
Maison >Périphériques technologiques >IA >Construction du système d'étiquettes de portrait et pratique d'application
Construction du système d'étiquettes de portrait et pratique d'application

- 王林avant
- 2024-03-07 11:50:07824parcourir
1. Système de balises d'images
Qunar a construit un système de balises d'images indépendant dans chaque processus de développement commercial. À mesure que l’entreprise continue de croître, il est nécessaire d’intégrer le système d’étiquetage des portraits de chaque entreprise. D'un point de vue technique, le processus d'intégration est relativement simple, mais l'intégration au niveau métier est plus complexe. Parce que chaque label a des définitions différentes selon les métiers, cela augmente la difficulté d’intégration. Afin de garantir que le système d'étiquettes intégré puisse mieux servir la stratégie globale de l'entreprise, une extraction et une optimisation approfondies des mots clés sont nécessaires pour garantir la logique et la cohérence de chaque étiquette.

1. Qu'est-ce qu'une balise portrait
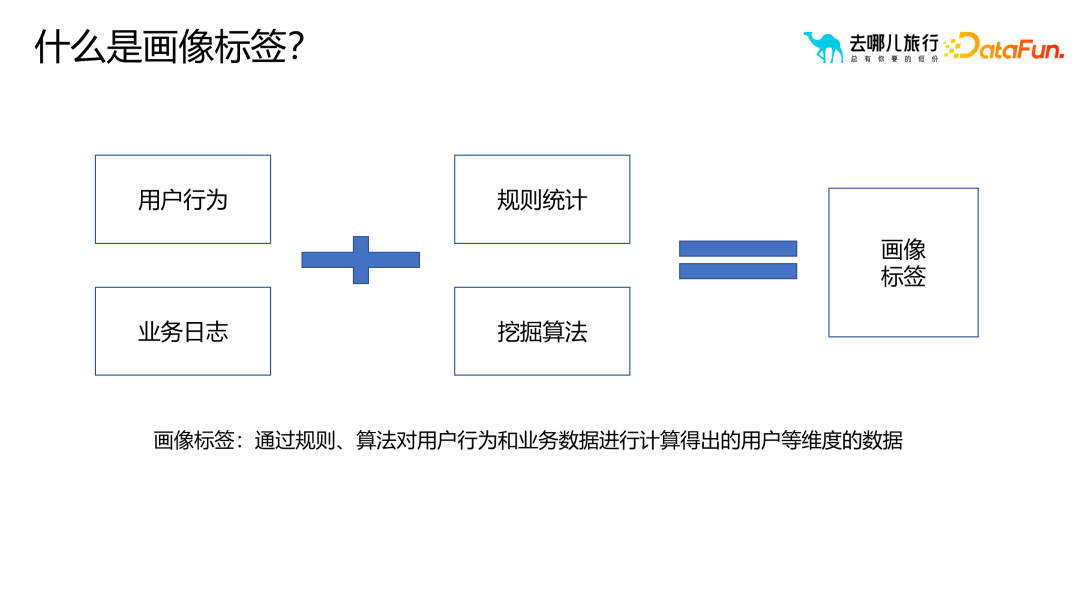
Le comportement de l'utilisateur fait référence aux opérations effectuées par les utilisateurs dans l'application, tandis que les journaux d'entreprise font référence aux données générées par les utilisateurs côté serveur, telles que les clics, commandes et comportement de recherche. Les balises Portrait sont des données multidimensionnelles des utilisateurs obtenues en analysant le comportement des utilisateurs et les données commerciales via des statistiques de règles et des algorithmes d'exploration de données. En analysant le comportement des utilisateurs et les données commerciales, nous pouvons mieux comprendre les préférences et les besoins des utilisateurs, offrant ainsi aux utilisateurs des services plus personnalisés et plus précis. Ces balises de portrait d'utilisateur peuvent aider les entreprises à mieux localiser les groupes d'utilisateurs cibles, à formuler des stratégies marketing ciblées et à améliorer l'expérience utilisateur. Grâce à une analyse approfondie du comportement des utilisateurs et des données commerciales, les entreprises peuvent mieux comprendre les modèles de comportement des utilisateurs et fournir aux utilisateurs de meilleurs produits et services, améliorant ainsi la satisfaction et la fidélité des utilisateurs. 2. Demande de balises de portrait Source
 Quand chaque entreprise. Le département construit sa propre plate-forme d'étiquetage de portraits, ses besoins sont également différents en raison d'objectifs différents. Par exemple, le secteur des billets d'avion cible généralement le marketing et le secteur hôtelier cible généralement le service. Nous devons partir des besoins réels de l'entreprise et communiquer avec différents départements, y compris la direction de l'entreprise, les stagiaires et autres membres du personnel à différents niveaux, pour mener une recherche approfondie sur la demande afin de garantir que le système d'étiquetage intégré puisse mieux répondre aux besoins de l'entreprise. Au cours du processus d'intégration, les exigences en matière d'étiquette de portrait d'utilisateur sont principalement divisées en trois catégories : contrôle des risques marketing, applications d'analyse commerciale interne et description des utilisateurs.
Quand chaque entreprise. Le département construit sa propre plate-forme d'étiquetage de portraits, ses besoins sont également différents en raison d'objectifs différents. Par exemple, le secteur des billets d'avion cible généralement le marketing et le secteur hôtelier cible généralement le service. Nous devons partir des besoins réels de l'entreprise et communiquer avec différents départements, y compris la direction de l'entreprise, les stagiaires et autres membres du personnel à différents niveaux, pour mener une recherche approfondie sur la demande afin de garantir que le système d'étiquetage intégré puisse mieux répondre aux besoins de l'entreprise. Au cours du processus d'intégration, les exigences en matière d'étiquette de portrait d'utilisateur sont principalement divisées en trois catégories : contrôle des risques marketing, applications d'analyse commerciale interne et description des utilisateurs.
Contrôle des risques marketing : marketing utilisateurs, recommandations personnalisées, publicité précise et contrôle des risques utilisateurs.
- Analyse commerciale : analyse de l'optimisation commerciale, surveillance des indicateurs commerciaux multidimensionnels et conseils sur la conception de nouveaux produits commerciaux.
- Décrire les utilisateurs : la définition d'un utilisateur unique, le positionnement des utilisateurs de la plateforme et les rapports de l'industrie.
- 3. La classification des tags portrait
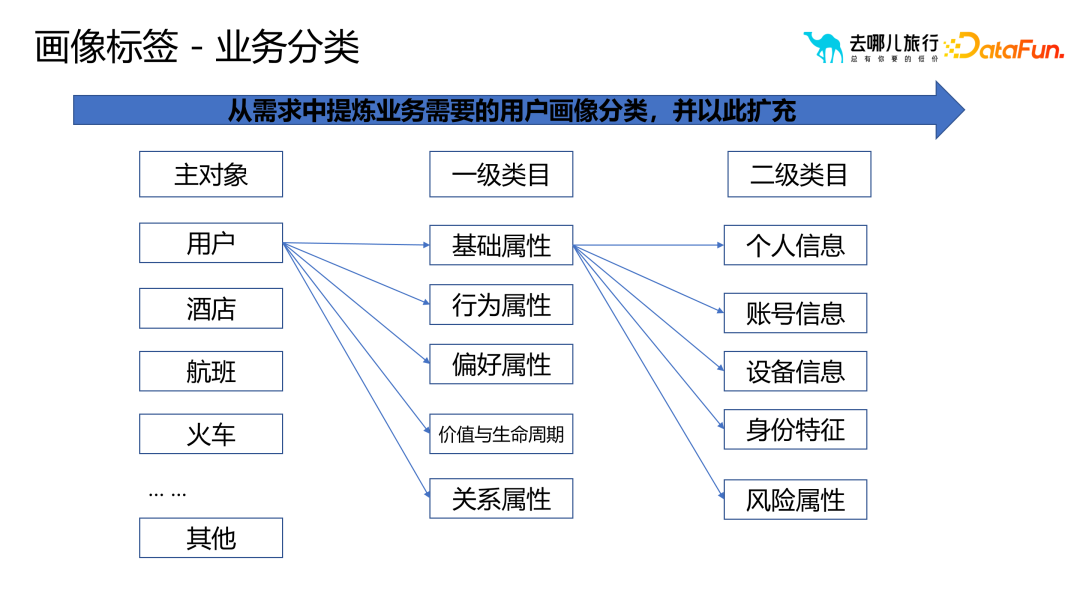
 est divisée en classification métier et classification technique en cours de construction des tags portrait.
est divisée en classification métier et classification technique en cours de construction des tags portrait.
