
Maison >Périphériques technologiques >IA >L'Université de Fudan et d'autres ont publié AnyGPT : toute entrée et sortie modale, y compris les images, la musique, le texte et la voix.
L'Université de Fudan et d'autres ont publié AnyGPT : toute entrée et sortie modale, y compris les images, la musique, le texte et la voix.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-05 09:19:17989parcourir
Récemment, le modèle de génération vidéo d'OpenAI, Sora, est devenu populaire et les capacités multimodales des modèles d'IA génératives ont une fois de plus attiré une large attention.
Le monde réel est intrinsèquement multimodal, avec des organismes détectant et échangeant des informations via différents canaux, notamment la vision, le langage, le son et le toucher. Une direction prometteuse pour le développement de systèmes multimodaux consiste à améliorer les capacités de perception multimodale de LLM, ce qui implique principalement l'intégration d'encodeurs multimodaux avec des modèles de langage, leur permettant ainsi de traiter des informations selon diverses modalités et d'exploiter la capacité de traitement de texte de LLM pour produire une réponse cohérente.
Cependant, cette stratégie s'applique uniquement à la génération de texte et ne couvre pas la sortie multimodale. Certaines recherches pionnières ont réalisé des progrès significatifs dans la compréhension et la génération multimodales de modèles linguistiques, mais ces modèles sont limités à une seule modalité non textuelle, telle que l'image ou l'audio.
Afin de résoudre les problèmes ci-dessus, l'équipe Qiu Xipeng de l'Université de Fudan, en collaboration avec des chercheurs de Multimodal Art Projection (MAP) et du Shanghai Artificial Intelligence Laboratory, a proposé un modèle de langage multimodal appelé AnyGPT, qui peut être utilisé dans n'importe quel Les combinaisons modales sont utilisées pour comprendre et raisonner sur le contenu de diverses modalités. Plus précisément, AnyGPT peut comprendre les instructions liées à plusieurs modalités telles que le texte, la voix, les images et la musique, et peut sélectionner habilement les combinaisons multimodales appropriées pour répondre.
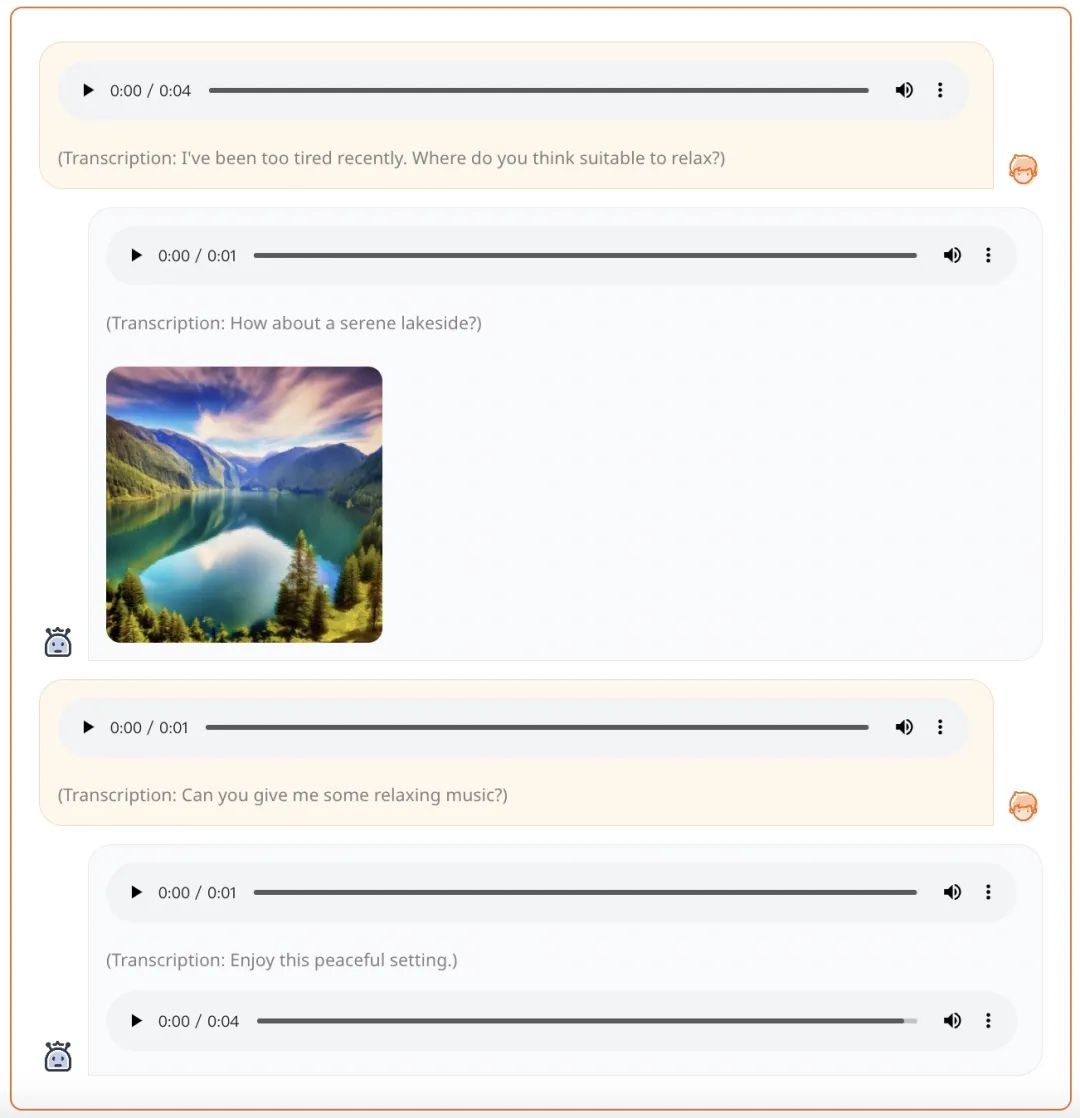
Par exemple, à partir d'une invite vocale, AnyGPT peut générer une réponse complète sous forme de voix, d'image et de musique :
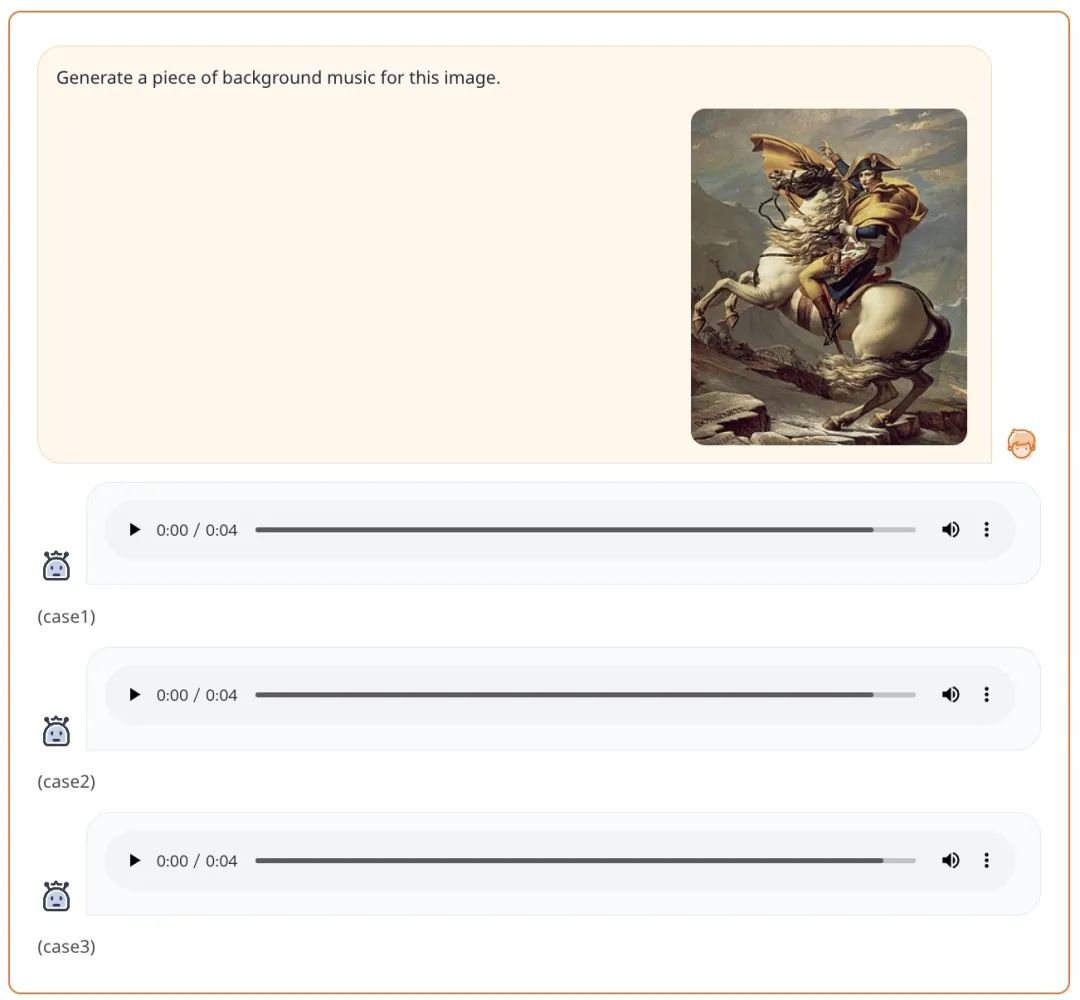
À partir d'une invite sous forme de texte + image, AnyGPT peut générer musique selon les exigences de l'invite :

