
Maison >Périphériques technologiques >IA >Maîtriser l'IA d'entreprise : créer une plate-forme d'IA de niveau entreprise avec RAG et CRAG
Maîtriser l'IA d'entreprise : créer une plate-forme d'IA de niveau entreprise avec RAG et CRAG

- 王林avant
- 2024-02-26 10:46:051190parcourir
Parcourez notre guide pour savoir comment tirer le meilleur parti de la technologie de l'IA pour votre entreprise. Découvrez des choses telles que l'intégration RAG et CRAG, l'intégration de vecteurs, le LLM et l'ingénierie rapide, qui seront bénéfiques pour les entreprises cherchant à appliquer l'intelligence artificielle de manière responsable.
Créer des plates-formes prêtes pour l'IA pour les entreprises
Les entreprises Lors de l'introduction de l'intelligence artificielle générative , elles seront confrontées à de nombreux risques commerciaux qui nécessitent une gestion stratégique. Ces risques sont souvent interdépendants et vont d’un biais potentiel conduisant à des problèmes de conformité à un manque de connaissance du domaine. Les problèmes clés comprennent l'atteinte à la réputation, le respect des normes juridiques et réglementaires (en particulier en ce qui concerne les interactions avec les clients), la violation de la propriété intellectuelle, les questions d'éthique et de confidentialité (en particulier lors du traitement de données personnelles ou identifiables).
Pour relever ces défis, des stratégies hybrides telles que la génération augmentée par récupération (RAG) sont proposées. La technologie RAG peut améliorer la qualité du contenu généré par l'intelligence artificielle et rendre les plans d'intelligence artificielle d'entreprise plus sûrs et plus fiables. Cette stratégie répond efficacement à des problèmes tels que le manque de connaissances et la désinformation, tout en garantissant le respect des directives juridiques et éthiques et en prévenant les atteintes à la réputation et le non-respect.
Comprendre la génération d'augmentation de récupération (RAG)
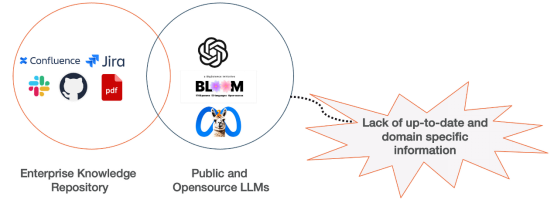
La génération d'augmentation de récupération (RAG) est une approche avancée pour améliorer les performances en intégrant les informations d'un base de connaissances de l'entreprise et la fiabilité dans la création de contenu IA. Considérez RAG comme un chef cuisinier qui s'appuie sur un talent inné, une formation approfondie et un flair créatif, le tout soutenu par une compréhension approfondie des principes fondamentaux de la cuisine. Lorsque vient le temps d’utiliser des épices inhabituelles ou de répondre à des demandes de plats nouveaux, les chefs consultent des références culinaires fiables pour garantir la meilleure utilisation des ingrédients.
Tout comme un chef peut cuisiner une variété de cuisines, les systèmes d'intelligence artificielle tels que GPT et LLaMA-2 peuvent également générer du contenu sur divers sujets. Cependant, lorsque vient le temps de fournir des informations détaillées et précises, en particulier lorsqu'il s'agit de cuisine nouvelle ou de navigation dans de grandes quantités de données d'entreprise, ils se tournent vers des outils spéciaux pour garantir l'exactitude et la profondeur des informations.
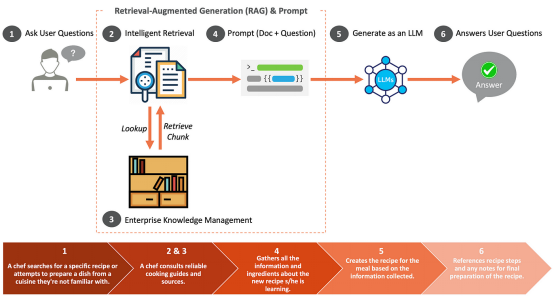
Et si la phase de récupération du RAG est insuffisante ?
CRAG est une intervention corrective conçue pour améliorer la stabilité des paramètres RAG. CRAG utilise T5 pour évaluer la pertinence des documents récupérés. Lorsque les documents provenant de l'entreprise sont jugés non pertinents, des recherches sur le Web peuvent être utilisées pour combler les lacunes en matière d'informations.
Considérations architecturales pour les solutions d'IA générative de niveau entreprise
L'architecture est fondamentalement construite autour de trois piliers principaux : l'ingestion de données, les requêtes et la récupération intelligente, la génération d'invites et le modèle de langage Big Data .
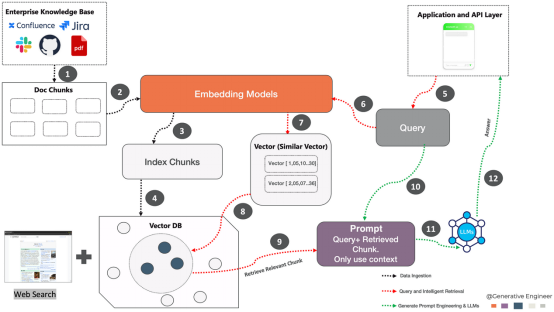
Données PhotographiéDans : La première étape consiste à convertir le contenu du document de l'entreprise en un format facilement interrogeable. Cette transformation s'effectue à l'aide d'un modèle d'intégration, en suivant la séquence d'opérations suivante
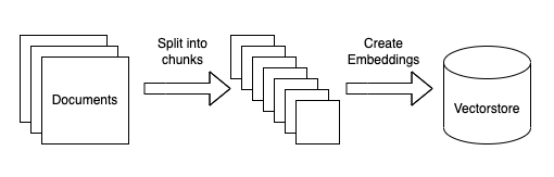
- Segmentation des données : Divers documents issus de sources de connaissances d'entreprise telles que Confluence, Jira et PDF sont extraits dans le système. Cette étape consiste à diviser le document en parties gérables, souvent appelées « morceaux ».
