
Maison >Périphériques technologiques >IA >Publication du rapport technique de Stable Diffusion 3 : révélant les mêmes détails d'architecture de Sora
Publication du rapport technique de Stable Diffusion 3 : révélant les mêmes détails d'architecture de Sora

- 王林avant
- 2024-03-07 12:01:11959parcourir
Très bientôt, le rapport technique de Stable Diffusion 3, le « nouveau roi du graphisme vincentien », est là.
Le texte intégral compte 28 pages au total et est plein de sincérité.

"Old Rules", les affiches promotionnelles (⬇️) sont directement générées avec les modèles, et montrent leurs capacités de rendu de texte :
Donc, SD3 a un texte et des commandes plus forts que DALL·E 3 et Midjourney v6 Comment la compétence suivante s’allume-t-elle ?
Le rapport technique révèle :
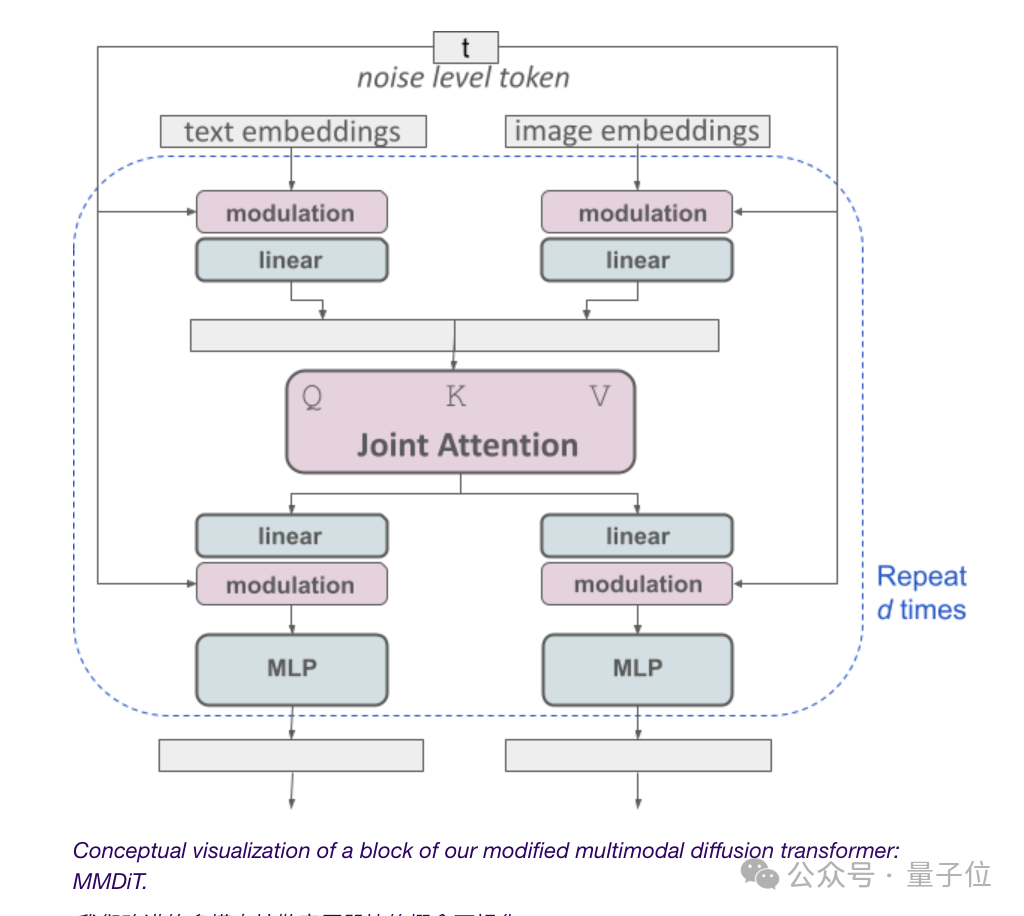
Tout repose sur l'architecture Transformer de diffusion multimodale MMDiT.
Obtenir de plus grandes améliorations de performances que les versions précédentes en appliquant différents ensembles de pondérations respectivement aux représentations d'images et de texte, ce qui est la clé du succès.
Pour la géométrie spécifique, ouvrons le rapport et voyons.
DiT affiné pour améliorer les capacités de rendu de texte
Au début de la sortie de SD3, le responsable a révélé que son architecture a la même origine que Sora et est un Transformer-DiT de diffusion.
Maintenant, la réponse est révélée :
Étant donné que le modèle de diagramme de Vincent doit prendre en compte à la fois les modes texte et image, Stability AI va encore plus loin que DiT et propose une nouvelle architecture MMDiT.
Le « MM » fait ici référence à « multimodal ».
Comme les versions précédentes de Stable Diffusion, le responsable utilise deux modèles pré-entraînés pour obtenir des représentations de texte et d'images appropriées.
L'encodage de la représentation textuelle se fait à l'aide de trois embedders de texte différents (embedders), dont deux modèles CLIP et un modèle T5.
L'encodage du jeton d'image est complété à l'aide d'un modèle d'encodeur automatique amélioré.
Étant donné que l'intégration de texte et d'image n'est pas conceptuellement la même chose, SD3 utilise deux ensembles de poids indépendants pour ces deux modes.
(Certains internautes se sont plaints : ce schéma d'architecture semble lancer le "Human Completion Project", oui, certaines personnes ont simplement "vu les informations sur "Neon Genesis Evangelion" et ont cliqué sur ce rapport")
Pour revenir au sujet, comme le montre la figure ci-dessus, cela équivaut à avoir deux transformateurs indépendants pour chaque modalité, mais leurs séquences seront connectées pour les opérations d'attention.
De cette façon, les deux représentations peuvent fonctionner dans leur propre espace tout en tenant compte de l'autre.
En fin de compte, grâce à cette méthode, les informations peuvent « circuler » entre les images et les jetons de texte, améliorant ainsi la compréhension globale du modèle et les capacités de rendu du texte lors de la sortie.
Et comme le montre l'effet précédent, cette architecture peut également être facilement étendue à plusieurs modes comme la vidéo.

