
Maison >Périphériques technologiques >IA >16 articles en trois ans, l'ancien chercheur scientifique de Google Yi Tay a officiellement annoncé un nouveau modèle, 21B comparable à Gemini Pro, GPT-3.5
16 articles en trois ans, l'ancien chercheur scientifique de Google Yi Tay a officiellement annoncé un nouveau modèle, 21B comparable à Gemini Pro, GPT-3.5

- 王林avant
- 2024-02-15 18:45:281356parcourir
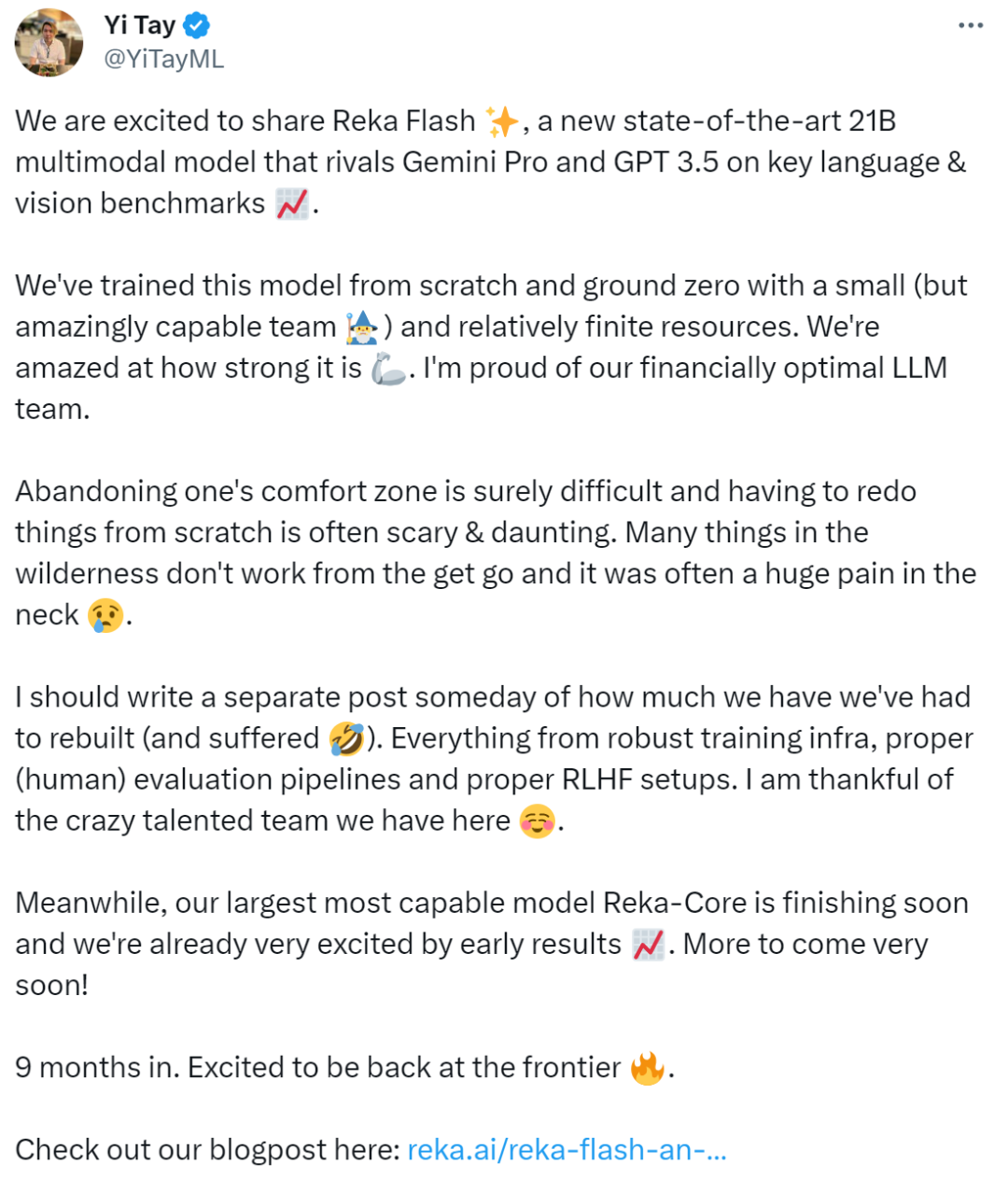
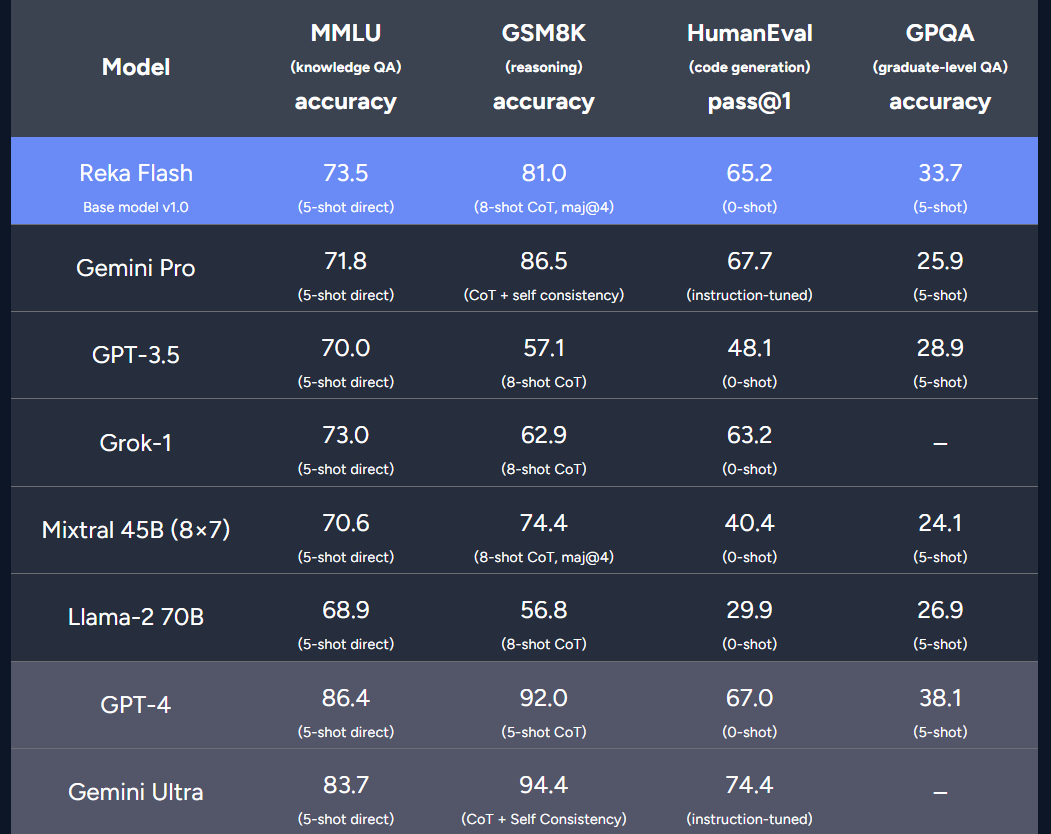