- Adresse papier : https://arxiv.org/pdf/2402.12226.pdf
- Page d'accueil du projet : https ://junzhan2000 .github.io/ AnyGPT.github.io/
Introduction à la méthode
AnyGPT exploite des représentations discrètes pour traiter uniformément diverses modalités, notamment la parole, le texte, les images et la musique.
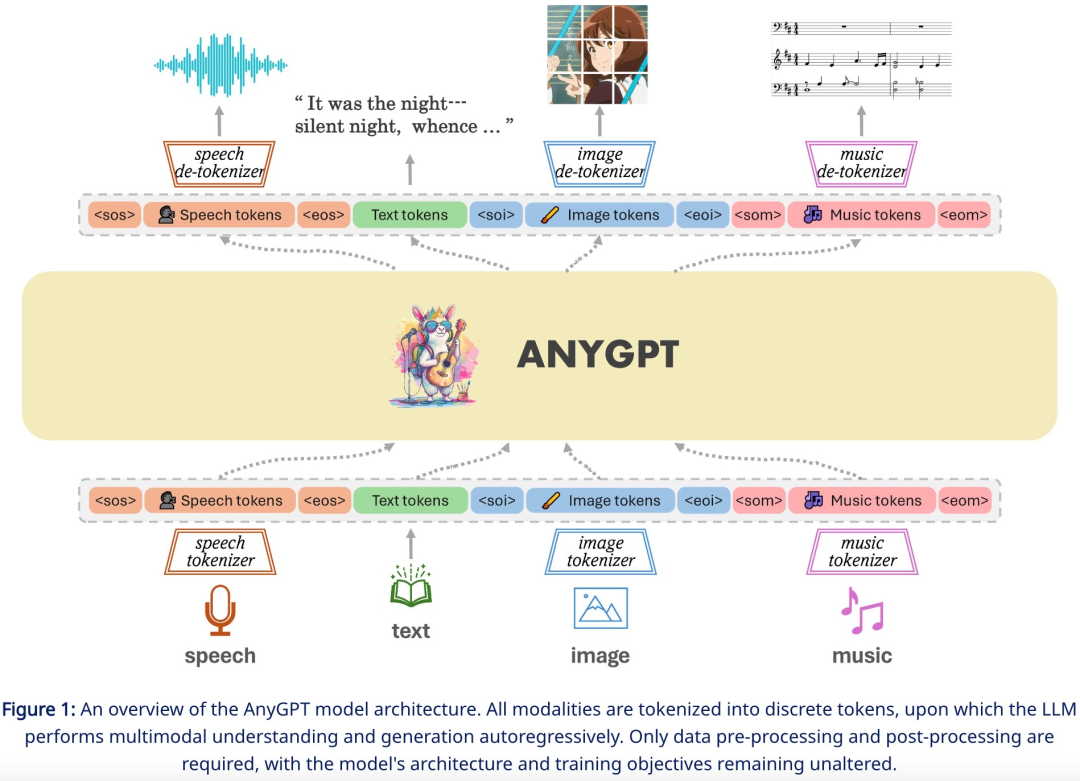
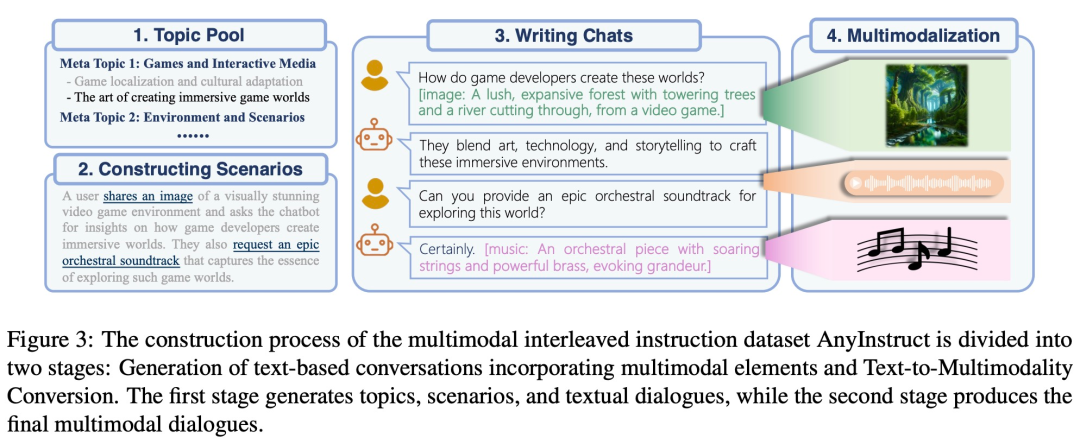
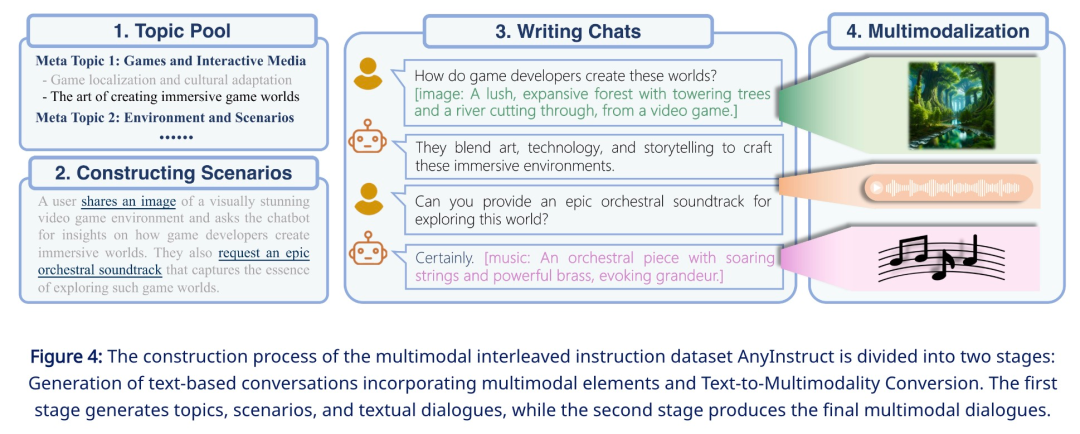
Afin d'accomplir la tâche de génération de n'importe quelle modalité à n'importe quelle modalité, cette recherche propose un cadre complet qui peut être formé de manière uniforme. Comme le montre la figure 1 ci-dessous, le cadre se compose de trois composants principaux, notamment:
- Multimodal Tokenizer
- Modèle de langage multimodal comme réseau de squelette
 multimodal détruit
multimodal détruit
Parmi eux, le tokenizer convertit les modalités non textuelles continues en jetons discrets, puis les organise en une séquence entrelacée multimodale. Le modèle de langage est ensuite entraîné à l'aide de la cible d'entraînement de prédiction de jeton suivante. Lors de l'inférence, les jetons multimodaux sont décodés vers leurs représentations