
Maison >Périphériques technologiques >IA >Recherche HKUST et MSRA : concernant la conversion d'image à image, le réglage fin est tout ce dont vous avez besoin
Recherche HKUST et MSRA : concernant la conversion d'image à image, le réglage fin est tout ce dont vous avez besoin

- 王林avant
- 2023-05-04 23:10:06987parcourir

De nombreux projets de production de contenu nécessitent la conversion de simples croquis en images réalistes, ce qui implique une traduction d'image en image, qui utilise des modèles génératifs profonds pour apprendre les conditions des images naturelles à partir d'une entrée distribuée.
Le concept de base de la conversion image en image consiste à utiliser des réseaux neuronaux pré-entraînés pour capturer des variétés d'images naturelles. La transformation d'image est similaire à la traversée du collecteur et à la localisation de points sémantiques d'entrée réalisables. Le système pré-entraîne le réseau synthétique à l’aide de nombreuses images pour fournir une sortie fiable à partir de tout échantillonnage de son espace latent. Grâce au réseau synthétique pré-entraîné, la formation en aval adapte les entrées de l’utilisateur à la représentation latente du modèle.
Au fil des années, nous avons vu de nombreuses méthodes spécifiques à des tâches atteindre le niveau SOTA, mais les solutions actuelles ont encore du mal à créer des images haute fidélité pour une utilisation dans le monde réel.

Dans un article récent, des chercheurs de l'Université des sciences et technologies de Hong Kong et de Microsoft Research Asia estiment que pour la conversion d'image en image, une pré-formation est tout ce dont vous avez besoin. Les méthodes précédentes nécessitaient une conception d'architecture spécialisée et la formation d'un modèle de transformation unique à partir de zéro, ce qui rendait difficile la génération de scènes complexes de haute qualité, en particulier lorsque les données de formation appariées sont insuffisantes.
Par conséquent, les chercheurs traitent chaque problème de traduction d'image à image comme une tâche en aval et introduisent un cadre général simple qui adopte un modèle de diffusion pré-entraîné pour s'adapter à diverses traductions d'image à image. Ils ont appelé le modèle de traduction d'image à image pré-entraîné proposé PITI (traduction d'image à image basée sur la pré-entraînement). En outre, les chercheurs ont également proposé d'utiliser la formation contradictoire pour améliorer la synthèse de texture dans la formation des modèles de diffusion, et de la combiner avec un échantillonnage guidé normalisé pour améliorer la qualité de la génération.
Enfin, les chercheurs ont mené des comparaisons empiriques approfondies sur diverses tâches sur des références difficiles telles que ADE20K, COCO-Stuff et DIODE, montrant que les images synthétisées par PITI affichent un réalisme et une fidélité sans précédent.

- Lien papier : https://arxiv.org/pdf/2205.12952.pdf
- Page d'accueil du projet : https://tengfei-wang.github.io/PITI/index.html
GAN est mort , le modèle de diffusion perdure
Au lieu d'utiliser un GAN qui fonctionne le mieux dans un domaine spécifique, l'auteur utilise un modèle de diffusion pour synthétiser une grande variété d'images. Deuxièmement, il devrait générer des images à partir de deux types de codes latents : un qui décrit la sémantique visuelle et un autre qui s'ajuste aux fluctuations de l'image. La latence sémantique de faible dimension est essentielle pour les tâches en aval. Autrement, il serait impossible de transformer l’entrée modale en un espace latent complexe. Compte tenu de cela, ils ont utilisé GLIDE, un modèle basé sur les données qui peut générer différentes images, comme préalable génératif pré-entraîné. Puisque GLIDE utilise du texte latent, il permet un espace latent sémantique.
Les méthodes basées sur la diffusion et les scores démontrent la qualité de la génération à travers les benchmarks. Sur ImageNet conditionnel aux classes, ces modèles rivalisent avec les méthodes basées sur le GAN en termes de qualité visuelle et de diversité d'échantillonnage. Récemment, des modèles de diffusion entraînés avec des appariements texte-image à grande échelle ont montré des capacités surprenantes. Un modèle de diffusion bien entraîné peut fournir un a priori génératif général pour la synthèse.
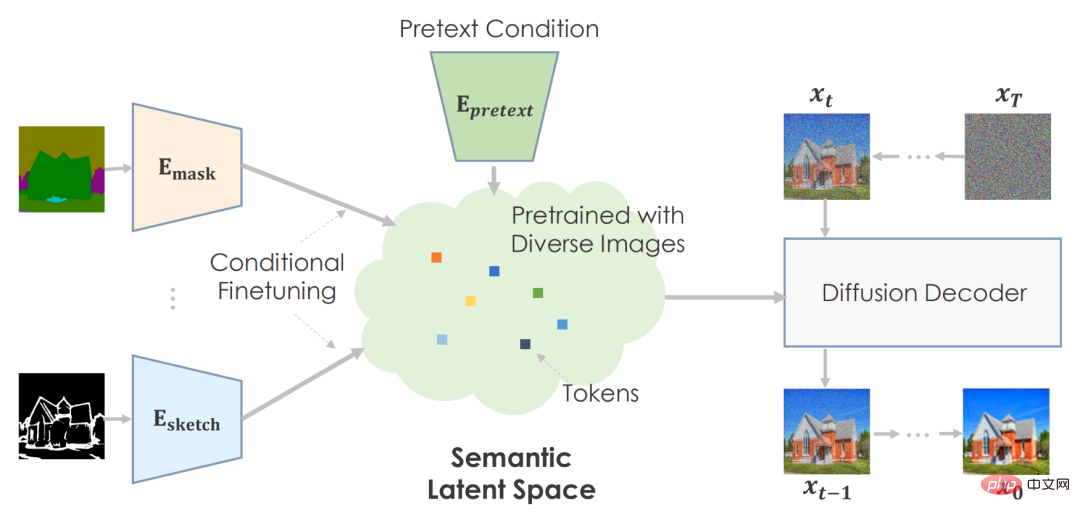
Framework
Les auteurs peuvent utiliser des tâches prétextes pour se pré-entraîner sur de grandes quantités de données et développer un espace latent très significatif pour prédire les statistiques d'images.
Pour les tâches en aval, ils affinent conditionnellement l'espace sémantique pour cartographier les environnements spécifiques aux tâches. La machine crée des visuels crédibles basés sur des informations pré-entraînées.
L'auteur recommande d'utiliser la saisie sémantique pour pré-entraîner le modèle de diffusion. Ils ont utilisé le modèle GLIDE conditionné par le texte et entraîné par l'image. Le réseau Transformer code la saisie de texte et génère des jetons pour le modèle de diffusion. Comme prévu, il est logique que le texte soit intégré dans l’espace.

