Lors d'une conférence au Forum économique mondial 2024, Yann LeCun, lauréat du prix Turing, a proposé que les modèles utilisés pour traiter les vidéos apprennent à faire des prédictions dans un espace de représentation abstrait, plutôt que dans un espace de pixels spécifique [1]. L'apprentissage de la représentation vidéo multimodale à l'aide d'informations textuelles peut extraire des fonctionnalités bénéfiques pour la compréhension vidéo ou la génération de contenu, ce qui constitue une technologie clé pour faciliter ce processus. Cependant, le phénomène répandu de corrélation de bruit entre les vidéos actuelles et les descriptions textuelles entrave sérieusement l'apprentissage de la représentation vidéo. Par conséquent, dans cet article, les chercheurs proposent un système robuste d’apprentissage vidéo long basé sur la théorie de la transmission optimale pour relever ce défi. Cet article a été accepté par l'ICLR 2024, la principale conférence sur l'apprentissage automatique, pour Oral. 
- Titre de l'article : Apprentissage par correspondance multigranulaire à partir de vidéos bruyantes à long terme
- Adresse de l'article : https://openreview.net/pdf?id=9Cu8MRmhq2
- Adresse du projet : https : //lin-yijie.github.io/projects/Norton
- Adresse du code : https://github.com/XLearning-SCU/2024-ICLR-Norton
L'apprentissage de la représentation vidéo est l'un des problèmes les plus brûlants de la recherche multimodale. La pré-formation au langage vidéo à grande échelle a obtenu des résultats remarquables dans une variété de tâches de compréhension vidéo, telles que la récupération vidéo, la réponse visuelle aux questions, la segmentation et la localisation de segments, etc. À l’heure actuelle, la plupart des travaux de pré-formation en langage vidéo se concentrent principalement sur la compréhension des segments de vidéos courtes, ignorant les relations et dépendances à long terme qui existent dans les vidéos longues. Comme le montre la figure 1 ci-dessous, la principale difficulté de l'apprentissage vidéo long est de savoir comment encoder la dynamique temporelle de la vidéo. Les solutions actuelles se concentrent principalement sur la conception d'encodeurs de réseau vidéo personnalisés pour capturer les dépendances à long terme [2], mais fait généralement face à une surcharge de ressources importante.
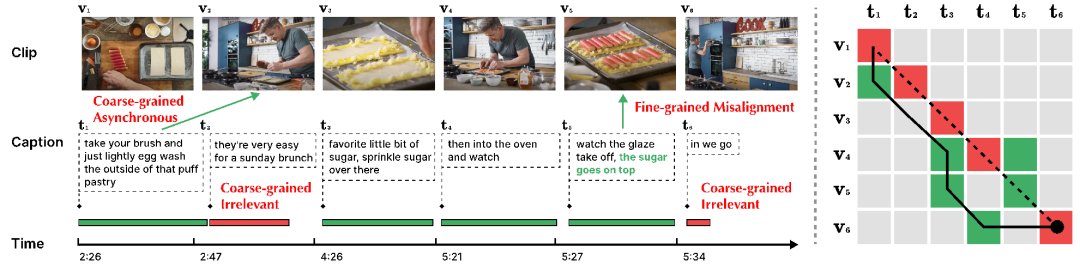
Figure 1 : Exemple de données vidéo longues [2]. La vidéo contient un scénario complexe et une dynamique temporelle riche. Chaque phrase ne peut décrire qu'un court fragment, et la compréhension de l'intégralité de la vidéo nécessite des capacités de raisonnement par corrélation à long terme. Étant donné que les vidéos longues utilisent généralement la reconnaissance automatique de la langue (ASR) pour obtenir les sous-titres de texte correspondants, le paragraphe de texte (Paragraphe) correspondant à la vidéo entière peut être divisé en plusieurs titres de texte courts en fonction de l'horodatage du texte ASR ( Légende) et une longue vidéo (Vidéo) peuvent être divisées en plusieurs clips vidéo (Clip) en conséquence. La stratégie de fusion ou d'alignement tardif de clips vidéo et de titres est plus efficace que l'encodage direct de la vidéo entière et constitue une solution optimale pour l'apprentissage d'associations temporelles à long terme. Cependant, la correspondance bruyante [3-4], NC) existe largement entre les clips vidéo et les phrases de texte, c'est-à-dire que le contenu vidéo et le corpus de texte correspondent/associés de manière incorrecte. Comme le montre la figure 2 ci-dessous, il y aura des problèmes de corrélation de bruit multi-granularité entre la vidéo et le texte.