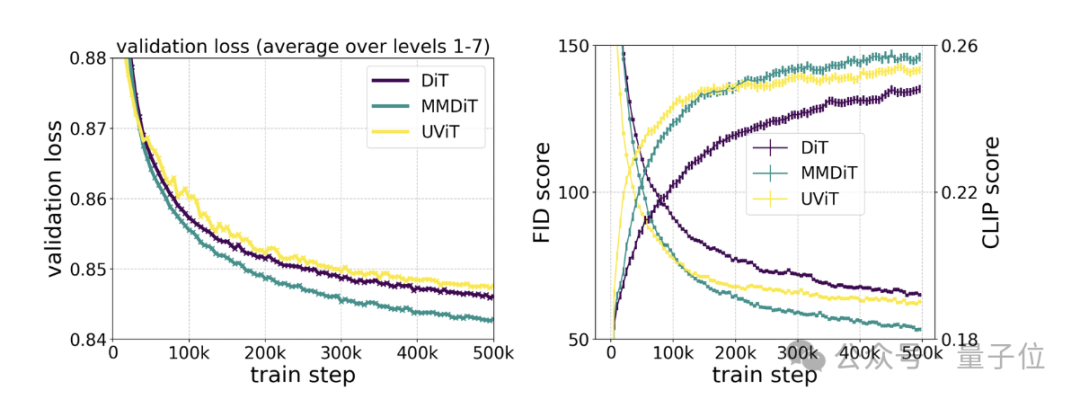
Des tests spécifiques montrent que MMDiT est basé sur DiT mais est meilleur que DiT :
Sa fidélité visuelle et l'alignement du texte pendant le processus de formation sont meilleurs que les backbones texte-image existants, tels que UViT et DiT.
Technologie de flux repondérée pour améliorer continuellement les performances
Au début de la version, en plus de l'architecture de diffusion Transformer, le responsable a également révélé que SD3 intègre la correspondance de flux.
Quel « flux » ?
Comme le révèle le titre de l'article publié aujourd'hui, SD3 utilise le « Rectified Flow » (RF).

