
Maison >Périphériques technologiques >IA >Comprendre l'évaluation LLM à l'aide d'Arthur Bench dans un article
Comprendre l'évaluation LLM à l'aide d'Arthur Bench dans un article

- 王林avant
- 2024-02-04 17:33:02831parcourir
Bonjour les amis, je m'appelle Luga, aujourd'hui nous parlerons des technologies liées au domaine écologique de l'intelligence artificielle (IA) - évaluation LLM.

1. Défis rencontrés par l'évaluation de texte traditionnelle
Ces dernières années, le développement et l'amélioration rapides des grands modèles de langage (LLM) ont rendu les méthodes traditionnelles d'évaluation de texte non applicables à certains égards. Dans le domaine de l'évaluation de texte, nous avons entendu parler de méthodes telles que les méthodes d'évaluation basées sur « l'occurrence de mots », telles que BLEU, et les méthodes d'évaluation basées sur des « modèles de traitement du langage naturel pré-entraînés », telles que BERTScore. Ces méthodes fournissent des indicateurs plus précis pour évaluer la qualité et la similarité des textes. Le développement rapide du LLM a apporté de nouveaux défis et opportunités dans le domaine de l'évaluation de textes. Nous devons continuellement explorer et améliorer les méthodes d'évaluation pour nous adapter à cette tendance de développement.
Même si ces méthodes fonctionnaient autrefois bien, avec le développement de la technologie écologique LLM, elles apparaissent progressivement comme n'étant plus assez puissantes pour répondre pleinement aux besoins d'aujourd'hui.
Avec le développement et l'amélioration rapides du LLM, nous sommes confrontés à de nouveaux défis et opportunités. Les capacités et les niveaux de performance de LLM continuent d'augmenter, ce qui rend possible que les méthodes d'évaluation basées sur l'occurrence de mots telles que BLEU ne capturent pas pleinement la qualité et l'exactitude sémantique du texte généré par LLM. En revanche, le LLM peut générer un texte plus fluide, cohérent et sémantiquement riche, et les méthodes traditionnelles d'évaluation basées sur l'occurrence des mots ne peuvent pas mesurer avec précision ces avantages.
De plus, les méthodes d'évaluation basées sur des modèles pré-entraînés, tels que BERTScore, bien que performantes sur de nombreuses tâches, sont également confrontées à certains défis. Les modèles pré-entraînés peuvent ne pas prendre pleinement en compte les caractéristiques uniques du LLM (modèle de langage) et ses performances sur une tâche spécifique. Par conséquent, s'appuyer uniquement sur des méthodes d'évaluation basées sur des modèles pré-entraînés peut ne pas évaluer pleinement les capacités du LLM. Cela signifie que nous avons besoin de recherches et de développements supplémentaires sur de nouvelles méthodes d'évaluation pour évaluer et comprendre plus précisément les performances et les capacités des LLM dans des tâches spécifiques. Cela peut impliquer un réglage précis et une personnalisation du LLM pour mieux répondre aux exigences de la mission. Dans le même temps, nous devons également prendre en compte la diversité des méthodes d'évaluation et combiner l'évaluation manuelle et d'autres indicateurs de mesure pour obtenir des résultats d'évaluation plus complets et plus précis. En améliorant et en développant continuellement les méthodes d'évaluation, nous pouvons mieux comprendre et exploiter le potentiel du LLM et favoriser de nouveaux progrès dans le domaine du traitement du langage naturel.
2. Pourquoi l'évaluation des orientations LLM est-elle nécessaire ? Et les défis qu'elle entraîne ?
De manière générale, l'aspect le plus précieux de l'utilisation de la méthode d'évaluation des orientations LLM dans des scénarios commerciaux réels est sa rapidité et sa sensibilité.
1. Efficace
Tout d'abord, la vitesse de mise en œuvre de l'utilisation du LLM pour guider l'évaluation est généralement plus rapide. Par rapport aux pipelines d'évaluation précédents, la création d'une évaluation guidée par LLM nécessite relativement peu d'efforts et est facile à mettre en œuvre. Pour l'évaluation guidée LLM, seules deux choses doivent être préparées : une description textuelle décrivant les critères d'évaluation et des exemples à utiliser dans le modèle d'invite. Par rapport à la création de votre propre modèle PNL pré-entraîné ou à l'ajustement précis d'un modèle PNL existant pour servir d'évaluateur, il est plus efficace d'utiliser le LLM pour accomplir ces tâches. L'itération des critères d'évaluation est également plus rapide avec LLM.