d'origine par les dé-tokenizers associés. Pour enrichir la qualité de la génération, des modules d'amélioration multimodaux peuvent être déployés pour post-traiter les résultats générés, y compris des applications telles que le clonage de la parole ou la super-résolution d'images. 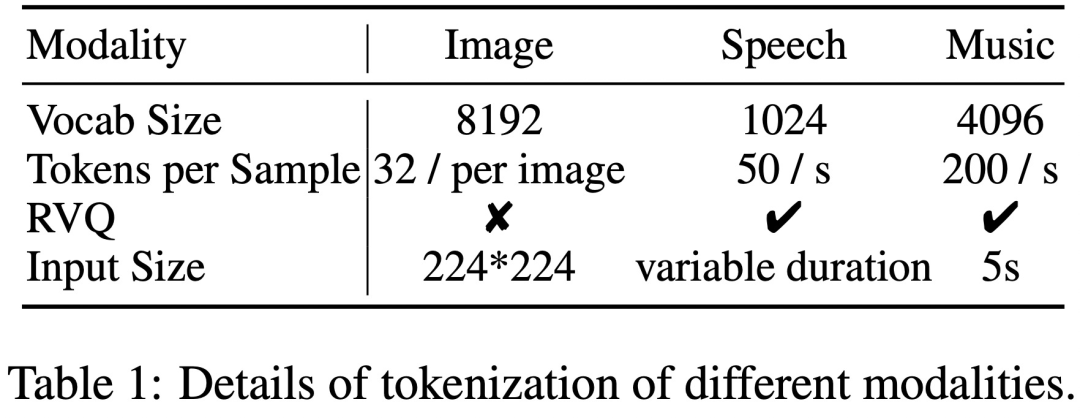

Ces données nécessitent généralement un grand nombre de bits pour être représentées avec précision, ce qui entraîne de longues séquences, particulièrement exigeantes pour les modèles de langage car la complexité de calcul augmente de façon exponentielle avec la longueur de la séquence. Pour résoudre ce problème, cette étude adopte un cadre de génération haute fidélité en deux étapes, comprenant la modélisation de l'information sémantique et la modélisation de l'information perceptuelle. Premièrement, le modèle linguistique est chargé de générer un contenu fusionné et aligné au niveau sémantique. Ensuite, le modèle non autorégressif convertit les jetons sémantiques multimodaux en contenu multimodal haute fidélité au niveau perceptuel, établissant ainsi un équilibre entre performances et efficacité.
Expérience
Les résultats expérimentaux montrent qu'AnyGPT est capable d'effectuer des tâches de dialogue de n'importe quel mode à n'importe quel mode tout en atteignant des performances comparables aux modèles dédiés dans tous les modes, prouvant ainsi son caractère discret. les représentations peuvent unifier efficacement et commodément plusieurs modalités dans des modèles de langage.
Cette étude évalue les capacités de base de la base pré-entraînée AnyGPT, couvrant les tâches de compréhension et de génération multimodales dans toutes les modalités. Cette évaluation vise à tester la cohérence entre les différentes modalités au cours du processus de pré-formation. Plus précisément, les tâches texte-à-X et X-à-texte de chaque modalité sont testées, où X est l'image, la musique et la voix.
Afin de simuler des scénarios réels, toutes les évaluations sont menées en mode zéro échantillon. Cela signifie qu'AnyGPT n'affine ni ne pré-entraîne les échantillons de formation en aval pendant le processus d'évaluation. Ce cadre d’évaluation difficile nécessite que le modèle se généralise à une distribution de tests inconnue.
Les résultats de l'évaluation montrent qu'AnyGPT, en tant que modèle de langage multimodal général, atteint des performances louables sur diverses tâches de compréhension et de génération multimodales.
Image
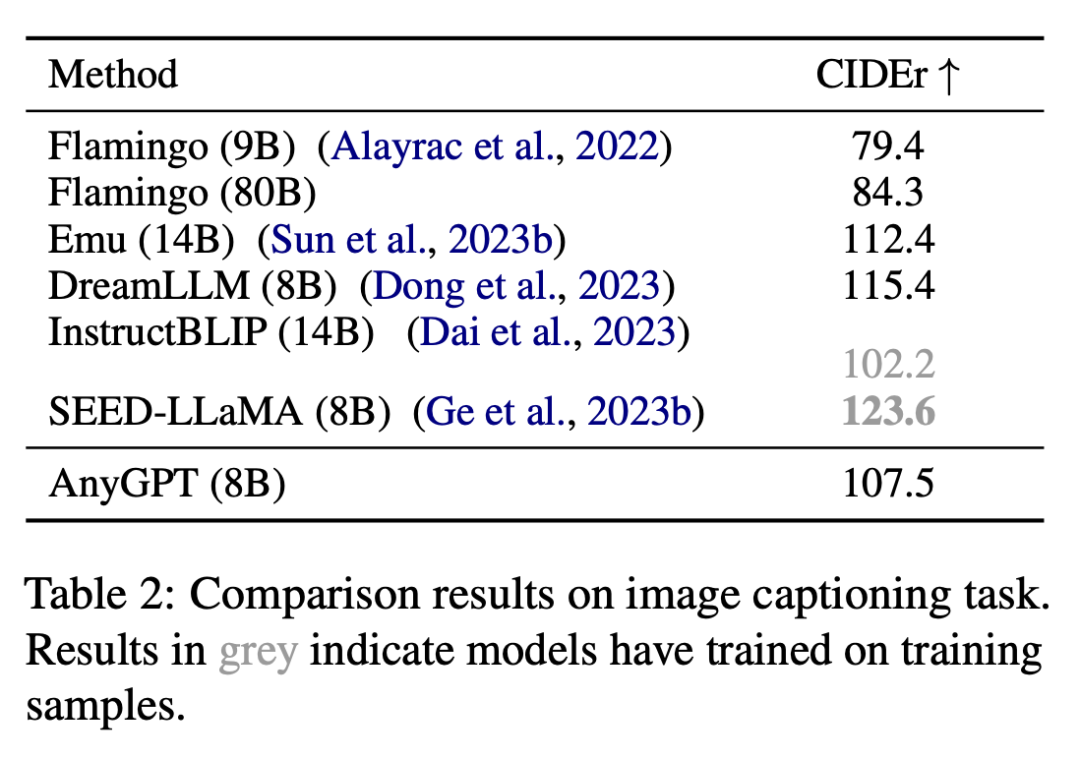
Cette étude a évalué la capacité de compréhension d'image d'AnyGPT sur des tâches de description d'image, et les résultats sont présentés dans le tableau 2.
