
Maison >Périphériques technologiques >IA >L'article de 6 pages de Microsoft explose : LLM ternaire, tellement délicieux !
L'article de 6 pages de Microsoft explose : LLM ternaire, tellement délicieux !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-29 22:01:02710parcourir
C'est la conclusion avancée par Microsoft et l'Université de l'Académie chinoise des sciences dans la dernière étude :
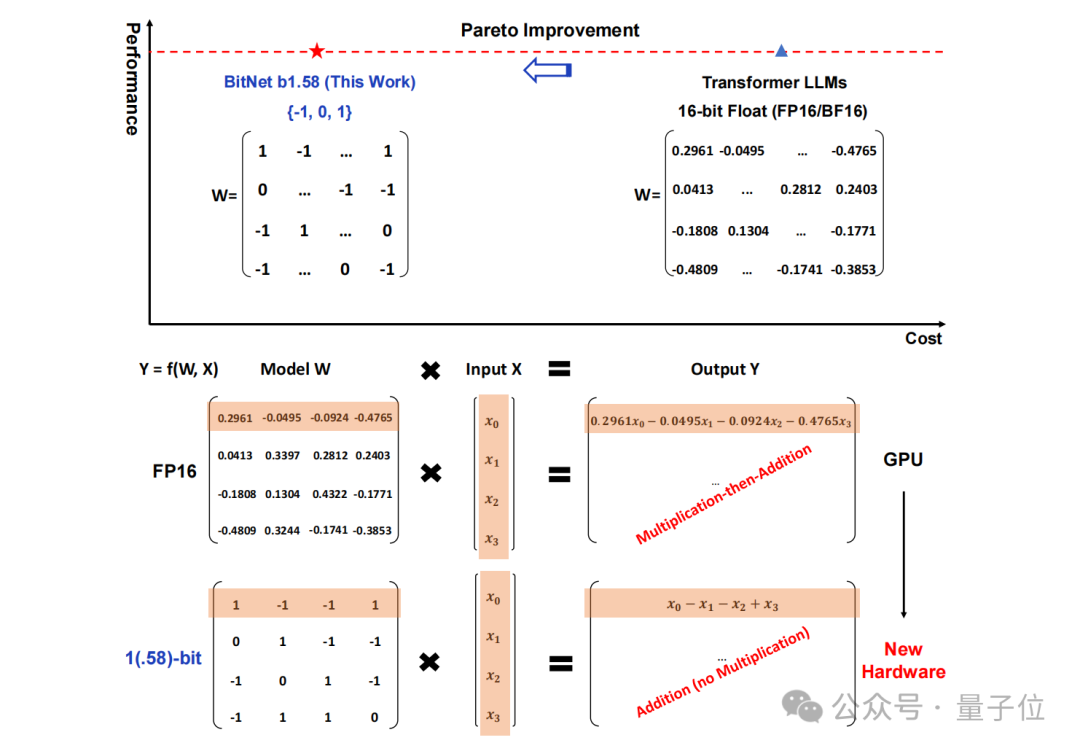
Tous les LLM seront en 1,58 bits.

Plus précisément, la méthode proposée dans cette étude s'appelle BitNet b1.58, dont on peut dire qu'elle part des paramètres de la « racine » du grand modèle de langage.
Le stockage traditionnel sous forme de nombres à virgule flottante 16 bits (tels que FP16 ou BF16) a été transformé en ternaire , qui est {-1, 0, 1}.
Il est à noter que « 1,58 bit » ne signifie pas que chaque paramètre occupe 1,58 octets d'espace de stockage, mais que chaque paramètre peut être codé avec 1,58 bits d'information.
Après une telle conversion, le calcul dans la matrice impliquera seulement l'ajout d'entiers, permettant ainsi aux grands modèles de réduire considérablement l'espace de stockage et les ressources de calcul requis tout en conservant une certaine précision.
Par exemple, BitNet b1.58 est comparé à Llama lorsque la taille du modèle est de 3B. Alors que la vitesse est augmentée de 2,71 fois, l'utilisation de la mémoire GPU ne représente presque qu'un quart de l'original.
Et lorsque la taille du modèle est plus grande (par exemple, 70B) , l'amélioration de la vitesse et l'économie de mémoire seront plus significatives !
Cette idée subversive a vraiment impressionné les internautes, et le journal a également reçu une grande attention sur La vieille blague du journal :
 1 bit est tout ce dont VOUS avez besoin.
1 bit est tout ce dont VOUS avez besoin.
Alors, comment BitNet b1.58 est-il implémenté ? Continuons la lecture.