2. Sensibilité
Deuxièmement, le LLM est généralement plus sensible que les modèles PNL pré-entraînés et les méthodes d'évaluation évoquées précédemment. Cette sensibilité a un impact positif à certains égards, permettant au LLM de gérer des situations spécifiques avec plus de flexibilité. Cependant, cette sensibilité peut également rendre les résultats de l’évaluation LLM moins prévisibles.
Comme nous en avons discuté précédemment, les évaluateurs LLM sont plus sensibles par rapport aux autres méthodes d'évaluation. Cependant, il existe de nombreuses façons différentes de configurer LLM en tant qu'évaluateur, et son comportement peut varier considérablement en fonction de la configuration choisie. En outre, un autre défi est que les évaluateurs LLM peuvent se retrouver bloqués si l'évaluation implique trop d'étapes d'inférence ou nécessite de traiter trop de variables simultanément. Par conséquent, lors de la conception et de la mise en œuvre des évaluations, la configuration du LLM et la complexité des tâches d'évaluation doivent être soigneusement prises en compte pour garantir des résultats d'évaluation précis et valides.
En raison des caractéristiques de LLM, ses résultats d'évaluation peuvent être affectés par différentes configurations et réglages de paramètres. Cela signifie que lors de l'évaluation des LLM, le modèle doit être soigneusement sélectionné et configuré pour garantir qu'il se comporte comme prévu. Différentes configurations peuvent conduire à des résultats différents, l'évaluateur doit donc consacrer du temps et des efforts pour ajuster et optimiser les paramètres du LLM afin d'obtenir des résultats d'évaluation précis et fiables.
De plus, les évaluateurs peuvent être confrontés à certains défis lorsqu'ils sont confrontés à des tâches d'évaluation qui nécessitent un raisonnement complexe ou le traitement simultané de plusieurs variables. En effet, la capacité de raisonnement du LLM peut être limitée lorsqu'il s'agit de situations complexes. Le LLM peut nécessiter des efforts supplémentaires pour accomplir ces tâches afin de garantir l'exactitude et la fiabilité de l'évaluation.
3. Qu'est-ce qu'Arthur Bench ?
Arthur Bench est un outil d'évaluation open source utilisé pour comparer les performances des modèles de texte génératifs (LLM). Il peut être utilisé pour évaluer différents modèles, indices et hyperparamètres LLM et fournir des rapports détaillés sur les performances LLM sur diverses tâches.
Les principales fonctionnalités d'Arthur Bench incluent : Les principales fonctionnalités d'Arthur Bench incluent :
- Comparez différents modèles LLM : Arthur Bench peut être utilisé pour comparer les performances de différents modèles LLM, y compris des modèles de différents fournisseurs, différentes versions de modèles et des modèles utilisant différents ensembles de données de formation.
- Évaluer les conseils : Arthur Bench peut être utilisé pour évaluer l'impact de différents conseils sur les performances du LLM. Les invites sont des instructions utilisées pour guider LLM dans la génération de texte.
- Test des hyperparamètres : Arthur Bench peut être utilisé pour tester l'impact de différents hyperparamètres sur les performances du LLM. Les hyperparamètres sont des paramètres qui contrôlent le comportement de LLM.
De manière générale, le flux de travail d'Arthur Bench implique principalement les étapes suivantes, et l'analyse détaillée est la suivante :
1. Définition des tâches
À ce stade, nous devons clarifier nos objectifs d'évaluation. plusieurs Une variété de tâches d'évaluation, notamment :
- Question et réponse : testez la capacité du LLM à comprendre et à répondre à des questions ouvertes, difficiles ou ambiguës.
- Résumé : évaluez la capacité de LLM à extraire des informations clés d'un texte et à générer des résumés concis.
