
Maison >Périphériques technologiques >IA >Détection d'images générées par l'IA à l'aide de la détection de contraste de texture
Détection d'images générées par l'IA à l'aide de la détection de contraste de texture

- 王林avant
- 2024-03-06 21:28:091138parcourir
Dans cet article, nous présenterons comment développer un modèle d'apprentissage profond pour détecter les images générées par l'intelligence artificielle.

De nombreuses méthodes d'apprentissage profond pour détecter les images générées par l'IA sont basées sur la façon dont l'image est générée ou sur les caractéristiques/sémantique de l'image. Généralement, ces modèles ne peuvent reconnaître que des objets spécifiques générés par l'IA, tels que des personnes. , Visage, voiture, etc.
Cependant, la méthode proposée dans cette étude intitulée « Contraste de texture riche et pauvre : une approche simple mais efficace pour la détection d'images générées par l'IA » surmonte ces défis et a une applicabilité plus large. Nous allons plonger dans ce document de recherche pour illustrer comment il résout efficacement les problèmes rencontrés par d’autres méthodes de détection d’images générées par l’IA.
Problème de généralisation
Lorsque nous utilisons un modèle (tel que ResNet-50) pour reconnaître des images générées par l'intelligence artificielle, le modèle apprend en fonction de la sémantique de l'image. Si nous entraînons un modèle à reconnaître les images de voitures générées par l'IA, en utilisant des images réelles et différentes images de voitures générées par l'IA pour l'entraînement, le modèle ne pourra obtenir des informations sur les voitures qu'à partir de ces données, mais pas sur d'autres objets avec précision. identification.
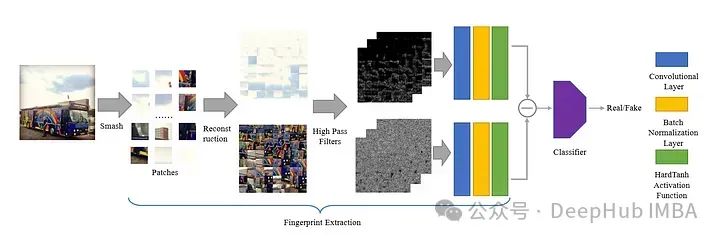
Bien que la formation puisse être effectuée sur les données de divers objets, cette méthode prend beaucoup de temps et ne peut atteindre qu'une précision d'environ 72 % sur des données inconnues. Bien que la précision puisse être améliorée en augmentant le nombre de temps d’entraînement et la quantité de données, nous ne pouvons pas obtenir des données d’entraînement illimitées. Cet article présente une méthode unique, utilisée pour empêcher le modèle d'apprendre les caractéristiques générées par l'IA à partir de la forme de l'image pendant l'entraînement. L'auteur propose une méthode appelée Smash&Reconstruction pour atteindre cet objectif.
Dans cette méthode, l'image est divisée en petits blocs de taille prédéterminée puis réorganisée pour générer une nouvelle image. Il ne s'agit que d'un bref aperçu, car des étapes supplémentaires sont nécessaires avant de former l'image d'entrée finale pour le modèle génératif.
Après avoir divisé l'image en petits patchs, nous divisons les patchs en deux groupes, l'un est les patchs à texture riche et l'autre est les patchs à texture pauvre.
Une zone détaillée d'une image, telle qu'un objet ou la limite entre deux zones de couleur contrastée, devient un riche patch de texture. Les zones richement texturées présentent une grande variation en pixels par rapport aux zones texturées qui constituent principalement l'arrière-plan, comme le ciel ou l'eau calme.
Calcul des mesures de richesse de texture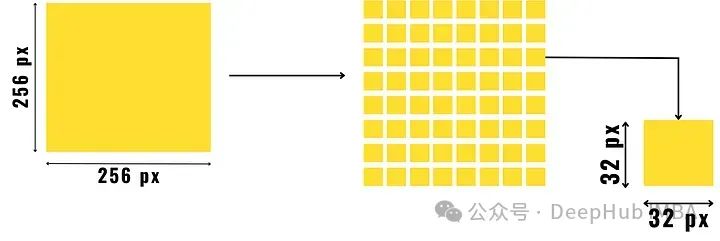
Commencez par diviser l'image en petits morceaux de taille prédéterminée, comme indiqué dans l'image ci-dessus. Recherchez ensuite les dégradés de pixels de ces patchs d'image (c'est-à-dire trouvez la différence entre les valeurs de pixels dans les directions horizontale, diagonale et anti-diagonale et additionnez-les) et séparez-les en patchs de texture riche et en patchs mal texturés.