La photo ci-dessus est l’œuvre de l’auteur. Les modèles pré-entraînés améliorent la qualité et la diversité des images par rapport aux techniques de zéro. Étant donné que l'ensemble de données COCO comporte de nombreuses catégories et combinaisons, l'approche de base ne peut pas fournir de beaux résultats avec une architecture convaincante. Leur méthode permet de créer des détails riches avec une sémantique précise pour les scènes difficiles. Les images illustrent la polyvalence de leur approche.
Expériences et impact
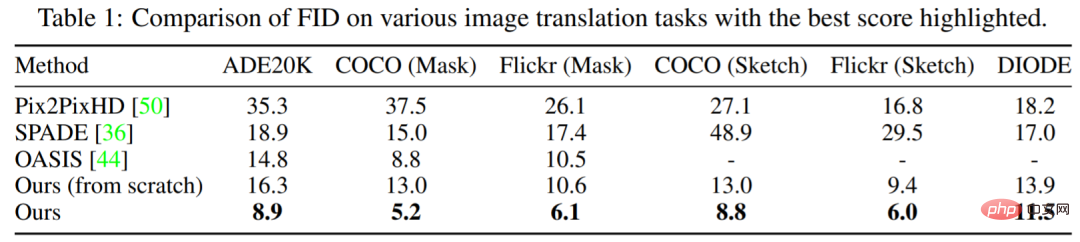
Le tableau 1 montre que les performances de la méthode proposée dans cette étude sont toujours meilleures que celles des autres modèles. Par rapport au leader OASIS, PITI réalise des améliorations significatives du FID dans la synthèse masque-image. En outre, la méthode montre également de bonnes performances dans les tâches de synthèse d’esquisse à image et de géométrie à image.
La figure 3 montre les résultats de visualisation de cette étude sur différentes tâches. Les expériences montrent que par rapport à la méthode de formation à partir de zéro, le modèle pré-entraîné améliore considérablement la qualité et la diversité des images générées. Les méthodes utilisées dans cette étude peuvent produire des détails saisissants et une sémantique correcte, même pour des tâches de génération difficiles.

Cette recherche a également mené une étude utilisateur sur la synthèse masque-image sur COCO-Stuff sur Amazon Mechanical Turk, avec 3000 votes de 20 participants. Les participants ont reçu deux images à la fois et ont été invités à voter pour laquelle était la plus réaliste. Comme le montre le tableau 2, la méthode proposée surpasse dans une large mesure le modèle à partir de zéro et les autres références.

La synthèse d'images conditionnelles crée des images de haute qualité qui répondent aux conditions. Les domaines de la vision par ordinateur et du graphisme l'utilisent pour créer et manipuler des informations. La pré-formation à grande échelle améliore la classification des images, la reconnaissance des objets et la segmentation sémantique. Ce que l’on ne sait pas, c’est si une pré-formation à grande échelle est bénéfique pour les tâches générales de génération.
La consommation d'énergie et les émissions de carbone sont des enjeux clés de la pré-formation en image. La pré-formation est gourmande en énergie, mais n'est nécessaire qu'une seule fois. Le réglage fin conditionnel permet aux tâches en aval d'utiliser le même modèle pré-entraîné. Le pré-entraînement permet d'entraîner des modèles génératifs avec moins de données d'entraînement, améliorant ainsi la synthèse d'images lorsque les données sont limitées en raison de problèmes de confidentialité ou de coûts d'annotation élevés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI