
Maison >Périphériques technologiques >IA >SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-20 11:48:22990parcourir
Titre original : SIMPL : A Simple and Efficient Multi-agent Motion Prediction Baseline for Autonomous Driving
Lien papier : https://arxiv.org/pdf/2402.02519.pdf
Lien code : https://github.com /HKUST-Aerial-Robotics/SIMPL
Affiliation de l'auteur : Hong Kong University of Science and Technology DJI

Idée de thèse :
Cet article propose une ligne de base de prédiction de mouvement simple et efficace (SIMPL) pour les véhicules autonomes. Contrairement aux méthodes traditionnelles centrées sur les agents (qui ont une grande précision mais nécessitent des calculs répétés) et aux méthodes centrées sur la scène (où la précision et la généralité en souffrent), SIMPL peut fournir une solution complète pour tout le trafic concerné, fournissant des prévisions de mouvement précises en temps réel. Pour améliorer la précision et la vitesse d'inférence, cet article propose un module global de fusion de fonctionnalités compact et efficace qui effectue la transmission de messages dirigés de manière symétrique, permettant au réseau de prédire le mouvement futur de tous les usagers de la route en une seule passe avec anticipation, et de réduire la précision. perte causée par le mouvement du point de vue. En outre, cet article étudie l'utilisation des polynômes de base de Bernstein pour le paramétrage continu de trajectoire dans le décodage de trajectoire, permettant l'évaluation des états et de leurs dérivées d'ordre supérieur à tout instant souhaité, ce qui est précieux pour les tâches de planification en aval. En tant que base de référence solide, SIMPL affiche des performances très compétitives sur les références de prédiction de mouvement Argoverse 1 et 2 par rapport aux autres méthodes de pointe. De plus, sa conception légère et sa faible latence d’inférence rendent SIMPL hautement évolutif et prometteur pour les déploiements aéroportés réels.
Conception du réseau :
La prévision des mouvements des usagers du trafic environnants est cruciale pour les véhicules autonomes, en particulier dans les modules de prise de décision et de planification en aval. Une prédiction précise des intentions et des trajectoires améliorera la sécurité et le confort de conduite.
Pour la prédiction de mouvement basée sur l'apprentissage, l'un des sujets les plus importants est la représentation du contexte. Les premières méthodes représentaient généralement la scène environnante sous la forme d'une image multicanal vue à vol d'oiseau [1]–[4]. En revanche, les recherches récentes adoptent de plus en plus une représentation de scène vectorisée [5]-[13], dans laquelle les emplacements et les géométries sont annotés à l'aide d'ensembles de points ou de polylignes avec des coordonnées géographiques, améliorant ainsi la fidélité et élargissant le champ de réception. Cependant, tant pour les représentations rastérisées que vectorisées, une question clé se pose : comment choisir le référentiel approprié pour tous ces éléments ? Une approche simple consiste à décrire toutes les instances au sein d'un système de coordonnées partagé (centré sur la scène), tel qu'un système centré sur un véhicule autonome, et à utiliser les coordonnées directement comme entités d'entrée. Cela nous permet de faire des prédictions pour plusieurs agents cibles en une seule passe de rétroaction [8, 14]. Cependant, en utilisant les coordonnées globales comme entrée, les prédictions sont généralement faites pour plusieurs agents cibles en une seule passe de rétroaction [8, 14]. Cependant, l'utilisation de coordonnées globales comme entrée (qui varient souvent dans une large mesure) exacerbera considérablement la complexité inhérente de la tâche, entraînant une dégradation des performances du réseau et une adaptabilité limitée à de nouveaux scénarios. Pour améliorer la précision et la robustesse, une solution courante consiste à normaliser le contexte de la scène en fonction de l'état actuel de l'agent cible [5, 7, 10]-[13] (centré sur l'agent). Cela signifie que le processus de normalisation et le codage des fonctionnalités doivent être effectués de manière répétée pour chaque agent cible, ce qui entraîne de meilleures performances au détriment de calculs redondants. Par conséquent, il est nécessaire d’explorer une méthode capable de coder efficacement les caractéristiques de plusieurs objets tout en conservant la robustesse aux changements de perspective.
Pour les modules en aval de prédiction de mouvement, tels que la prise de décision et la planification de mouvements, non seulement la position future doit être prise en compte, mais également le cap, la vitesse et d'autres dérivés d'ordre élevé doivent être pris en compte. Par exemple, les caps prévus des véhicules environnants jouent un rôle clé dans la détermination de l'occupation spatio-temporelle future, ce qui est un facteur clé pour garantir une planification de mouvement sûre et robuste [15, 16]. De plus, prédire indépendamment des quantités d’ordre élevé sans adhérer aux contraintes physiques peut conduire à des résultats de prédiction incohérents [17, 18]. Par exemple, même si la vitesse est nulle, elle peut produire un déplacement de position qui perturbe le module de planification.
