L'effet est plus stable et la mise en œuvre est plus simple.
Le succès des grands modèles de langage (LLM) est indissociable de « l'apprentissage par renforcement basé sur le feedback humain (RLHF) ». Le RLHF peut être grossièrement divisé en deux étapes. Premièrement, étant donné une paire de comportements préférés et non préférés, un modèle de récompense est formé pour attribuer un score plus élevé au premier en classant la cible. Cette fonction de récompense est ensuite optimisée grâce à une sorte d’algorithme d’apprentissage par renforcement. Toutefois, des éléments clés du modèle de récompense peuvent avoir des effets indésirables. Des chercheurs de l'Université Carnegie Mellon (CMU) et de Google Research ont proposé conjointement une nouvelle méthode RLHF simple, théoriquement rigoureuse et expérimentalement efficace : l'optimisation des préférences de jeu automatique (optimisation des préférences de jeu personnel (SPO). Cette approche élimine les modèles de récompense et ne nécessite pas de formation contradictoire. 
Article : Une approche minimaximaliste de l'apprentissage par renforcement à partir de la rétroaction humaineAdresse de l'article : https://arxiv.org/abs/2401.04056Introduction à la méthode SPO Le les méthodes comprennent principalement deux aspects. Premièrement, cette étude élimine véritablement le modèle de récompense en construisant le RLHF comme un jeu à somme nulle, le rendant plus capable de gérer les préférences bruyantes et non markoviennes qui apparaissent souvent dans la pratique. Deuxièmement, en exploitant la symétrie du jeu, cette étude démontre qu’un seul agent peut simplement être entraîné de manière autonome, éliminant ainsi le besoin d’un entraînement contradictoire instable. En pratique, cela équivaut à échantillonner plusieurs trajectoires auprès de l'agent, à demander à l'évaluateur ou au modèle de préférence de comparer chaque paire de trajectoires et à fixer la récompense en fonction du taux de réussite de la trajectoire. SPO évite la modélisation des récompenses, les erreurs composées et la formation contradictoire. En établissant le concept de gagnant minmax à partir de la théorie du choix social, cette étude construit le RLHF comme un jeu à somme nulle à deux et exploite la symétrie de la matrice des gains du jeu pour démontrer qu'un seul agent peut être simplement entraîné contre lui-même.
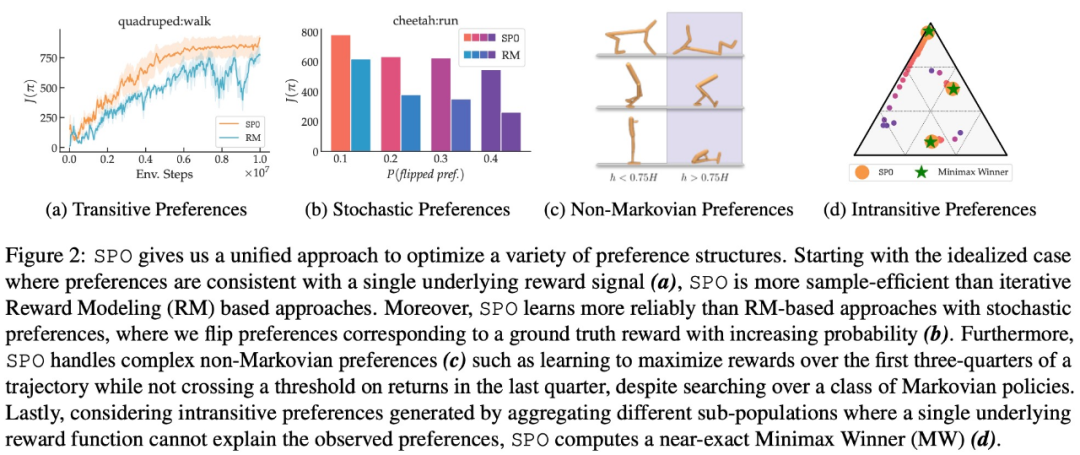
L'étude analyse également les caractéristiques de convergence de SPO et prouve que lorsque la fonction de récompense potentielle existe, SPO peut converger vers la politique optimale à une vitesse rapide comparable aux méthodes standards. Cette étude démontre que SPO fonctionne mieux que les méthodes basées sur un modèle de récompense sur une série de tâches de contrôle continu avec des fonctions de préférence réalistes. SPO est capable d'apprendre des échantillons plus efficacement que les méthodes basées sur des modèles de récompense dans divers paramètres de préférence, comme le montre la figure 2 ci-dessous.
