez Np points uniformément à partir de la voie précédente et utilisez l'interpolation bilinéaire pour calculer les valeurs exactes des entités en entrée à ces emplacements. Pour les fonctionnalités ROI de L1 et L2, la représentation des fonctionnalités peut être améliorée en connectant les fonctionnalités ROI des couches précédentes. Les caractéristiques proches de chaque pixel de voie peuvent être collectées par convolution des caractéristiques de retour sur investissement extraites. Afin d'économiser de la mémoire, entièrement connecté est utilisé ici pour extraire davantage les caractéristiques antérieures de la voie (Xp ∈ RC×1), où la taille de la carte des caractéristiques est ajustée à Elle peut continuer à être aplatie à Xf∈ RC×HW. Afin de collecter les informations de contexte global de la voie avec des caractéristiques antérieures, il est nécessaire de d'abord calculer la matrice d'attention W entre les caractéristiques antérieures de la voie ROI (Xp) et la carte de caractéristiques globale (Xf), qui s'écrit comme :
où f est la fonction de normalisation soft max. Les caractéristiques agrégées peuvent être écrites comme suit :
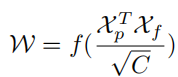
La sortie G reflète la valeur de superposition de Xf sur Xp , qui est sélectionnée parmi toutes les positions de Xf . Enfin, la sortie est ajoutée à l'entrée Xp d'origine.
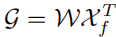
Figure 3. Illustration des poids d'attention dans ROIGather
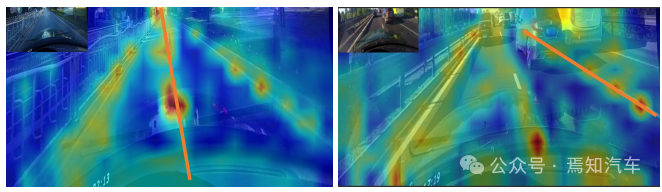
5. Intersection de la ligne de voie et perte d'IoU du rapport d'union
Comme mentionné ci-dessus, l'avant de la voie est constitué de points discrets qui doivent être régressés vers leur vérité terrain. Les pertes de distance courantes telles que smooth-l1 peuvent être utilisées pour régresser ces points. Cependant, cette perte traite les points comme des variables distinctes, ce qui constitue une hypothèse trop simpliste et aboutit à une régression moins précise.
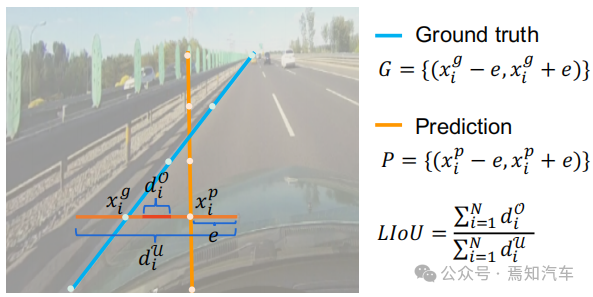
Contrairement à la perte de distance, l'intersection sur union (IoU) peut régresser les priorités de voie dans son ensemble, et elle est adaptée à la métrique d'évaluation. Un algorithme simple et efficace est dérivé ici pour calculer la perte Line over Union (LIoU).Comme le montre la figure ci-dessous, l'intersection de lignes et le rapport d'union IoU peuvent être calculés en intégrant l'IoU du segment étendu en fonction de la position xi échantillonnée.
Figure 4. Diagramme IoU de ligne
pi
) en un segment de ligne de rayon e. Ensuite, l'IoU entre le segment de ligne étendu et sa vérité fondamentale peut être calculée, écrite sous la forme :où xpi - e, xpi + e est le point d'expansion de xpi i + e est le point de vérité terrain correspondant. Notez que d0i peut être négatif, ce qui permet une optimisation efficace des informations dans le cas de segments de ligne qui ne se chevauchent pas. Alors LIoU peut être considéré comme une combinaison de points de ligne infinis. Pour simplifier l'expression et faciliter son calcul, convertissez-la sous forme discrète, Ensuite, la perte LIoU est définie comme : où −1 ≤ LIoU ≤1, lorsque deux lignes se chevauchent parfaitement, alors LIoU = 1. Lorsque les deux lignes sont éloignées, LIoU converge vers -1. 6. Détails de la formation et de l'inférence
Tout d'abord, la sélection avancée des échantillons est effectuée. Pendant le processus de formation, chaque voie de vérité terrain se voit attribuer dynamiquement une ou plusieurs voies prédites en tant qu'échantillon positif. En particulier, les voies de prédiction sont triées en fonction du coût d'allocation, qui est défini comme :
où Ccls est le coût focal entre la prédiction et l'étiquette. Csim est le coût de similarité entre la voie prédite et la voie réelle. Il se compose de trois parties. Cdis représente la distance moyenne en pixels de tous les points de voie valides, Cxy représente la distance des coordonnées du point de départ et Ctheta représente la différence d'angle thêta. Ils sont tous normalisés à [0, 1]. wcls et wsim sont les coefficients de pondération de chaque composant défini. Chaque voie de vérité terrain se voit attribuer un nombre dynamique (top-k) de voies prédites selon Cassign. La perte de formation comprend la perte de classification et la perte de régression, où la perte de régression est calculée uniquement pour des échantillons spécifiés. La fonction de perte globale est définie comme :
Lcls est la perte focale entre les prédictions et les étiquettes, Lxytl est la perte lisse-l1 pour la régression des coordonnées du point de départ, de l'angle thêta et de la longueur de la voie, LLIoU est entre les voies de prédiction et la vérité terrain sur la perte de la ligne IoU. En ajoutant une perte de segmentation auxiliaire, elle n'est utilisée que pendant la formation et n'a aucun coût d'inférence. Résumé Dans cet article, nous avons proposé un réseau de raffinement multicouche (CLRNet) pour la détection de voie. CLRNet peut utiliser des fonctionnalités de haut niveau pour prédire les voies tout en tirant parti des fonctionnalités locales détaillées pour améliorer la précision de la localisation. Afin de résoudre le problème de l'insuffisance des preuves visuelles de l'existence des voies, il est proposé d'améliorer la représentation des caractéristiques des voies en établissant des relations avec tous les pixels via ROIGather. Pour régresser les voies dans leur ensemble, une perte Line IoU adaptée à la détection des voies est proposée, ce qui améliore considérablement les performances par rapport à la perte standard (c'est-à-dire une perte Smooth-L1). La présente méthode est évaluée sur trois ensembles de données de référence de détection de voie, à savoir CULane, LLamas et Tusimple. La méthode proposée surpasse considérablement les autres méthodes de pointe (CULane, Tusimple et LLAMAS) sur trois critères de détection de voie. 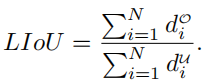
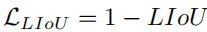 Le calcul de la corrélation des lignes de voie via la perte Line IoU présente deux avantages : (1) Il est simple et différenciable, et il est facile de mettre en œuvre le calcul parallèle. (2) Il prédit la voie dans son ensemble, ce qui contribue à améliorer les performances globales.
Le calcul de la corrélation des lignes de voie via la perte Line IoU présente deux avantages : (1) Il est simple et différenciable, et il est facile de mettre en œuvre le calcul parallèle. (2) Il prédit la voie dans son ensemble, ce qui contribue à améliorer les performances globales. 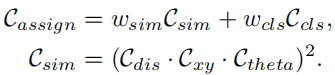 Deuxièmement, il y a la perte d'entraînement.
Deuxièmement, il y a la perte d'entraînement. 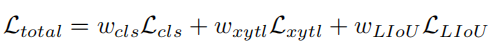 Enfin, il s’agit de raisonner efficacement. Filtrez les voies d'arrière-plan (voie à faible score avant) en définissant un seuil avec un score de classification et utilisez NMS pour supprimer ensuite les voies à chevauchement élevé. Cela peut également être sans NMS si vous utilisez une allocation individuelle, c'est-à-dire en définissant top-k = 1.
Enfin, il s’agit de raisonner efficacement. Filtrez les voies d'arrière-plan (voie à faible score avant) en définissant un seuil avec un score de classification et utilisez NMS pour supprimer ensuite les voies à chevauchement élevé. Cela peut également être sans NMS si vous utilisez une allocation individuelle, c'est-à-dire en définissant top-k = 1.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!