
Maison >Périphériques technologiques >IA >rare! L'outil de retouche d'image open source d'Apple, MGIE, va-t-il être disponible sur iPhone ?
rare! L'outil de retouche d'image open source d'Apple, MGIE, va-t-il être disponible sur iPhone ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-05 15:33:291332parcourir
Prendre une photo, saisir une commande de texte et votre téléphone commencera automatiquement à retoucher la photo ?
Cette fonctionnalité magique vient du nouvel outil d’édition d’images open source d’Apple « MGIE ».

Supprimer les personnes en arrière-plan
Ajouter une pizza sur la table
Récemment, l'IA a fait des progrès significatifs dans l'édition d'images. D'une part, grâce aux grands modèles multimodaux (MLLM), l'IA peut prendre des images en entrée et fournir des réponses de perception visuelle, permettant ainsi une édition d'image plus naturelle. D'un autre côté, la technologie d'édition basée sur les instructions fait que le processus d'édition ne repose plus sur des descriptions détaillées ou des masques de zone, mais permet aux utilisateurs de donner directement des instructions pour exprimer les méthodes et les objectifs d'édition. Cette méthode est très pratique car elle correspond davantage à la manière intuitive des humains. Grâce à ces technologies innovantes, l’IA devient progressivement le bras droit des gens dans le domaine de l’édition d’images.
Sur la base de l'inspiration de la technologie ci-dessus, Apple a proposé MGIE (MLLM-Guided Image Editing), utilisant MLLM pour résoudre le problème du guidage d'instructions insuffisant.

- Titre de l'article : Guiding Instruction-based Image Editing via Multimodal Large Language Models
- Lien de l'article : https://openreview.net/pdf?id=S1RKWSyZ2Y
- Page d'accueil du projet : https ://mllm-ie.github.io/
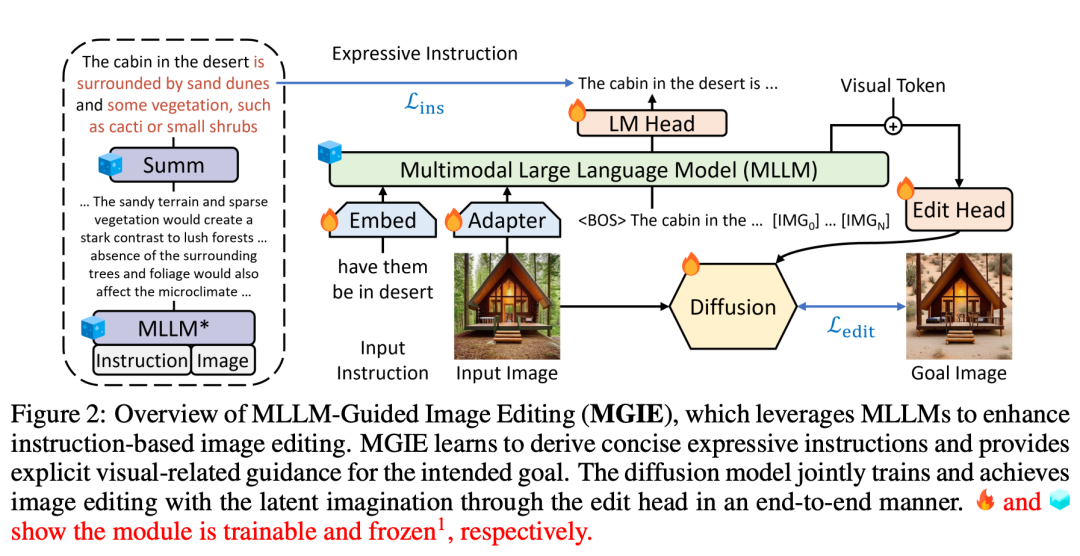
MGIE (Mind-Guided Image Editing) se compose du MLLM (Mind-Language Linking Model) et du modèle de diffusion, comme le montre la figure 2. MLLM apprend à acquérir des instructions d'expression concises et fournit des conseils clairs et visuellement pertinents. Le modèle de diffusion effectue l'édition d'images en utilisant l'imagination latente de la cible prévue et est mis à jour de manière synchrone grâce à un entraînement de bout en bout. De cette manière, MGIE est capable de bénéficier de la dérivation visuelle inhérente et de résoudre les instructions humaines ambiguës, ce qui aboutit à un montage judicieux.
