
Maison >Périphériques technologiques >IA >CMUÐ réalise une percée : le chien robot a une pleine valeur d'agilité, peut franchir des obstacles à très grande vitesse et a à la fois vitesse et sécurité !
CMUÐ réalise une percée : le chien robot a une pleine valeur d'agilité, peut franchir des obstacles à très grande vitesse et a à la fois vitesse et sécurité !

- 王林avant
- 2024-02-05 16:33:15866parcourir
Les équipes de la CMU et de l'ETH Zurich ont collaboré pour développer un nouveau framework appelé "Agile But Safe" (ABS), qui fournit une solution permettant aux robots quadrupèdes d'effectuer des mouvements à grande vitesse dans des environnements complexes. Le cadre fait non seulement preuve d'une grande efficacité pour éviter les collisions, mais atteint également une vitesse sans précédent de 3,1 millisecondes. Cette innovation apporte de nouveaux progrès dans le domaine des robots à pattes.
Dans le domaine du mouvement des robots à grande vitesse, maintenir à la fois vitesse et sécurité a toujours été un énorme défi. Cependant, une équipe de recherche de l’Université Carnegie Mellon (CMU) et de l’ETH Zurich (ETH) a récemment réalisé une percée. Le nouvel algorithme de robot quadrupède qu'ils ont développé peut non seulement se déplacer rapidement dans des environnements complexes, mais également éviter habilement les obstacles, atteignant ainsi véritablement l'objectif « d'agilité et de sécurité ». L’innovation de cet algorithme réside dans sa capacité à identifier et analyser rapidement l’environnement et à prendre des décisions intelligentes basées sur des données en temps réel. Grâce à des capteurs avancés et à une puissance de calcul puissante, le robot est capable de détecter avec précision les obstacles autour de lui et de les éviter en ajustant sa démarche et sa trajectoire. L'application réussie de cette technologie favorisera grandement le développement de robots à grande vitesse

Adresse papier : https://arxiv.org/pdf/2401.17583.pdf
Avec le soutien de l'ABS, le chien robot peut effectuer dans divers scénarios Tous ont démontré d'étonnantes capacités d'évitement d'obstacles à grande vitesse :
Couloirs étroits remplis d'obstacles :

Scènes intérieures désordonnées :

Qu'il s'agisse d'herbe ou d'extérieur, d'obstacles statiques ou dynamiques, le robot le chien peut les gérer calmement :

Lorsqu'il rencontre une poussette, le chien robot esquive adroitement :

Les panneaux d'avertissement, les boîtes et les chaises ne sont pas non plus un problème :

Il peut aussi facilement s'en occuper avec l'apparition soudaine de tapis et de pieds humains Bypass :

Le chien robot peut même jouer à l'aigle et attraper des poulets :

ABS Technologie révolutionnaire :
RL+ Apprentissage sans modèle de la valeur Reach-Avoid
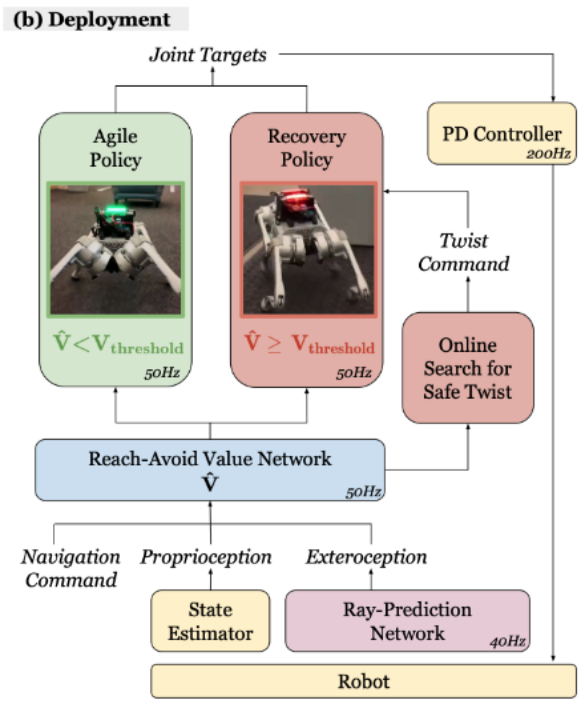
ABS utilise un paramètre de politique double (Dual Policy), comprenant une « Politique Agile » (Politique Agile) et une « Politique de récupération » (Politique de récupération). La stratégie Agile permet au robot de se déplacer rapidement à travers des environnements d'obstacles, tandis que la stratégie de récupération intervient pour assurer la sécurité du robot une fois que l'estimation de la valeur Atteindre-Éviter détecte un danger potentiel (comme l'apparition soudaine d'une poussette).