- Modèle d'intégration : Transmettez ensuite ces morceaux de document au modèle d'intégration. Un modèle d'intégration est un réseau de neurones qui convertit le texte en une forme numérique (vecteur) qui représente la sémantique du texte, le rendant compréhensible par les machines.
- Bloc d'indexation : Le vecteur produit par le modèle d'intégration est ensuite indexé. L'indexation est le processus d'organisation des données de manière à faciliter une récupération efficace.
- Base de données vectorielles : Enregistrez toutes les intégrations vectorielles dans une base de données vectorielles. Et enregistrez le texte représenté par chaque intégration dans un fichier différent, en veillant à inclure une référence à l'intégration correspondante.
Requête et récupération intelligente : Une fois que le serveur d'inférence reçoit la question de l'utilisateur, il la convertit en vecteur via un processus d'intégration, qui utilise le même modèle pour intégrer le document dans la base de connaissances. La base de données de vecteurs est ensuite recherchée pour identifier les vecteurs étroitement liés à l'intention de l'utilisateur et transmise à un grand modèle de langage (LLM) pour enrichir le contexte.
5.Requêtes : Requêtes de la couche application et API. La requête est ce qu'un utilisateur ou une autre application saisit lors de la recherche d'informations.
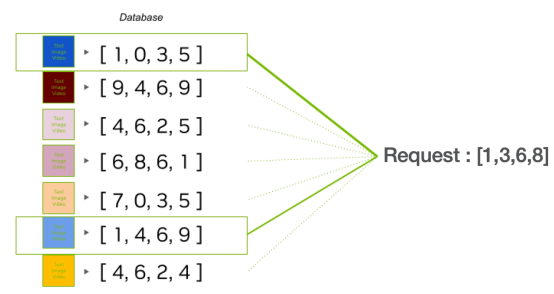
6.Récupération de requêtes intégrées : Utilisez le Vector.Embedding généré pour lancer une recherche dans l'index de la base de données vectorielles. Choisissez le nombre de vecteurs que vous souhaitez récupérer de la base de données de vecteurs ; ce nombre sera proportionnel au nombre de contextes que vous envisagez de compiler et d'utiliser pour résoudre le problème.
7. Vecteurs (vecteurs de similarité) : Ce processus identifie des vecteurs similaires qui représentent des morceaux de documents pertinents pour le contexte de la requête.
8.Récupérer les vecteurs associés :
Récupérer les vecteurs associés à partir de la base de données vectorielles. Par exemple, dans le contexte d’un chef, cela peut correspondre à deux vecteurs liés : une recette et une étape de préparation. Les fragments correspondants seront collectés et fournis avec l'invite.
9. Récupérer les morceaux associés : Le système récupère les parties du document qui correspondent aux vecteurs identifiés comme pertinents pour la requête. Une fois la pertinence des informations évaluée, le système détermine les prochaines étapes. Si les informations sont tout à fait cohérentes, elles seront classées selon leur importance. Si les informations sont incorrectes, le système les ignore et recherche de meilleures informations en ligne.
Générer des Invites Ingénierie et LLM : Générer des invites L'ingénierie est essentielle pour guider les grands modèles de langage afin de donner les bonnes réponses . Cela implique de créer des questions claires et précises qui tiennent compte des éventuelles lacunes dans les données. Ce processus est continu et nécessite des ajustements réguliers pour une meilleure réponse. Il est également important de s’assurer que les questions sont éthiques, exemptes de préjugés et d’éviter les sujets sensibles.
10. Ingénierie de l'invite : Les morceaux récupérés sont ensuite utilisés avec la requête d'origine pour créer l'invite. Cet indice est conçu pour transmettre efficacement le contexte de la requête au modèle de langage.
11. LLM (Large Scale Language Model) : Les astuces d'ingénierie sont gérées par de grands modèles de langage. Ces modèles peuvent générer un texte de type humain en fonction des entrées qu'ils reçoivent.
12. Réponse : Enfin, le modèle de langage utilise le contexte fourni par l'indice et les morceaux récupérés pour générer la réponse à la requête. Cette réponse est ensuite renvoyée à l'utilisateur via les couches application et API.
Conclusion
Ce blog explore le processus complexe d'intégration de l'IA dans le développement de logiciels, soulignant le potentiel de transformation de la création d'une plateforme d'IA générative d'entreprise inspirée de CRAG. En abordant les complexités de l’ingénierie juste à temps, de la gestion des données et des approches innovantes de génération augmentée de récupération (RAG), nous décrivons les moyens d’intégrer la technologie de l’IA au cœur des opérations commerciales. Les discussions futures approfondiront le Cadre d'IA générative pour le développement intelligent, en examinant les outils, techniques et stratégies spécifiques permettant de maximiser l'utilisation de l'IA afin de garantir un environnement de développement plus intelligent et plus efficace.
Source | https://www.php.cn/link/1f3e9145ab192941f32098750221c602
Auteur |Venkat Rangasamy
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les tendances de développement de l'intelligence artificielle ?
- À quelle spécialité appartient l'intelligence artificielle ?
- Comment organiser le texte selon sa forme dans l'IA ?
- Quelles sont les caractéristiques d'application de la technologie de l'intelligence artificielle dans l'armée ?
- Quelles sont les classifications de l'intelligence artificielle ?