Extraire la classification du portrait d'utilisateur requise pour l'entreprise à partir des besoins des utilisateurs, principalement basée sur les catégories de premier et deuxième niveaux, avec le processus métier comme base de classification principale, et continuer à se développer et à s'améliorer.
De plus, en fonction des différents besoins techniques, nous devons choisir la pile technologique appropriée pour réaliser la génération, le stockage et l'appel de tags portrait.
 Tout d'abord, il est nécessaire de clarifier la définition et les objectifs des tags portrait afin de déterminer quelle technologie doit être utilisée. Deuxièmement, le cycle de mise à jour et la méthode d'accès aux balises doivent être pris en compte, ce qui détermine si les balises doivent être traitées en ligne ou hors ligne et quelles ressources de stockage sont sélectionnées. Enfin, sur la base de ces facteurs, nous pouvons choisir la pile technologique appropriée pour mettre en œuvre le système d'étiquetage portrait et garantir les performances et la stabilité du système. Grâce à une telle classification technique, le système d'étiquettes portrait peut être mieux géré et entretenu, et son évolutivité et sa convivialité peuvent être améliorées
Tout d'abord, il est nécessaire de clarifier la définition et les objectifs des tags portrait afin de déterminer quelle technologie doit être utilisée. Deuxièmement, le cycle de mise à jour et la méthode d'accès aux balises doivent être pris en compte, ce qui détermine si les balises doivent être traitées en ligne ou hors ligne et quelles ressources de stockage sont sélectionnées. Enfin, sur la base de ces facteurs, nous pouvons choisir la pile technologique appropriée pour mettre en œuvre le système d'étiquetage portrait et garantir les performances et la stabilité du système. Grâce à une telle classification technique, le système d'étiquettes portrait peut être mieux géré et entretenu, et son évolutivité et sa convivialité peuvent être améliorées
(1) Méthode de construction
- Classe statistique : Elle peut être complétée en s'appuyant sur SQL.
- Type de règle : pour les personnes ayant une certaine expérience commerciale, telles que les analystes de données, les analystes commerciaux et les opérateurs de produits, elles peuvent créer des étiquettes basées sur des règles grâce à leur compréhension de l'entreprise. Ces étiquettes changeront en fonction de leur situation. compréhension de l’entreprise entraîne des changements.
- Classe Model : ce type d'étiquette nécessite que l'équipe d'algorithmes effectue des calculs complexes ou nécessite des exemples de données. Contrairement à certaines étiquettes de base, les étiquettes modèles peuvent présenter des problèmes de précision et ne peuvent pas être exactes à 100 %. Parce que parfois le nombre d’échantillons que nous obtenons est très limité, ce qui rend difficile le maintien d’un haut niveau de précision des étiquettes. Par conséquent, pour les étiquettes de classe de modèle, nous devrons peut-être trouver d’autres méthodes et techniques pour améliorer leur précision et leur convivialité.
(2) Cycle de mise à jour
En plus des cycles de mise à jour horaires, hebdomadaires et mensuels répertoriés, nous mettons actuellement également en œuvre des mises à jour d'étiquettes en temps réel, ce qui est plus proche des mises à jour en continu.
(3) Méthode d'accès
Étant donné que la plateforme d'étiquetage de portraits doit traiter une grande quantité de données et de demandes d'utilisateurs, il est nécessaire de choisir la méthode d'accès appropriée en fonction de la pile technologique d'arrière-plan pour certaines grandes entreprises. , le nombre d'utilisateurs et le volume de données sont très importants, nous devons donc réfléchir à la manière de stocker et de rappeler efficacement les balises. Certaines balises devront peut-être uniquement être créées hors ligne, tandis que d'autres devront peut-être être appelées en ligne. Pour les balises hors ligne, nous pouvons choisir des ressources qui n'occupent pas des coûts de stockage élevés, comme le stockage de données dans Redis ou HBase. Pour les balises en ligne, il est nécessaire de garantir que le système peut répondre rapidement aux demandes des utilisateurs et fournir des services stables. Par conséquent, lors du choix d'une méthode d'accès, nous devons faire des compromis et des choix en fonction de la situation réelle pour garantir les performances et la stabilité du système.
4. Le processus de construction du système d'étiquettes portrait
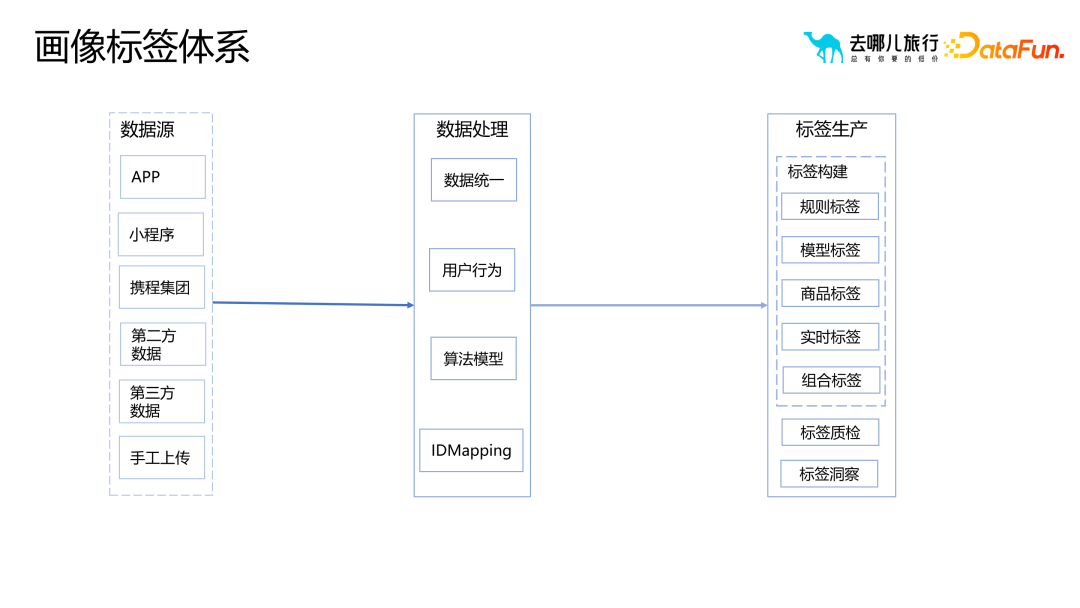
Dans le processus de production du système d'étiquettes portrait, nous devons effectuer une série de traitements sur diverses sources de données pour finalement générer des étiquettes. Parmi eux, ID Mapping constitue un maillon clé. L'objectif de l'ID Mapping est de résoudre le problème des différents identifiants pointant vers la même personne, en particulier pour les entreprises en démarrage. En raison des différentes méthodes d'enregistrement, plusieurs identifiants peuvent correspondre au même utilisateur. Par exemple, les utilisateurs peuvent lier ou modifier leur numéro de téléphone mobile après s'être inscrits par e-mail, ou ils ont été autorisés à l'utiliser sans se connecter. Ces situations peuvent entraîner plusieurs identifiants correspondant au même utilisateur.
