
Maison >Périphériques technologiques >IA >L'UC Berkeley publie un classement des grands modèles de langage ! Vicuna a remporté le championnat et Tsinghua ChatGLM s'est classé parmi les 5 premiers.
L'UC Berkeley publie un classement des grands modèles de langage ! Vicuna a remporté le championnat et Tsinghua ChatGLM s'est classé parmi les 5 premiers.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-04 23:04:091636parcourir
Récemment, des chercheurs de LMSYS Org (dirigés par l'UC Berkeley) ont fait une autre grande nouvelle : le grand concours de classement des versions de modèles de langage !
Comme son nom l'indique, le "LLM Ranking" permet à un groupe de grands modèles de langage de mener des batailles au hasard et de les classer en fonction de leurs scores Elo.
Nous pouvons alors savoir d'un seul coup d'œil si un certain chatbot est le "Roi de la bouche la plus forte" ou le "Roi le plus fort".
Point clé : L'équipe prévoit également de faire venir tous ces modèles « source fermée » en provenance de pays nationaux et étrangers. Vous saurez s'il s'agit de mulets ou de chevaux ! (GPT-3.5 est maintenant dans l'arène anonyme)

L'arène des chatbots anonymes ressemble à ceci :
Évidemment, le modèle B a répondu correctement et a gagné la partie et le modèle A n'a même pas répondu ; comprendre la question...
Adresse du projet : https://arena.lmsys.org/
Dans le classement actuel, Vicuna avec 13 milliards de paramètres Elle s'est classée première avec un score sur 1 169, Koala, qui possédait également 13 milliards de paramètres, s'est classé deuxième, et Open Assistant de LAION, troisième.
ChatGLM proposé par l'Université Tsinghua, bien qu'il ne dispose que de 6 milliards de paramètres, il s'est quand même classé parmi les cinq premiers, à seulement 23 points derrière Alpaca avec 13 milliards de paramètres.
En comparaison, le LLaMa original de Meta ne s'est classé que huitième (avant-dernier), tandis que StableLM de Stability AI n'a reçu que plus de 800 points, se classant premier depuis le dernier.
L'équipe a déclaré qu'elle mettrait non seulement à jour régulièrement la liste de classement, mais qu'elle optimiserait également l'algorithme et le mécanisme, et fournirait des classements plus détaillés basés sur différents types de tâches.

Actuellement, tous les codes d'évaluation et analyses de données ont été publiés.
Pull LLM dans le classement
Dans cette évaluation, l'équipe a sélectionné 9 chatbots open source actuellement bien connus.
Chaque fois qu'il y a une bataille 1v1, le système sélectionnera au hasard deux joueurs PK. Les utilisateurs doivent discuter avec les deux robots en même temps, puis décider quel chatbot est le meilleur.
Vous pouvez voir qu'il y a 4 options en bas de la page, la gauche (A) est meilleure, la droite (B) est meilleure, tout aussi bonne, ou les deux sont mauvaises.
Une fois que l'utilisateur a soumis un vote, le système affichera le nom du modèle. A ce moment, l'utilisateur peut continuer à discuter ou sélectionner un nouveau modèle pour relancer un round de bataille.
Cependant, lors de l'analyse, l'équipe n'utilisera les résultats du vote que lorsque le modèle est anonyme. Après presque une semaine de collecte de données, l'équipe a collecté un total de 4,7 000 votes anonymes valides.
Avant de commencer, l'équipe a d'abord saisi le classement possible de chaque modèle en fonction des résultats du test de référence.
Sur la base de ce classement, l'équipe laissera le modèle prioriser la sélection d'adversaires plus adaptés.
Obtenez ensuite une meilleure couverture globale du classement grâce à un échantillonnage uniforme.
À la fin des qualifications, l'équipe a présenté un nouveau modèle fastchat-t5-3b.
Les opérations ci-dessus conduisent finalement à des fréquences de modèle non uniformes.
