
Maison >Périphériques technologiques >IA >Déployez des modèles de langage volumineux localement sur 2 Go DAYU200
Déployez des modèles de langage volumineux localement sur 2 Go DAYU200

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-07 18:20:26566parcourir

Idées et étapes de mise en œuvre
Portez le cadre d'inférence de modèle LLM léger InferLLM vers le système standard OpenHarmony et compilez un fichier binaire qui peut s'exécuter sur OpenHarmony. Ce cadre d'inférence est un cadre d'inférence CPU LLM simple et efficace qui peut déployer localement des modèles quantitatifs dans LLM.
Utilisez OpenHarmony NDK pour compiler le fichier exécutable InferLLM sur OpenHarmony (utilisez spécifiquement le framework de compilation croisée OpenHarmony lycium, puis écrivez quelques scripts. Ensuite, stockez-le dans l'entrepôt tpc_c_cplusplusSIG.)
Déployez le grand modèle de langage localement sur DAYU200
Compilez et obtenez le produit de compilation de bibliothèque tierce InferLLM
Téléchargez le sdk OpenHarmony, adresse de téléchargement :
http://ci.openharmony.cn/workbench/cicd/dailybuild/dailyList
Téléchargez cet entrepôt
git clone https://gitee.com/openharmony-sig/tpc_c_cplusplus.git --depth=1
# 设置环境变量export OHOS_SDK=解压目录/ohos-sdk/linux# 请替换为你自己的解压目录 cd lycium./build.sh InferLLM
Obtenez le fichier d'en-tête de la bibliothèque tierce InferLLM et la bibliothèque générée
InferLLM-405d866e4c11b884a8072b4b3065 9c sera généré dans le répertoire tpc_c_cplusplus/thirdparty/InferLLM/ directory 63555be41d, dans lequel a compilé une bibliothèque tierce 32 bits et 64 bits. (Les résultats de compilation pertinents ne seront pas regroupés dans le répertoire usr sous le répertoire lycium).
InferLLM-405d866e4c11b884a8072b4b30659c63555be41d/arm64-v8a-buildInferLLM-405d866e4c11b884a8072b4b30659c63555be41d/armeabi-v7a-build
Poussez les fichiers de produit et de modèle compilés vers la carte de développement pour les exécuter
- Téléchargez le fichier de modèle : https://huggingface.co/kewin4933/InferLLM-Model/tree/main
- Compilera Le fichier exécutable lama généré par InferLLM, libc++_shared.so dans le SDK OpenHarmony, et le fichier modèle téléchargé chinois-alpaca-7b-q4.bin sont regroupés dans le dossier llama_file
# 将llama_file文件夹发送到开发板data目录hdc file send llama_file /data
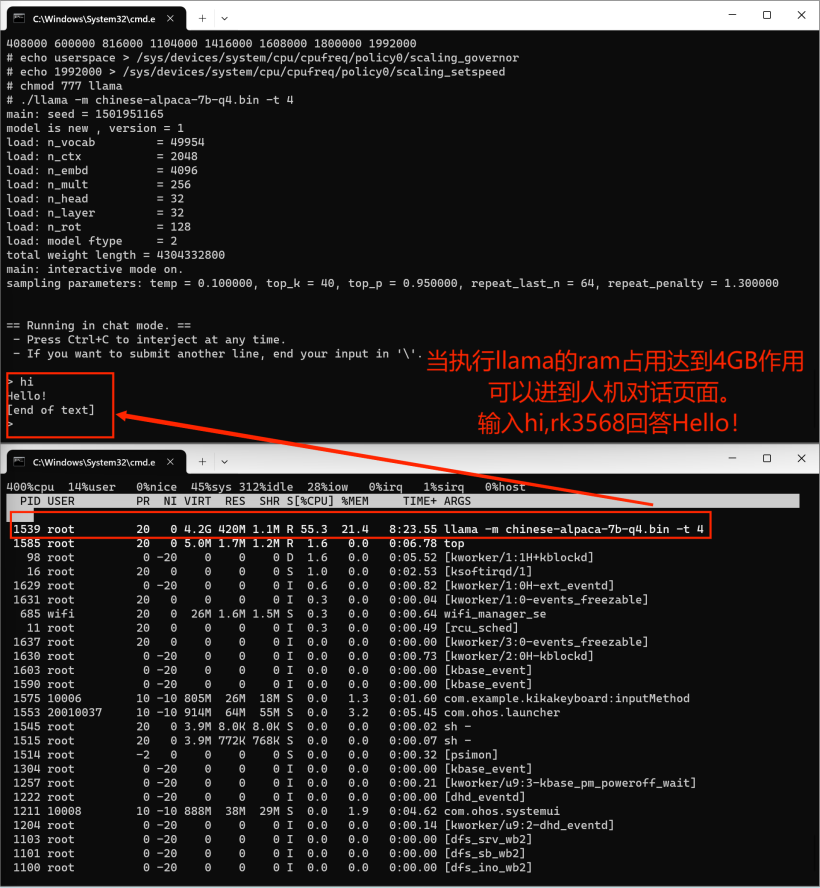
# hdc shell 进入开发板执行cd data/llama_file# 在2GB的dayu200上加swap交换空间# 新建一个空的ram_ohos文件touch ram_ohos# 创建一个用于交换空间的文件(8GB大小的交换文件)fallocate -l 8G /data/ram_ohos# 设置文件权限,以确保所有用户可以读写该文件:chmod 777 /data/ram_ohos# 将文件设置为交换空间:mkswap /data/ram_ohos# 启用交换空间:swapon /data/ram_ohos# 设置库搜索路径export LD_LIBRARY_PATH=/data/llama_file:$LD_LIBRARY_PATH# 提升rk3568cpu频率# 查看 CPU 频率cat /sys/devices/system/cpu/cpu*/cpufreq/cpuinfo_cur_freq# 查看 CPU 可用频率(不同平台显示的可用频率会有所不同)cat /sys/devices/system/cpu/cpufreq/policy0/scaling_available_frequencies# 将 CPU 调频模式切换为用户空间模式,这意味着用户程序可以手动控制 CPU 的工作频率,而不是由系统自动管理。这样可以提供更大的灵活性和定制性,但需要注意合理调整频率以保持系统稳定性和性能。echo userspace > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor# 设置rk3568 CPU 频率为1.9GHzecho 1992000 > /sys/devices/system/cpu/cpufreq/policy0/scaling_setspeed# 执行大语言模型chmod 777 llama./llama -m chinese-alpaca-7b-q4.bin -t 4
pour la transplantation La bibliothèque tierce InferLLM déploie un grand modèle de langage sur le périphérique OpenHarmmony rk3568 pour réaliser le dialogue homme-machine. L'effet d'exécution final est un peu lent et la fenêtre contextuelle de la boîte de dialogue homme-machine est également un peu lente. Veuillez patienter.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Hongmeng est-il un système d'exploitation ?
- L'UC Berkeley publie un classement des grands modèles de langage ! Vicuna a remporté le championnat et Tsinghua ChatGLM s'est classé parmi les 5 premiers.
- Test urgent de modèle en langue chinoise : SenseTime, Shanghai AI Lab et d'autres ont récemment publié 'Scholar·Puyu'
- Quelles sont les fonctions de Hongmeng OS3.0 ?
- Wang Haifeng, CTO de Baidu : Le nombre de développeurs Flying Paddle a atteint 8 millions et les grands modèles de langage annoncent l'aube de l'intelligence artificielle générale