Afin de résoudre ce problème, ID Mapping se charge de réaliser une association multi-appareils. En outre, l’ID Mapping constitue également une étape fondamentale cruciale pour le contrôle des risques. Grâce au mappage d'identité, les utilisateurs de différents appareils peuvent être mieux identifiés et associés, permettant un meilleur contrôle des risques et une meilleure gestion de la sécurité. Grâce à une conception et une gestion raisonnables du mappage d'identité, nous pouvons mieux protéger la confidentialité des utilisateurs et la sécurité des données, tout en améliorant la précision et la fiabilité du système d'étiquetage des portraits.
2. Plateforme de marquage d'images
La plate-forme de marquage d'images est également appelée plate-forme CDP, qui comprend la production de balises d'image, l'analyse de données, les applications métiers, l'analyse des effets et d'autres services. La figure ci-dessous montre l'architecture fonctionnelle de la plateforme Qunar CDP.
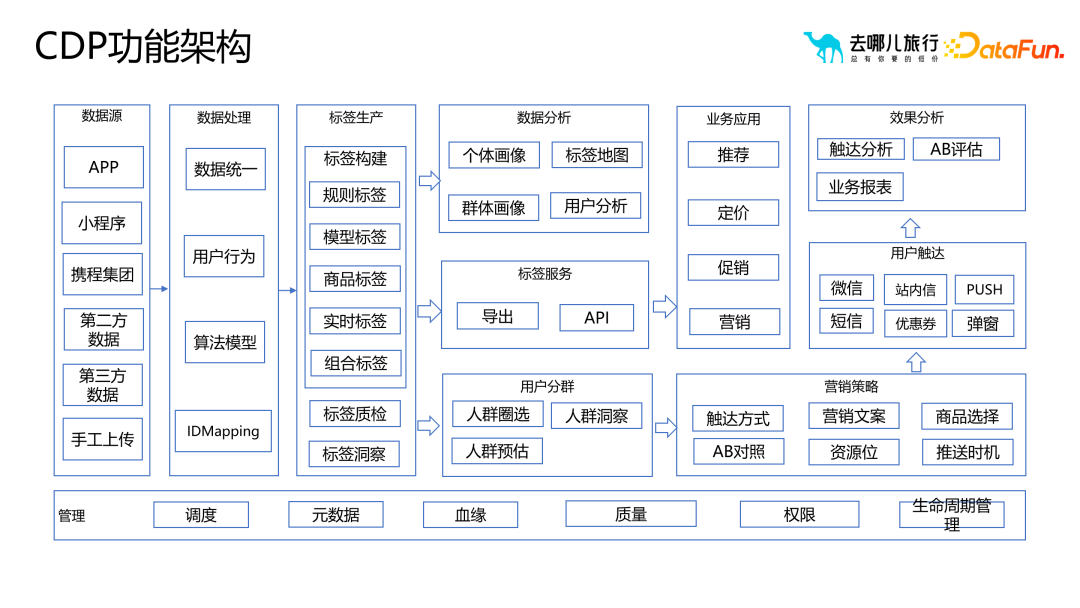
Chez Qunar.com, après l'épidémie, nous avons renforcé la construction de capacités internes et intégré des balises d'image aux plateformes stratégiques traditionnelles. Actuellement, la plate-forme couvre tout le cycle de vie des balises de portrait et peut réaliser des fonctions telles que la construction de portraits, la sélection de foule et les actions marketing finales. Grâce à une telle intégration, les stratégies marketing basées sur les données peuvent être mieux mises en œuvre et les portraits d'utilisateurs et les activités marketing peuvent être connectés de manière transparente. Cela contribue à améliorer l’efficacité du marketing et la satisfaction des utilisateurs, et favorise également l’intégration des données et le travail collaboratif au sein de l’entreprise.

3. Étiquettes communes de portrait d'algorithme
1. Étiquettes de classe de modèle communes Types d'algorithmes communs
, vous pouvez Couramment utilisé les algorithmes d'étiquetage des modèles sont divisés dans les catégories suivantes :
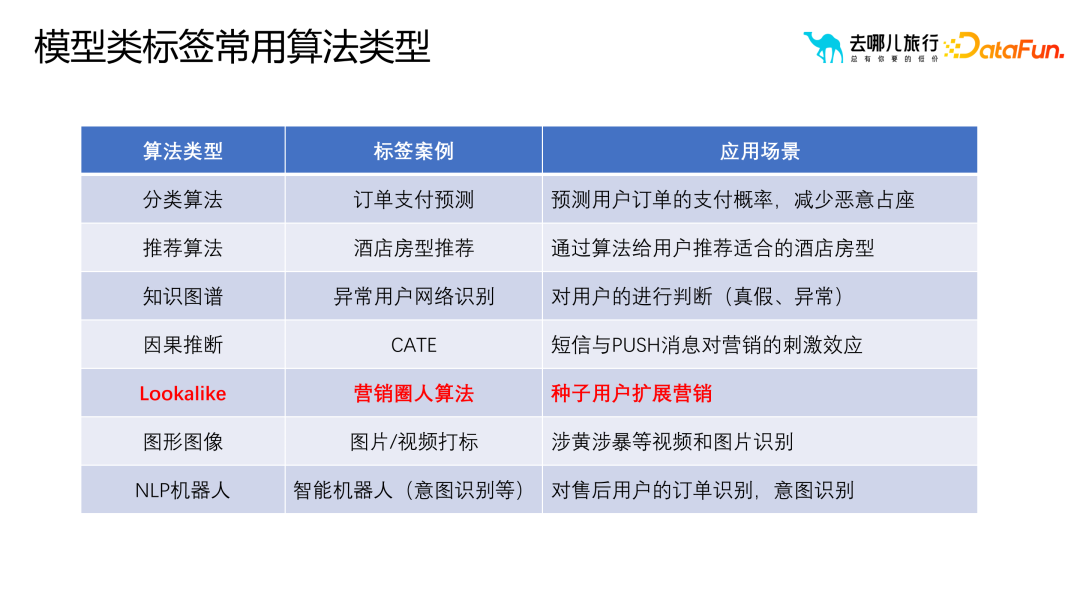
(1) Algorithme de classification : l'utilisation d'étiquettes de classe prédictives pour la sélection de cercles et le filtrage métier dans les processus métier nécessite suffisamment d'échantillons de données pour entraîner et optimiser le modèle, améliorant ainsi la précision des prédictions. Les balises de prédiction ne se limitent pas aux prédictions de paiement de commande, mais peuvent également inclure des prédictions de paiement de recherche, des prédictions de recherche, des prédictions de page détaillée, etc.
(2) Algorithme de recommandation : lié au tri et à la priorisation, nécessitant un éventail plus large de connaissances de pointe et de pile technologique. L’objectif de l’algorithme de recommandation est de recommander aux utilisateurs des types de chambres d’hôtel appropriés à partir de l’ensemble de rappel. Par exemple, pour les scénarios de voyage parent-enfant, l'algorithme de recommandation peut recommander aux utilisateurs des types de chambres d'hôtel appropriés, tels que des chambres lits jumeaux ou des suites.
(3) Graphique de connaissances : utilisez la technologie de base de données graphique pour mieux révéler les utilisateurs et leurs relations environnantes. Il existe de nombreuses applications dans les scénarios de contrôle des risques, telles que l'identification des utilisateurs anormaux et la détermination s'il s'agit d'utilisateurs malveillants.
(4) Inférence causale : un exemple est utilisé pour expliquer l'impact de l'envoi de messages texte et de messages push aux utilisateurs sur l'efficacité du marketing, et implique des problèmes de coûts.
(5) Graphiques et images : Combiner la technologie graphique et de traitement d'image pour marquer les graphiques et les images. Cela implique la segmentation d'images, la reconnaissance et d'autres technologies, mais le plus souvent, cela est appliqué à l'envers à l'étiquetage des images via des balises utilisateur. Par exemple, pour les utilisateurs qui publient des commentaires inappropriés, leurs étiquettes sont extraites et appliquées à l'algorithme d'étiquetage des images graphiques pour améliorer l'efficacité et la précision de l'étiquetage.
(6) Robot PNL
(7) algorithme de marketing sosie : un algorithme de marketing d'expansion via les utilisateurs de semences.
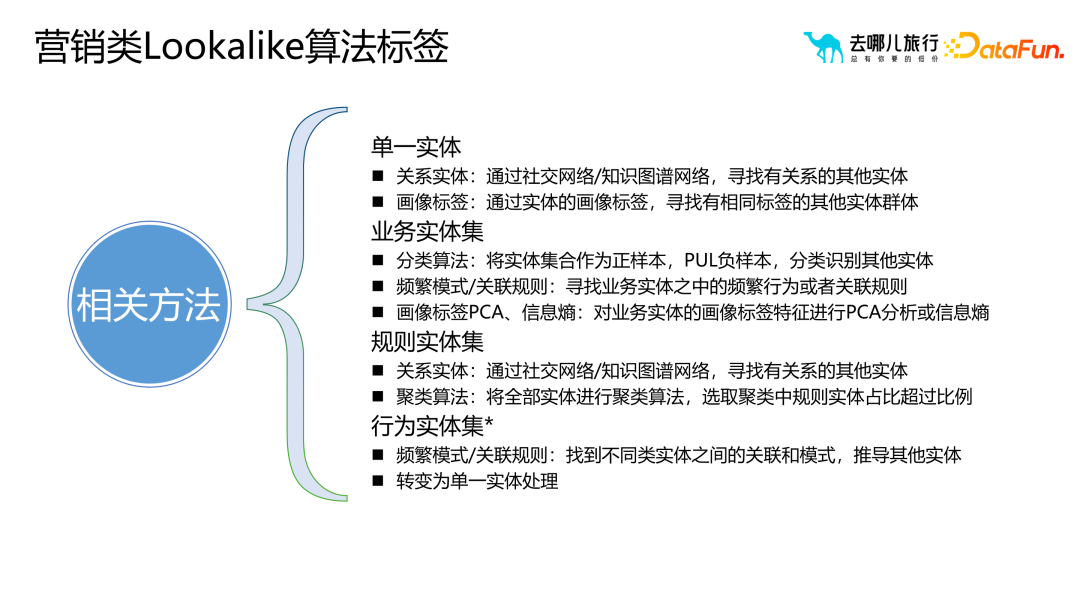
Il existera différentes méthodes de classification en fonction des types de demande :
- Entité unique : recherchez d'autres entités associées via des réseaux de relations ou des graphiques de connaissances. Par exemple, les graphes de connaissances peuvent être utilisés pour découvrir des relations entre des entités, étendant ainsi les entités associées à une seule entité.
- Ensemble d'entités commerciales : balises liées à une entreprise spécifique, générées par l'entreprise elle-même et non contrôlées par des humains. Par exemple, si vous souhaitez cibler les utilisateurs de recherche d'hôtels ou de billets d'avion pour commercialiser et développer votre entreprise, vous devez mieux comprendre les besoins et les comportements des utilisateurs grâce à une analyse approfondie et à l'exploration des balises d'entité commerciale, optimisant ainsi les stratégies commerciales et améliorant la conversion. tarifs et expérience utilisateur. L'ensemble des entités commerciales peut être étendu via des modèles de marque, des règles d'association, des plateformes d'étiquetage de solutions, etc., pour obtenir des étiquettes de portraits ou des utilisateurs de portraits plus riches.
- Ensemble d'entités de règles : fait référence aux étiquettes générées en fonction de règles ou de conditions spécifiques. Ces balises sont généralement utilisées par l'équipe produit en fonction de leur compréhension de l'entreprise et de l'utilisation d'outils de balises pour sélectionner des groupes d'utilisateurs qui répondent à des règles spécifiques. Par exemple, dans le processus de recommandation d'itinéraires ou de types de chambres, certains utilisateurs peuvent avoir acheté des billets d'avion et des hôtels à Pékin. Nous pouvons alors utiliser ces utilisateurs avec des chaînes de comportement spécifiques comme groupes cibles pour la promotion marketing. Peut être traité à l’aide d’entités relationnelles et d’algorithmes de clustering. Lors de l'exécution d'algorithmes de clustering, il est important de noter que vous ne pouvez pas utiliser uniquement des étiquettes de règles pour le clustering, mais que d'autres étiquettes doivent être utilisées. Dans le même temps, vous devez éviter de mélanger des balises fortement liées aux balises de règle avec des balises de règle. Afin d'éviter cette situation, la plateforme de balises de solution fournira une analyse de corrélation entre les balises et d'autres balises pour aider les utilisateurs à filtrer les balises similaires.
- Ensemble d'entités comportementales : balises générées en fonction du comportement de l'utilisateur. Ces balises développent des stratégies marketing correspondantes en analysant les caractéristiques comportementales et les types de demande des utilisateurs. Par exemple, pour les utilisateurs qui ont acheté des billets d'avion et des hôtels à Pékin, nous pouvons analyser plus en détail leurs caractéristiques comportementales, telles que le moment de l'achat, la fréquence, les préférences, etc., afin de développer des stratégies marketing plus ciblées.
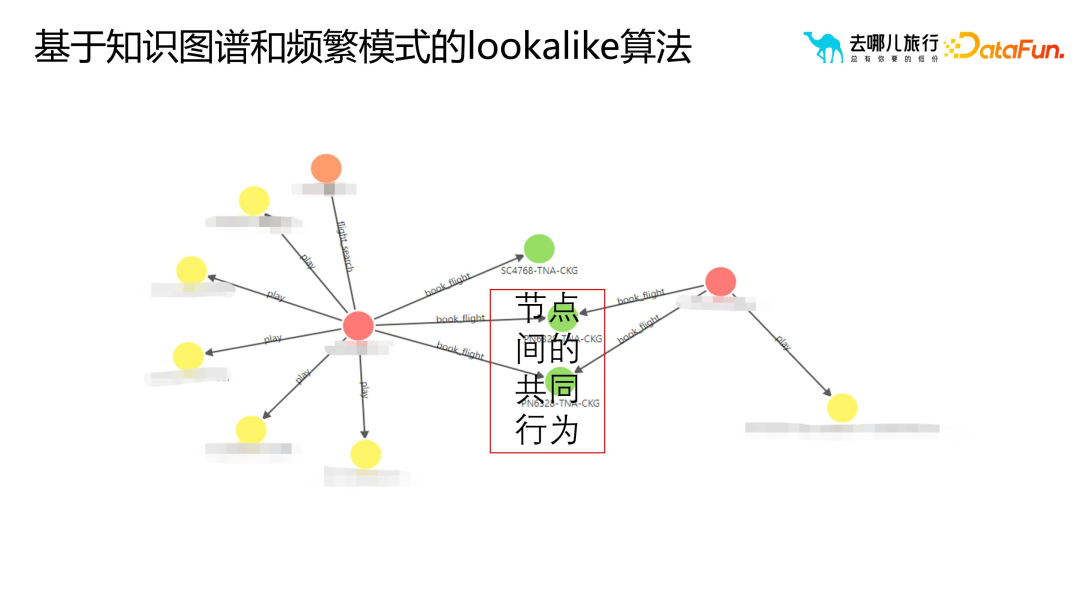
2. Algorithme Looklike basé sur un graphique de connaissances et des modèles fréquents
S'appuyer uniquement sur des balises de portrait pour le filtrage peut produire un grand nombre d'utilisateurs cibles qui ne répondent pas aux besoins. problème difficile. Les méthodes traditionnelles telles que le tri basé sur la valeur, l'activité, etc., sont difficiles à garantir que les utilisateurs sélectionnés ressemblent le plus au groupe d'utilisateurs cible. Grâce à des graphiques de connaissances ou des modèles fréquents, nous pouvons mesurer la similarité entre les utilisateurs, et cette similarité est quantifiable et évolutive. Grâce au niveau relationnel, l'algorithme peut trouver plus précisément des groupes d'utilisateurs similaires à l'utilisateur cible.
