
Maison >Périphériques technologiques >IA >À l'ère post-Sora, comment les praticiens du CV choisissent-ils leurs modèles ? Convolution ou ViT, apprentissage supervisé ou paradigme CLIP
À l'ère post-Sora, comment les praticiens du CV choisissent-ils leurs modèles ? Convolution ou ViT, apprentissage supervisé ou paradigme CLIP

- PHPzavant
- 2024-02-19 09:57:021043parcourir
La précision d'ImageNet était autrefois le principal indicateur d'évaluation des performances du modèle, mais dans le domaine de la vision informatique d'aujourd'hui, cet indicateur apparaît progressivement incomplet.
À mesure que les modèles de vision par ordinateur sont devenus plus complexes, la variété des modèles disponibles a considérablement augmenté, des ConvNets aux Transformateurs de Vision. Les méthodes de formation ont également évolué vers l'apprentissage auto-supervisé et la formation par paires image-texte comme CLIP, et ne se limitent plus à la formation supervisée sur ImageNet.
Bien que la précision d'ImageNet soit un indicateur important, elle ne suffit pas pour évaluer pleinement les performances du modèle. Différentes architectures, méthodes de formation et ensembles de données peuvent entraîner des performances différentes des modèles sur différentes tâches. Par conséquent, se fier uniquement à ImageNet pour juger les modèles peut présenter des limites. Lorsqu'un modèle surajuste l'ensemble de données ImageNet et atteint une saturation en termes de précision, la capacité de généralisation du modèle sur d'autres tâches peut être négligée. Par conséquent, plusieurs facteurs doivent être pris en compte pour évaluer les performances et l’applicabilité du modèle.
Bien que la précision ImageNet de CLIP soit similaire à celle de ResNet, son encodeur visuel est plus robuste et transférable. Cela a incité les chercheurs à explorer les avantages uniques de CLIP qui n'étaient pas évidents en considérant uniquement les métriques ImageNet. Cela souligne l’importance d’analyser d’autres propriétés pour aider à découvrir des modèles utiles.
En outre, les benchmarks traditionnels ne peuvent pas évaluer pleinement la capacité d'un modèle à gérer les défis visuels du monde réel, tels que les différents angles de caméra, les conditions d'éclairage ou les occlusions. Les modèles formés sur des ensembles de données tels qu'ImageNet ont souvent du mal à exploiter leurs performances dans des applications pratiques, car les conditions et les scénarios du monde réel sont plus diversifiés.
Ces questions ont apporté une nouvelle confusion aux praticiens du domaine : Comment mesurer un modèle visuel ? Et comment choisir un modèle visuel adapté à vos besoins ?
Dans un article récent, des chercheurs de MBZUAI et Meta ont mené une discussion approfondie sur cette question.

- Titre de l'article : ConvNet vs Transformer, Supervised vs CLIP : Au-delà de la précision d'ImageNet
- Lien de l'article : https://arxiv.org/pdf/2311.09215 pdf.
La recherche se concentre sur le comportement des modèles au-delà de la précision d'ImageNet, en analysant les performances des principaux modèles dans le domaine de la vision par ordinateur, notamment ConvNeXt et Vision Transformer (ViT), qui fonctionnent tous deux sous les paradigmes de formation supervisée et CLIP Performance.
Les modèles sélectionnés ont un nombre similaire de paramètres et presque la même précision sur ImageNet-1K sous chaque paradigme de formation, garantissant une comparaison équitable. Les chercheurs ont exploré en profondeur une série de caractéristiques du modèle, telles que le type d'erreur de prédiction, la capacité de généralisation, l'invariance des représentations apprises, l'étalonnage, etc., en se concentrant sur les caractéristiques du modèle sans formation supplémentaire ni réglage fin, dans l'espoir de directement fournir des références. par des praticiens utilisant des modèles pré-entraînés.
Dans l'analyse, les chercheurs ont découvert qu'il existe de grandes différences dans le comportement des modèles entre les différentes architectures et paradigmes de formation. Par exemple, les modèles formés sous le paradigme CLIP ont produit moins d'erreurs de classification que ceux formés sur ImageNet. Cependant, le modèle supervisé est mieux calibré et surpasse généralement le benchmark de robustesse ImageNet. ConvNeXt présente des avantages sur les données synthétiques, mais est plus orienté texture que ViT. Pendant ce temps, ConvNeXt supervisé fonctionne bien sur de nombreux benchmarks, avec des performances de transférabilité comparables à celles du modèle CLIP.
On peut constater que différents modèles démontrent leurs avantages de manière unique, et ces avantages ne peuvent pas être capturés par un seul indicateur. Les chercheurs soulignent que des mesures d'évaluation plus détaillées sont nécessaires pour sélectionner avec précision les modèles dans des contextes spécifiques et pour créer de nouveaux points de référence indépendants d'ImageNet.
Sur la base de ces observations, Yann LeCun, scientifique en chef de Meta AI, a retweeté l'étude et l'a aimée :

Sélection du modèle
Pour le modèle supervisé, les chercheurs ont utilisé le DeiT3-Base/16 pré-entraîné de ViT, qui a la même architecture que ViT-Base/16, mais la méthode d'entraînement a en outre été améliorée, ConvNeXt ; -La base a été utilisée. Pour le modèle CLIP, les chercheurs ont utilisé les encodeurs visuels de ViT-Base/16 et ConvNeXt-Base dans OpenCLIP.
Veuillez noter que les performances de ces modèles sont légèrement différentes de celles du modèle OpenAI d'origine. Tous les points de contrôle du modèle peuvent être trouvés sur la page d'accueil du projet GitHub. La comparaison détaillée des modèles est présentée dans le tableau 1 :

Pour le processus de sélection du modèle, le chercheur a donné une explication détaillée :
1 Étant donné que le chercheur utilise un modèle pré-entraîné, il ne peut pas contrôler le modèle. période de formation. La quantité et la qualité des échantillons de données consultés.
2. Pour analyser les ConvNets et les Transformers, de nombreuses études antérieures ont comparé ResNet et ViT. Cette comparaison n'est généralement pas propice à ConvNet, car ViT est généralement formé avec des recettes plus avancées et atteint une plus grande précision ImageNet. ViT comporte également certains éléments de conception architecturale, tels que LayerNorm, qui n'étaient pas intégrés à ResNet lors de son invention il y a de nombreuses années. Par conséquent, pour une évaluation plus équilibrée, nous avons comparé ViT avec ConvNeXt, un représentant moderne de ConvNet qui fonctionne à égalité avec Transformers et partage de nombreuses conceptions.
