
Maison >Périphériques technologiques >IA >Un article résumant l'application du modèle de diffusion dans les séries chronologiques
Un article résumant l'application du modèle de diffusion dans les séries chronologiques

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-07 10:30:041107parcourir
Le modèle de diffusion est actuellement le module de base de l'IA générative et a été largement utilisé dans les grands modèles d'IA générative tels que Sora, DALL-E et Imagen. Parallèlement, les modèles de diffusion sont de plus en plus appliqués aux séries chronologiques. Cet article vous présente les idées de base du modèle de diffusion, ainsi que plusieurs travaux typiques du modèle de diffusion utilisé dans les séries chronologiques, pour vous aider à comprendre les principes d'application du modèle de diffusion dans les séries chronologiques.

1.Idée de modélisation du modèle de diffusion
Le cœur du modèle génératif est de pouvoir échantillonner un point à partir d'une distribution simple aléatoire et de mapper ce point à une image de l'espace cible via une série de transformations ou sur un échantillon. Le modèle de diffusion supprime continuellement le bruit au niveau des points d'échantillonnage échantillonnés et génère les données finales à travers plusieurs étapes de suppression du bruit. Ce processus est très similaire au processus de sculpture. Le bruit échantillonné à partir de la distribution gaussienne est la matière première initiale. Le processus d'élimination du bruit consiste à éliminer constamment les parties excédentaires de ce matériau.
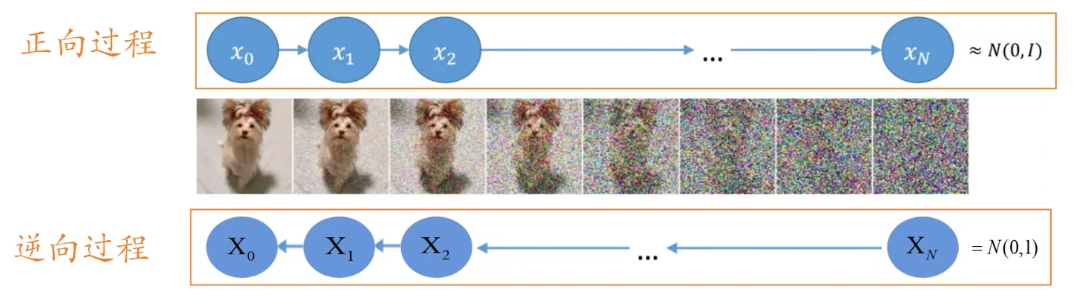
Ce qui est mentionné ci-dessus est le processus inverse, c'est-à-dire supprimer progressivement le bruit d'un bruit pour obtenir une image. Ce processus est un processus itératif, qui nécessite T temps de débruitage pour éliminer petit à petit le bruit des points d'échantillonnage d'origine. À chaque étape, le résultat généré par l'étape précédente est entré et le bruit doit être prédit, puis le bruit est soustrait de l'entrée pour obtenir la sortie du pas de temps actuel.
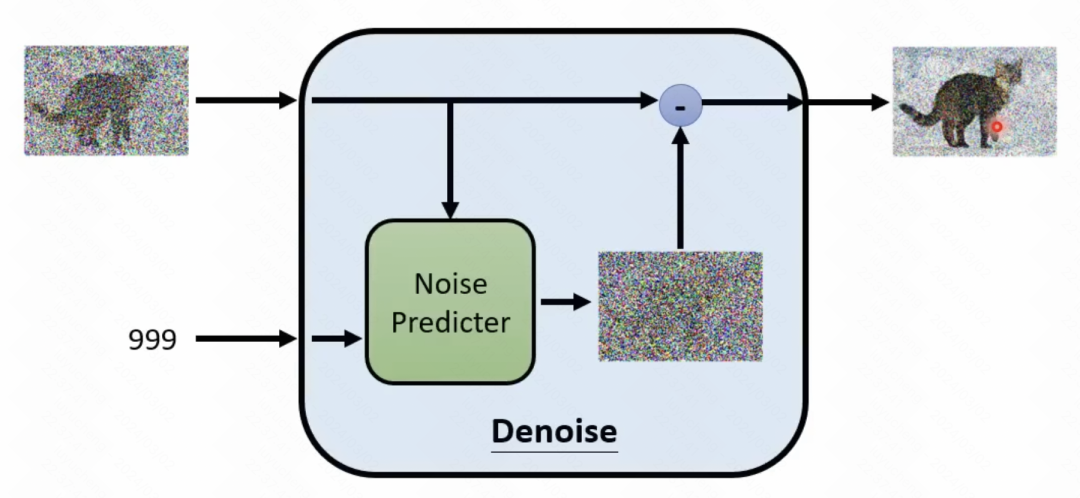
Ici, vous devez former un module (module de débruitage) qui prédit le bruit de l'étape actuelle. Ce module saisit l'étape actuelle t, ainsi que l'entrée de l'étape actuelle, et prédit quel est le bruit. Ce module de prédiction du bruit est réalisé via un processus direct, similaire à la partie Encodeur de VAE. Dans le processus direct, une image est entrée, un bruit est échantillonné à chaque étape et le bruit est ajouté à l'image originale pour obtenir le résultat généré. Ensuite, les résultats générés et l'intégration de l'étape actuelle t sont utilisés comme entrée pour prédire le bruit généré, remplissant ainsi le rôle de formation du module de débruitage.