Il s'agit d'une nouvelle méthode de génération de modèle de diffusion de « génération en une étape extrêmement simplifiée », qui a été sélectionnée pour l'ICLR2023.
Il permet aux données et au bruit du modèle d'être connectés selon une trajectoire linéaire pendant l'entraînement, produisant un chemin d'inférence plus « droit » qui peut utiliser moins d'étapes pour l'échantillonnage.
Basé sur RF, SD3 introduit un nouvel échantillonnage de trajectoire pendant le processus d'entraînement.
Il s’efforce de donner plus de poids à la partie médiane de la trajectoire, car l’auteur suppose que ces parties effectueront des tâches de prédiction plus difficiles.
Le test de cette méthode de génération par rapport à 60 autres méthodes de trajectoire de diffusion (telles que LDM, EDM et ADM) sur plusieurs ensembles de données, métriques et configurations d'échantillonneurs a révélé que :
Alors que les méthodes RF précédentes fonctionnaient bien dans les schémas d'échantillonnage en quelques étapes, elles offraient de bonnes performances, mais leurs performances relatives diminuent à mesure que le nombre d'étapes augmente.
En revanche, la variante RF repondérée SD3 améliore continuellement les performances.
La capacité du modèle peut être encore améliorée
Le responsable a mené une étude de mise à l'échelle sur la génération de texte en image en utilisant la méthode RF repondérée et l'architecture MMDiT.
Les modèles formés vont de 15 modules avec 450 millions de paramètres à 38 modules avec 8 milliards de paramètres.
À partir de là, ils ont observé : à mesure que la taille du modèle et les étapes de formation augmentent, la perte de validation montre une tendance à la baisse douce, c'est-à-dire que le modèle s'adapte à des données plus complexes grâce à un apprentissage continu.
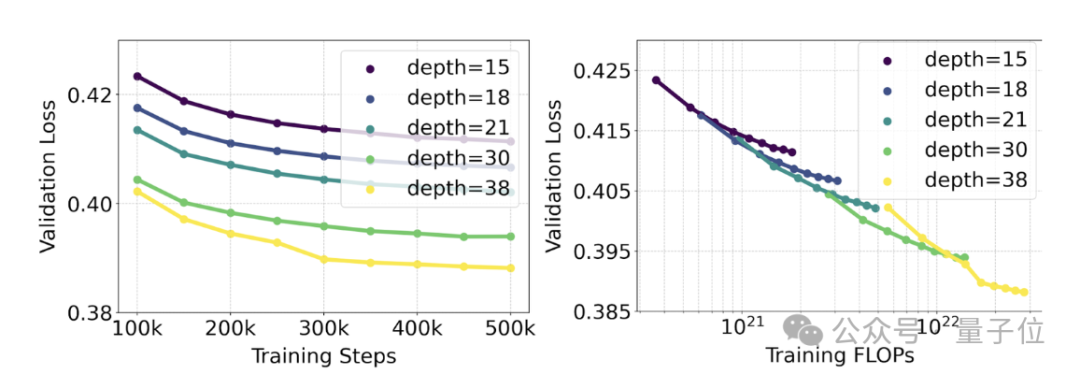
Pour tester si cela se traduisait par des améliorations plus significatives de la sortie du modèle, nous avons également évalué la métrique d'alignement automatique de l'image (GenEval) ainsi que le score de préférence humaine (ELO) .
Le résultat est :
Il existe une forte corrélation entre les deux. Autrement dit, la perte de vérification peut être utilisée comme un indicateur très puissant pour prédire les performances globales du modèle.
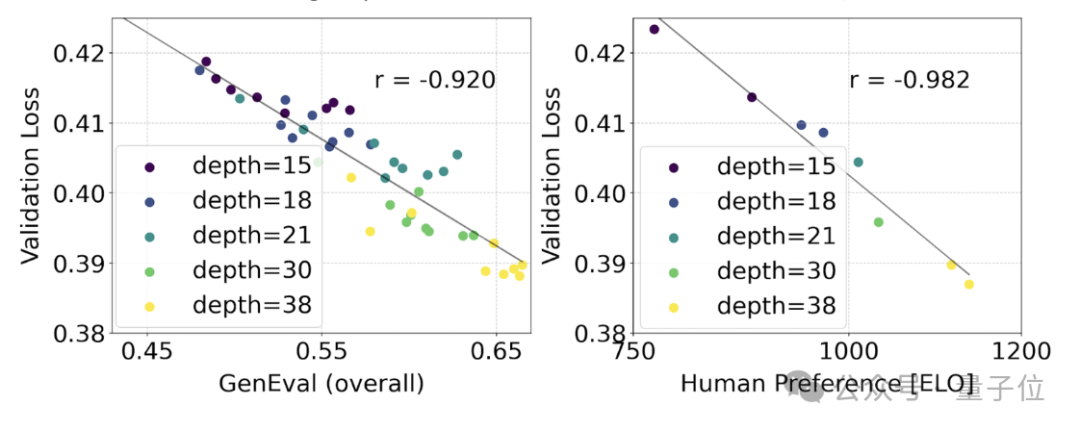
De plus, comme la tendance à l'expansion ici ne montre aucun signe de saturation (c'est-à-dire qu'à mesure que la taille du modèle augmente, les performances s'améliorent encore et n'ont pas atteint la limite), le responsable est très optimiste :
Le les performances du SD3 à l’avenir peuvent encore continuer à s’améliorer.
Enfin, le rapport technique mentionne également la question des encodeurs de texte :
En supprimant le paramètre 4,7 milliards, encodeur de texte T5 gourmand en mémoire utilisé pour l'inférence, les besoins en mémoire du SD3 peuvent être considérablement réduits, mais en même temps, la perte de performance est faible (le taux de victoire est passé de 50 % à 46 %).
Cependant, pour des raisons de capacités de rendu de texte, la recommandation officielle est de ne pas supprimer T5, car sans lui, le taux de réussite de la représentation de texte tombera à 38 %.