3. Algorithme de sosie basé sur l'inférence causale
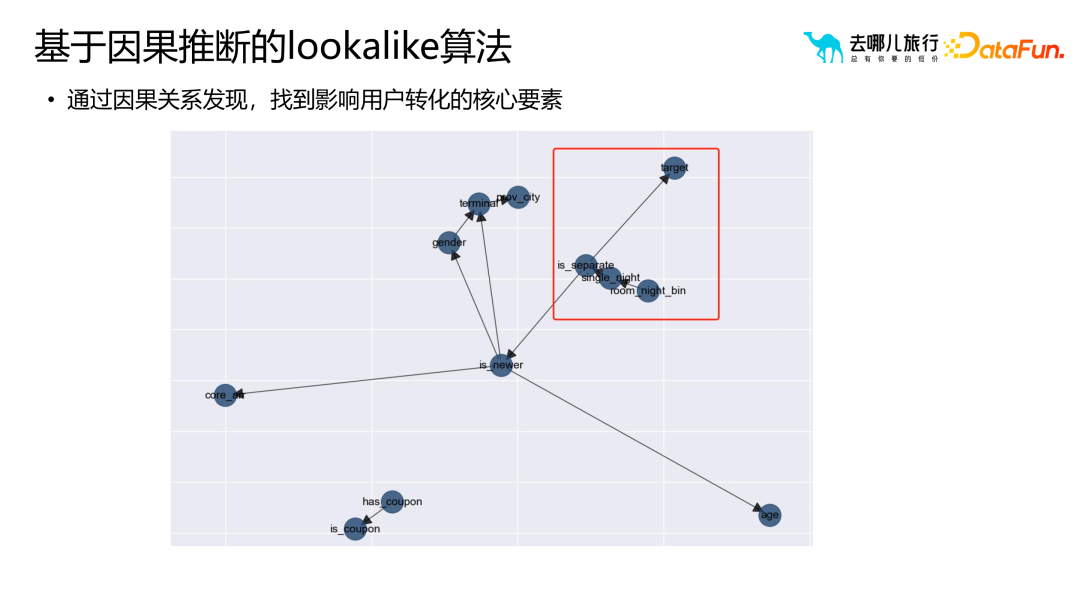
Par rapport aux règles d'association traditionnelles et aux étiquettes de portrait, l'inférence causale peut résoudre des problèmes plus profonds. Les règles d'association et les étiquettes de portrait résolvent principalement les problèmes de corrélation, tels que « les utilisateurs qui achètent de la bière peuvent également acheter des couches », mais ne peuvent pas expliquer pourquoi cette corrélation existe. Cette corrélation peut ne pas être vraie dans différentes cultures et marchés. Par conséquent, grâce à l’inférence causale à l’aide de données et de modèles historiques, les facteurs clés affectant le comportement et la conversion des utilisateurs peuvent être trouvés. Ces facteurs clés peuvent être découverts grâce à la découverte des relations, ce qui nous aide à mieux comprendre le comportement des utilisateurs et les processus métier.
Par exemple, la partie rouge dans le coin supérieur droit filtre les parties qui reflètent mieux le processus métier grâce à la compréhension de l'entreprise, afin d'élargir davantage d'utilisateurs.
4. Portrait d'objet
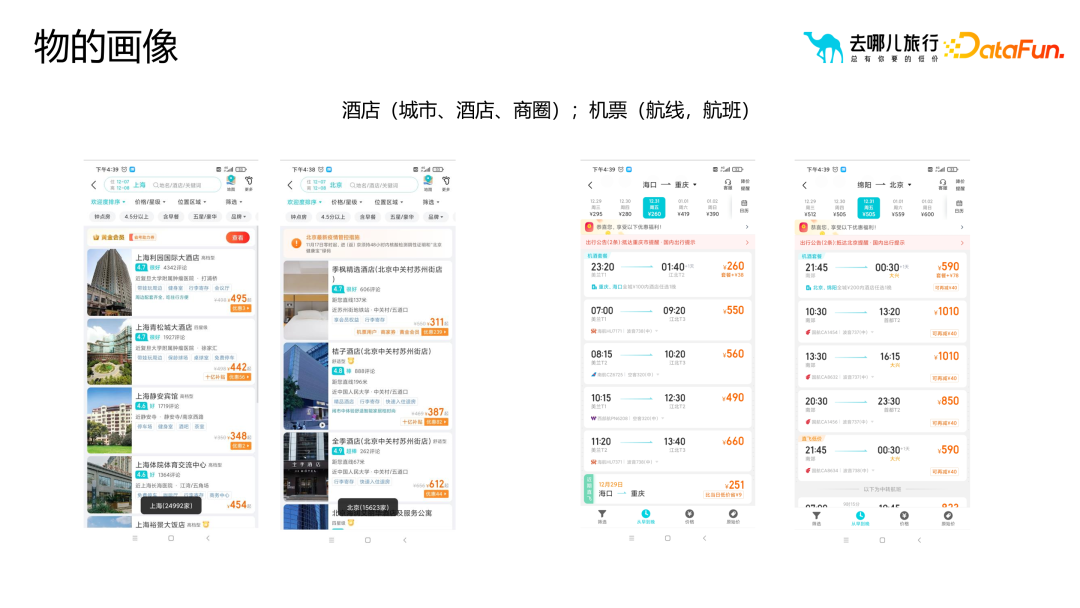
Dans le processus de construction du portrait d'objet, nous nous concentrons principalement sur les attributs et les caractéristiques de l'objet, tels que les villes, les quartiers d'affaires, les itinéraires, etc. dans le portrait de l'hôtel. Vols, etc. Ces propriétés nous aident à décrire et à comprendre les objets avec plus de précision et fournissent un contenu riche pour leurs portraits.

Comparés aux portraits d'utilisateurs, les portraits d'objets mettent l'accent sur les similitudes entre les objets. En pratique, on utilise généralement la similarité des objets pour effectuer des opérations telles que la recommandation et le classement. Afin de mesurer la similarité entre les objets, diverses méthodes peuvent être utilisées, telles que les vecteurs d'attributs et l'intégration. Ces méthodes peuvent représenter des objets sous forme de vecteurs et utiliser ces vecteurs pour effectuer des calculs de similarité. Il convient de noter que bien que le processus de création de portraits d'objets soit similaire au processus de création de portraits d'utilisateurs, dans les applications réelles, nous devons procéder aux ajustements et aux optimisations appropriés en fonction des besoins et des scénarios de l'entreprise. Dans le même temps, il est également nécessaire de procéder à une analyse approfondie des relations et des structures hiérarchiques entre les objets pour garantir que les portraits d'objets reflètent fidèlement les besoins de l'entreprise.