Convertir tous les paramètres en ternaire 
Dans l'ensemble, BitNet b1.58 est toujours basé sur l'architecture BitNet
(un Transformer), remplaçant nn.Linear par BitLinear. 
quantification du poids(quantification du poids)
.Les poids du modèle BitNet b1.58 sont quantifiés en valeurs ternaires {-1, 0, 1}, ce qui équivaut à utiliser 1,58 bits pour représenter chaque poids dans le système binaire. Cette méthode de quantification réduit l'empreinte mémoire du modèle et simplifie le processus de calcul.
Deuxièmement, en termes de
conception de la fonction de quantification, afin de limiter le poids à -1, 0 ou +1, les chercheurs ont utilisé une fonction de quantification appelée absmean. 
Cette fonction évolue d'abord en fonction de la valeur absolue moyenne de la matrice de poids, puis arrondit chaque valeur à l'entier le plus proche (-1, 0, +1).
La prochaine étape est la 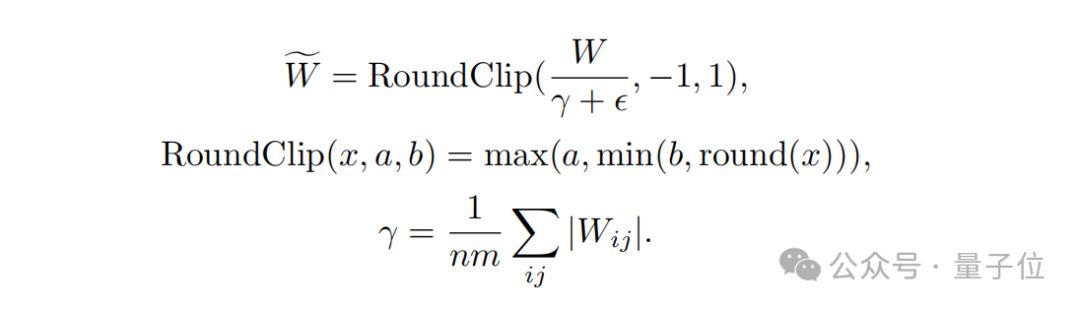 quantification d'activation
quantification d'activation
(quantification d'activation)
.La quantification des valeurs d'activation est la même que l'implémentation dans BitNet, mais les valeurs d'activation ne sont pas mises à l'échelle dans la plage [0, Qb] avant la fonction non linéaire. Au lieu de cela, les activations sont adaptées à la plage [−Qb, Qb] pour éliminer la quantification du point zéro.
Il convient de mentionner que afin de rendre BitNet b1.58 compatible avec la communauté open source, l'équipe de recherche a adopté des composants du modèle LLaMA, tels que RMSNorm, SwiGLU, etc., afin qu'il puisse être facilement intégré au grand public. logiciel source.
Enfin, en termes de comparaison des performances expérimentales, l'équipe a comparé BitNet b1.58 et FP16 LLaMA LLM sur des modèles de différentes tailles.
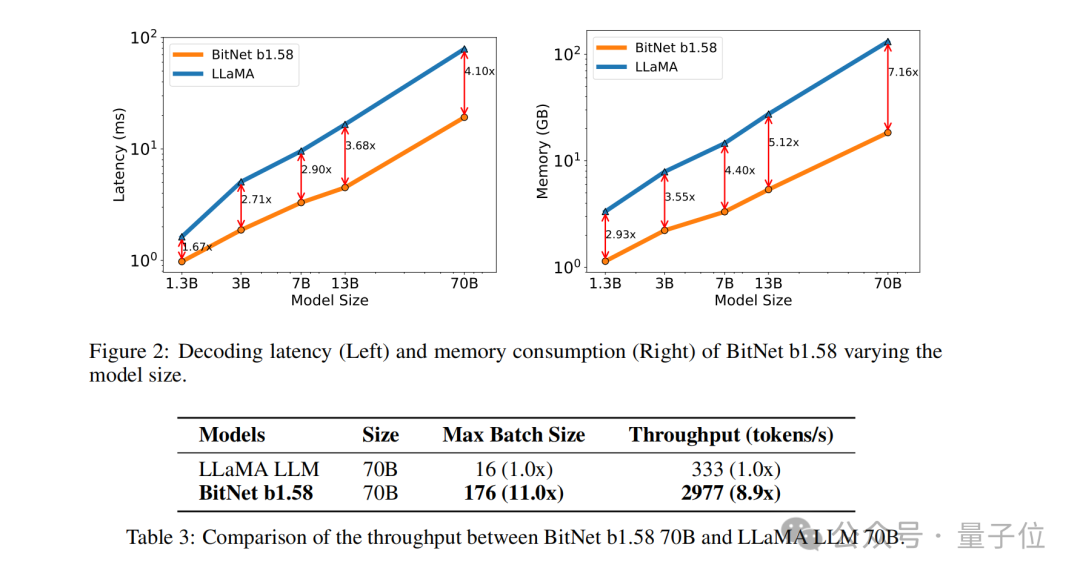
Les résultats montrent que BitNet b1.58 commence à correspondre au LLaMA LLM de pleine précision en perplexité à une taille de modèle 3B, tout en obtenant des améliorations significatives en termes de latence, d'utilisation de la mémoire et de débit.