Guidé par des instructions humaines, MGIE peut effectuer des modifications de style Photoshop, une optimisation globale des photos et des modifications d'objets locaux. Prenons l'image ci-dessous à titre d'exemple. Il est difficile de saisir le sens de « sain » sans contexte supplémentaire, mais MGIE peut associer avec précision les « garnitures végétales » à la pizza et les modifier en fonction des attentes humaines.

Cela nous rappelle "l'ambition" que Cook a exprimée il n'y a pas si longtemps lors de l'appel aux résultats : "Je pense qu'Apple a d'énormes opportunités en matière d'IA générative, mais je ne veux pas en parler davantage. Plus détails. » Les informations qu’il a divulguées incluent qu’Apple développe activement des fonctionnalités logicielles d’IA générative et que ces fonctionnalités seront disponibles pour les clients plus tard en 2024.
Combinés à une série de résultats de recherche théorique sur l'IA générative publiés par Apple ces derniers temps, il semble que nous attendons avec impatience les nouvelles fonctionnalités d'IA qu'Apple publiera ensuite.
Détails de l'article
La méthode MGIE proposée dans cette étude peut éditer l'image d'entrée V en une image cible via une instruction donnée X  . Pour ces instructions imprécises, MLLM dans MGIE effectuera une dérivation d'apprentissage pour obtenir des instructions d'expression concises ε. Afin de construire un pont entre le langage et les modalités visuelles, les chercheurs ont également ajouté un jeton spécial [IMG] après ε et ont utilisé la tête d'édition (edit head)
. Pour ces instructions imprécises, MLLM dans MGIE effectuera une dérivation d'apprentissage pour obtenir des instructions d'expression concises ε. Afin de construire un pont entre le langage et les modalités visuelles, les chercheurs ont également ajouté un jeton spécial [IMG] après ε et ont utilisé la tête d'édition (edit head) 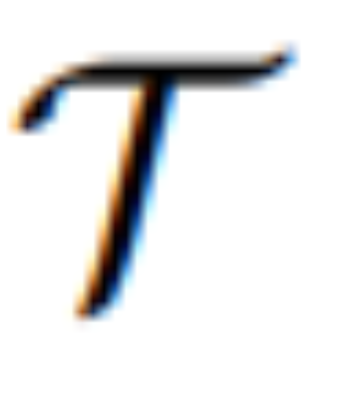 pour les convertir. Les informations transformées serviront d'imagination visuelle sous-jacente dans MLLM, guidant le modèle de diffusion pour atteindre les objectifs d'édition souhaités. MGIE est alors capable de comprendre les commandes floues visuellement conscientes pour effectuer une édition d'image raisonnable (le schéma d'architecture est présenté dans la figure 2 ci-dessus).