- Traduction : examinez la capacité du LLM à traduire avec précision et fluidité entre différentes langues.
- Génération de code : testez la capacité de LLM à générer du code basé sur des descriptions en langage naturel.
2. Sélection du modèle
A cette étape, le travail principal consiste à sélectionner les objets d'évaluation. Arthur Bench prend en charge une variété de modèles LLM, couvrant les technologies de pointe d'institutions bien connues telles que OpenAI, Google AI, Microsoft, etc., telles que GPT-3, LaMDA, Megatron-Turing NLG, etc. Nous pouvons sélectionner des modèles spécifiques à évaluer en fonction des besoins de recherche.
3. Configuration des paramètres
Après avoir terminé la sélection du modèle, l'étape suivante consiste à effectuer un contrôle affiné. Pour évaluer plus précisément les performances de LLM, Arthur Bench permet aux utilisateurs de configurer des astuces et des hyperparamètres.
- Astuce : Guidez LLM dans la direction et le contenu du texte généré, tel que des questions, des descriptions ou des instructions.
- Hyperparamètres : paramètres clés qui contrôlent le comportement du LLM, tels que le taux d'apprentissage, le nombre d'étapes de formation, l'architecture du modèle, etc.
Grâce à une configuration raffinée, nous pouvons explorer en profondeur les différences de performances de LLM sous différents paramètres et obtenir des résultats d'évaluation avec plus de valeur de référence.
4. Exécution d'évaluation : processus automatisé
La dernière étape consiste à effectuer une évaluation des tâches à l'aide d'un processus automatisé. En règle générale, Arthur Bench fournit un processus d'évaluation automatisé qui nécessite une configuration simple pour exécuter les tâches d'évaluation. Il effectuera automatiquement les étapes suivantes :
- Appelez le modèle LLM et génèrez une sortie texte.
- Pour des tâches spécifiques, appliquez les indicateurs d'évaluation correspondants pour l'analyse.
- Générez des rapports détaillés et présentez les résultats de l'évaluation.
4. Analyse du scénario d'utilisation d'Arthur Bench
En tant que clé d'une évaluation LLM rapide et basée sur les données, Arthur Bench fournit principalement les solutions suivantes, impliquant spécifiquement :
1. est une étape cruciale dans le domaine de l’intelligence artificielle et revêt une grande importance pour garantir la validité et la fiabilité du modèle. Dans ce processus, le rôle d'Arthur Bench a été crucial. Son objectif est de fournir aux entreprises un cadre de comparaison fiable pour les aider à prendre des décisions éclairées parmi les nombreuses options de grands modèles de langage (LLM) grâce à l'utilisation de mesures et de méthodes d'évaluation cohérentes.
 Arthur Bench utilisera son expertise et son expérience pour évaluer chaque option LLM et veillera à ce que des mesures cohérentes soient utilisées pour comparer leurs forces et leurs faiblesses. Il prendra en compte des facteurs tels que les performances du modèle, la précision, la rapidité, les besoins en ressources et bien plus encore pour garantir que les entreprises puissent faire des choix éclairés et clairs.
Arthur Bench utilisera son expertise et son expérience pour évaluer chaque option LLM et veillera à ce que des mesures cohérentes soient utilisées pour comparer leurs forces et leurs faiblesses. Il prendra en compte des facteurs tels que les performances du modèle, la précision, la rapidité, les besoins en ressources et bien plus encore pour garantir que les entreprises puissent faire des choix éclairés et clairs.
En utilisant des mesures et des méthodologies d'évaluation cohérentes, Arthur Bench fournira aux entreprises un cadre de comparaison fiable, leur permettant d'évaluer pleinement les avantages et les limites de chaque option LLM. Cela permettra aux entreprises de prendre des décisions éclairées pour maximiser les progrès rapides de l’intelligence artificielle et garantir la meilleure expérience possible avec leurs applications.
2. Optimisation du budget et de la confidentialité
Lors du choix d'un modèle d'IA, toutes les applications ne nécessitent pas les grands modèles de langage (LLM) les plus avancés ou les plus coûteux. Dans certains cas, les besoins de la mission peuvent être satisfaits à l’aide de modèles d’IA moins coûteux.
Cette approche d'optimisation budgétaire peut aider les entreprises à faire des choix intelligents avec des ressources limitées. Au lieu d’opter pour le modèle le plus cher ou le plus moderne, choisissez celui qui convient en fonction de vos besoins spécifiques. Les modèles les plus abordables peuvent être légèrement moins performants que les LLM de pointe à certains égards, mais pour certaines tâches simples ou standard, Arthur Bench peut toujours fournir une solution qui répond aux besoins.
De plus, Arthur Bench a souligné que l'intégration du modèle en interne permet un meilleur contrôle sur la confidentialité des données. Pour les applications impliquant des données sensibles ou des problèmes de confidentialité, les entreprises préféreront peut-être utiliser leurs propres modèles formés en interne plutôt que de s'appuyer sur des LLM externes tiers. En utilisant des modèles internes, les entreprises peuvent mieux contrôler le traitement et le stockage des données et mieux protéger la confidentialité des données.
3. Traduire les repères académiques en performances réelles
Les repères académiques font référence à des indicateurs et des méthodes d'évaluation de modèles établis dans la recherche universitaire. Ces indicateurs et méthodes sont généralement spécifiques à une tâche ou un domaine spécifique et peuvent évaluer efficacement les performances du modèle dans cette tâche ou ce domaine.
Cependant, les références académiques ne reflètent pas toujours directement les performances d’un modèle dans le monde réel. En effet, les scénarios d'application dans le monde réel sont souvent plus complexes et nécessitent la prise en compte de davantage de facteurs, tels que la distribution des données, l'environnement de déploiement du modèle, etc.
Arthur Bench aide à traduire les références académiques en performances réelles. Il atteint cet objectif des manières suivantes :
- Fournit un ensemble complet d'indicateurs d'évaluation couvrant plusieurs aspects de la précision, de l'efficacité, de la robustesse du modèle, etc. Ces mesures peuvent refléter non seulement les performances du modèle selon des critères académiques, mais également les performances potentielles du modèle dans le monde réel.
- Prend en charge plusieurs types de modèles et peut comparer différents types de modèles. Cela permet aux entreprises de choisir le modèle qui convient le mieux à leurs scénarios d'application.
- Fournit des outils d'analyse visuelle pour aider les entreprises à comprendre intuitivement les différences de performances des différents modèles. Cela permet aux entreprises de prendre des décisions plus facilement.
5. Analyse des fonctionnalités d'Arthur Bench
En tant que clé d'une évaluation LLM rapide et basée sur les données, Arthur Bench possède les fonctionnalités suivantes :
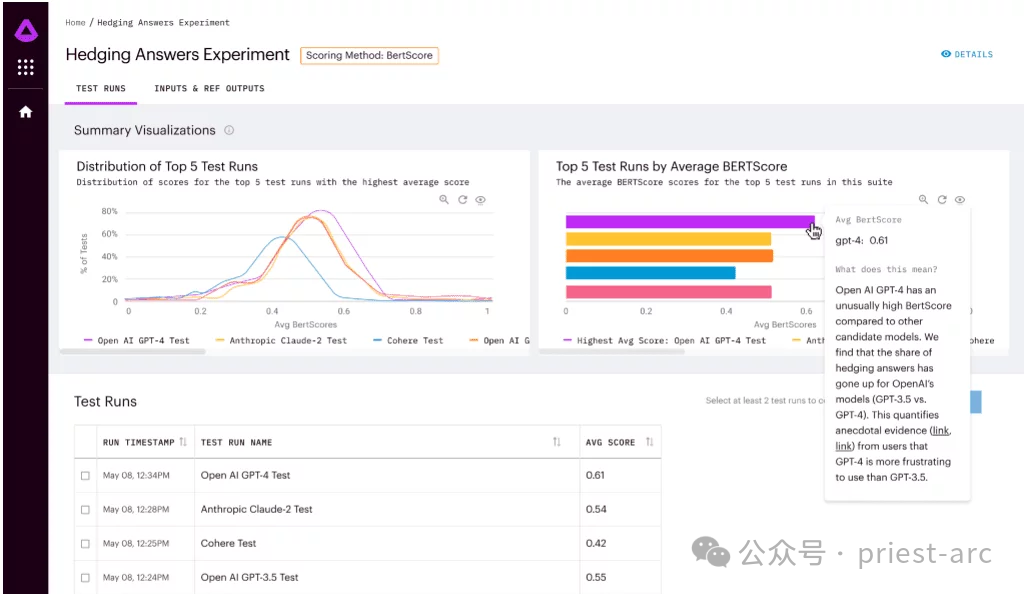
1. Ensemble complet d'indicateurs de notation
Arthur Bench dispose d'un ensemble complet d'indicateurs de notation. indicateurs, couvrant tout, depuis la synthèse de tous les aspects de la qualité jusqu'à l'expérience utilisateur. Il peut utiliser ces mesures de notation à tout moment pour évaluer et comparer différents modèles. L’utilisation combinée de ces mesures de notation peut l’aider à pleinement comprendre les forces et les faiblesses de chaque modèle.