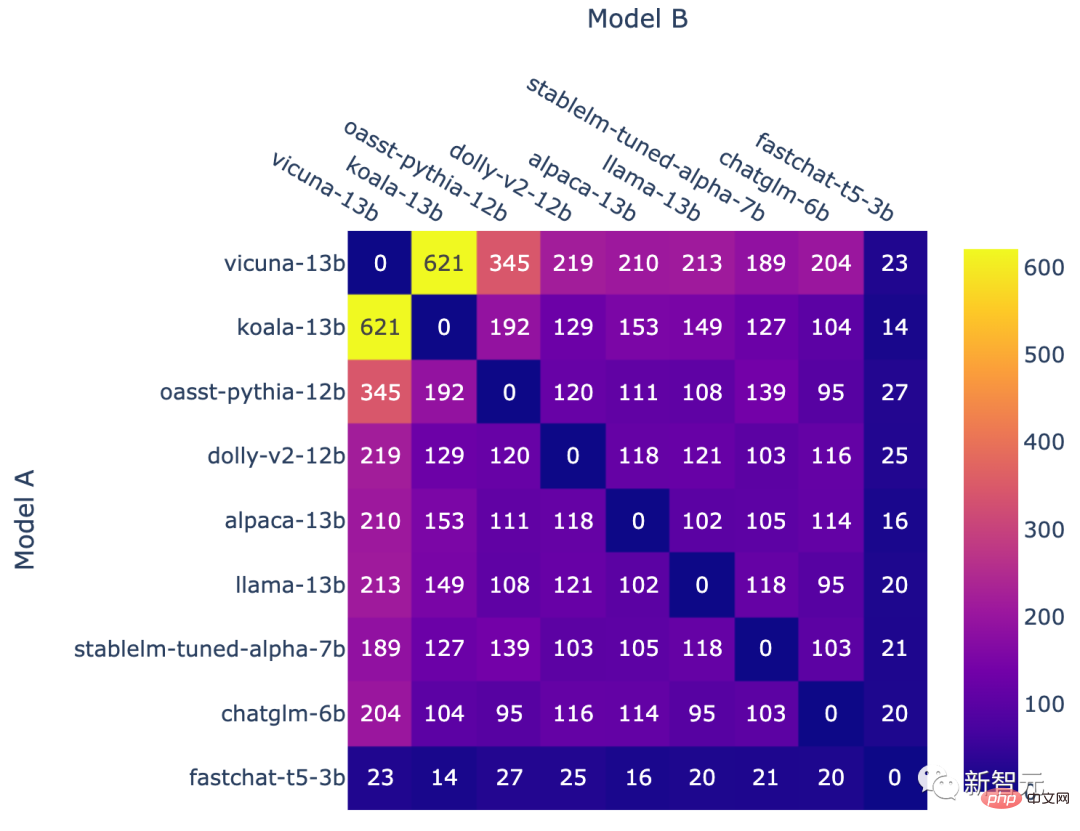
Le nombre de batailles pour chaque combinaison de modèles
D'après les données statistiques, la plupart des utilisateurs utilisent l'anglais, le chinois se classant deuxième.
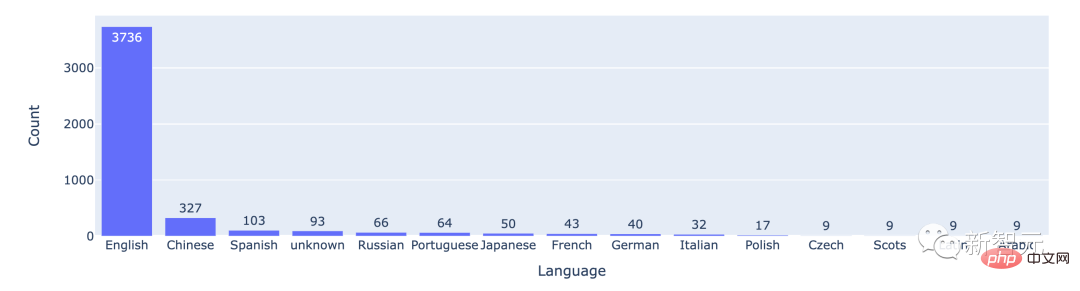
Le nombre de batailles entre les 15 meilleures langues
Évaluer le LLM est vraiment difficile
Depuis que ChatGPT est devenu populaire, de grands modèles de langage open source qui ont été peaufinés selon les instructions ont poussé comme des champignons après la pluie. On peut dire que de nouveaux LLM open source sont publiés presque chaque semaine.