pour les convertir. Les informations transformées serviront d'imagination visuelle sous-jacente dans MLLM, guidant le modèle de diffusion pour atteindre les objectifs d'édition souhaités. MGIE est alors capable de comprendre les commandes floues visuellement conscientes pour effectuer une édition d'image raisonnable (le schéma d'architecture est présenté dans la figure 2 ci-dessus). 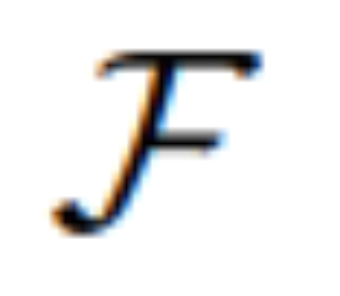
Grâce à l'alignement des fonctionnalités et à l'ajustement des instructions, MLLM est capable de fournir des réponses visuellement pertinentes à travers les perceptions modales. Pour l'édition d'images, l'étude utilise l'invite « à quoi ressemblera cette image si [instruction] » comme langue d'entrée pour l'image et en dérive des explications détaillées sur les commandes d'édition. Cependant, ces explications sont souvent trop longues et induisent même en erreur l’intention de l’utilisateur. Pour obtenir une description plus concise, cette étude applique un résumé pré-entraîné pour permettre à MLLM d'apprendre à générer une sortie récapitulative. Ce processus peut être résumé comme suit :
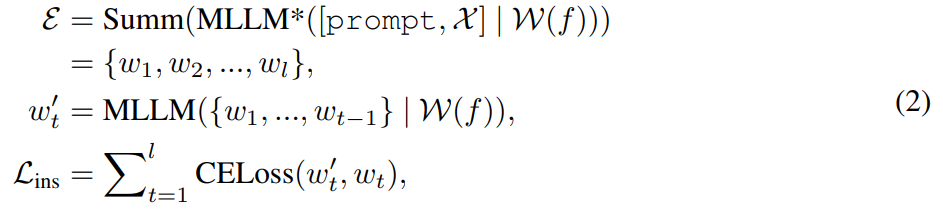
L'étude utilise une tête d'édition
pour transformer [IMG] en véritable guidage visuel. où 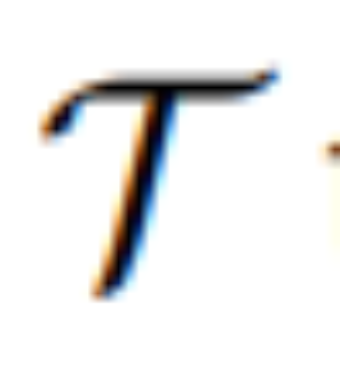 est un modèle séquence à séquence qui mappe les jetons visuels continus de MLLM à U latent sémantiquement significatif = {u_1, u_2, ..., u_L} et sert de guide éditorial :
est un modèle séquence à séquence qui mappe les jetons visuels continus de MLLM à U latent sémantiquement significatif = {u_1, u_2, ..., u_L} et sert de guide éditorial : 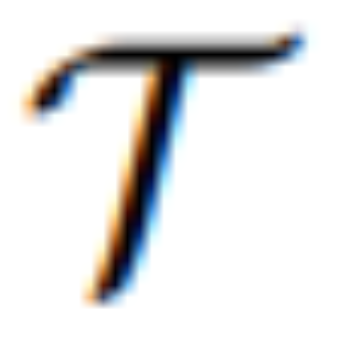
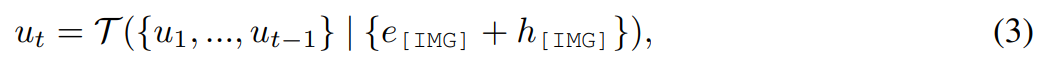 Afin de réaliser le processus de guidage de l'édition d'images à travers l'imagination visuelle U, cette étude envisage l'utilisation d'un modèle de diffusion
Afin de réaliser le processus de guidage de l'édition d'images à travers l'imagination visuelle U, cette étude envisage l'utilisation d'un modèle de diffusion
, qui, tout en incluant un auto-encodeur variationnel (VAE), peut également résoudre la diffusion de débruitage dans la question de l'espace latent. 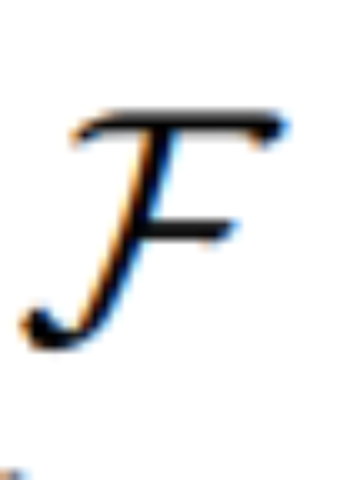
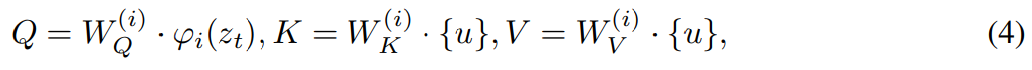 L'algorithme 1 montre le processus d'apprentissage MGIE. MLLM dérive des instructions compactes ε via les pertes d'instructions L_ins. Avec l'imagination sous-jacente de [IMG],
L'algorithme 1 montre le processus d'apprentissage MGIE. MLLM dérive des instructions compactes ε via les pertes d'instructions L_ins. Avec l'imagination sous-jacente de [IMG],
transforme sa modalité et guide 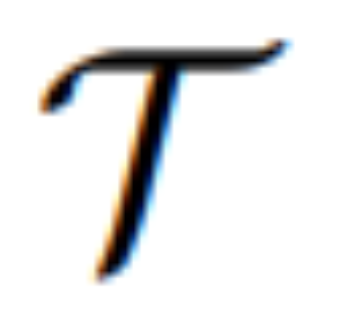 pour synthétiser l'image résultante. La perte d'édition L_edit est utilisée pour la formation à la diffusion. Étant donné que la plupart des poids peuvent être gelés (blocage d’auto-attention dans MLLM), un entraînement de bout en bout efficace en termes de paramètres est obtenu.
pour synthétiser l'image résultante. La perte d'édition L_edit est utilisée pour la formation à la diffusion. Étant donné que la plupart des poids peuvent être gelés (blocage d’auto-attention dans MLLM), un entraînement de bout en bout efficace en termes de paramètres est obtenu. 
 Évaluation expérimentale
Évaluation expérimentale
Pour les images d'entrée, la comparaison entre différentes méthodes sous les mêmes instructions, comme la première ligne d'instructions est "transformer le jour en nuit":
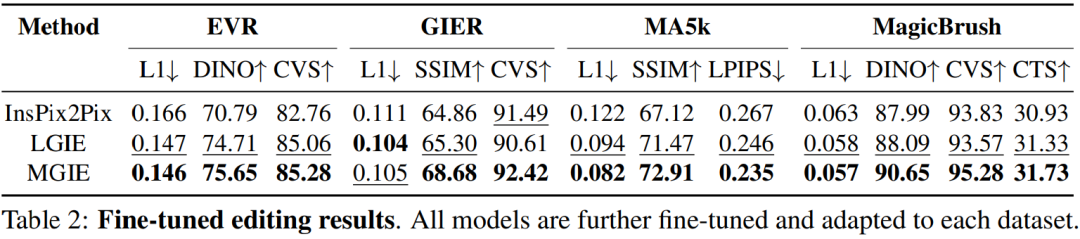
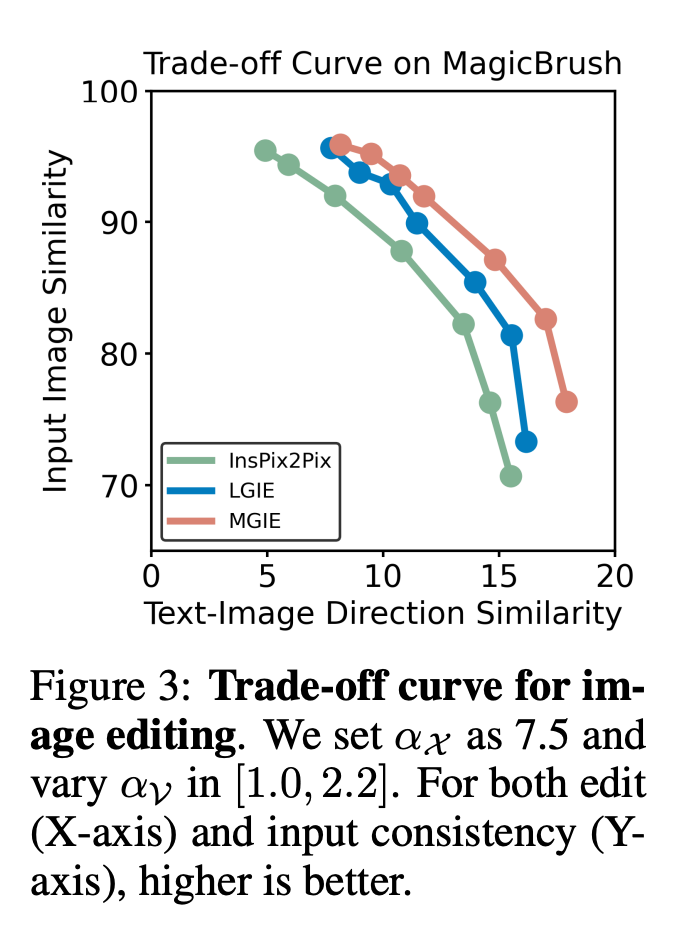
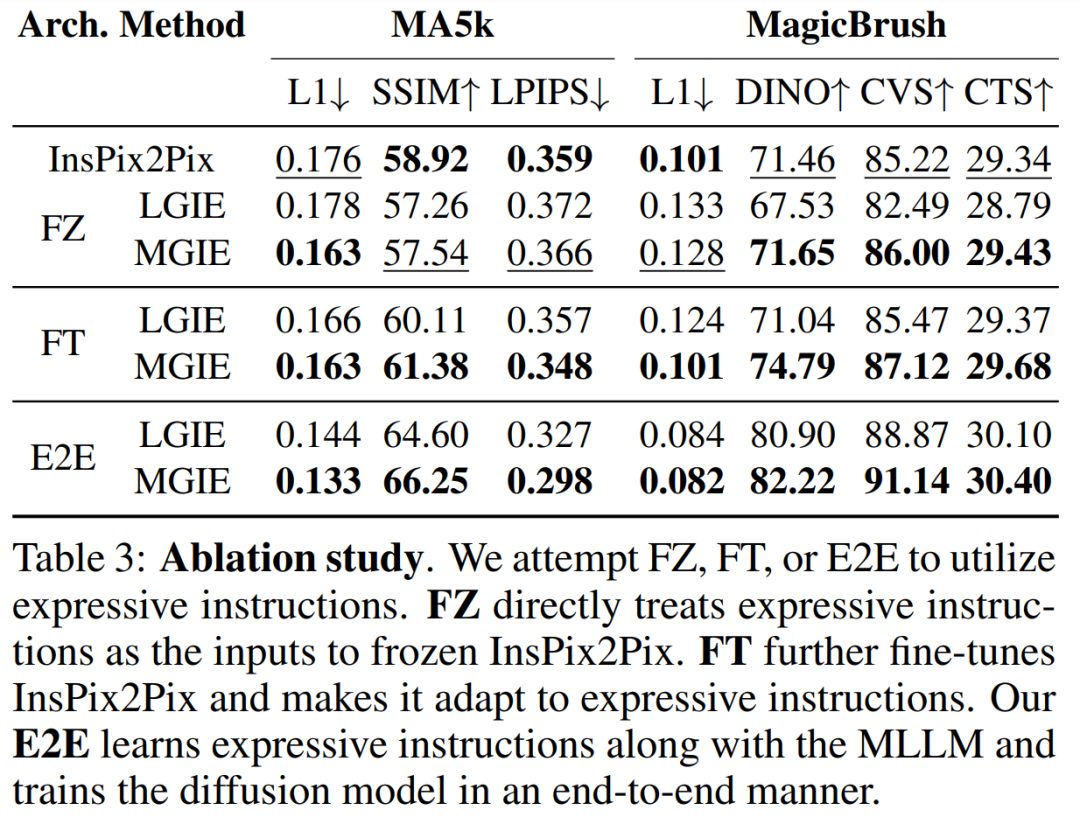
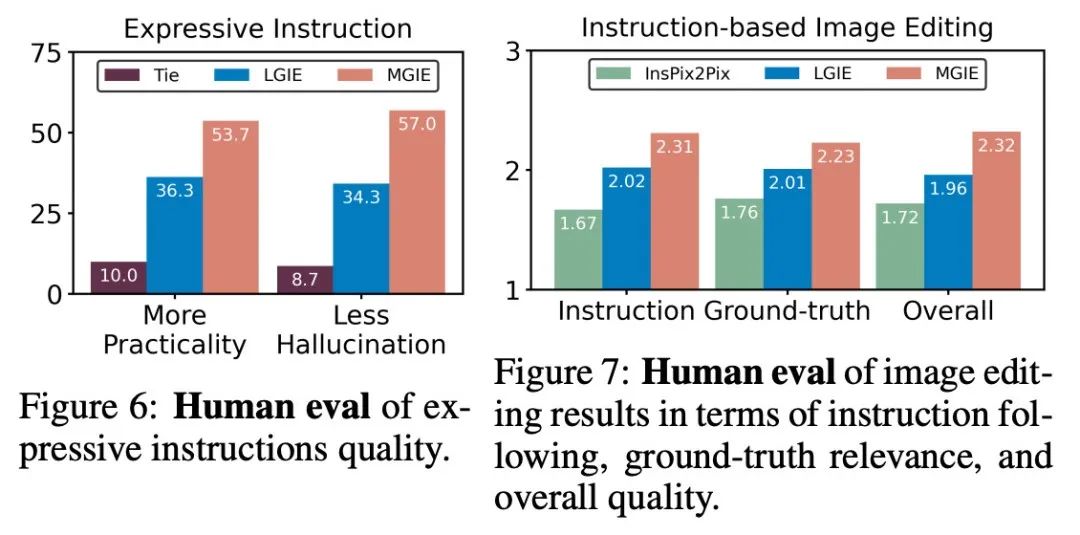
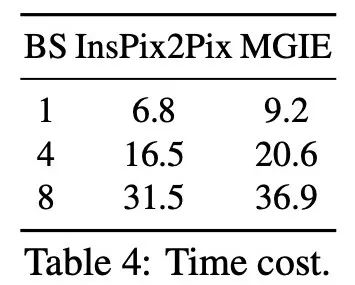
Le Tableau 1 montre les résultats de l'édition zéro-shot du modèle formé uniquement sur l'ensemble de données IPr2Pr. Pour EVR et GIER impliquant des modifications de style Photoshop, les résultats d'édition étaient plus proches de l'intention d'amorçage (par exemple, LGIE a obtenu un CVS plus élevé de 82,0 sur EVR). Pour l'optimisation globale des images sur MA5k, InsPix2Pix est intraitable en raison de la rareté des triples de formation pertinents. Le LGIE et le MGIE peuvent fournir des explications détaillées grâce à l'apprentissage du LLM, mais le LGIE est encore limité à sa seule modalité. En accédant à l'image, MGIE peut dériver des instructions explicites telles que quelles zones doivent être éclaircies ou quels objets doivent être plus clairs, ce qui entraîne des améliorations significatives des performances (par exemple, un SSIM plus élevé de 66,3 et une distance photo inférieure de 0,3), dans des résultats