Cet article présente une méthode appelée SIMPL (Simple and Efficient Motion Prediction Baseline) pour résoudre le problème clé de la prédiction de trajectoire multi-agents dans les systèmes de conduite autonome. La méthode adopte d'abord une représentation de scène centrée sur l'instance, puis introduit la technologie de transformateur de fusion symétrique (SFT), capable de prédire efficacement les trajectoires de tous les agents en une seule passe à action directe tout en conservant la précision et la robustesse de l'invariance de la perspective. Comparée à d’autres méthodes basées sur la fusion symétrique de contextes, SFT est plus simple, plus légère et plus facile à mettre en œuvre, ce qui la rend adaptée au déploiement dans les environnements automobiles.
Deuxièmement, cet article présente une nouvelle méthode de paramétrage pour les trajectoires prédites basée sur le polynôme de base de Bernstein (également connu sous le nom de courbe de Bézier). Cette représentation continue garantit la fluidité et permet une évaluation facile de l'état précis et de ses dérivées d'ordre supérieur à tout moment donné. L'étude empirique de cet article montre qu'apprendre à prédire les points de contrôle des courbes de Bézier est plus efficace et numériquement plus stable que l'estimation des coefficients des polynômes à base monôme.
Enfin, les composants proposés sont bien intégrés dans un modèle simple et efficace. Cet article évalue la méthode proposée sur deux ensembles de données de prédiction de mouvement à grande échelle [22, 23], et les résultats expérimentaux montrent que SIMPL est très compétitif par rapport aux autres méthodes de pointe malgré sa conception simplifiée. Plus important encore, SIMPL permet une prédiction efficace de trajectoire multi-agents avec moins de paramètres à apprendre et une latence d'inférence plus faible sans sacrifier les performances de quantification, ce qui est prometteur pour un déploiement aéroporté réel. Cet article souligne également que, en tant que base de référence solide, SIMPL présente une excellente évolutivité. L'architecture simple facilite l'intégration directe avec les dernières avancées en matière de prédiction de mouvement, offrant ainsi la possibilité d'améliorer encore les performances globales.
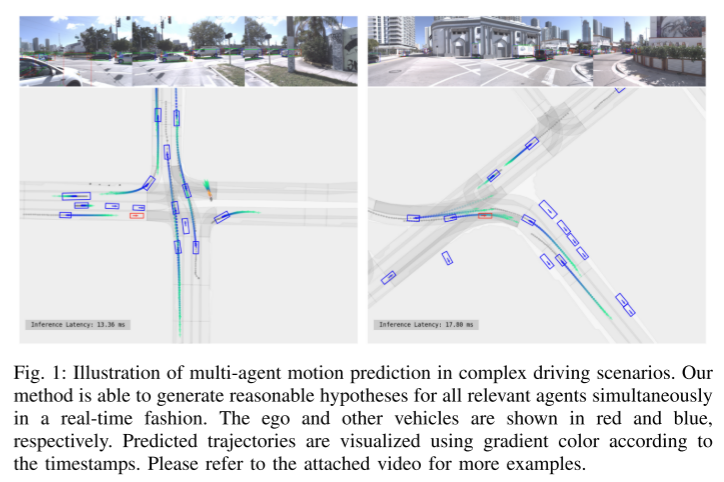
Figure 1 : Illustration de la prédiction de mouvement multi-agents dans des scénarios de conduite complexes. Notre approche est capable de générer simultanément et en temps réel des hypothèses raisonnables pour tous les agents concernés. Votre propre véhicule et les autres véhicules sont représentés respectivement en rouge et en bleu. Utilisez des couleurs dégradées pour visualiser les trajectoires prévues en fonction des horodatages. Veuillez vous référer à la vidéo ci-jointe pour plus d'exemples.