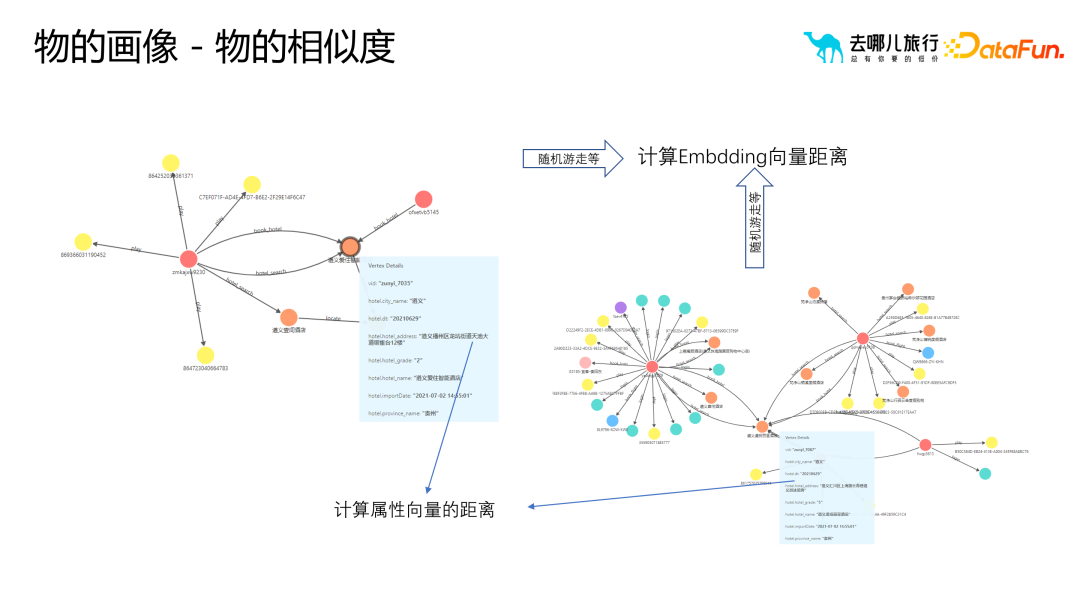
De plus, dans le processus de construction de l'image de l'objet, nous devons également prêter attention à certaines questions clés.
(1) Semblable ne veut pas dire similaire. Par exemple, lors de l'utilisation de la méthode d'intégration, si un groupe d'utilisateurs de grande valeur recherche des hôtels cinq étoiles, la corrélation entre ces hôtels cinq étoiles peut être forte. Mais dans certains scénarios économiques, cette corrélation peut ne pas s’appliquer. Par conséquent, nous devons examiner attentivement la similitude des objets en fonction de scénarios commerciaux spécifiques.
(2) Problème de démarrage à froid. Par exemple, dans le profilage d'hôtel, lorsqu'un nouvel hôtel est mis en ligne, il peut manquer de données sur le comportement des utilisateurs. Afin de résoudre ce problème, nous pouvons utiliser la distance des attributs pour extraire les attributs d'étiquettes de grande dimension, construire une étiquette de portrait conviviale et utiliser cette étiquette pour effectuer des calculs de similarité. (3) Interprétabilité
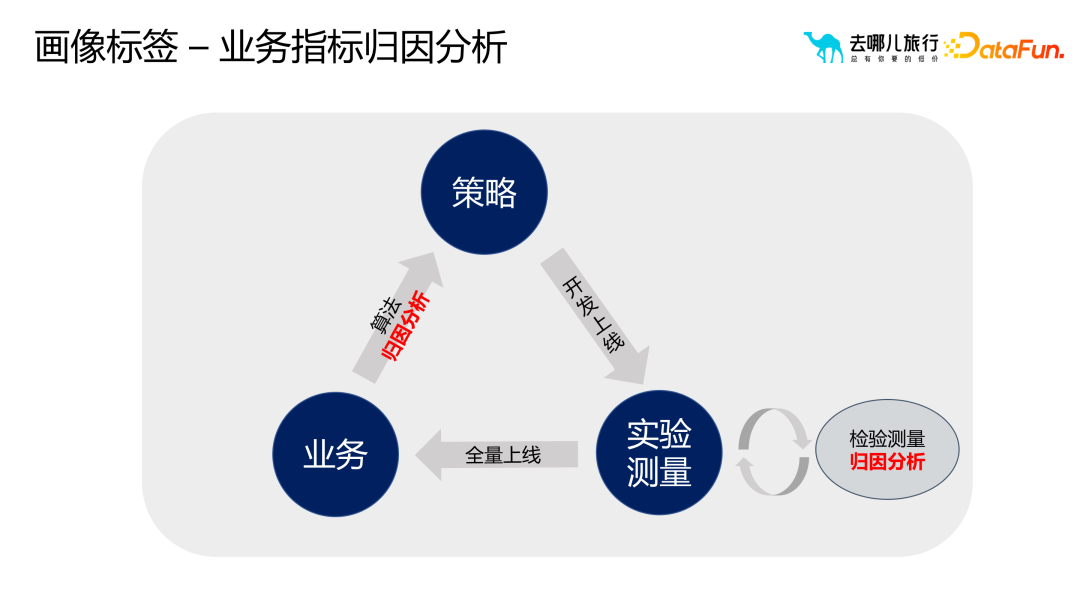
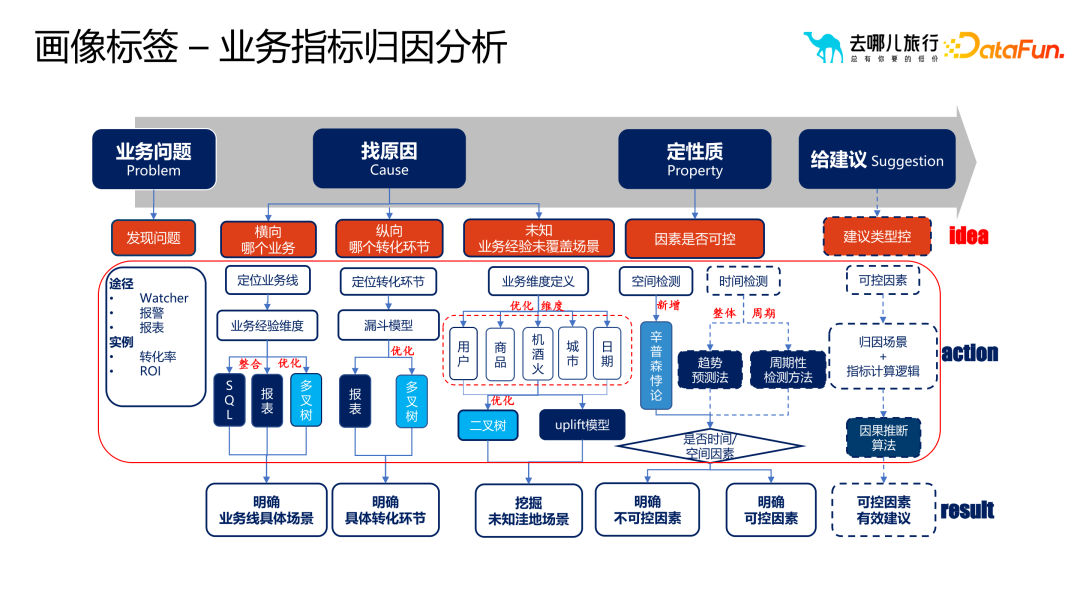
Portrait Tags joue un rôle vital rôle dans le processus de sélection et de diffusion du marketing. En utilisant rationnellement les balises portrait, les opérateurs peuvent effectuer une analyse et un filtrage plus détaillés des groupes d'utilisateurs sélectionnés. Lorsque les opérateurs estiment que les groupes d'utilisateurs initialement sélectionnés sont trop grands ou trop petits, ou que l'effet marketing doit être étendu ou optimisé davantage. être diffusés ou resélectionnés via des tags de portrait pour obtenir de meilleurs résultats marketing. Cependant, lors de la sélection et de la diffusion des balises de portrait, les problèmes les plus courants sont les quatre quadrants de la conversion des utilisateurs et de l'intervention opérationnelle. Ces quatre quadrants représentent respectivement différents états de conversion des utilisateurs et stratégies d'intervention opérationnelle, qui nécessitent des réponses différentes à différentes situations. Par exemple, pour les utilisateurs avec une conversion élevée et une faible intervention, vous pouvez adopter des stratégies pour maintenir le statu quo ; pour les utilisateurs avec une faible conversion et une faible intervention, vous pouvez adopter des stratégies pour promouvoir la conversion, etc. Voici les quatre étapes de sélection marketing et de diffusion des balises de portrait dans le processus de candidature : Analyse scientifique : Explorez en profondeur les données des utilisateurs et localisez avec précision les groupes cibles pour améliorer les effets de conversion. Sélection du cercle auxiliaire : Utilisez des balises pour filtrer efficacement les utilisateurs cibles et améliorer la pertinence et l'efficacité des activités marketing. Expansion intelligente : Sur la base d'algorithmes et de modèles, les groupes d'utilisateurs sont intelligemment classés et élargis pour étendre la couverture marketing. Mise en œuvre du modèle : En combinaison avec des activités marketing réelles, optimisez les balises d'image et les stratégies pour obtenir les meilleurs résultats marketing. Utilisez le système de balises portrait pour analyser la qualité des indicateurs commerciaux et optimiser davantage les stratégies. Au cours du processus d'itération commerciale, nous utilisons généralement des méthodes telles que des algorithmes d'analyse d'attribution et l'analyse commerciale pour générer des stratégies. Effectuez ensuite des mesures expérimentales. Si la stratégie expérimentale fonctionne bien, elle sera pleinement lancée. Cependant, deux problèmes seront rencontrés dans ce processus : comment analyser la qualité des indicateurs et la qualité des résultats expérimentaux. Afin de résoudre ces problèmes, nous devons effectuer une analyse d’attribution des indicateurs commerciaux. Tout d'abord, découvrez les problèmes commerciaux au moyen de rapports, d'alarmes, etc., découvrez les causes des problèmes et clarifiez des scénarios spécifiques et des relations de transformation réelles. Ensuite, localisez la cause du problème et déterminez si la cause est contrôlable ou incontrôlable. S'il est incontrôlable, il peut s'agir d'une gigue naturelle et ne nécessite pas trop d'attention ; s'il est contrôlable, il est nécessaire d'explorer davantage s'il existe des scénarios inconnus à l'origine de ce problème. Dans le module d'analyse qualitative, nous clarifierons les facteurs contrôlables et incontrôlables et explorerons les causes des problèmes dans certains scénarios inconnus. Enfin, des suggestions sont données pour guider le personnel de l'entreprise dans les scénarios à suivre. Ce scénario signifie en fait que le taux de conversion d'une certaine entreprise a chuté. Grâce au processus d'analyse de l'ensemble de l'entreprise, nous pouvons déterminer la proportion de facteurs non marchands et de facteurs contrôlables. Si les facteurs du marché représentent une part importante, nous pouvons alors résoudre le problème plus tard sans utiliser immédiatement beaucoup de ressources humaines et matérielles. Dans le processus d'être responsable du système d'expérimentation AB de Qunar, nous sommes souvent confrontés à certains défis. Lorsque l'équipe produit investit beaucoup de temps et de ressources pour réaliser des expériences, si les résultats expérimentaux