Par rapport aux blocs avec une texture médiocre, les blocs riches en texture ont des valeurs de dégradé de pixels plus élevées. La formule pour calculer la valeur du dégradé de l'image est la suivante :
Séparez l'image en fonction du contraste des pixels, Deux images composites sont obtenues. Ce processus est un processus complet que cet article appelle « Smash&Reconstruction ».
Cela permet au modèle d'apprendre les détails de la texture au lieu de la représentation du contenu de l'objet
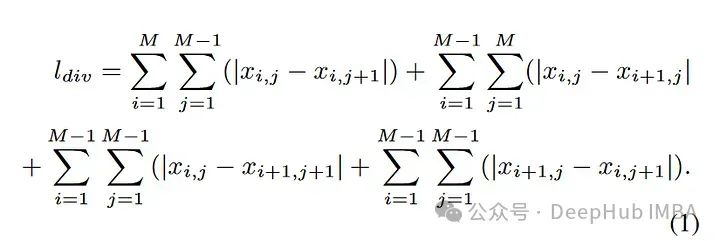
empreinte digitale
La plupart des méthodes basées sur les empreintes digitales sont limitées par la technologie de génération d'images, ces modèles/ Les algorithmes ne peuvent détecter que les images générées par des méthodes spécifiques/similaires telles que la diffusion, le GAN ou d'autres méthodes de génération d'images basées sur CNN. 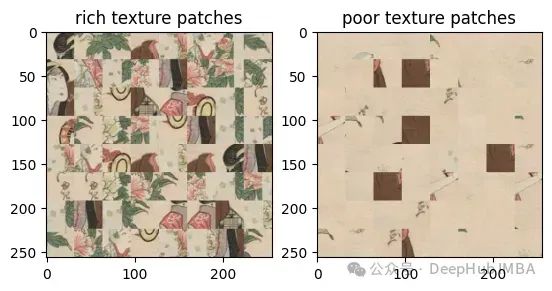
Pour résoudre précisément ce problème, le journal a divisé ces patchs d'images en textures riches ou pauvres. L’auteur a ensuite proposé une nouvelle méthode d’identification des empreintes digitales dans les images générées par l’intelligence artificielle, c’est le titre de l’article. Ils ont proposé de trouver le contraste entre les zones riches et pauvres en texture de l'image après avoir appliqué 30 filtres passe-haut.
En quoi le contraste entre les blocs de texture riches et pauvres aide-t-il ?
Pour une meilleure compréhension, nous comparons les images côte à côte, les images réelles et les images générées par l'IA.

Ces deux images sont également très difficiles à voir à l'œil nu, non ? filtre passe-haut, le contraste entre elles :

À partir de ces résultats, nous pouvons voir que les images générées par l'IA ont des taches de texture riches et un faible contraste par rapport aux images réelles. Le contraste est beaucoup plus élevé. 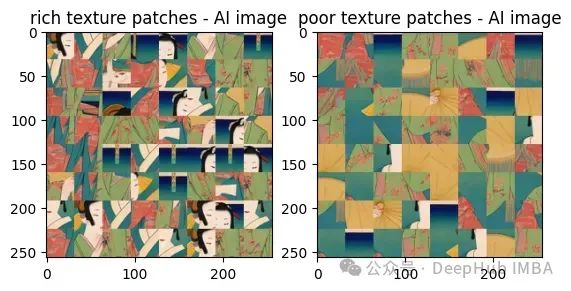
De cette façon, nous pouvons voir la différence à l'œil nu, nous pouvons donc mettre les résultats de contraste dans le modèle entraînable et saisir les données de résultat dans le classificateur. C'est l'architecture du modèle de notre article :
. 