La portée de ces indicateurs de notation est très large, incluant, mais sans s'y limiter, la qualité du résumé, l'exactitude, la fluidité, l'exactitude grammaticale, la capacité de compréhension du contexte, la cohérence logique, etc. Arthur Bench évaluera chaque modèle par rapport à ces mesures et combinera les résultats dans un score complet pour aider les entreprises à prendre des décisions éclairées.
De plus, si l'entreprise a des besoins ou des préoccupations spécifiques, Arthur Bench peut également créer et ajouter des mesures de notation personnalisées en fonction des exigences de l'entreprise. Ceci est fait pour mieux répondre aux besoins spécifiques de l'entreprise et garantir que le processus d'évaluation est conforme aux objectifs et aux normes de l'entreprise.
2. Versions locales et basées sur le cloud
Pour ceux qui préfèrent le déploiement local et le contrôle autonome, vous pouvez accéder au référentiel GitHub et déployer Arthur Bench dans votre propre environnement local. De cette manière, chacun peut maîtriser et contrôler pleinement le fonctionnement d’Arthur Bench et le personnaliser et le configurer selon ses propres besoins.
D'autre part, pour les utilisateurs qui préfèrent la commodité et la flexibilité, des produits SaaS basés sur le cloud sont également proposés. Vous pouvez choisir de vous inscrire pour accéder et utiliser Arthur Bench via le cloud. Cette méthode élimine le besoin d’une installation et d’une configuration locales fastidieuses et vous permet de profiter immédiatement des fonctions et services fournis.
3. Complètement open source
En tant que projet open source, Arthur Bench présente ses caractéristiques open source typiques en termes de transparence, d'évolutivité et de collaboration communautaire. Cette nature open source offre aux utilisateurs une multitude d’avantages et d’opportunités pour mieux comprendre le fonctionnement du projet, ainsi que pour le personnaliser et l’étendre en fonction de leurs besoins. Dans le même temps, l'ouverture d'Arthur Bench encourage également les utilisateurs à participer activement à la collaboration communautaire, à collaborer et à se développer avec d'autres utilisateurs. Ce modèle de coopération ouverte contribue à promouvoir le développement continu et l'innovation du projet, tout en créant davantage de valeur et d'opportunités pour les utilisateurs.
En bref, Arthur Bench fournit un cadre ouvert et flexible qui permet aux utilisateurs de personnaliser les indicateurs d'évaluation, et a été largement utilisé dans le domaine financier. Les partenariats avec Amazon Web Services et Cohere font progresser le cadre, encourageant les développeurs à créer de nouvelles métriques pour Bench et contribuant aux progrès dans le domaine de l'évaluation des modèles de langage.
Référence :
- [1] https://github.com/arthur-ai/bench
- [2] https://neurohive.io/en/news/arthur-bench-framework-for-evaluating- modèles de langage/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que dois-je faire si la barre de menus en haut de mon IA est manquante ?
- Quel est le concept de base de l'intelligence artificielle
- Alibaba Cloud AnalyticDB (ADB) + LLM : créer un chatbot spécifique à l'entreprise à l'ère de l'AIGC
- Protéger les données sensibles : guide de sécurité PHP pour prévenir les fuites d'informations