2.Application du modèle de diffusion dans les séries chronologiques
TimeGrad est le premier à utiliser le modèle de diffusion pour les séries chronologiques prévision Une des méthodes. Différent du modèle de diffusion traditionnel, TimeGrad introduit un module de débruitage basé sur le modèle de diffusion de base et fournit un état caché supplémentaire pour chaque pas de temps. Cet état caché est obtenu en codant la séquence historique et les variables externes via le modèle RNN, et est utilisé pour guider le modèle de diffusion pour générer la séquence. La logique globale est présentée dans la figure ci-dessous.
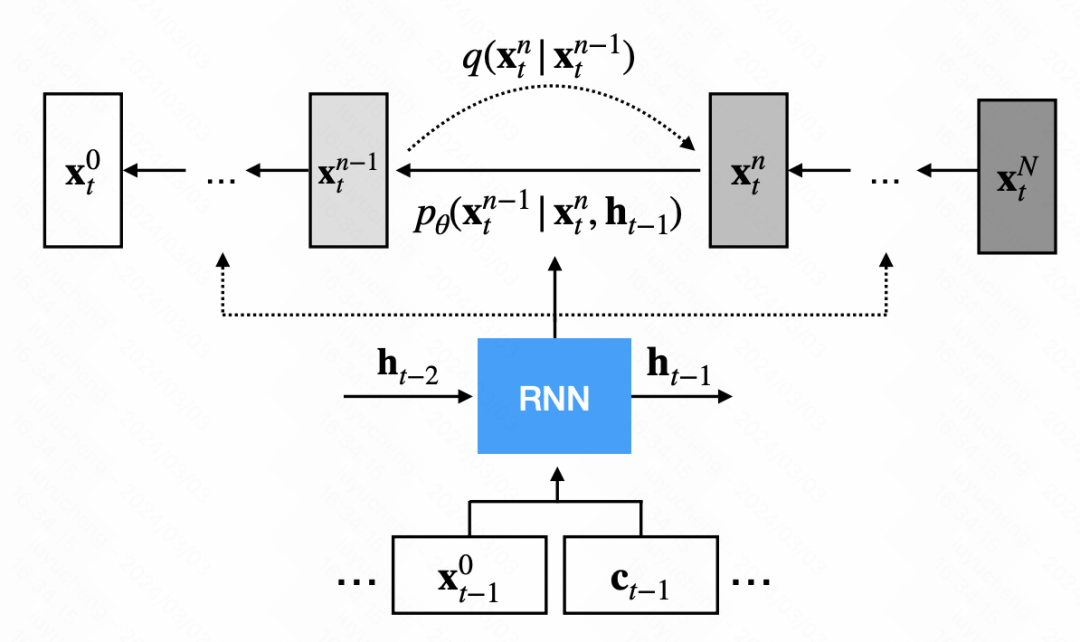
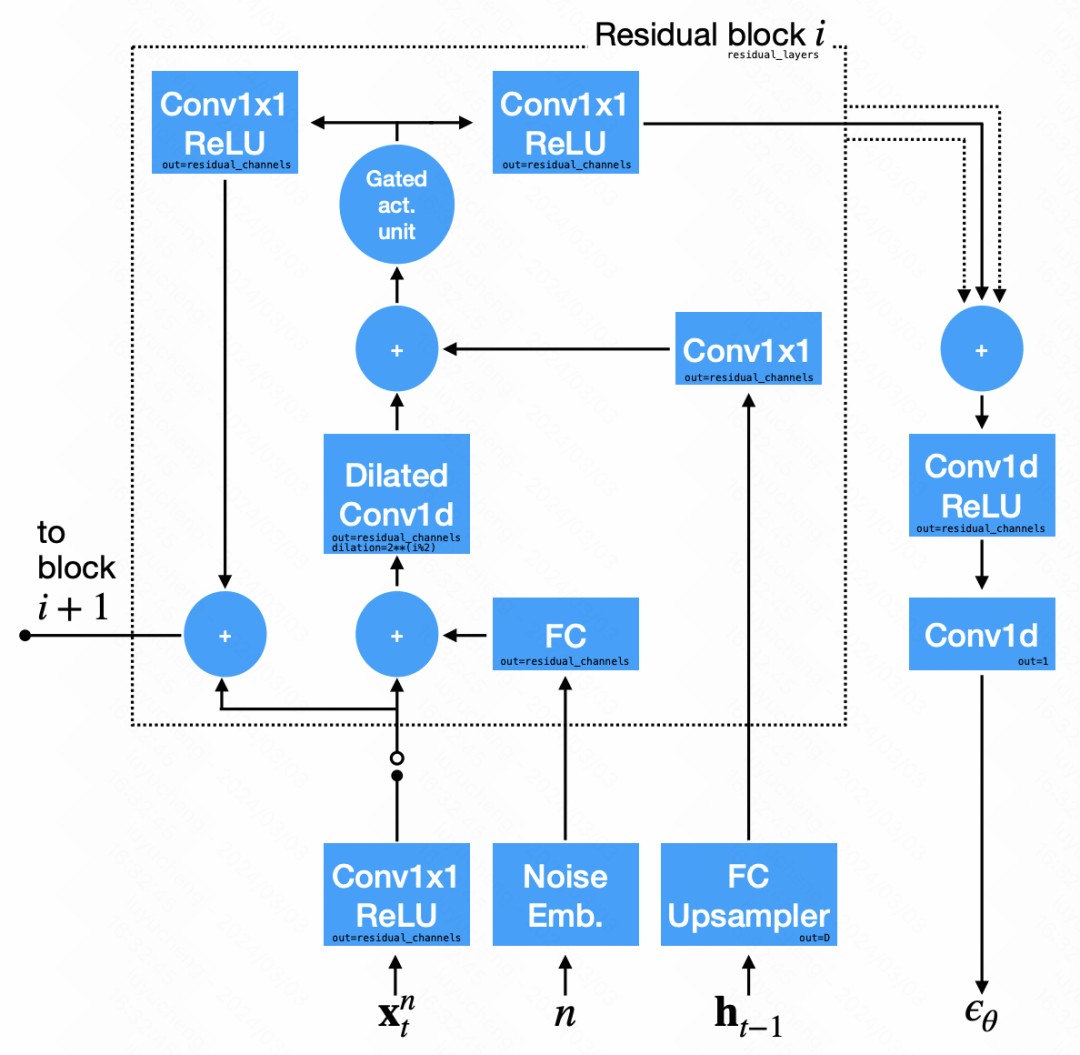
Dans la structure de réseau du module de débruitage, le réseau neuronal convolutif est principalement utilisé. Le signal d'entrée est divisé en deux parties : la première partie est la séquence de sortie de l'étape précédente, et la deuxième partie est l'état caché émis par le RNN, le résultat obtenu après suréchantillonnage. Ces deux parties sont convoluées puis additionnées pour la prédiction du bruit.
Cet article utilise le modèle de diffusion pour modéliser la tâche de remplissage de séries chronologiques. La méthode de modélisation globale est similaire à TimeGrad. Comme le montre la figure ci-dessous, la série temporelle initiale comporte des valeurs manquantes. Tout d'abord, elle est remplie de bruit, puis le modèle de diffusion est utilisé pour prédire progressivement le bruit afin d'obtenir le débruitage. Après plusieurs étapes, le résultat de remplissage est finalement obtenu.