Figure 2 : Corrélation de bruit multi-granularité. Dans cet exemple, le contenu vidéo est divisé en 6 morceaux en fonction du titre du texte. (À gauche) Une chronologie verte indique que le texte peut être aligné sur le contenu de la vidéo, tandis qu'une chronologie rouge indique que le texte ne peut pas être aligné sur le contenu de la vidéo entière. Le texte vert en t5 indique la partie liée au contenu vidéo v5. (Image de droite) La ligne pointillée indique la relation d'alignement donnée à l'origine, le rouge indique la relation d'alignement incorrecte dans l'alignement d'origine et le vert indique la véritable relation d'alignement. La ligne continue représente le résultat du réalignement effectué par l'algorithme Dynamic Time Wraping, qui ne gère pas non plus bien le défi de la corrélation du bruit.
- NC à gros grains (entre Clip-Caption). La NC à gros grain comprend deux catégories : asynchrone (Asynchrone) et non pertinent (Non pertinent). La différence réside dans le fait que le clip vidéo ou le titre peut correspondre à un titre ou un clip vidéo existant. « Asynchrone » fait référence au désalignement temporel entre le clip vidéo et le titre, tel que t1 dans la figure 2. Cela entraîne une inadéquation entre la séquence de déclarations et d'actions, comme le narrateur l'explique avant et après que les actions soient réellement exécutées. « Non pertinent » fait référence à des titres dénués de sens qui ne peuvent pas être alignés avec les clips vidéo (tels que t2 et t6) ou à des clips vidéo non pertinents. Selon une recherche pertinente de l'Oxford Visual Geometry Group [5], seulement environ 30 % des clips vidéo et des titres de l'ensemble de données HowTo100M sont visuellement alignés, et seulement 15 % sont initialement alignés
- NC à grain fin ( Cadre-Mot) . Pour un clip vidéo, seule une partie de la description textuelle peut être pertinente. Dans la figure 2, le titre t5 « Saupoudrer du sucre dessus » est fortement lié au contenu visuel v5, mais l'action « Observer le glaçage se décolle » n'est pas liée au contenu visuel. Des mots ou des images vidéo non pertinents peuvent gêner l'extraction d'informations clés, affectant l'alignement entre les segments et les titres.
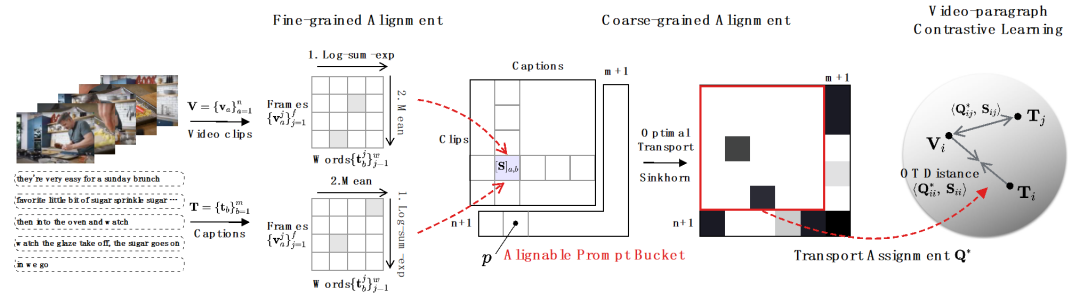
Cet article propose une Timing Optimal transport (Norton) robuste au bruit, grâce à un apprentissage par comparaison vidéo au niveau du paragraphe et une comparaison au niveau du titre du segment Apprentissage, vidéo d'apprentissage des représentations à partir de plusieurs granularités de manière post-fusion, ce qui permet d'économiser considérablement le temps de formation.
1) Vidéo - Comparaison de paragraphes. Comme le montre la figure 3, les chercheurs utilisent une stratégie fine à grossière pour effectuer un apprentissage d'association multi-granularité. Premièrement, la corrélation image-mot est utilisée pour obtenir la corrélation segment-titre, et une agrégation supplémentaire est utilisée pour obtenir la corrélation vidéo-paragraphe, et enfin la corrélation à long terme est capturée grâce à un apprentissage contrastif au niveau vidéo. Pour le défi de corrélation de bruit multi-granularité, la réponse spécifique est la suivante :
- pour NC à grain fin. Les chercheurs utilisent l'approximation log-sum-exp comme opérateur de maximum souple pour identifier les mots-clés et les images clés dans l'alignement image-mot et mot-image, réaliser une extraction d'informations importantes de manière interactive à granularité fine et accumuler des similitudes segment-titre. sexe.
- Pour NC asynchrone à gros grains. Les chercheurs ont utilisé la distance de transmission optimale comme mesure de distance entre les clips vidéo et les titres. Étant donné une matrice de similarité de titre de clip vidéo-texte , où représente le nombre de clips et de titres, l'objectif de transmission optimal est de maximiser la similarité d'alignement globale, qui peut naturellement gérer le timing de manière asynchrone ou un à plusieurs (comme t3 et). v4, v5 correspondant) situation d’alignement complexe.
où est une distribution uniforme donnant un poids égal à chaque segment et titre, est l'affectation de transmission ou le moment de réalignement, qui peut être résolu par l'algorithme Sinkhorn. - Orienté vers NC non pertinent à gros grains. Inspirés par SuperGlue [6] dans la correspondance de fonctionnalités, nous concevons un compartiment d'indices adaptatif et alignable pour essayer de filtrer les segments et les titres non pertinents. Le compartiment d'invite est un vecteur de même valeur dans une ligne et une colonne, épissé sur la matrice de similarité , et sa valeur représente le seuil de similarité pour savoir s'il peut être aligné. Les Tip Buckets s’intègrent parfaitement dans le solveur Optimal Transport Sinkhorn.
Mesurer la distance de la séquence grâce à une transmission optimale au lieu de modéliser directement de longues vidéos peut réduire considérablement la quantité de calcul. La fonction finale de perte de paragraphe vidéo est la suivante, où représente la matrice de similarité entre la ème vidéo longue et le ème paragraphe de texte.
2) Extrait - Comparaison des titres . Cette perte garantit l'exactitude de l'alignement segment-titre dans les comparaisons de paragraphes vidéo. Étant donné que l'apprentissage contrastif auto-supervisé optimisera par erreur des échantillons sémantiquement similaires en tant qu'échantillons négatifs, nous utilisons un transfert optimal pour identifier et corriger les échantillons faux négatifs potentiels :
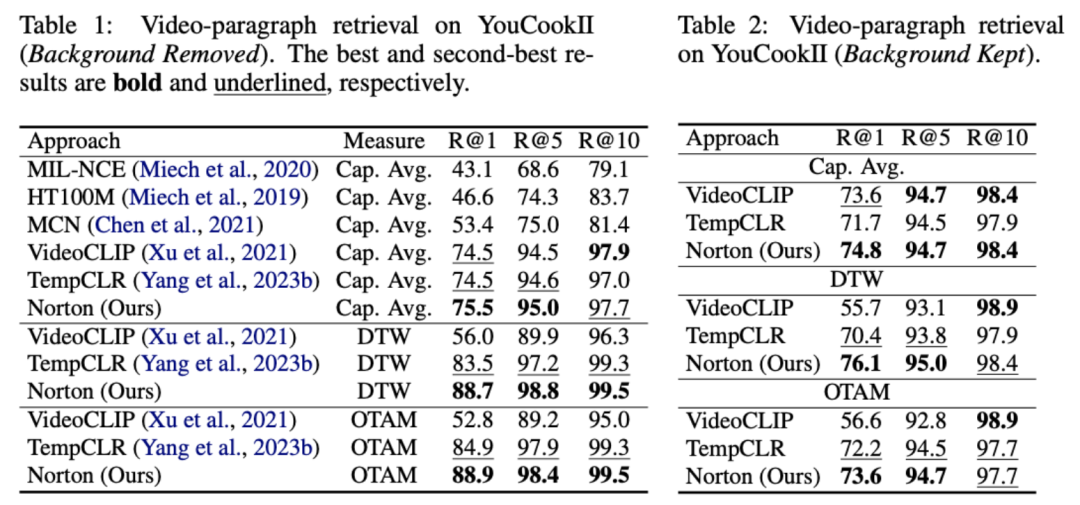
où représente tous les clips vidéo et les titres dans le numéro de lot de formation, l'identité la matrice représente la cible d'alignement standard dans la perte d'entropie croisée d'apprentissage contrastif, représente la cible de réalignement après incorporation de la cible de correction de transmission optimale , et est le coefficient de poids. Cet article vise à surmonter la corrélation du bruit pour améliorer la capacité du modèle à comprendre de longues vidéos. Nous l'avons vérifié grâce à des tâches spécifiques telles que la récupération vidéo, les questions et réponses et la segmentation des actions. Certains résultats expérimentaux sont les suivants. 1) Récupération de vidéo longueLe but de cette tâche est de récupérer la longue vidéo correspondante à partir d'un paragraphe de texte. Sur l'ensemble de données YouCookII, les chercheurs ont testé deux scénarios : la conservation de l'arrière-plan et la suppression de l'arrière-plan, selon qu'il fallait conserver ou non les clips vidéo indépendants du texte. Ils utilisent trois critères de mesure de similarité : Caption Average, DTW et OTAM. Caption Average correspond à un clip vidéo optimal pour chaque titre du paragraphe de texte et rappelle enfin la longue vidéo avec le plus grand nombre de correspondances. DTW et OTAM accumulent la distance entre les paragraphes vidéo et texte par ordre chronologique. Les résultats sont présentés dans les tableaux 1 et 2 ci-dessous.