similaires ont été trouvés sur MagicBrush. MGIE obtient également les meilleures performances grâce à une imagerie visuelle précise et à la modification de cibles spécifiées en tant que cibles (par exemple, une similarité visuelle DINO supérieure à 82,2 et un alignement global des sous-titres supérieur à 30,4 CTS). Pour étudier l'édition d'images basée sur des instructions à des fins spécifiques, le tableau 2 affine le modèle sur chaque ensemble de données. Pour EVR et GIER, tous les modèles se sont améliorés après s'être adaptés aux tâches d'édition de style Photoshop. MGIE surpasse systématiquement LGIE dans tous les aspects du montage. Cela illustre également que l’apprentissage à l’aide d’instructions expressives peut améliorer efficacement l’édition d’images et que la perception visuelle joue un rôle crucial dans l’obtention de conseils explicites pour une amélioration maximale. Compromis entre α_X et α_V. L'édition d'image a deux objectifs : manipuler la cible comme une instruction et conserver le reste de l'image d'entrée. La figure 3 montre la courbe de compromis entre l'instruction (α_X) et la cohérence d'entrée (α_V). Cette étude a fixé α_X à 7,5 et α_V variait dans la plage [1,0, 2,2]. Plus α_V est grand, plus le résultat de l’édition est similaire à l’entrée, mais moins il est cohérent avec l’instruction. L'axe X calcule la similarité directionnelle CLIP, c'est-à-dire la cohérence des résultats d'édition avec les instructions ; l'axe Y représente la similarité des caractéristiques entre l'encodeur visuel CLIP et l'image d'entrée. Avec des instructions d'expression spécifiques, les expériences surpassent InsPix2Pix dans tous les paramètres. De plus, MGIE peut apprendre grâce à un guidage visuel explicite, permettant une amélioration globale. Cela prend en charge des améliorations robustes, qu’elles nécessitent une plus grande pertinence de saisie ou d’édition. Recherche sur l'ablation De plus, les chercheurs ont également mené des expériences d'ablation, en considérant les performances de différentes architectures FZ, FT et E2E dans l'expression d'instructions. Les résultats montrent que MGIE dépasse systématiquement LGIE en FZ, FT et E2E. Cela suggère que les instructions expressives avec une perception visuelle critique présentent un avantage constant dans tous les contextes d'ablation. Pourquoi le bootstrap MLLM est-il utile ? La figure 5 montre les valeurs CLIP-Score entre les images cibles d'entrée ou de vérité terrain et les instructions d'expression. Un score CLIP-S plus élevé pour l'image d'entrée indique que les instructions sont pertinentes pour la source d'édition, tandis qu'un meilleur alignement avec l'image cible fournit des conseils d'édition clairs et pertinents. Comme indiqué, MGIE est plus cohérent avec l'entrée/l'objectif, ce qui explique pourquoi ses instructions expressives sont utiles. Avec un exposé clair des résultats attendus, MGIE peut réaliser les plus grandes améliorations en matière d’édition d’images. Évaluation humaine. En plus des indicateurs automatiques, les chercheurs ont également effectué une évaluation manuelle. La figure 6 montre la qualité des instructions d'expression générées et la figure 7 compare les résultats d'édition d'images d'InsPix2Pix, LGIE et MGIE en termes