Cette étude compare la SPO à la méthode itérative de modélisation des récompenses (RM) à partir de plusieurs dimensions, visant à répondre à 4 questions :
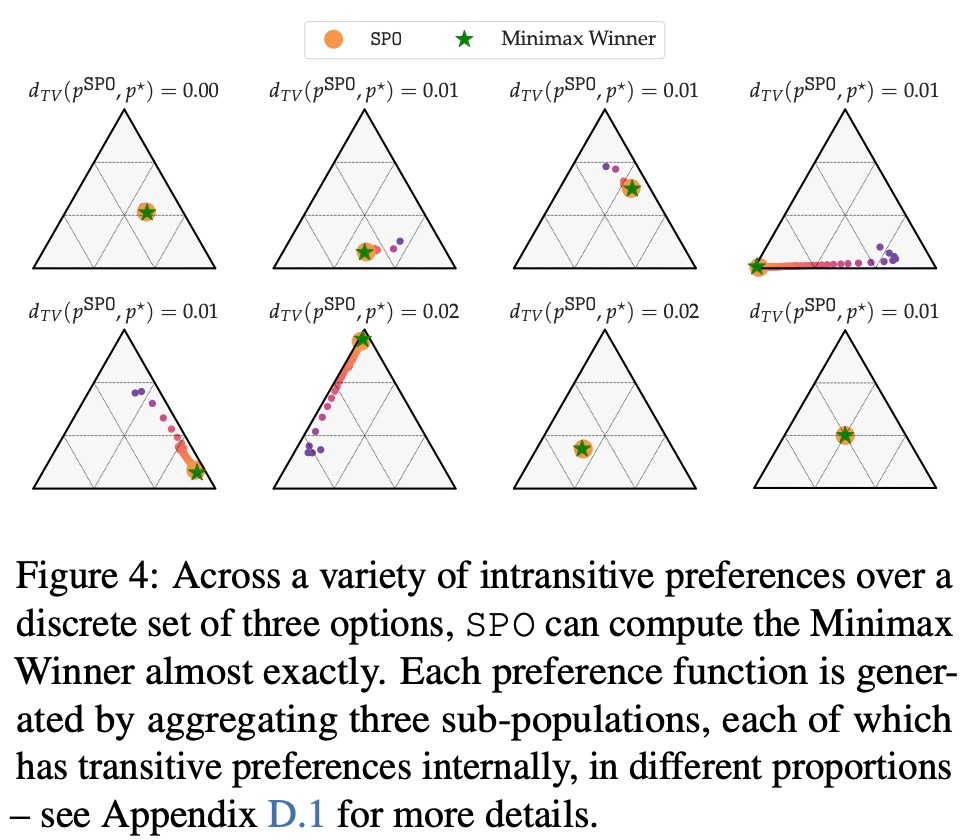
- Lorsque des préférences intransitives sont confrontées, la SPO peut-elle calculer MW ?
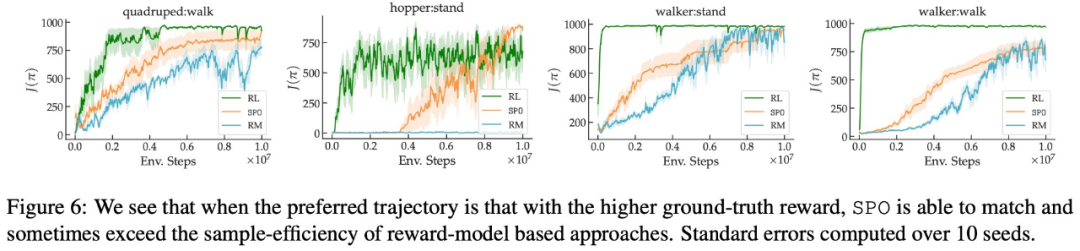
- SPO peut-il égaler ou dépasser l'efficacité de l'échantillon RM sur des problèmes avec des stratégies gagnantes/optimales uniques de Copeland ?