Comparaison des performances de récupération de vidéos longues sur l'ensemble de données YouCookII 2) Analyse de robustesse de la corrélation du bruit Vidéos dans HowTo100M réalisées par Oxford Visual Geometry Group Une ré-annotation manuelle a été réalisée pour re -annotez chaque titre de texte avec l'horodatage correct. L'ensemble de données HTM-Align résultant [5] contient 80 vidéos et 49 000 textes. La récupération vidéo sur cet ensemble de données vérifie principalement si le modèle surajuste la corrélation du bruit, et les résultats sont présentés dans le tableau 9 ci-dessous.
Cet article est un apprentissage par corrélation de bruit[3][4 ]——Poursuite approfondie de la corrélation d'inadéquation/erreur de données, en étudiant le problème de corrélation de bruit multi-granularité auquel sont confrontés pré-formation multimodale vidéo-texte, la méthode d'apprentissage vidéo longue proposée peut être étendue à une gamme plus large de données vidéo avec une charge moyenne de ressources inférieure.
En regardant vers l'avenir, les chercheurs peuvent explorer davantage la corrélation entre plusieurs modalités. Par exemple, les vidéos contiennent souvent des signaux visuels, textuels et audio ; ils peuvent essayer de combiner des modèles de langage étendus externes (LLM) ou des modèles multimodaux ; (BLIP). -2) Nettoyer et réorganiser le corpus de texte ; et explorer la possibilité d'utiliser le bruit comme un stimulus positif pour la formation des modèles, plutôt que de simplement supprimer l'impact négatif du bruit.
Références :
1 Ce site, "Yann LeCun : Les modèles génératifs ne sont pas adaptés au traitement des vidéos, l'IA doit faire des prédictions dans l'espace abstrait", 23/01/2024. 2. Sun, Y., Xue, H., Song, R., Liu, B., Yang, H. et Fu, J. (2022). avec apprentissage contrastif temporel multimodal Avancées dans les systèmes de traitement de l'information neuronale, 35, 38032-38045.3. , Wu, H. et Peng, Yang, M., Yu, J., Hu, P., Zhang, C. et Peng, X. (2023). Correspondance graphique avec correspondance bruyante à deux niveaux. Actes de la conférence internationale IEEE/CVF sur la vision par ordinateur.5 Han, T., Xie, W. et Zisserman, A. (2022). de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes (pp. 2906-2916).6.Sarlin, P. E., DeTone, D., Malisiewicz, T. et Rabinovich, A. (2020) . Superglue : correspondance de fonctionnalités d'apprentissage avec les réseaux de neurones graphiques . Dans les actes de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes (pp. 4938-4947).Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




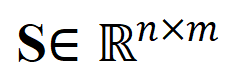 , où
, où 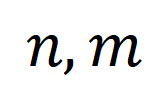 représente le nombre de clips et de titres, l'objectif de transmission optimal est de maximiser la similarité d'alignement globale, qui peut naturellement gérer le timing de manière asynchrone ou un à plusieurs (comme t3 et). v4, v5 correspondant) situation d’alignement complexe.