de suivi des instructions, de pertinence de la vérité terrain et de qualité globale. Efficacité de l'inférence. Bien que MGIE s'appuie sur MLLM pour piloter l'édition d'images, il n'introduit que des instructions d'expression concises (moins de 32 jetons), l'efficacité est donc comparable à celle d'InsPix2Pix. Le tableau 4 répertorie les coûts de temps d'inférence sur le GPU NVIDIA A100. Pour une seule saisie, MGIE peut réaliser la tâche d'édition en 10 secondes. Avec plus de parallélisme des données, le temps requis est similaire (37 secondes avec une taille de lot de 8). L'ensemble du processus peut être réalisé avec un seul GPU (40 Go). Comparaison qualitative. La figure 8 montre une comparaison visuelle de tous les ensembles de données utilisés, et la figure 9 compare en outre les instructions d'expression pour LGIE ou MGIE. Sur la page d'accueil du projet, le chercheur propose également plus de démos (https://mllm-ie.github.io/). Pour plus de détails sur la recherche, veuillez vous référer à l’article original. 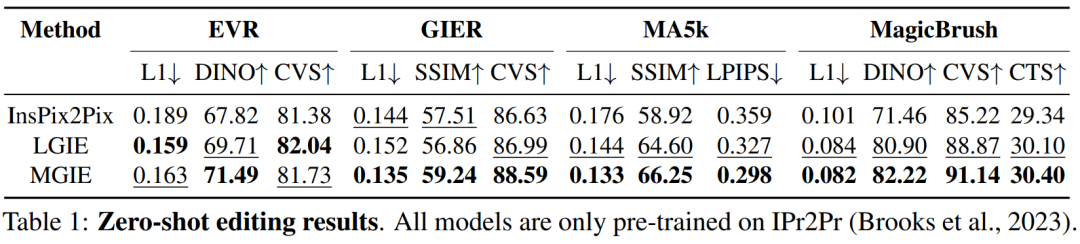



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quel dossier est BaiduNetDisk ?
- Les méta-chercheurs font une nouvelle tentative en matière d'IA : apprendre aux robots à naviguer physiquement sans cartes ni formation
- Retour vers le futur ! En utilisant des journaux d'enfance pour entraîner l'IA, ce programmeur a utilisé GPT-3 pour établir un dialogue avec son « moi passé »
- Explication détaillée du modèle de pré-formation d'apprentissage profond en Python
- Quelle est la différence entre la version américaine de l'iPhone et la version chinoise ?