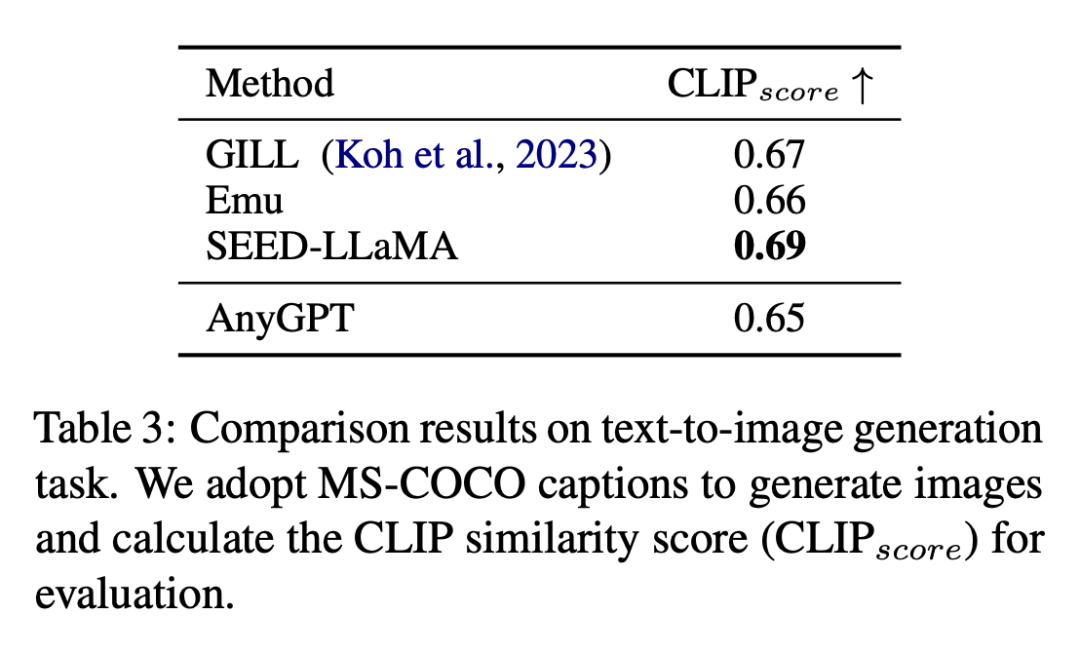
Les résultats de la tâche de génération de texte en image sont présentés dans le tableau 3.
 Speech
Speech
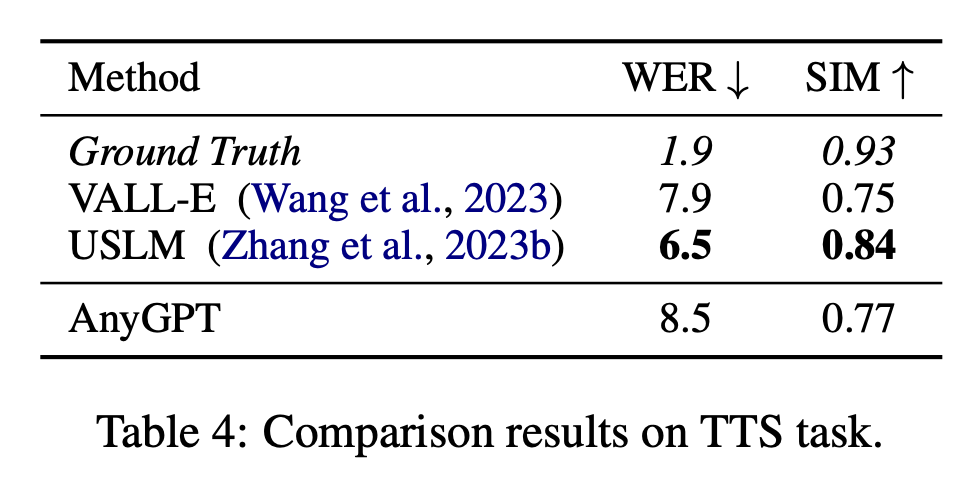
Cette étude évalue les performances d'AnyGPT sur les tâches de reconnaissance automatique de la parole (ASR) en calculant le taux d'erreur de mots (WER) sur le sous-ensemble de test de l'ensemble de données LibriSpeech, en utilisant Wav2vec 2.0 et Whisper Grand V2 comme référence, et les résultats de l’évaluation sont présentés dans le tableau 5. L'étude a évalué les performances d'AnyGPT sur les tâches de compréhension et de génération de musique sur le benchmark MusicCaps, en utilisant le score CLAP_score comme mesure objective pour mesurer la musique générée. et La similarité entre les descriptions textuelles, les résultats de l'évaluation sont présentés dans le tableau 6.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Méthode de mise en œuvre de l'algorithme de permutation et de combinaison complète JS
- Quelles sont les deux manières d'écrire le tri à bulles ? Utilisez le tri à bulles pour organiser 10 nombres.
- Quelle est la principale contribution du modèle informatique de la machine de Turing ?
- Quels paramètres peuvent être utilisés pour organiser les icônes du bureau sous Windows ?
- Comment organiser le texte horizontalement en CSS