3. En termes de mode entraînement, les chercheurs ont comparé le mode supervisé et le mode CLIP. Les modèles supervisés ont maintenu des performances de pointe en matière de vision par ordinateur. Les modèles CLIP, en revanche, fonctionnent bien en termes de généralisation et de transférabilité et fournissent des propriétés permettant de connecter les représentations visuelles et linguistiques.
4. Étant donné que le modèle auto-supervisé a montré un comportement similaire à celui du modèle supervisé lors des tests préliminaires, il n'a pas été inclus dans les résultats. Cela peut être dû au fait qu’ils ont fini par être supervisés et peaufinés sur ImageNet-1K, ce qui affecte l’étude de nombreuses fonctionnalités.
Ensuite, examinons comment les chercheurs ont analysé différents attributs.
Analyse
Erreur de modèle
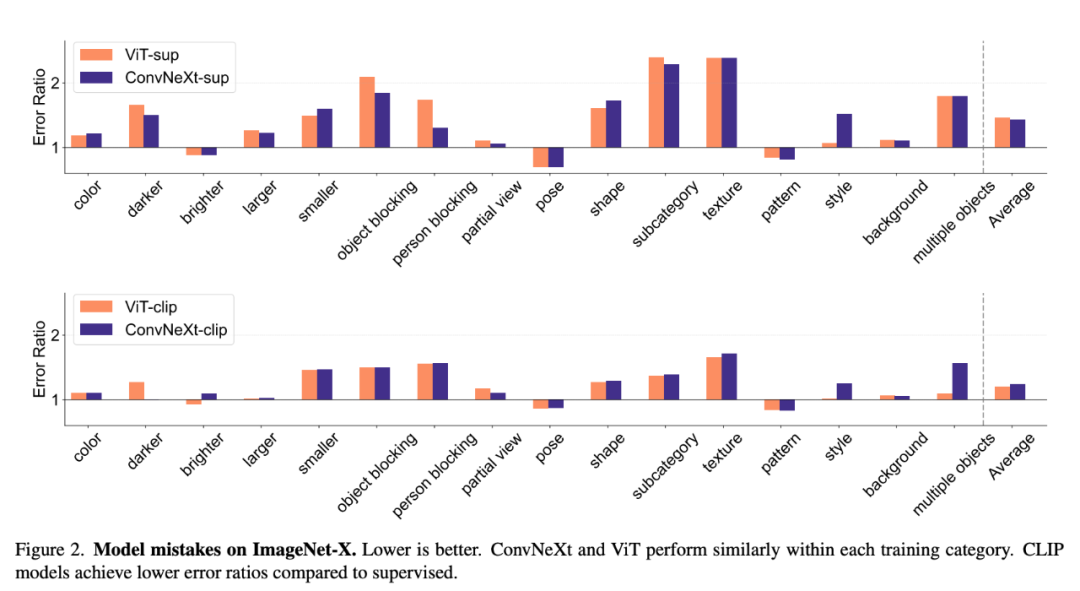
ImageNet-X est un ensemble de données qui étend ImageNet-1K et contient des annotations humaines détaillées de 16 facteurs changeants pour classer les images Effectuer une analyse approfondie des erreurs de modèle dans . Il utilise une mesure du taux d'erreur (le plus faible est le mieux) pour quantifier les performances d'un modèle sur des facteurs spécifiques par rapport à la précision globale, permettant une analyse nuancée des erreurs du modèle. Les résultats sur ImageNet-X montrent :
1. Par rapport aux modèles supervisés, les modèles CLIP font moins d'erreurs dans la précision d'ImageNet.
2. Tous les modèles sont principalement affectés par des facteurs complexes tels que l'occlusion.
3. La texture est le facteur le plus difficile de tous les modèles.
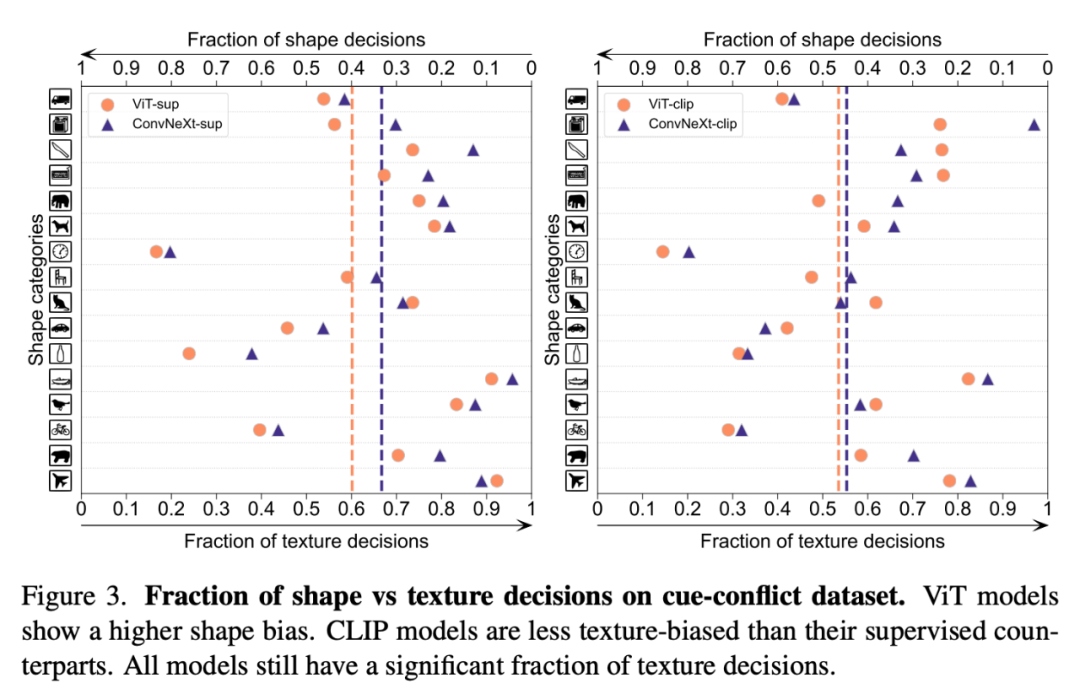
Biais de forme/texture
Le biais de forme-texture détecte si un modèle s'appuie sur des raccourcis de texture fragiles au lieu d'indices de forme de haut niveau. Ce biais peut être étudié en combinant des images contradictoires de différentes catégories de forme et de texture. Cette approche permet de comprendre dans quelle mesure les décisions d'un modèle sont basées sur la forme par rapport à la texture. Les chercheurs ont évalué le biais de forme-texture sur l'ensemble de données de conflit de signaux et ont constaté que le biais de texture du modèle CLIP était inférieur à celui du modèle supervisé, tandis que le biais de forme du modèle ViT était supérieur à celui des ConvNets.
