
Maison >Périphériques technologiques >IA >Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats
Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats

- PHPzavant
- 2024-03-01 21:16:151172parcourir
À mesure que les performances des modèles de langage open source à grande échelle continuent de s'améliorer, les performances d'écriture et d'analyse du code, des recommandations, du résumé de texte et des paires questions-réponses (QA) se sont considérablement améliorées. Mais lorsqu'il s'agit d'assurance qualité, le LLM ne répond souvent pas aux problèmes liés aux données non traitées, et de nombreux documents internes sont conservés au sein de l'entreprise pour garantir la conformité, les secrets commerciaux ou la confidentialité. Lorsque ces documents sont interrogés, LLM peut halluciner et produire un contenu non pertinent, fabriqué ou incohérent.

Une technique possible pour relever ce défi est la génération d'augmentation de récupération (RAG). Cela implique le processus d'amélioration des réponses en référençant des bases de connaissances faisant autorité au-delà de la source de données de formation pour améliorer la qualité et la précision de la génération. Le système RAG se compose d'un système de récupération qui récupère les fragments de documents pertinents du corpus et d'un modèle LLM qui utilise les fragments récupérés comme contexte pour générer des réponses. Par conséquent, la qualité du corpus et la représentation intégrée dans l’espace vectoriel sont cruciales pour la performance de RAG.
Dans cet article, nous utiliserons la bibliothèque de visualisation renumics-spotlight pour visualiser l'intégration multidimensionnelle de l'espace vectoriel FAISS en 2D et rechercher des possibilités pour améliorer la précision de la réponse RAG en modifiant certains paramètres de vectorisation clés. Pour le LLM que nous choisirons, nous utiliserons le TinyLlama 1.1B Chat, un modèle compact avec la même architecture que le Llama 2. Il présente l’avantage d’avoir une empreinte en ressources réduite et des temps d’exécution plus rapides sans perte proportionnelle de précision, ce qui le rend idéal pour une expérimentation rapide.
Conception du système
Le système d'assurance qualité comporte deux modules, comme le montre la figure.
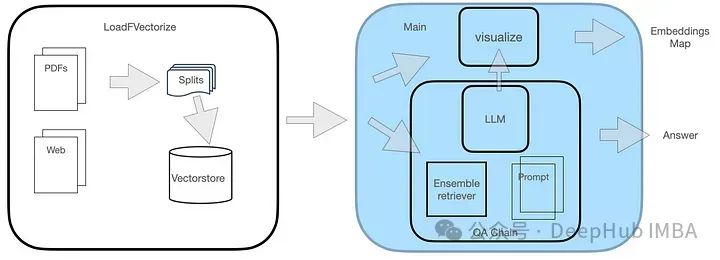
Le module LoadFVectorize est utilisé pour charger des documents PDF ou Web et effectuer des tests et une visualisation préliminaires. Un autre module est chargé de charger LLM et d'instancier le chercheur FAISS, puis de créer une chaîne de recherche comprenant LLM, le chercheur et les invites de requête personnalisées. Enfin, nous visualisons l'espace vectoriel.
Implémentation du code
1. Installez les bibliothèques nécessaires
La bibliothèque renomics-spotlight adopte une méthode de visualisation de type umap pour réduire les intégrations de grande dimension dans des visualisations 2D gérables tout en conservant les attributs clés. Nous avons brièvement présenté l'utilisation d'umap auparavant, mais uniquement les fonctions de base. Cette fois, nous l’avons intégré dans un projet réel dans le cadre de la conception du système. Tout d’abord, vous devez installer les bibliothèques nécessaires.
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
La dernière ligne ci-dessus consiste à installer la bibliothèque llama-pcp-python avec le support Metal, qui sera utilisée pour charger TinyLlama avec une accélération matérielle sur le processeur M1.
2. Module LoadFVectorize
comprend 3 fonctions :
load_doc gère le chargement des documents pdf en ligne, chaque bloc est divisé en 512 caractères, superposés par 100 caractères, et renvoie la liste des documents.
vectorize appelle la fonction load_doc ci-dessus pour obtenir la liste de blocage du document, créer l'intégration et l'enregistrer dans le répertoire local opdf_index, et renvoyer l'instance FAISS.
load_db vérifie si la bibliothèque FAISS est sur le disque dans le répertoire opdf_index et tente de la charger, renvoyant finalement un objet FAISS.
Le code complet de ce module est le suivant :
# LoadFVectorize.py from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.document_loaders import OnlinePDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS # access an online pdf def load_doc() -> 'List[Document]':loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&versinotallow=9.15.0")documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)docs = text_splitter.split_documents(documents)return docs # vectorize and commit to disk def vectorize(embeddings_model) -> 'FAISS':docs = load_doc()db = FAISS.from_documents(docs, embeddings_model)db.save_local("./opdf_index")return db # attempts to load vectorstore from disk def load_db() -> 'FAISS':embeddings_model = HuggingFaceEmbeddings()try:db = FAISS.load_local("./opdf_index", embeddings_model)except Exception as e:print(f'Exception: {e}\nNo index on disk, creating new...')db = vectorize(embeddings_model)return db3. Module principal
Le module principal définit initialement le modèle d'invite TinyLlama du modèle suivant :
{context}{question}De plus, il utilise la version quantifiée de TinyLlama de TheBloke qui peut réduire considérablement la mémoire. Nous avons choisi de charger le LLM quantifié au format GGUF.
Utilisez ensuite l'objet FAISS renvoyé par le module LoadFVectorize, créez un récupérateur FAISS, instanciez RetrievalQA et utilisez-le pour la requête.
# main.py from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp from langchain_community.embeddings import HuggingFaceEmbeddings import LoadFVectorize from renumics import spotlight import pandas as pd import numpy as np # Prompt template qa_template = """ You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context} {question} """ # Create a prompt instance QA_PROMPT = PromptTemplate.from_template(qa_template) # load LLM llm = LlamaCpp(model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",temperature=0.01,max_tokens=2000,top_p=1,verbose=False,n_ctx=2048 ) # vectorize and create a retriever db = LoadFVectorize.load_db() faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000) # Define a QA chain qa_chain = RetrievalQA.from_chain_type(llm,retriever=faiss_retriever,chain_type_kwargs={"prompt": QA_PROMPT} ) query = 'What versions of TLS supported by Client Accelerator 6.3.0?' result = qa_chain({"query": query}) print(f'--------------\nQ: {query}\nA: {result["result"]}') visualize_distance(db,query,result["result"])La visualisation de l'espace vectoriel elle-même est gérée par la dernière ligne de visualize_distance dans le code ci-dessus :
visualize_distance accède à l'attribut __dict__ de l'objet FAISS, index_to_docstore_id lui-même est le dictionnaire d'index clé pour la valeur docstore -ids, utilisé Le nombre total de documents vectorisés est représenté par l'attribut ntotal de l'objet index.
vs = db.__dict__.get("docstore")index_list = db.__dict__.get("index_to_docstore_id").values()doc_cnt = db.index.ntotalL'appel de la méthode d'index d'objet reconstruct_n peut réaliser une reconstruction approximative de l'espace vectoriel
embeddings_vec = db.index.reconstruct_n()
Avec la liste docstore-id comme index_list, vous pouvez trouver l'objet de document pertinent et l'utiliser pour créer A liste comprenant le docstore-id, les métadonnées du document, le contenu du document et son intégration dans l'espace vectoriel de tous les identifiants :
doc_list = list() for i,doc-id in enumerate(index_list):a_doc = vs.search(doc-id)doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])Utilisez ensuite la liste pour créer un DF contenant les en-têtes de colonnes, nous utilisons enfin ce DF pour la visualisation
df = pd.DataFrame(doc_list,columns=['id','metadata','document','embedding'])
在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answerembeddings_model = HuggingFaceEmbeddings()question_df = pd.DataFrame({"id": "question","question": question,"embedding": [embeddings_model.embed_query(question)],})answer_df = pd.DataFrame({"id": "answer","answer": answer,"embedding": [embeddings_model.embed_query(answer)],})df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)# add column for vector distancedf["dist"] = df.apply( lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,)
因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)
Cette étape lancera Spotlight dans la fenêtre du navigateur. 、 Exécution du test 基 1. Test de base
Vous trouverez ci-dessous l'exemple de problème que nous avons choisi :
Quelles versions de tls sont prises en charge par Client Accelerator 6.3.0 Oui :
Client Accelerator 6.3.0 est pris en charge ? TLS 1.1 ou 1.2.
Les informations supplémentaires suivantes peuvent être incluses dans la réponse.
Vous devez activer cette fonctionnalité à l'aide de la commande CLI suivante sur Client Accelerator :(config) # Policy id
Ensuite, regardons la réponse de TinyLlama à la question ci-dessus :
Client Accelerator 6.3.0 prend en charge TLS 1.1 ou 1.2 par défaut versions TLS prises en charge avec Client Accelerator. Vous devez activer cette fonctionnalité à l'aide de la commande CLI suivante sur Client Accelerator :
(config) # Policy id```
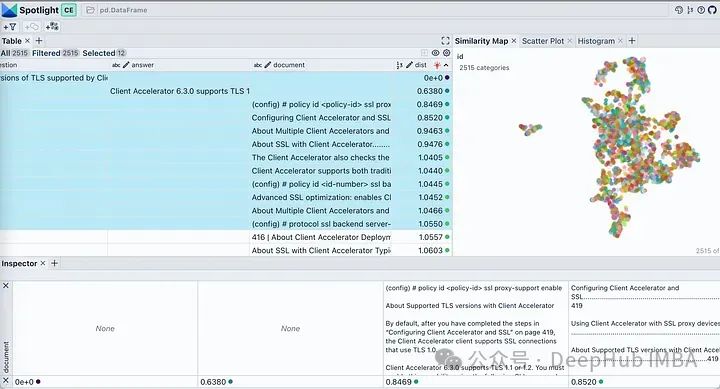
Utilisez le bouton visible sous les projecteurs pour contrôler les colonnes affichées. Triez le tableau par « dist » pour afficher les questions, les réponses et les extraits de documents les plus pertinents en haut. En regardant l'intégration de notre document, elle décrit presque tous les morceaux du document comme un seul cluster. Cela est raisonnable car notre PDF original est un guide de déploiement pour un produit spécifique, il n'y a donc aucun problème à le considérer comme un cluster.```Notez que cette commande s'applique uniquement à TLS 1.1 ou TLS 1.2 Si vous devez prendre en charge les anciennes versions de TLS, vous pouvez utiliser la commande backend ssl avec le client-tlss1.0. ou l'option client-tlss1.1 à la place. ressemble beaucoup à la réponse réelle, mais elle n'est pas tout à fait correcte car ces versions TLS ne sont pas celles par défaut. Alors voyons dans quels passages il a trouvé la réponse ?
Cliquez sur l'icône de filtre dans l'onglet Carte de similarité, elle met en surbrillance uniquement la liste de documents sélectionnés, qui est étroitement regroupée, et le reste est affiché en gris comme le montre l'image ci-dessous.
Étant donné que le retriever est un facteur clé affectant les performances du RAG, examinons plusieurs paramètres qui affectent l'espace d'intégration. Les paramètres de taille de bloc (1 000, 2 000) et/ou de chevauchement (100, 200) de TextSplitter sont différents lors du fractionnement du document.
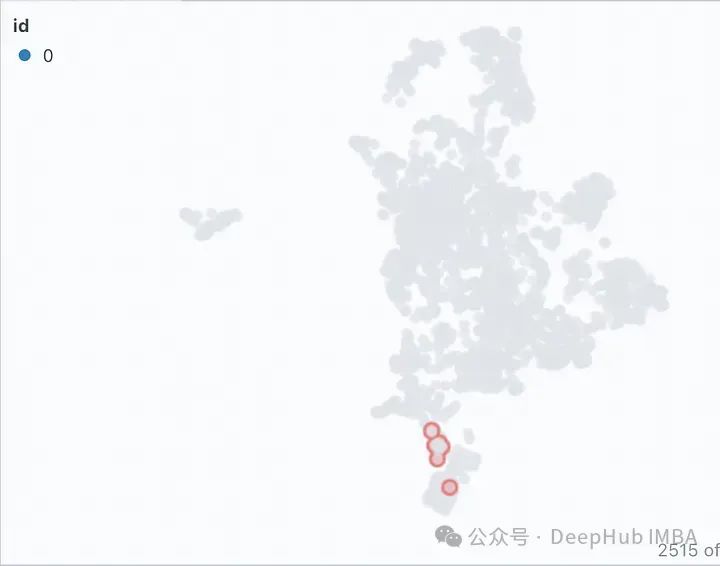
En regardant de gauche à droite, à mesure que la taille des blocs augmente, nous pouvons observer que l'espace vectoriel devient clairsemé et que les blocs deviennent plus petits. De bas en haut, le chevauchement augmente progressivement sans changements significatifs dans les caractéristiques de l’espace vectoriel. Dans toutes ces cartographies, l’ensemble apparaît toujours plus ou moins comme un seul cluster, avec seulement quelques valeurs aberrantes. Cela se voit dans les réponses générées car les réponses générées sont toutes très similaires.
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。
为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。
def load_doc():loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])documents = loader.load()...
只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。
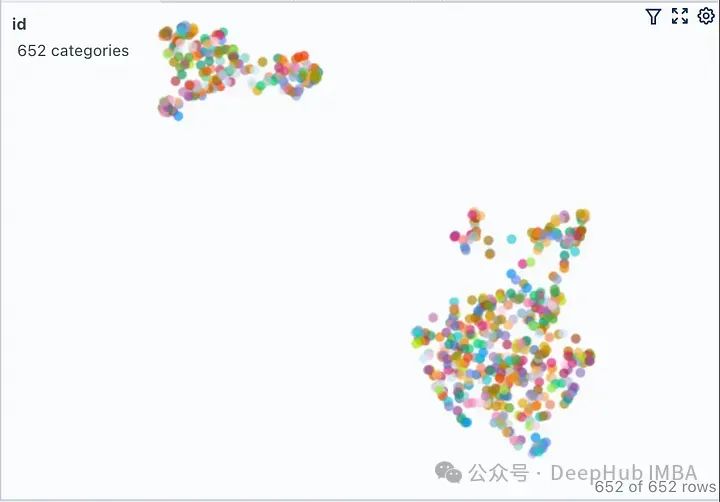
这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉”
Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS):
- TLS 1.2\2. TLS 1.3\3. TLS 1.2 with Extended Validation (EV) certificates\4. TLS 1.3 with EV certificates\5. TLS 1.3 with SHA-256 and SHA-384 hash algorithms
这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。
总结
检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。
在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!