ne sont pas significatifs, il est facile de se poser des questions telles que « Pourquoi l'expérience est-elle invalide » et « Quelle est la direction de la prochaine itération ? Afin de résoudre ces problèmes, nous avons effectué une analyse des performances expérimentales AB, qui était principalement divisée en trois parties. Tout d’abord, nous avons essayé de déterminer si les mauvais résultats expérimentaux étaient dus à une amélioration insuffisante du volume grâce au modèle d’entonnoir de processus métier, à l’identification des étiquettes de portrait d’utilisateur principal et à l’identification d’étiquettes trompeuses du domaine commercial. Deuxièmement, utilisez des méthodes d'analyse telles que des arbres de décision pour déterminer s'il existe des problèmes avec l'amélioration qualitative, tels que des conflits dans d'autres expériences ou des situations dans lesquelles l'amélioration n'atteint pas une proportion significative. Enfin, quantifiez l’efficacité de l’action et clarifiez l’impact de chaque action sur l’objectif. Grâce à ces processus d'analyse, nous pouvons fournir des conseils spécifiques à l'équipe produit pour l'aider à choisir des directions d'optimisation plus efficaces, obtenant ainsi une amélioration qualitative. Ces analyses permettent non seulement d'optimiser les directions d'itération des produits, mais également d'économiser des ressources et du temps pour l'entreprise et d'améliorer les résultats commerciaux globaux.
A1 : Les données sur le comportement des utilisateurs enregistrent principalement les comportements interactifs des utilisateurs côté APP, tels que les clics, etc. Ces données reflètent principalement le processus d'interaction de l'utilisateur. Les données métiers impliquent diverses informations traitées en arrière-plan, telles que les processus de connexion des agents, les informations logistiques, etc. Bien que ces données soient invisibles pour les utilisateurs, elles sont également cruciales pour comprendre l'ensemble du processus métier et améliorer l'expérience utilisateur. En fonctionnement réel, nous devons intégrer ces données dans notre système de balises de portrait pour mieux analyser et comprendre le comportement des utilisateurs et les processus commerciaux. Par exemple, pour les plateformes de commerce électronique, certaines données peuvent ne pas être pertinentes pour les utilisateurs, mais d’autres impliquent l’expérience utilisateur et les processus commerciaux, ce qui nécessite un contrôle et un traitement appropriés. A2 : Les balises de streaming peuvent être implémentées via le streaming informatique, par exemple en utilisant des outils tels que Flink. Les utilisateurs peuvent glisser et déposer des données définies pour calculer des étiquettes via des calculs en continu. Dans le même temps, vous pouvez également télécharger du code Python ou du code SQL pour des calculs personnalisés. De plus, il peut également être pris en charge via Spark et d’autres méthodes. Dans les balises de streaming, la quantité et la fenêtre temporelle des calculs doivent être limitées pour répondre à différents besoins. Les balises de streaming peuvent prendre en charge des règles de balises complexes. Les utilisateurs peuvent implémenter des calculs d'étiquettes plus complexes en téléchargeant du code Python ou du code SQL. Les balises de streaming peuvent être implémentées de deux manières : le développement de données et la configuration visuelle. Sur la plateforme Qunar, les utilisateurs peuvent glisser et déposer des données définies pour calculer des étiquettes via le streaming informatique, ou télécharger du code Python ou du code SQL pour des calculs personnalisés. A3 : Les balises en temps réel font référence aux balises qui sont calculées et appliquées en temps réel lorsque le comportement de l'utilisateur ou des événements commerciaux se produisent. Par exemple, lorsqu'un utilisateur soumet une réclamation sur l'interface frontale, le système analysera les demandes de l'utilisateur et les problèmes de commande en temps réel, et attribuera à l'utilisateur les étiquettes correspondantes en temps réel. Ce type d'étiquetage en temps réel peut refléter rapidement les besoins et les problèmes des utilisateurs pour un traitement et une optimisation en temps opportun. Différentes entreprises ont des définitions différentes des balises en temps réel. Pour Qunar, tout ce qui se déroule dans les 3 secondes est considéré comme du temps réel, tandis que les heures sont considérées comme un scénario non temps réel. A4 : Avec la popularité de l'Internet mobile, plus ? et de plus en plus d'entreprises commencent à utiliser le numéro de téléphone mobile comme identifiant unique de l'utilisateur. La connexion en un clic est devenue une pratique courante dans l'industrie, ce qui permet aux utilisateurs de se connecter et d'utiliser les applications plus facilement. Pour les plateformes comme Qunar, nous utilisons également les numéros de téléphone mobile comme identifiants d'utilisateur uniques. Dans la plupart des cas, nous traitons un numéro de téléphone mobile comme un identifiant unique pour un utilisateur. Cependant, dans certains cas particuliers, nous considérerons également le scénario dans lequel l'utilisateur modifie son numéro de téléphone mobile et le gérerons en conséquence. De plus, afin de mieux gérer et identifier les utilisateurs, lorsqu'un numéro de téléphone mobile est connecté sur deux appareils, nous utiliserons une série de jugements pour déterminer l'état de détention de l'utilisateur sur l'appareil. Si l'utilisateur se connecte temporairement à l'appareil, nous le considérons comme l'accesseur ; si l'utilisateur détient l'appareil pendant une longue période, il est considéré comme le titulaire. A5 : Le plus courant est le prix des produits. Afin de personnaliser les prix des produits, nous devons utiliser des balises de produits. Ces labels sont calculés sur la base de valeurs spécifiques de facteurs internes et externes. Si les facteurs internes ne sont pas correctement triés, l’impact des facteurs externes peut être exagéré. Cela peut être compris comme similaire à la méthode de résolution par force brute. Nous intégrons chaque facteur et l'essayons, puis voyons quelle influence chaque facteur a sur lui, et jugeons s'il s'agit d'une corrélation ou d'un lien de causalité dans chaque facteur. A6 : Une fois les balises en temps réel créées, nous avons fait de notre mieux pour épuiser certaines balises en temps réel qui peuvent être obtenues grâce à des statistiques de base jusqu'au niveau de développement. Quant aux tags temps réel comme les règles et les modèles, ils doivent être personnalisés et développés. A7 : Au début de l'implantation, il y aura quelques tags à usage unique qui ne serviront plus après utilisation. A8 : Pour les petites entreprises, le trafic peut ne pas être suffisamment congénital. Si vous souhaitez atteindre une taille d'échantillon minimale, cela n'est pas possible au niveau opérationnel, nous en avons donc besoin lorsque la taille minimale de l'échantillon n'est pas atteinte. .Peut déduire rapidement et grossièrement l'effet expérimental. A9 : Montrer que chaque entreprise est différente. Du point de vue du stockage, Qunar dispose de plusieurs méthodes de stockage. Nous pouvons tolérer le stockage redondant de certaines données, principalement pour une réponse rapide en temps réel, c'est-à-dire que lors de l'accès aux balises, nous faisons de notre mieux pour en utiliser une qui prend peu de temps pour y accéder. A10 : En fait, grâce à ma pratique actuelle chez Qunar, les grands modèles sont largement utilisés dans l'étiquetage des algorithmes. Tout d'abord, l'exemple le plus simple. Lorsque nous construisons des portraits d'utilisateurs, nous rencontrons souvent des données de points d'intérêt. Les données de points d'intérêt sont extraites de certains documents. La précision de cet endroit est bien meilleure que celle de certains documents. modèles que nous avons nous-mêmes construits dans le passé. Et lorsque nous construisons un graphe de connaissances, nous rencontrerons une certaine désambiguïsation d'entités, une fusion d'entités, etc. A11 : En fait non, cette recommandation est destinée à recommander des ingénieurs, mais l'algorithme de recommandation doit utiliser les résultats de l'ingénieur portrait. L'ingénieur portrait doit donc décrire clairement la qualité de l'étiquette portrait et le scénario de l'application. que l'ingénieur de classement des recommandations peut mieux utiliser. 
Application 2 : Analyse d'attribution des indicateurs commerciaux
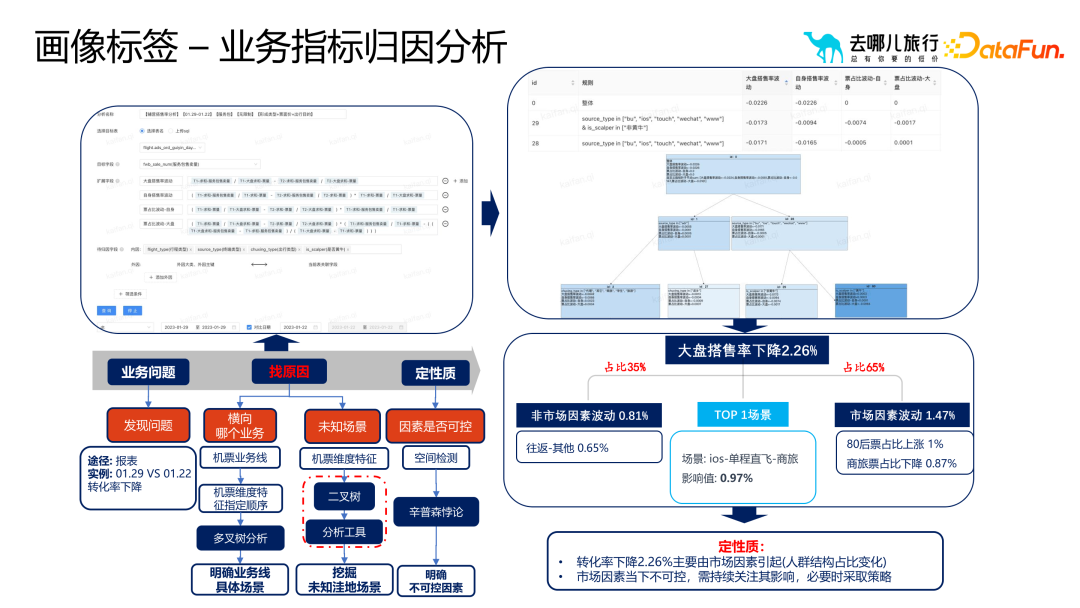
Application 3 : Analyse des performances de l'expérience AB

5. Session de questions et réponses
Q1 : Quelle est la différence entre le comportement des utilisateurs et les journaux d'entreprise ?
Q2 : Comment se fait actuellement l'étiquetage du streaming ? Peut-il prendre en charge des règles de balises plus complexes ? Est-il développé à partir de données ou configuré visuellement ?
Q3 : Qu'est-ce que les balises en temps réel ?
Q4 : L'ID Mapping identifie-t-il plusieurs numéros de téléphone mobile/numéros d'appareil dans un identifiant unique ou chaque utilisateur a-t-il un identifiant unique ? Par exemple, un numéro de téléphone mobile a été connecté sur deux appareils, et l'un des appareils s'est connecté à un autre numéro de téléphone mobile. Est-ce le seul ou trois
Q5 : Quels sont les scénarios d'application des étiquettes de produits ?
Q6 : Les étiquettes commerciales en temps réel doivent-elles être personnalisées et développées ?
Q7 : Comment gérer le cycle de vie des tags ?
Q8 : Certaines méthodes statistiques peuvent-elles être utilisées pour déterminer la taille minimale de l'échantillon pour les expériences AB ? Il existe un processus de calcul standard pour l’expérience AB. Pouvons-nous connaître la taille approximative de l’échantillon requise pour obtenir un effet statistiquement significatif ?
Q9 : Comment les types de calibre des portraits de calibre utilisateur sont-ils stockés et affichés ? En plus des balises uniques, les portraits d'utilisateurs comportent également plusieurs balises pour former une perspective de préférences utilisateur. Comment mieux stocker ces deux types de tags ?
Q10 : Quelles sont les applications des modèles dans la construction d'étiquettes de solutions ?
Q11 : Les ingénieurs en algorithmes de profilage doivent-ils également mettre en œuvre des recommandations de classement ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Implémentation et application de l'algorithme de réseau neuronal (BP) Python
- Quels sont les cinq algorithmes les plus couramment utilisés ?
- Quel est l'algorithme de signature numérique actuellement couramment utilisé ?
- Qu'est-ce qu'un algorithme bien connu pour éviter les impasses ?
- Quels sont les algorithmes de planification de disque ?