Et lorsque la taille du modèle devient plus grande, cette amélioration des performances deviendra plus significative.
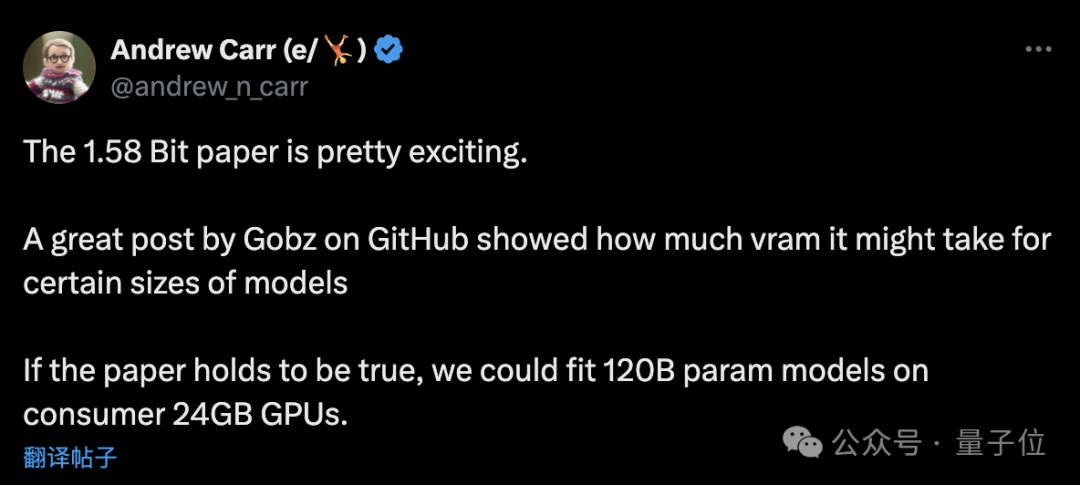
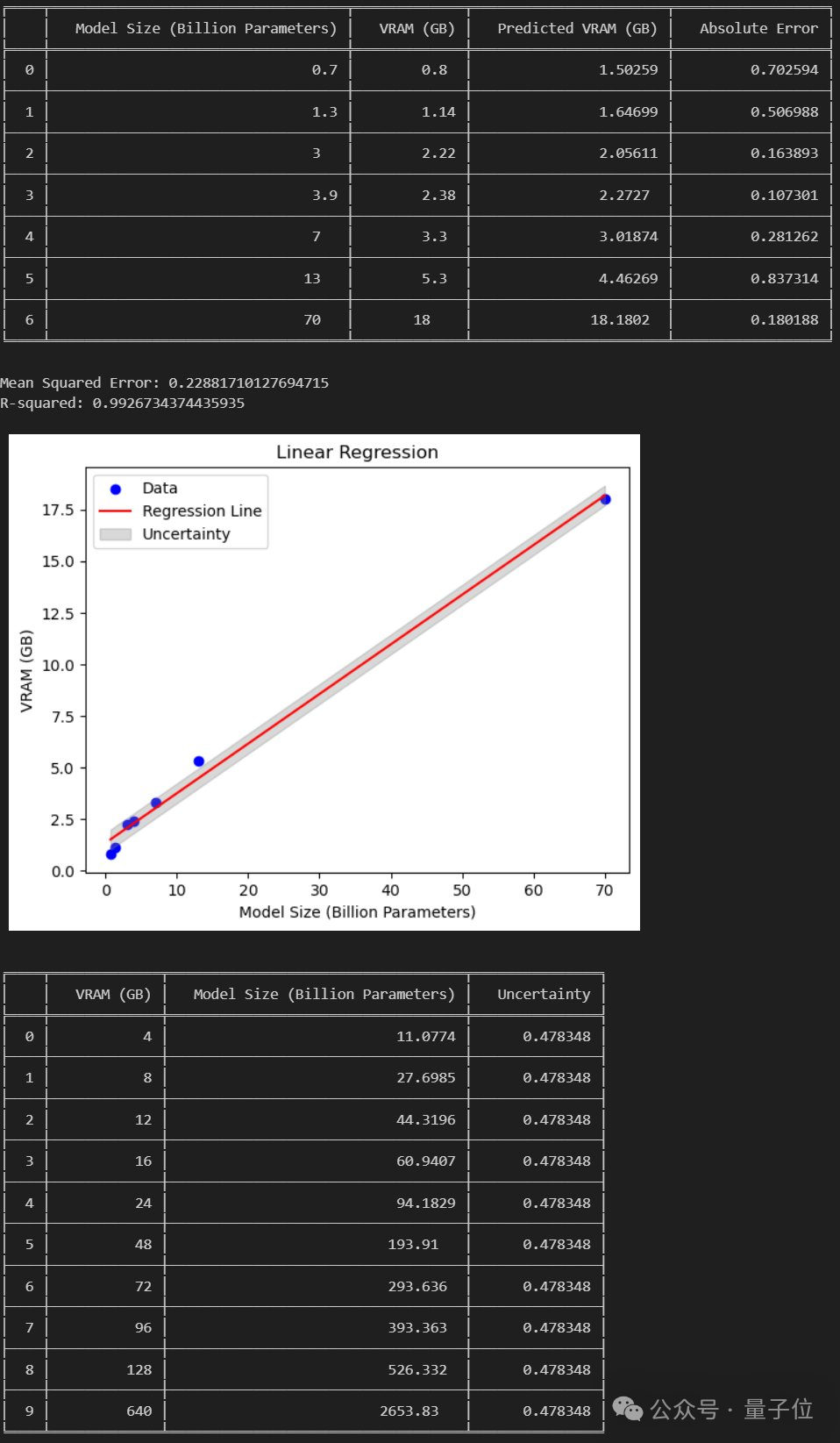
Internautes : Il est possible d'exécuter 120 milliards de grands modèles sur des GPU grand public
Comme mentionné ci-dessus, la méthode unique de cette étude a suscité de nombreuses discussions animées sur Internet.
L'auteur de DeepLearning.scala, Yang Bo, a déclaré :
Par rapport au BitNet original, la plus grande caractéristique de BitNet b1.58 est qu'il autorise 0 paramètre. Je pense qu'en modifiant légèrement la fonction de quantification, nous pourrons peut-être contrôler la proportion de 0 paramètres. Lorsque la proportion de paramètres 0 est grande, les poids peuvent être stockés dans un format clairsemé, de sorte que la mémoire vidéo moyenne occupée par chaque paramètre soit même inférieure à 1 bit. Cela équivaut à un MoE au niveau du poids. Je pense que c'est plus élégant que le MoE classique.
Dans le même temps, il a également soulevé les lacunes de BitNet :
Le plus gros inconvénient de BitNet est que bien qu'il puisse réduire la surcharge de mémoire lors de l'inférence, l'état et le gradient de l'optimiseur utilisent toujours des nombres à virgule flottante, et la formation est toujours très gourmand en mémoire. Je pense que si BitNet peut être combiné avec une technologie qui économise la mémoire vidéo pendant l'entraînement, alors par rapport aux réseaux traditionnels de demi-précision, il peut prendre en charge plus de paramètres avec la même puissance de calcul et la même mémoire vidéo, ce qui présentera de grands avantages.
La façon actuelle d'économiser la surcharge de mémoire graphique de l'état de l'optimiseur est le déchargement. Un moyen d'économiser l'utilisation de la mémoire des dégradés peut être ReLoRA. Cependant, l’expérience papier ReLoRA n’a utilisé qu’un modèle comportant un milliard de paramètres, et rien ne prouve qu’elle puisse être généralisée à des modèles comportant des dizaines ou des centaines de milliards de paramètres.

△Source de l'image : Zhihu, cité avec autorisation
Cependant, certains internautes ont analysé que :
Si le document est établi, alors nous pouvons exécuter un grand modèle de 120 Go sur un GPU grand public de 24 Go.
Alors que pensez-vous de cette nouvelle méthode ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment résoudre le problème de l'absence de la barre d'attributs en haut de l'IA ?
- Comment faire apparaître la barre d'attributs AI
- Google l'a fait aussi ? Bard a été exposé à l'utilisation des données ChatGPT pour la formation. Le grand modèle prend vraiment du retard, étape par étape.
- Implémentez une formation Edge avec moins de 256 Ko de mémoire et le coût est inférieur à un millième de celui de PyTorch
- Explication détaillée du modèle de pré-formation d'apprentissage profond en Python