Mais le problème est qu'il est très difficile d'évaluer ces grands modèles de langage.
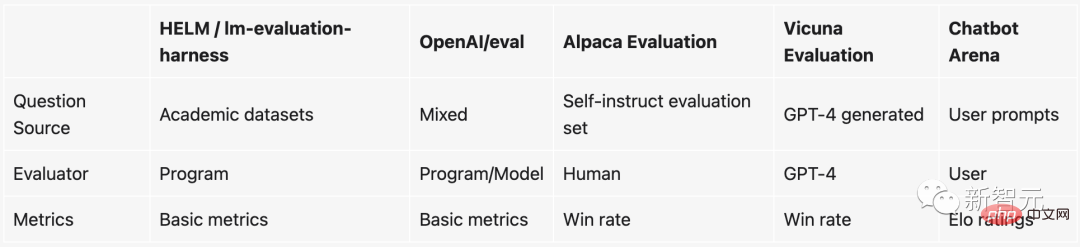
Pour être plus précis, les éléments actuellement utilisés pour mesurer la qualité d'un modèle sont essentiellement basés sur certains critères académiques, tels que la construction d'un ensemble de données de test sur une certaine tâche PNL, puis l'examen de l'exactitude des données de test. ensemble. .
Cependant, ces benchmarks académiques (comme HELM) ne sont pas faciles à utiliser sur les grands modèles et les chatbots. Les raisons sont :
1. Puisque juger si un chatbot est bon ou non est très subjectif, il est difficile de le mesurer avec les méthodes existantes.
2. Ces grands modèles scannent presque toutes les données sur Internet pendant la formation, il est donc difficile de s'assurer que l'ensemble des données de test n'a pas été vu. Même en allant plus loin, l'utilisation de l'ensemble de tests pour « entraîner spécialement » directement le modèle entraînera de meilleures performances.
3. En théorie, nous pouvons discuter de tout avec le chatbot, mais de nombreux sujets ou tâches n'existent tout simplement pas dans les benchmarks existants.
Si vous ne souhaitez pas utiliser ces références, il existe en fait une autre solution : payer quelqu'un pour évaluer le modèle.
En fait, c'est ce que fait OpenAI. Mais cette méthode est évidemment très lente, et surtout, trop coûteuse...
Afin de résoudre cet épineux problème, les équipes de l'UC Berkeley, de l'UCSD et de la CMU ont inventé un nouveau mécanisme à la fois ludique et pratique— — Arène des chatbots.
En comparaison, le système de benchmark basé sur les combats présente les avantages suivants :
- Évolutivité
Lorsque suffisamment de données ne peuvent pas être collectées pour toutes les paires de modèles potentielles, le système devrait pouvoir être étendu à autant de personnes. modèles possibles.
- Incrémentalité
Le système devrait être capable d'évaluer de nouveaux modèles en utilisant un nombre relativement restreint d'essais.
- Commande unique
Le système doit fournir une commande unique pour tous les modèles. Étant donné deux modèles, nous devrions être en mesure de déterminer lequel est le mieux classé ou s'ils sont à égalité.
Système de notation Elo
Le système de notation Elo est une méthode de calcul du niveau de compétence relatif des joueurs et est largement utilisé dans les jeux compétitifs et divers sports. Parmi eux, plus le score Elo est élevé, plus le joueur est puissant.
Par exemple, dans League of Legends, Dota 2, Chicken Fighting, etc., c'est le mécanisme par lequel le système classe les joueurs.
Par exemple, lorsque vous jouez à de nombreuses parties classées dans League of Legends, un score caché apparaîtra. Ce score caché détermine non seulement votre classement, mais détermine également que les adversaires que vous rencontrez lorsque vous jouez avec classement sont fondamentalement d'un niveau similaire.
De plus, la valeur de ce score Elo est absolue. En d'autres termes, lorsque de nouveaux chatbots seront ajoutés à l'avenir, nous pourrons toujours juger directement quel chatbot est le plus puissant grâce au score d'Elo.