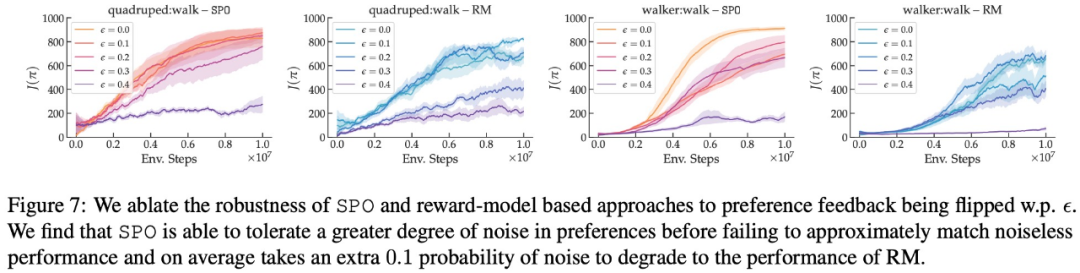
- Dans quelle mesure SPO est-il robuste aux préférences aléatoires ?
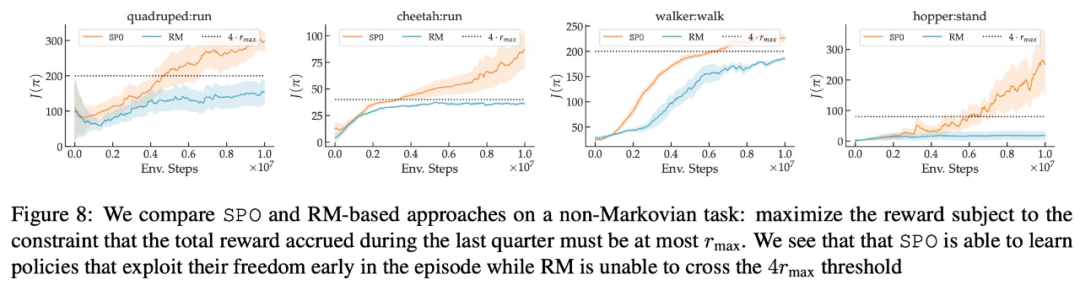
- SPO peut-il gérer les préférences non markoviennes ?
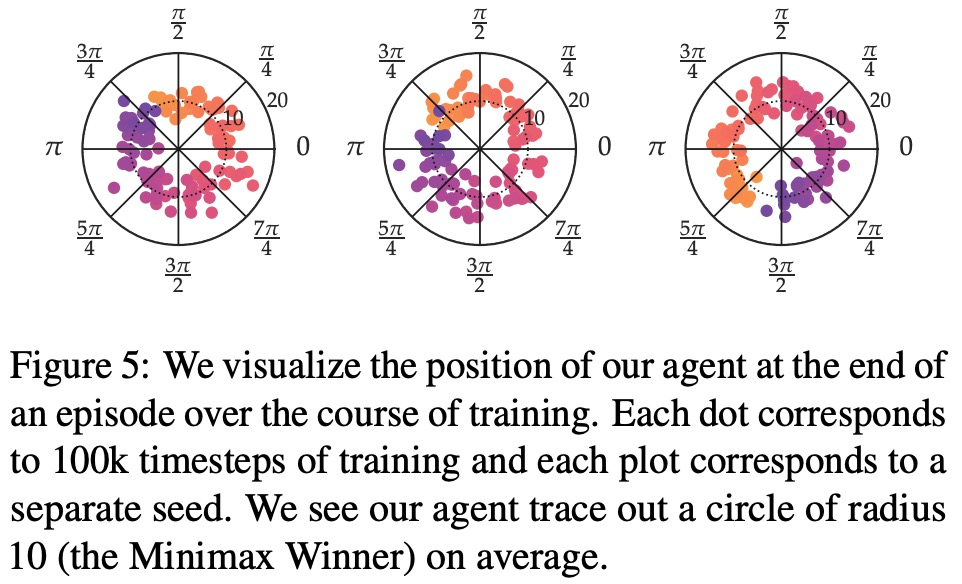
En termes de préférence de récompense maximale, de préférence de bruit et de préférence non markovienne, les résultats expérimentaux de cette étude sont présentés respectivement dans les figures 6, 7 et 8 :
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!