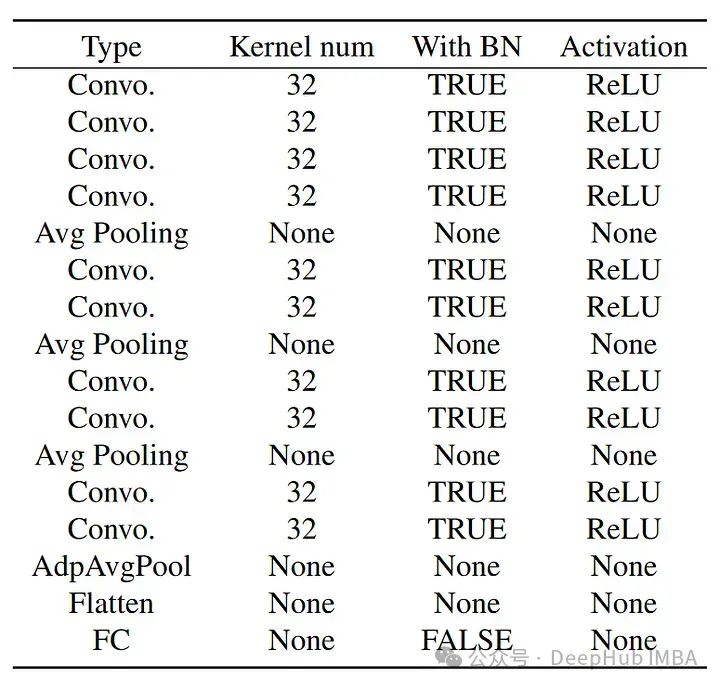
 La structure du classificateur est la suivante :
La structure du classificateur est la suivante :
L'article mentionne 30 filtres passe-haut, qui ont été initialement introduits pour la stéganalyse.
 Remarque : Il existe de nombreuses façons de stéganographie d'image. D'une manière générale, tant que l'information est cachée d'une manière ou d'une autre dans une image et qu'elle est difficile à découvrir par les méthodes ordinaires, on peut parler de stéganographie d'image. Il existe de nombreuses études connexes sur la stéganalyse, et ceux qui sont intéressés peuvent vérifier les informations pertinentes.
Remarque : Il existe de nombreuses façons de stéganographie d'image. D'une manière générale, tant que l'information est cachée d'une manière ou d'une autre dans une image et qu'elle est difficile à découvrir par les méthodes ordinaires, on peut parler de stéganographie d'image. Il existe de nombreuses études connexes sur la stéganalyse, et ceux qui sont intéressés peuvent vérifier les informations pertinentes.
Le filtre ici est une valeur matricielle appliquée à l'image à l'aide d'une méthode de convolution. Le filtre utilisé est un filtre passe-haut, qui ne laisse passer que les caractéristiques haute fréquence de l'image. Les caractéristiques haute fréquence incluent généralement des contours, des détails fins et des changements rapides d'intensité ou de couleur.
À l'exception de (f) et (g), tous les filtres sont pivotés selon un angle avant d'être réappliqués à l'image, formant ainsi un total de 30 filtres. La rotation de ces matrices se fait à l'aide de transformations affines, qui se font à l'aide de SciPy.
Résumé
Les résultats de l'article ont atteint une précision de vérification de 92%, et on dit que si vous vous entraînez davantage, vous obtiendrez de meilleurs résultats. C'est une étude très intéressante, et j'ai également trouvé. le Code de formation, ceux qui sont intéressés peuvent étudier en profondeur :
 Paper : https://arxiv.org/abs/2311.12397
Paper : https://arxiv.org/abs/2311.12397
Code : https://github.com/hridayK/Detection-of-AI-generated -images
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment organiser automatiquement 123456 colonnes dans Excel
- Le but de l'intelligence artificielle est de rendre les machines capables de
- Quelles sont les caractéristiques d'application de la technologie de l'intelligence artificielle dans l'armée ?
- Quelles sont les méthodes de stockage et les exigences en matière de disposition des éléments pour les tables adaptées à la recherche binaire ?
- Comment améliorer les modèles de deep learning à l'aide de petits ensembles de données ?