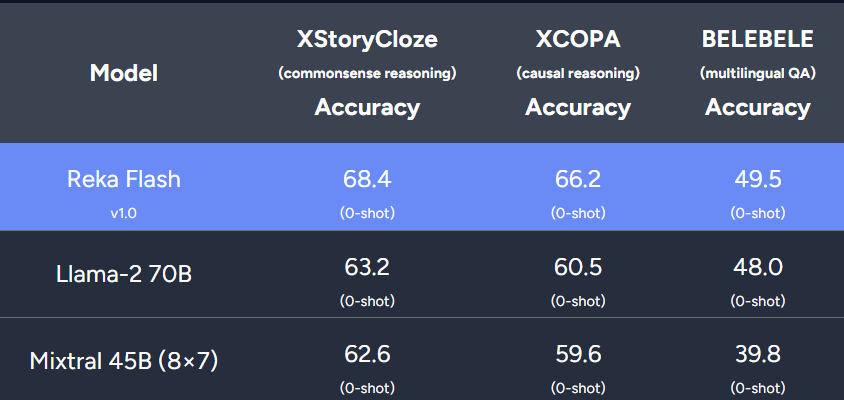
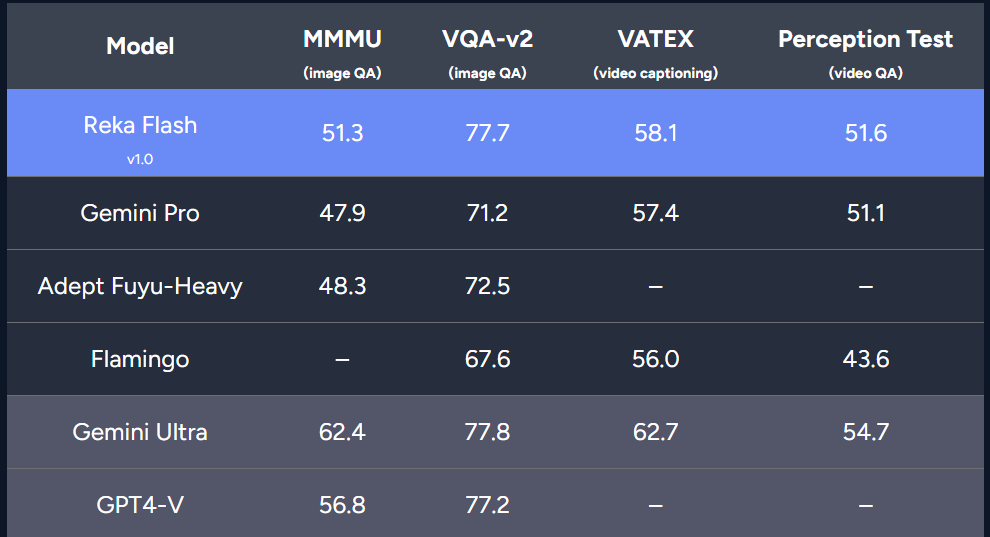
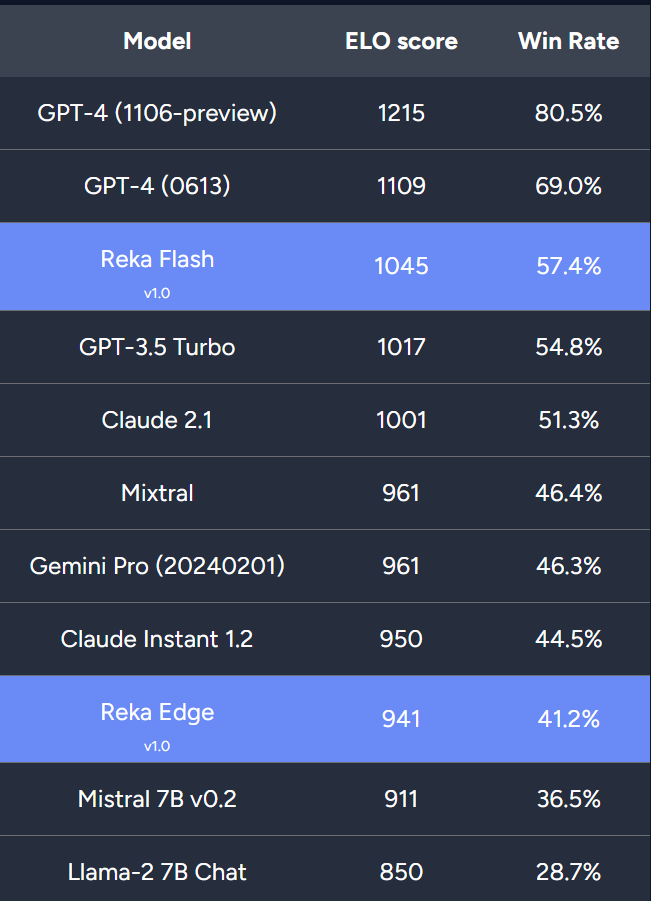
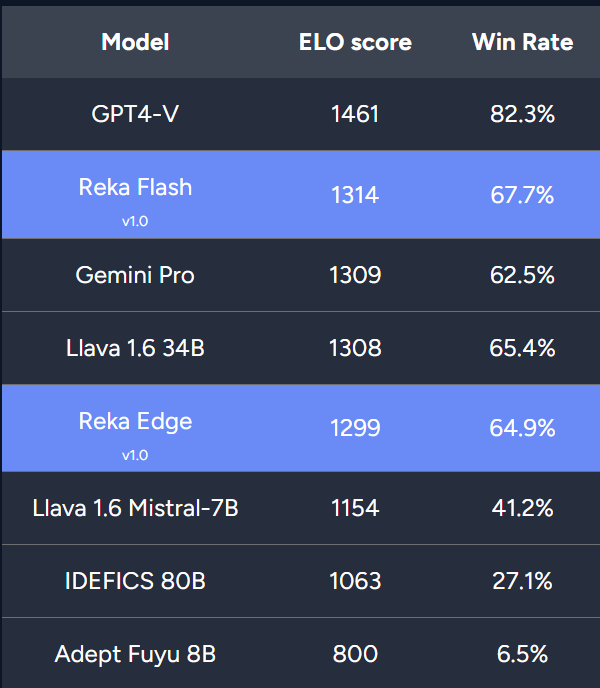
Le nouveau modèle de l'équipe est comparable à Gemini Pro et GPT-3.5 dans plusieurs benchmarks.
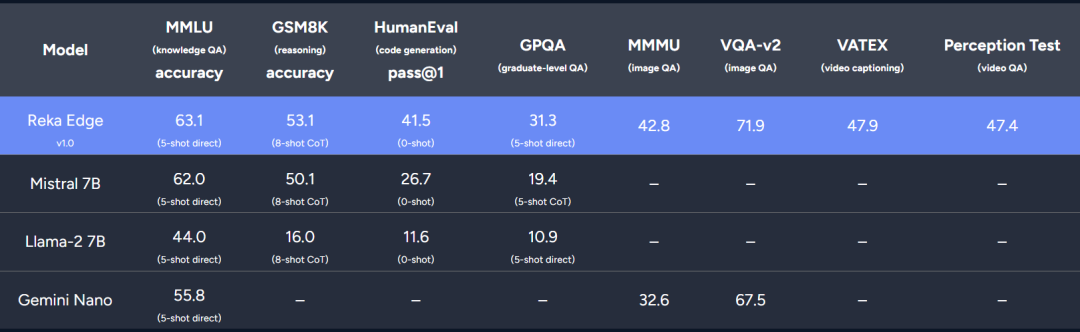
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Cet article est reproduit dans:. en cas de violation, veuillez contacter admin@php.cn Supprimer
Article précédent:ICLR 2024 | Le premier framework d'apprentissage en profondeur optimisé d'ordre zéro, MSU et LLNL proposent DeepZeroArticle suivant:ICLR 2024 | Le premier framework d'apprentissage en profondeur optimisé d'ordre zéro, MSU et LLNL proposent DeepZero
Articles Liés
Voir plus- Comment résoudre l'échec du démarrage d'Eureka avec l'intégration SpringBoot
- Pour aider au développement de l'industrie Yuanverse, ce concours d'applications innovantes de communication mobile a été lancé
- [Trend Weekly] Tendance mondiale du développement de l'industrie de l'intelligence artificielle : OpenAI a soumis une demande de marque 'GPT-5' auprès de l'Office américain des brevets
- Les normes façonnent une vie meilleure, conférence de promotion de la normalisation de l'industrie des robots et des machines-outils CNC à Suzhou
- Liu Qiang : Construire la prochaine génération d'écosystème de contenu industriel du métaverse du tourisme culturel sur Internet