Calibrage du modèle
Le calibrage peut quantifier si la confiance de prédiction du modèle est cohérente avec sa précision réelle, qui peut être mesurée au moyen d'indicateurs tels que l'erreur d'étalonnage attendue (ECE), ainsi que tracés de fiabilité et histogrammes de confiance. Outils visuels pour l’évaluation. L'étalonnage a été évalué sur ImageNet-1K et ImageNet-R, classant les prédictions en 15 niveaux. Au cours de l'expérience, les chercheurs ont observé les points suivants :
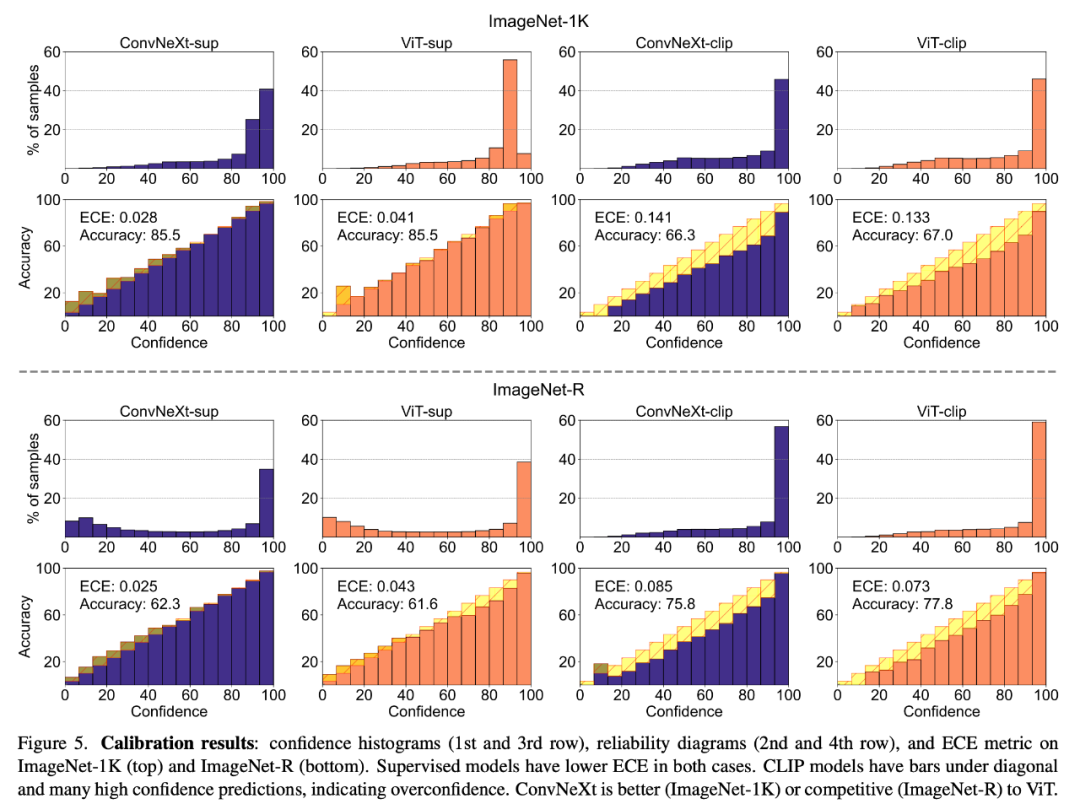
1. Le modèle CLIP est trop confiant, tandis que le modèle supervisé est légèrement sous-confiant.
2. Supervised ConvNeXt effectue un meilleur étalonnage que Supervised ViT.
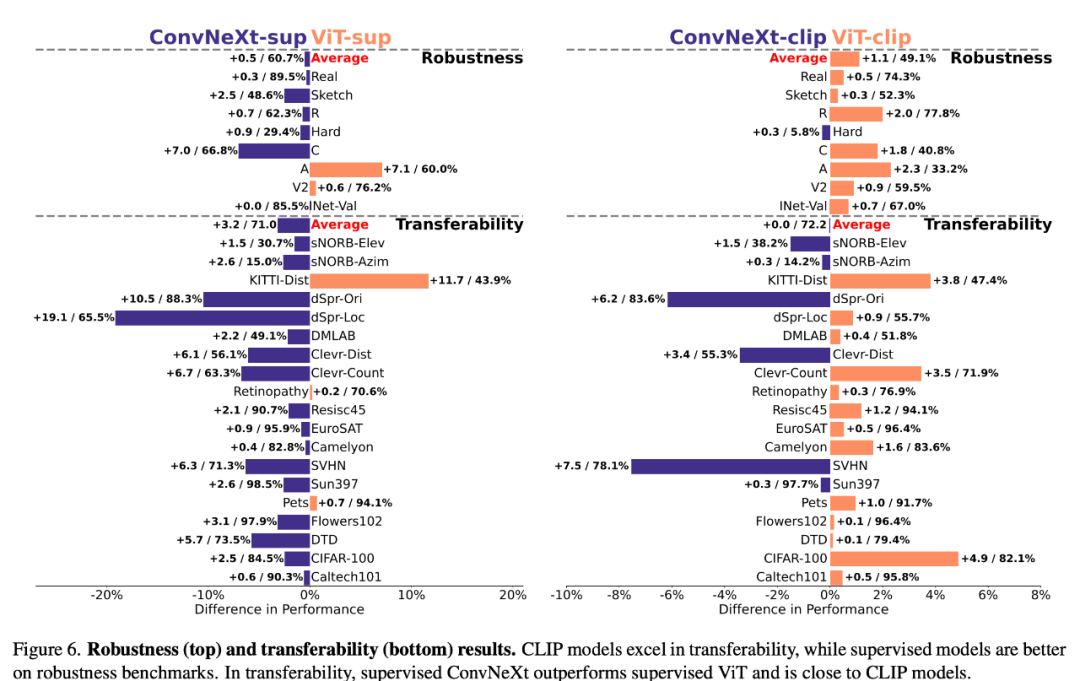
Robustesse et transférabilité
La robustesse et la transférabilité des modèles sont cruciales pour s'adapter aux changements dans la distribution des données et aux nouvelles tâches. Les chercheurs ont évalué la robustesse à l'aide de diverses variantes d'ImageNet et ont constaté que même si les performances moyennes des modèles ViT et ConvNeXt étaient comparables, à l'exception d'ImageNet-R et ImageNet-Sketch, les modèles supervisés surpassaient généralement CLIP en termes de robustesse. En termes de transférabilité, ConvNeXt supervisé surpasse ViT et est presque à égalité avec les performances du modèle CLIP, telles qu'évaluées sur le benchmark VTAB à l'aide de 19 ensembles de données.
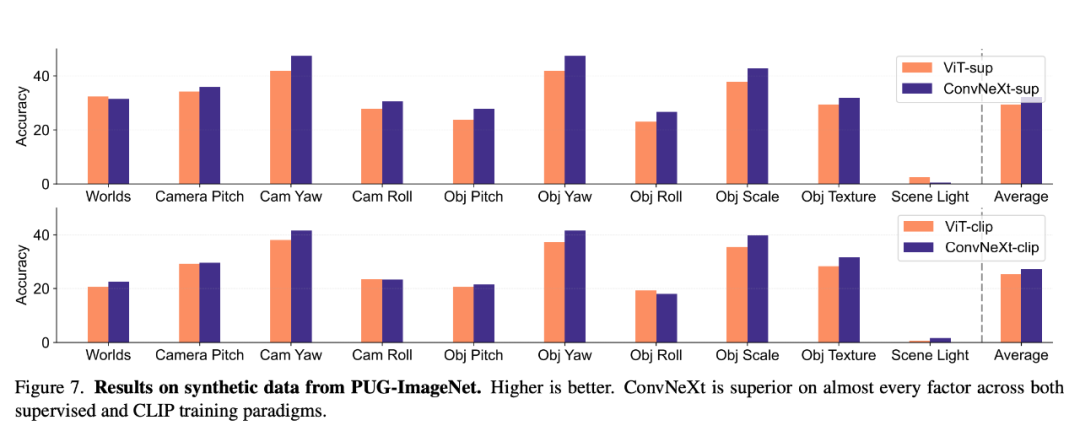
Données synthétiques
PUG-ImageNet et d'autres ensembles de données synthétiques peuvent contrôler avec précision des facteurs tels que l'angle et la texture de la caméra. Il s'agit d'une voie de recherche prometteuse, les chercheurs ont donc analysé l'utilisation du modèle en synthèse. Performances sur les données. PUG-ImageNet contient des images ImageNet photoréalistes avec une variation systématique de facteurs tels que la pose et l'éclairage, et les performances sont mesurées avec une précision absolue de premier ordre. Les chercheurs fournissent des résultats sur différents facteurs dans PUG-ImageNet et constatent que ConvNeXt surpasse ViT dans presque tous les facteurs. Cela montre que ConvNeXt surpasse ViT sur les données synthétiques, tandis que l'écart pour le modèle CLIP est plus petit car la précision du modèle CLIP est inférieure à celle du modèle supervisé, ce qui peut être lié à la précision moindre de l'ImageNet d'origine. L'invariance de transformation fait référence à la capacité du modèle à produire des représentations cohérentes qui ne sont pas affectées par les transformations d'entrée telles que la mise à l'échelle ou le mouvement, conservant ainsi la sémantique. Cette propriété permet au modèle de bien se généraliser sur des entrées différentes mais sémantiquement similaires. Les méthodes utilisées incluent le redimensionnement des images pour l'invariance d'échelle, le déplacement des cultures pour l'invariance de position et l'ajustement de la résolution des modèles ViT à l'aide d'intégrations positionnelles interpolées.
 Ils ont évalué l'invariance de l'échelle, du mouvement et de la résolution sur ImageNet-1K en faisant varier l'échelle/la position du recadrage et la résolution de l'image. ConvNeXt surpasse ViT en matière de formation supervisée. Globalement, le modèle est plus robuste aux transformations d’échelle/résolution qu’aux mouvements. Pour les applications qui nécessitent une grande robustesse en matière de mise à l’échelle, de déplacement et de résolution, les résultats suggèrent que ConvNeXt supervisé peut être le meilleur choix.
Ils ont évalué l'invariance de l'échelle, du mouvement et de la résolution sur ImageNet-1K en faisant varier l'échelle/la position du recadrage et la résolution de l'image. ConvNeXt surpasse ViT en matière de formation supervisée. Globalement, le modèle est plus robuste aux transformations d’échelle/résolution qu’aux mouvements. Pour les applications qui nécessitent une grande robustesse en matière de mise à l’échelle, de déplacement et de résolution, les résultats suggèrent que ConvNeXt supervisé peut être le meilleur choix.