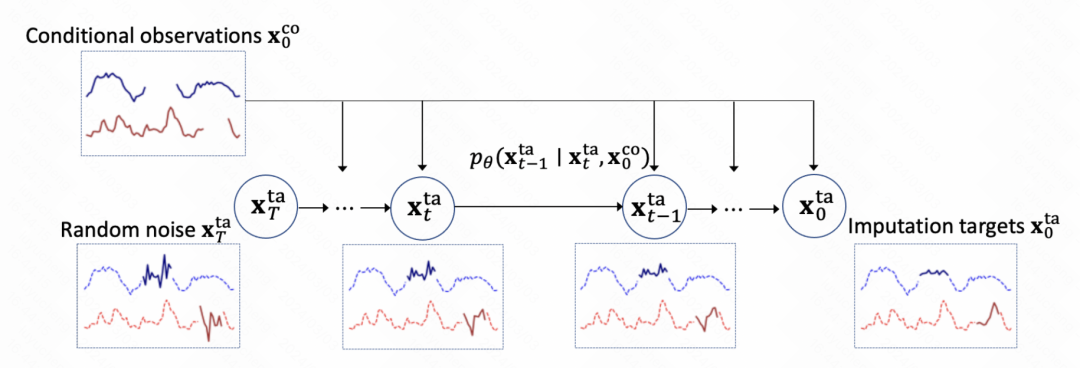
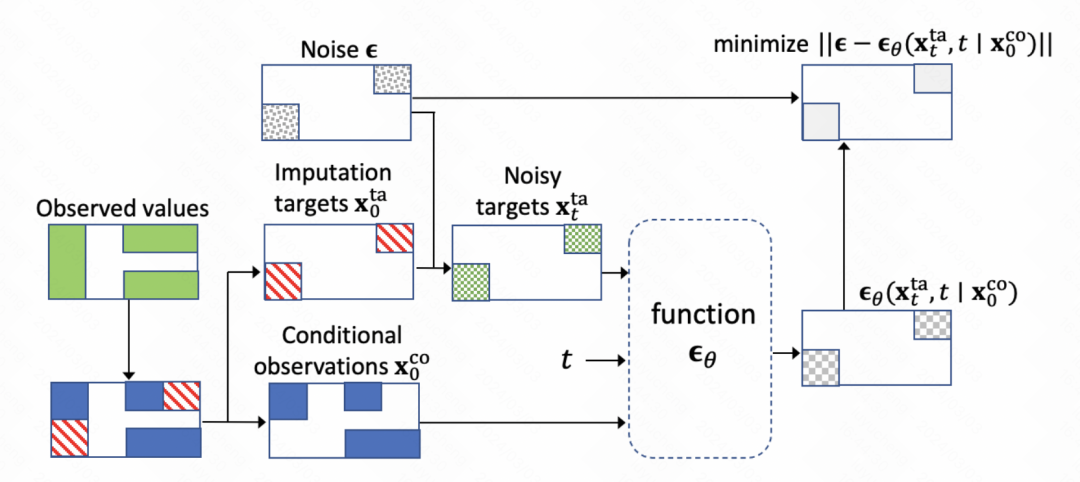
Le cœur de l'ensemble du modèle est également le module de débruitage de formation du modèle de diffusion. L'essentiel est de former le réseau de prédiction du bruit. Chaque étape saisit l'intégration de l'étape actuelle, les résultats d'observation historiques et la sortie du moment précédent pour prédire les résultats du bruit.
Le transformateur est utilisé dans la structure du réseau, comprenant deux parties : Transformateur en dimension temporelle et Transformateur en dimension variable.

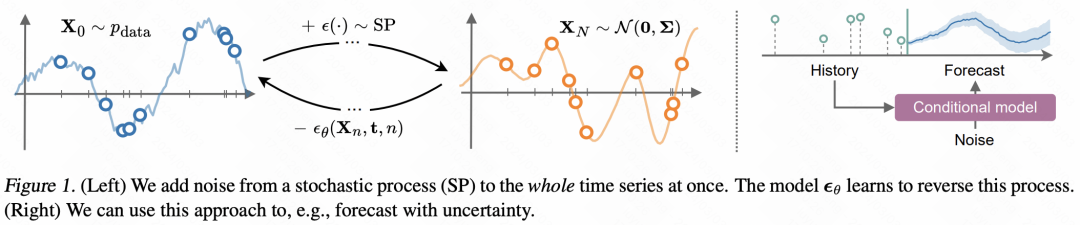
La méthode proposée dans cet article a augmenté d'un niveau par rapport à TimeGrad. Elle modélise directement la fonction elle-même qui génère le temps. séries à travers le modèle de diffusion. On suppose ici que chaque point d'observation est généré à partir d'une fonction, puis la distribution de cette fonction est directement modélisée au lieu de modéliser la distribution des points de données dans la série chronologique. Par conséquent, cet article modifie le bruit indépendant ajouté dans le modèle de diffusion en bruit qui change avec le temps, et entraîne le module de débruitage dans le modèle de diffusion pour débruiter la fonction.
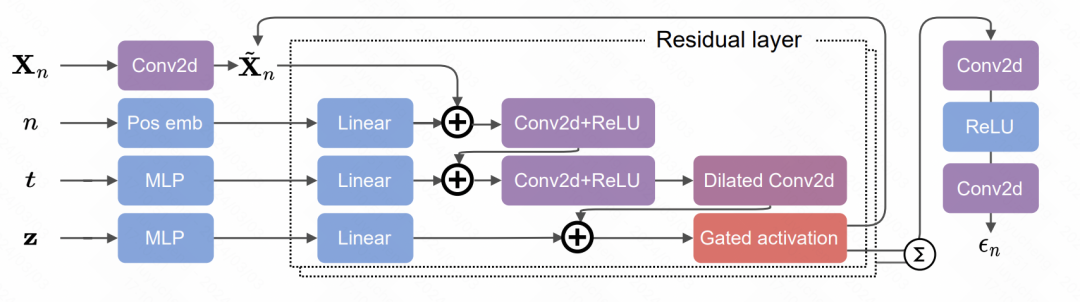
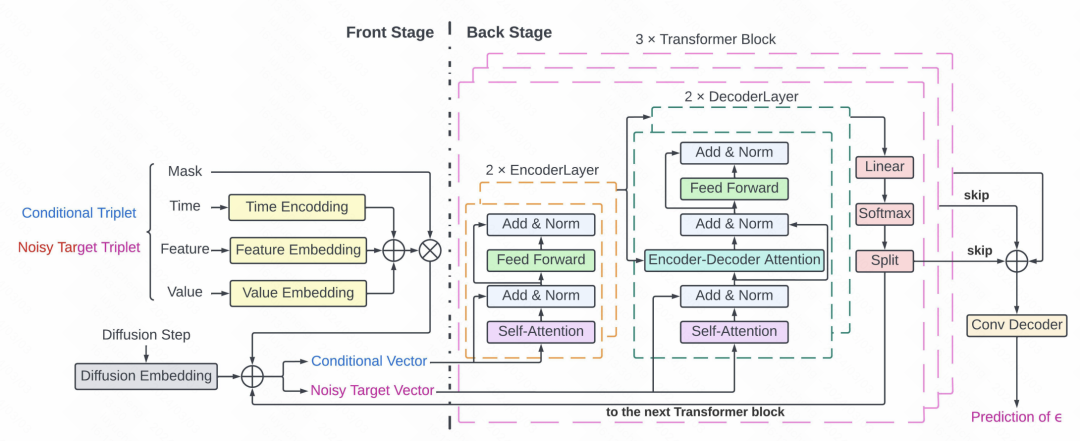
Cet article applique le modèle de diffusion à l'extraction de signaux clés en soins intensifs. Le cœur de cet article est d'une part le traitement de données de séries chronologiques médicales clairsemées et irrégulières, en utilisant des triplets de valeur, de caractéristique et de temps pour représenter chaque point de la séquence, et en utilisant un masque pour la partie valeur réelle. D’autre part, il existe des méthodes de prédiction basées sur des modèles de transformateur et de diffusion. Le processus global du modèle de diffusion est illustré dans la figure. Le principe du modèle de génération d'images est similaire. Le modèle de débruitage est formé sur la base de la série chronologique historique, puis le bruit est progressivement soustrait de la séquence de bruit initiale dans la propagation vers l'avant.

La partie spécifique de prédiction du bruit du modèle de diffusion utilise la structure Transformer. Chaque point temporel se compose d'un masque et d'un triplet, qui sont entrés dans le transformateur et utilisés comme module de débruitage pour prédire le bruit. La structure détaillée comprend 3 couches de transformateur. Chaque transformateur comprend 2 couches de réseaux d'encodeur et 2 couches de réseaux de décodeur. La sortie du décodeur est connectée à l'aide du réseau résiduel et de l'entrée au décodeur à convolution pour générer des résultats de prédiction du bruit.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les classifications de l'intelligence artificielle ?
- Quel est le concept de base de l'intelligence artificielle
- Pour la première fois, vous ne vous appuyez pas sur un modèle génératif et laissez l'IA éditer des images en une seule phrase !
- Pas aussi bon que GAN ! Google, DeepMind et d'autres ont publié des articles : les modèles de diffusion sont « copiés » directement à partir de l'ensemble de formation
- Méthodes d'analyse de la diffusion du bruit dans les modèles générés