Donc, pour résumer : parmi les trois encodeurs de texte du SD3, T5 apporte la plus grande contribution lors de la génération d'images avec du texte (et d'images de description de scène très détaillées).
Internautes : L'engagement open source a été rempli comme prévu, merci
Dès la publication du rapport SD3, de nombreux internautes ont déclaré :
Stability AI est très heureux que l'engagement open source ait été rempli comme prévu, et j'espère qu'ils pourront continuer à l'entretenir et à l'exploiter pendant longtemps.

Certaines personnes sont sur le point de revendiquer le nom d'OpenAI :

Ce qui est encore plus gratifiant, c'est que quelqu'un a mentionné dans la zone de commentaire :
Tous les poids du modèle SD3 peuvent être téléchargés, et le plan actuel est de 800 millions de paramètres, 2 milliards de paramètres et 8 milliards de paramètres.


Comment est la vitesse ?
Ahem, le rapport technique mentionne :
8 milliards de SD3 prennent 34 secondes pour générer une image 1024*1024 sur un RTX 4090 de 24 Go (50 étapes d'échantillonnage) - mais ce n'est qu'un premier résultat de test d'inférence préliminaire non optimisé.
Texte intégral du rapport : https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf.
Lien de référence :
[1]https://stability.ai/news/stable-diffusion-3-research-paper.
[2]https://news.ycombinator.com/item?id=39599958.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Modèle de graphique Wensheng open source de Stability AI ; Mo Yan a demandé à ChatGPT d'écrire le discours de remise des prix ; Yuncong a publié quotidiennement un grand modèle d'IA pour l'événement majeur de l'AIGC ;
- Stability AI lance le modèle de graphique vincentien SDXL0.9, avec des exigences GPU abaissées au niveau grand public