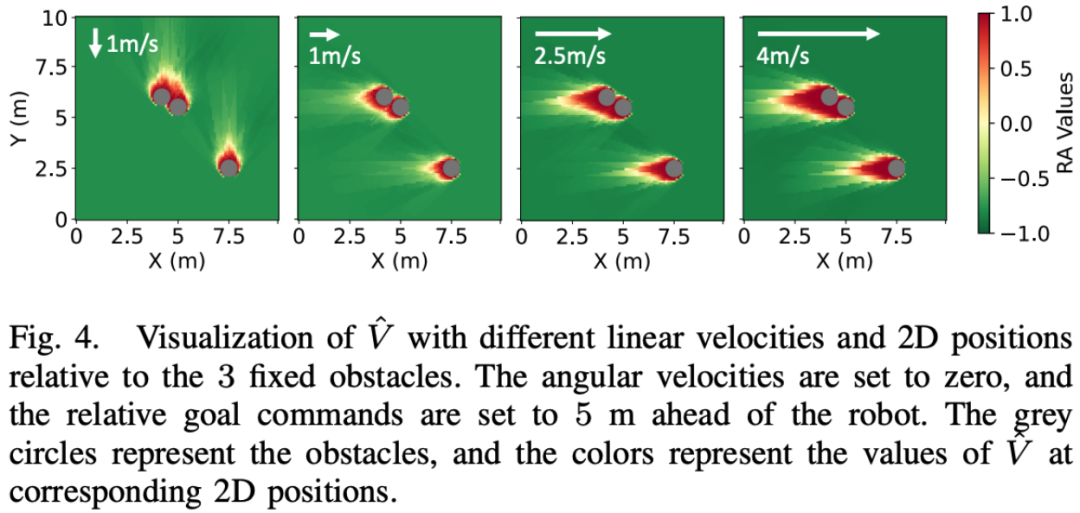
La figure ci-dessous montre la valeur RA (reach defense) apprise pour un ensemble spécifique d'obstacles. À mesure que la vitesse du robot change, le paysage de distribution des valeurs RA change en conséquence. Le signe de la valeur RA est une indication raisonnable de la sécurité de la stratégie agile. En d’autres termes, ce graphique montre le risque de sécurité du robot face à des obstacles spécifiques à différentes vitesses à travers différentes valeurs RA. Les changements élevés et faibles de la valeur RA reflètent les risques de sécurité que le robot peut rencontrer lors de l'exécution de stratégies agiles dans différents états.
L'innovation de la stratégie de récupération est qu'elle permet au robot quadrupède de suivre rapidement les instructions de vitesse linéaire et de vitesse angulaire en guise de sauvegarde stratégies de conservation. Contrairement à la stratégie agile, l’espace d’observation de la stratégie de récupération se concentre sur le suivi des commandes de vitesse linéaire et de vitesse angulaire et ne nécessite pas d’informations sensorielles externes. Les récompenses de mission de la stratégie de récupération se concentrent sur le suivi de la vitesse linéaire, le suivi de la vitesse angulaire, le maintien en vie et le maintien de la posture pour permettre un retour en douceur à la stratégie d'agilité. La formation à cette stratégie est également effectuée dans un environnement de simulation, mais avec une randomisation de domaine spécifique et des paramètres de programme pour mieux s'adapter aux conditions susceptibles de déclencher la stratégie de récupération. Cette approche permet aux robots quadrupèdes de réagir rapidement aux pannes potentielles lors de mouvements à grande vitesse.
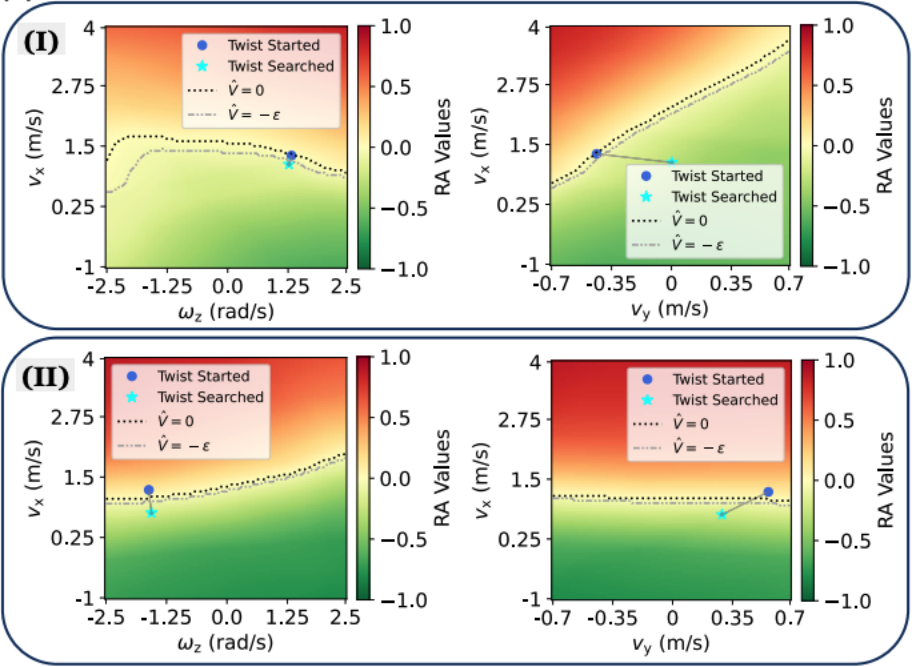
La figure ci-dessous montre une représentation visuelle du paysage des valeurs RA lorsque la stratégie de redressement est déclenchée dans deux situations spécifiques (I et II). Ces visualisations sont effectuées dans les plans vx (vitesse le long de l'axe x) par rapport à ωz (vitesse angulaire autour de l'axe z) et vx par rapport à vy (vitesse le long de l'axe y). La figure montre l'état de rotation initial avant la recherche (c'est-à-dire l'état de rotation actuel de la base du robot) et les commandes obtenues grâce à la recherche. En termes simples, ces graphiques montrent les instructions de mouvement optimales obtenues grâce à la recherche de stratégie de récupération dans des conditions spécifiques, et comment ces instructions affectent la valeur RA, reflétant ainsi la sécurité du robot dans différents états de mouvement.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La chaîne industrielle de l'intelligence artificielle comprend
- Renforcez l'industrie de la mode grâce à la technologie et aidez le district de Futian à construire un « centre de siège social de la mode dans la région de la Baie »
- Quelle est la prochaine frontière en matière d'intelligence artificielle et de robotique ?
- Tesla envisage de créer une usine de véhicules électriques en Inde pour dynamiser l'industrie indienne des véhicules électriques
- En mettant l'accent sur le changement et la persévérance, Web3 et l'IA remodèlent le dialogue organisé au sommet de l'industrie cinématographique