Résumé
Dans l'ensemble, chaque modèle a ses propres avantages uniques. Cela suggère que le choix du modèle devrait dépendre du cas d’utilisation cible, car les mesures de performances standard peuvent ignorer les nuances critiques d’une tâche spécifique. De plus, de nombreux benchmarks existants sont dérivés d'ImageNet, ce qui biaise également l'évaluation. Le développement de nouveaux benchmarks avec différentes distributions de données est crucial pour évaluer les modèles dans un environnement plus représentatif du monde réel.
Ce qui suit est un résumé des conclusions de cet article :

ConvNet avec Transformer
1. Supervised ConvNeXt surpasse le ViT supervisé sur de nombreux benchmarks : il est mieux calibré, il est plus invariant à. transformations de données et présente une meilleure portabilité et robustesse.
2. ConvNeXt fonctionne mieux que ViT sur les données synthétiques.
3. ViT a un écart de forme plus important.
Supervision vs CLIP
1 Bien que le modèle CLIP soit supérieur en termes de transférabilité, ConvNeXt supervisé est performant dans cette tâche. Cela démontre le potentiel des modèles supervisés.
2. Les modèles supervisés fonctionnent mieux sur les tests de robustesse, probablement parce que ces modèles sont tous des variantes d'ImageNet.
3. Le modèle CLIP présente un plus grand biais de forme et moins d'erreurs de classification par rapport à la précision d'ImageNet.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Appréciation des graphiques d'animation HTML5 et du texte sur 8 effets visuels 3D
- Dans le modèle de référence ISO/OSI, quelles sont les principales fonctions de la couche réseau ?
- Classification des images de vision par ordinateur
- Une brève analyse de la voie technologique de perception visuelle pour la conduite autonome
- Utilisez JavaScript pour créer et afficher des modèles 3D et des effets visuels