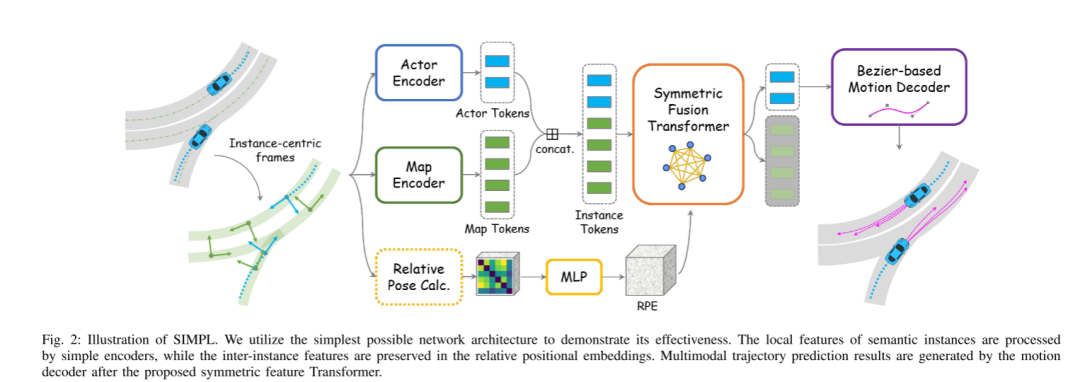
Figure 2 : Schéma SIMPL. Cet article utilise l'architecture réseau la plus simple possible pour démontrer son efficacité. Les caractéristiques locales des instances sémantiques sont traitées par un simple encodeur, tandis que les caractéristiques inter-instances sont préservées dans des intégrations de position relative. Les résultats de prédiction de trajectoire multimodale sont générés par un décodeur de mouvement après le transformateur de caractéristiques symétrique proposé.
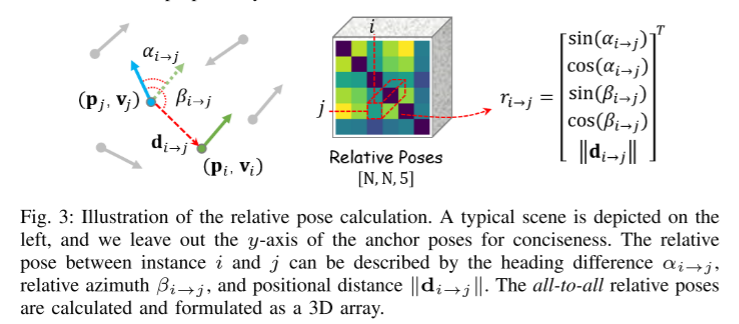
Figure 3 : Diagramme schématique du calcul de la pose relative.
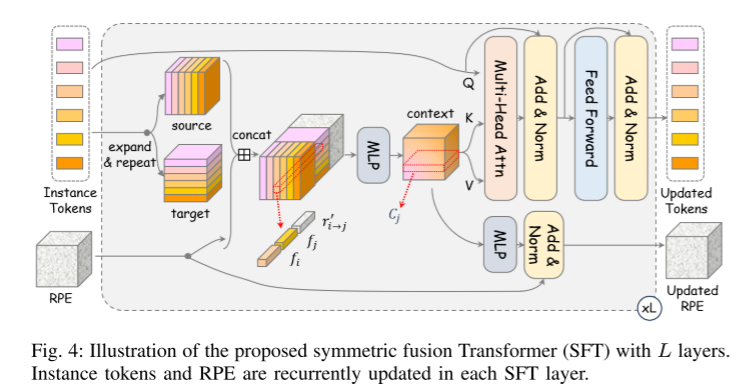
Figure 4 : Illustration du transformateur à fusion symétrique (SFT) proposé en couche L. Les jetons d'instance et les intégrations de position relative (RPE) sont mis à jour de manière cyclique dans chaque couche SFT.
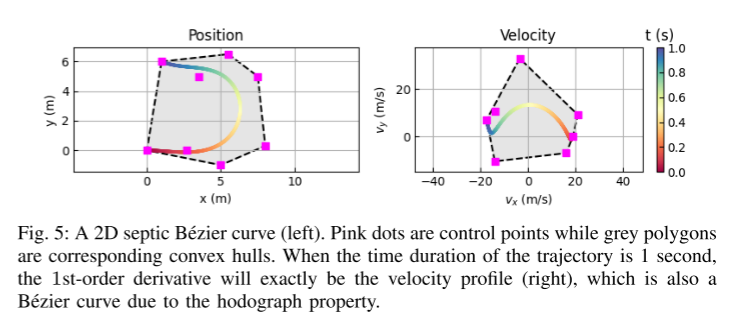
Figure 5 : Courbe de Bézier septique 2D (à gauche).
Résultats expérimentaux :
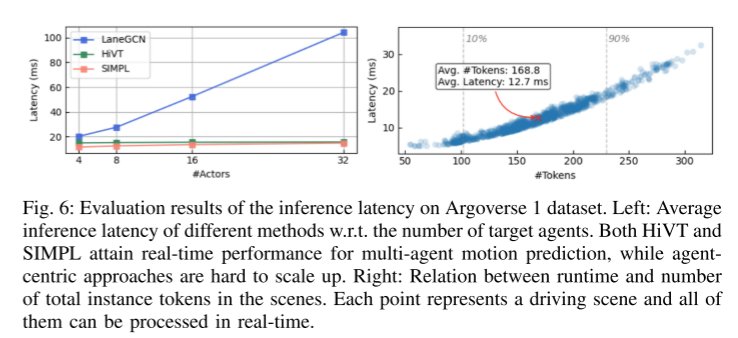
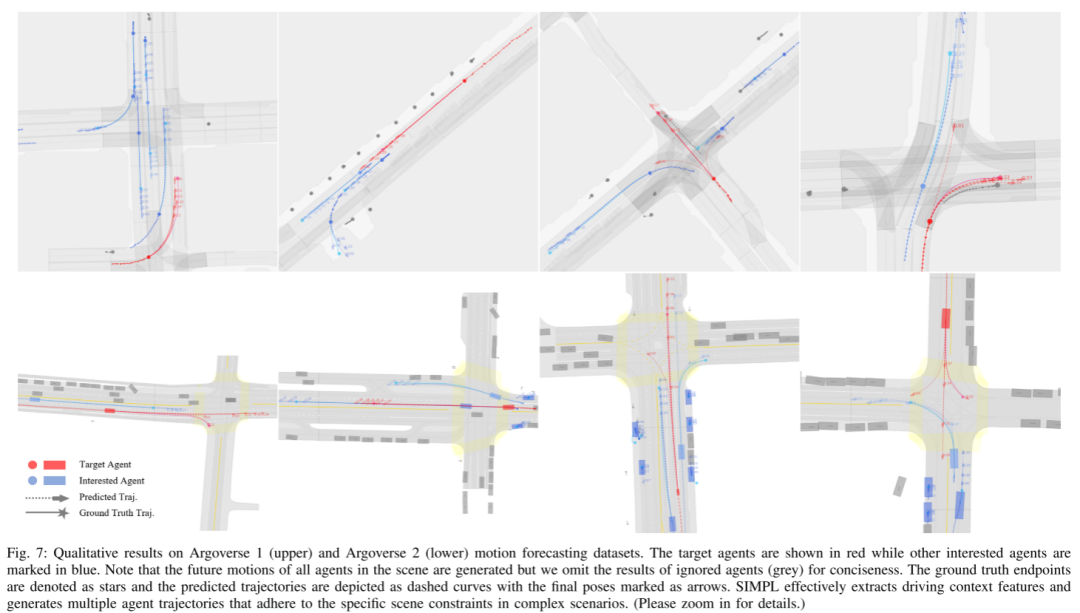
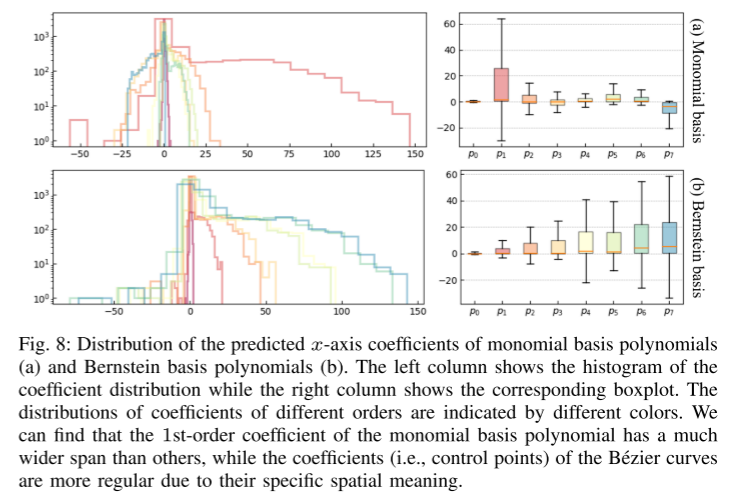
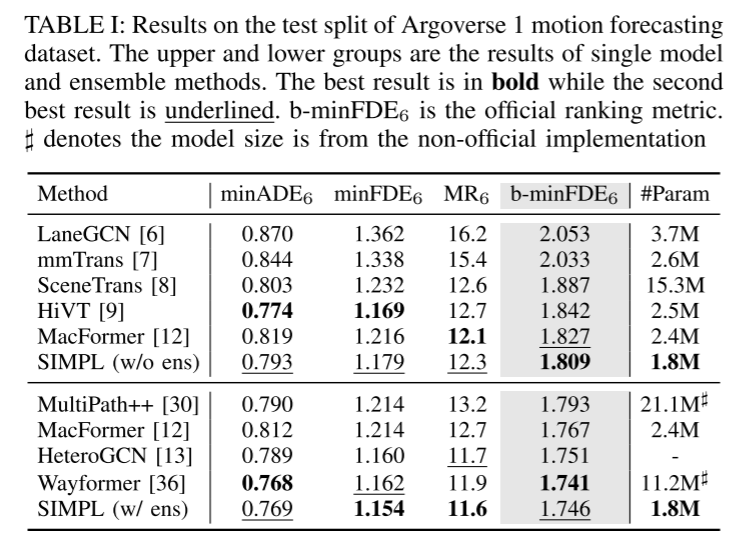
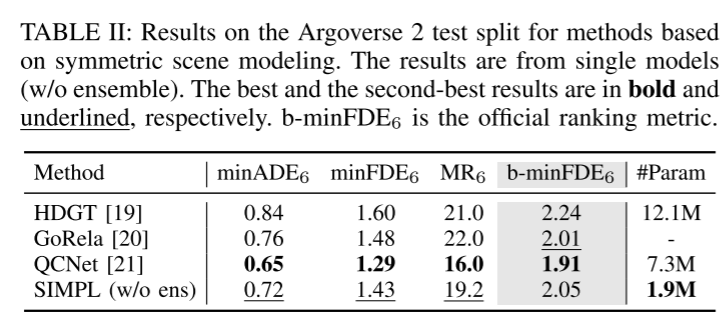
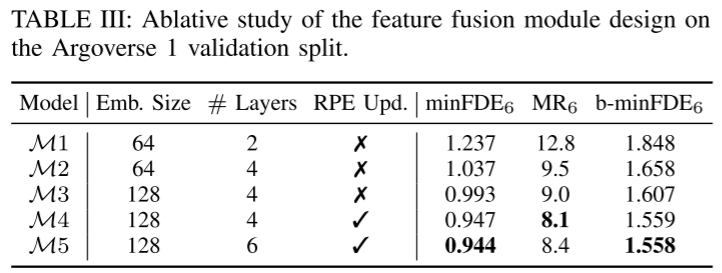
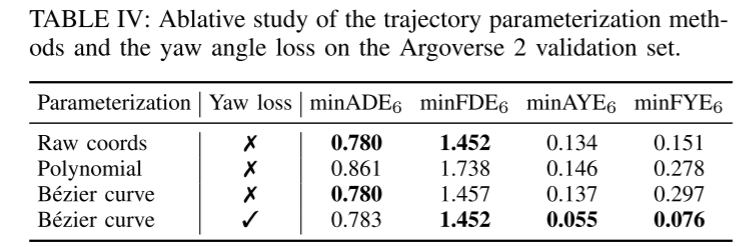
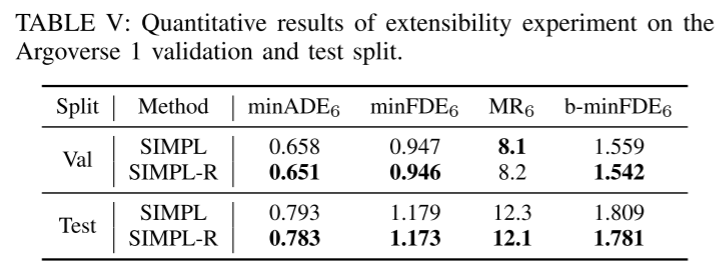
Résumé :
Cet article propose une conduite autonome simple et efficace multi- Objectif Base de référence pour la prédiction du mouvement des agents. En utilisant le transformateur de fusion symétrique proposé, la méthode proposée permet une fusion globale efficace des caractéristiques et maintient la robustesse contre le mouvement du point de vue. Le paramétrage de trajectoire continue basé sur les polynômes de base de Bernstein offre une meilleure compatibilité avec les modules en aval. Les résultats expérimentaux sur des ensembles de données publiques à grande échelle montrent que SIMPL présente des avantages en termes de taille de modèle et de vitesse d'inférence tout en atteignant le même niveau de précision que les autres méthodes de pointe.Citation :
Zhang L, Li P, Liu S et al SIMPL : Une base de référence de prédiction de mouvement multi-agent simple et efficace pour la conduite autonome[J].Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Prédiction de contrôle pour le guidage de trajectoire en conduite autonome de bout en bout : une méthode de base simple et puissante TCP
- Façons de corriger l'erreur de réinitialisation du pilote automatique Windows 0x80070032
- Le premier robot conçu par ChatGPT est là ! [Avec les prévisions de l'industrie de l'intelligence artificielle]
- Il peut « conduire de manière autonome » sans piles, et ce robot peut avoir une autonomie illimitée.