représente le nombre de clips et de titres, l'objectif de transmission optimal est de maximiser la similarité d'alignement globale, qui peut naturellement gérer le timing de manière asynchrone ou un à plusieurs (comme t3 et). v4, v5 correspondant) situation d’alignement complexe. 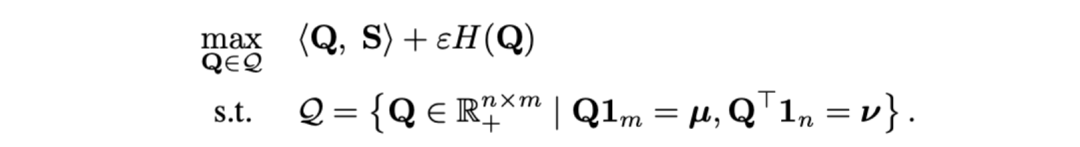
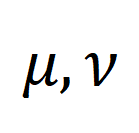 est une distribution uniforme donnant un poids égal à chaque segment et titre,
est une distribution uniforme donnant un poids égal à chaque segment et titre, 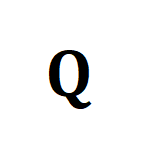 est l'affectation de transmission ou le moment de réalignement, qui peut être résolu par l'algorithme Sinkhorn.
est l'affectation de transmission ou le moment de réalignement, qui peut être résolu par l'algorithme Sinkhorn.  , et sa valeur représente le seuil de similarité pour savoir s'il peut être aligné. Les Tip Buckets s’intègrent parfaitement dans le solveur Optimal Transport Sinkhorn.
, et sa valeur représente le seuil de similarité pour savoir s'il peut être aligné. Les Tip Buckets s’intègrent parfaitement dans le solveur Optimal Transport Sinkhorn. 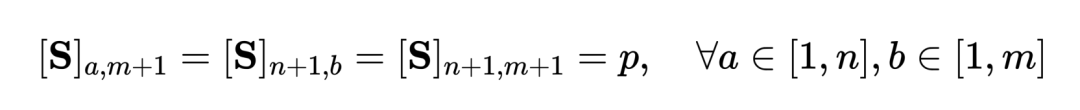
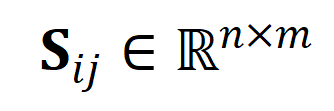 représente la matrice de similarité entre la
représente la matrice de similarité entre la  ème vidéo longue et le
ème vidéo longue et le 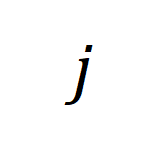 ème paragraphe de texte.
ème paragraphe de texte. 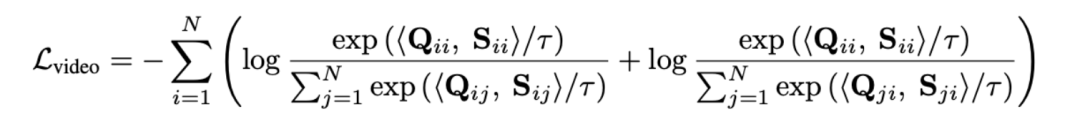
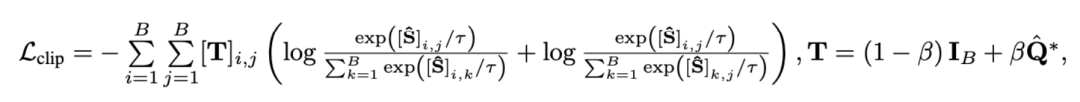
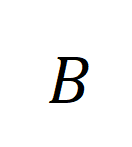 représente tous les clips vidéo et les titres dans le numéro de lot de formation, l'identité la matrice
représente tous les clips vidéo et les titres dans le numéro de lot de formation, l'identité la matrice 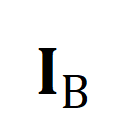 représente la cible d'alignement standard dans la perte d'entropie croisée d'apprentissage contrastif,
représente la cible d'alignement standard dans la perte d'entropie croisée d'apprentissage contrastif, 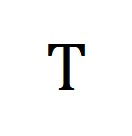 représente la cible de réalignement après incorporation de la cible de correction de transmission optimale
représente la cible de réalignement après incorporation de la cible de correction de transmission optimale 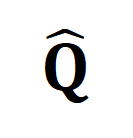 , et
, et 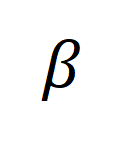 est le coefficient de poids.
est le coefficient de poids.