Plus précisément, si la note du joueur A est Ra et celle du joueur B est Rb, la formule exacte de la probabilité de gagner du joueur A (en utilisant une courbe logistique de base 10) est :

Ensuite, les notes des joueurs sera mis à jour linéairement après chaque match.
Supposons que le joueur A (noté Ra) s'attende à obtenir des points Ea, mais qu'il ait en fait obtenu des points Sa. La formule pour mettre à jour cette note de joueur est la suivante :
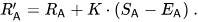
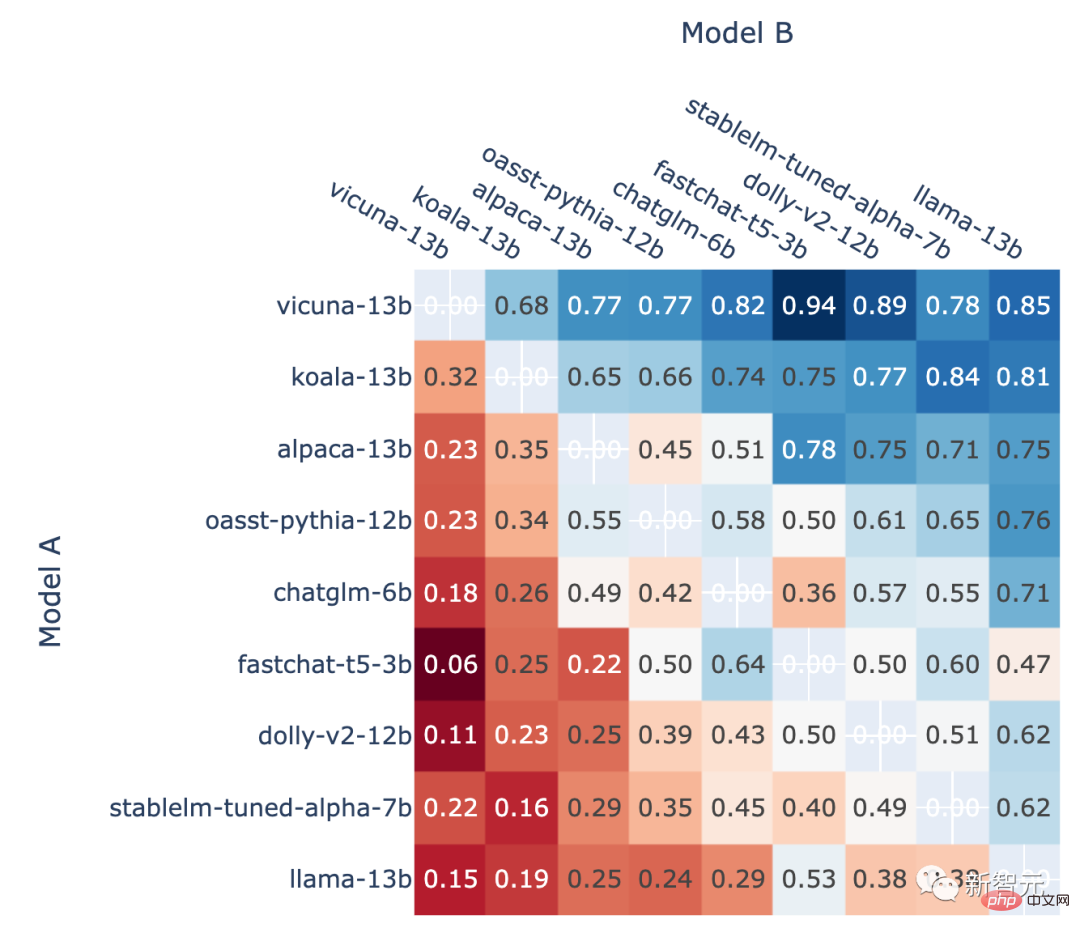
Taux de victoire 1v1
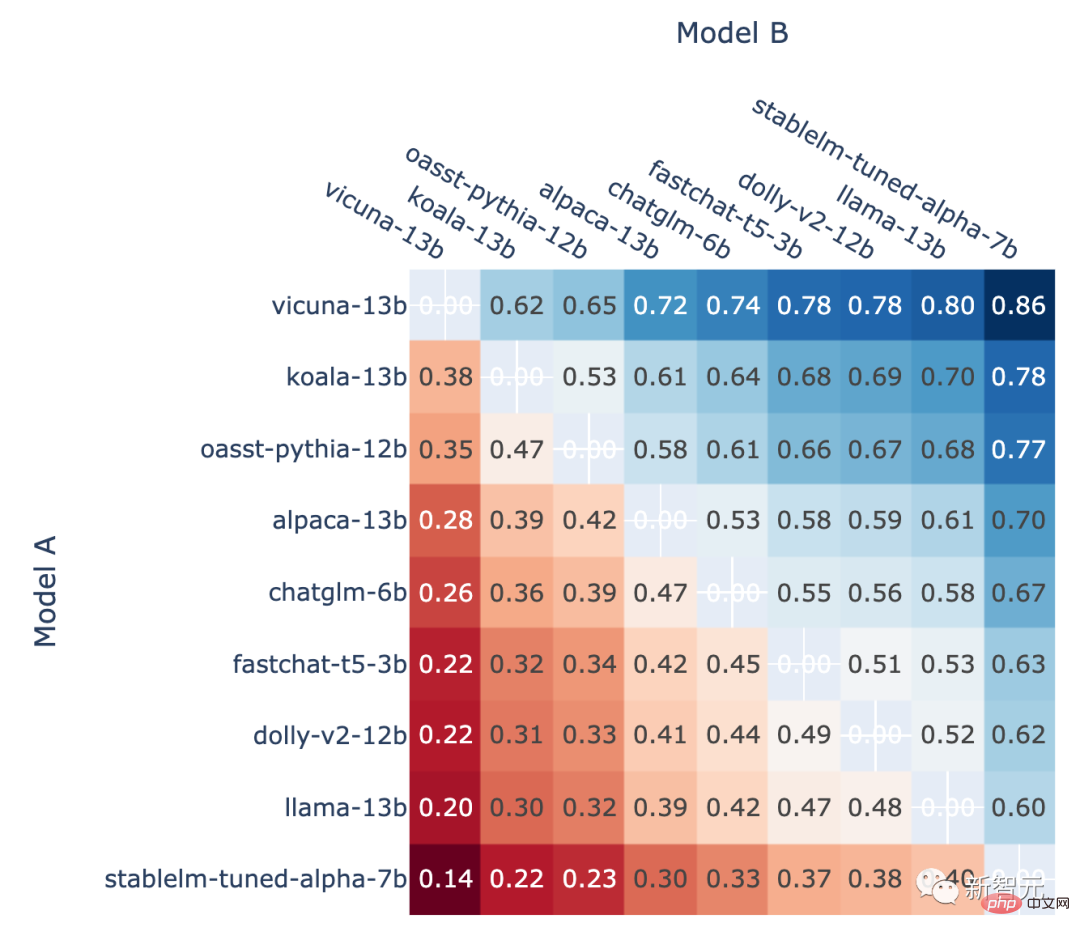
De plus, l'auteur montre également le taux de victoire en face-à-face de chaque modèle dans le jeu classé et le face-à-face prévu. taux de victoire en face-à-face estimé à l’aide de la note Elo.
Les résultats montrent que le score Elo peut en effet prédire de manière relativement précise
La proportion de victoires du modèle A dans tous les A vs. Dans la bataille contre B, le taux de victoire du modèle A prédit à l'aide du score Elo
Introduction à l'auteur
L'organisation a été fondée par Lianmin Zheng, Ph.D. de l'UC Berkeley, et Hao Zhang, professeur agrégé à l'UCSD, dans le but de rendre les grands modèles accessibles à tous en développant conjointement des ensembles de données, des modèles, des systèmes et des outils d'évaluation ouverts.
Lianmin Zheng
Lianmin Zheng est doctorant au département EECS de l'Université de Californie à Berkeley. Ses intérêts de recherche incluent les systèmes d'apprentissage automatique, les compilateurs et les systèmes distribués.
Hao Zhang est actuellement chercheur postdoctoral à l'Université de Californie à Berkeley. Il occupera le poste de professeur adjoint à l’Institut des sciences des données Halıcıoğlu et au Département d’informatique de l’UC San Diego à partir de l’automne 2023.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI