
Maison >Périphériques technologiques >IA >Sans le diviser en jetons, apprendre directement à partir des octets de manière efficace peut également être utilisé de cette manière.
Sans le diviser en jetons, apprendre directement à partir des octets de manière efficace peut également être utilisé de cette manière.

- 王林avant
- 2024-02-04 14:54:29727parcourir
Lors de la définition d'un modèle de langage, des méthodes de base de segmentation de mots sont souvent utilisées pour diviser les phrases en mots, sous-mots ou caractères. La segmentation des sous-mots a longtemps été le choix le plus populaire car elle établit un équilibre entre l'efficacité de la formation et la capacité à gérer des mots en dehors du vocabulaire. Cependant, certaines études ont souligné des problèmes liés à la segmentation des sous-mots, tels qu'un manque de robustesse dans la gestion des fautes de frappe, des changements d'orthographe et de casse, ainsi que des changements morphologiques. Par conséquent, ces questions doivent être soigneusement prises en compte lors de la conception des modèles de langage afin d’améliorer la précision et la robustesse du modèle.
Par conséquent, certains chercheurs ont choisi une approche utilisant des séquences d'octets, c'est-à-dire une cartographie de bout en bout des données brutes pour prédire les résultats sans aucune segmentation de mots. Comparés aux modèles de sous-mots, les modèles de langage au niveau octet sont plus faciles à généraliser à différentes formes d'écriture et changements morphologiques. Cependant, modéliser le texte en octets signifie que les séquences générées sont plus longues que les sous-mots correspondants. Afin d’améliorer l’efficacité, il faut y parvenir en améliorant l’architecture.
Autoregressive Transformer occupe une position dominante dans la modélisation du langage, mais son problème d'efficacité est particulièrement important. Son coût de calcul augmente quadratiquement à mesure que la longueur de la séquence augmente, ce qui entraîne une faible évolutivité pour les longues séquences. Pour résoudre ce problème, les chercheurs ont compressé la représentation interne du Transformer afin de gérer de longues séquences. Une approche consiste à développer une approche de modélisation tenant compte de la longueur qui fusionne des groupes de jetons au sein d'une couche intermédiaire, réduisant ainsi le coût de calcul. Récemment, Yu et al. ont proposé une méthode appelée MegaByte Transformer. Il utilise des fragments d'octets de taille fixe pour simuler des formes compressées en tant que sous-mots, réduisant ainsi le coût de calcul. Cependant, cette solution n’est peut-être pas la meilleure à l’heure actuelle et nécessite des recherches et des améliorations supplémentaires.
Dans une dernière étude, des chercheurs de l'Université Cornell ont introduit un modèle de langage simple et efficace au niveau des octets appelé MambaByte. Ce modèle est dérivé d'une amélioration directe de l'architecture Mamba récemment introduite. L'architecture Mamba est construite sur la méthode du modèle d'espace d'état (SSM), tandis que MambaByte introduit un mécanisme de sélection plus efficace, ce qui le rend plus performant lors du traitement de données discrètes telles que le texte, et fournit également une implémentation GPU efficace. Les chercheurs ont brièvement observé l'utilisation de Mamba non modifié et ont découvert qu'il était capable d'atténuer un goulot d'étranglement informatique majeur dans la modélisation du langage, éliminant ainsi le besoin de correctifs et exploitant pleinement les ressources informatiques disponibles.

- Titre de l'article : MambaByte : Modèle spatial d'état sélectif sans jeton
- Lien de l'article : https://arxiv.org/pdf/2401.13660.pdf
Lors d'expériences, ils ont comparé MambaByte aux architectures Transformers, SSM et MegaByte (patch). Ces architectures sont évaluées sous des paramètres fixes et des paramètres de calcul et sur plusieurs ensembles de données textuelles longues. La figure 1 résume leurs principales conclusions.
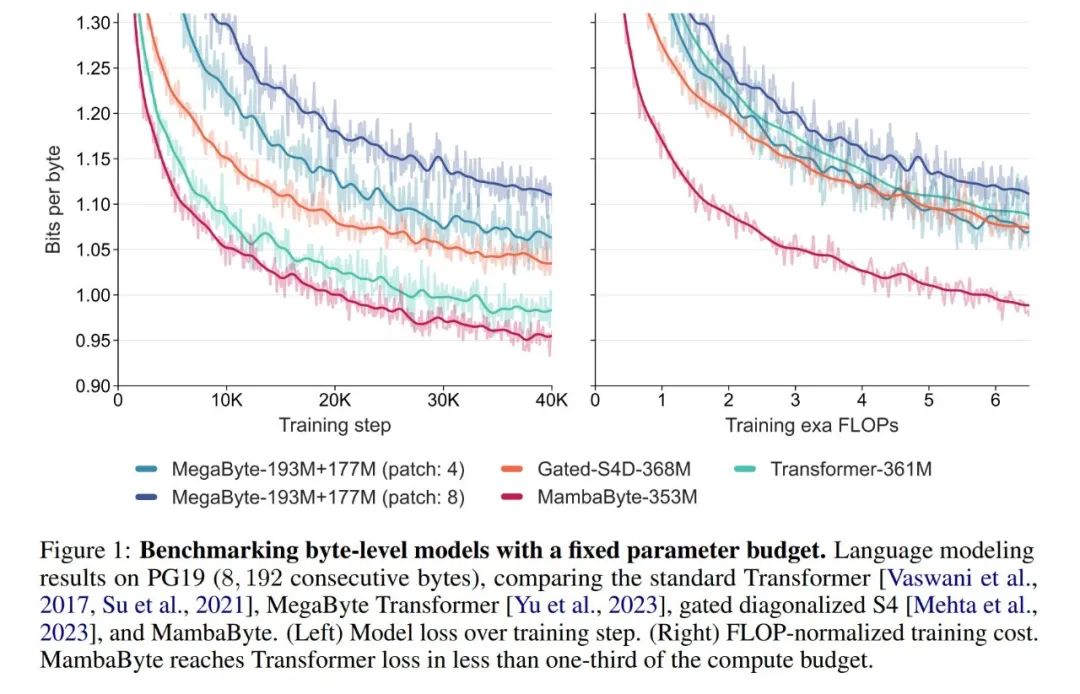
Par rapport aux transformateurs au niveau octet, MambaByte offre une solution plus rapide et plus performante, tandis que l'efficacité informatique a également été considérablement améliorée. Les chercheurs ont également comparé les modèles de langage sans jeton avec les modèles de sous-mots de pointe actuels et ont constaté que MambaByte est compétitif à cet égard et peut gérer des séquences plus longues. Les résultats de cette étude montrent que MambaByte peut être une alternative puissante aux tokenizers existants qui en dépendent, et devrait promouvoir le développement ultérieur de l'apprentissage de bout en bout.
Contexte : Modèle de séquence spatiale d'états sélectifs
SSM utilise des équations différentielles du premier ordre pour modéliser l'évolution temporelle des états cachés. Le SSM linéaire invariant dans le temps a montré de bons résultats dans une variété de tâches d'apprentissage en profondeur. Cependant, récemment, les auteurs de Mamba, Gu et Dao, ont soutenu que la dynamique constante de ces méthodes manque de sélection de contexte dépendante des entrées dans les états cachés, ce qui peut être nécessaire pour des tâches telles que la modélisation du langage. Par conséquent, ils ont proposé la méthode Mamba, qui est définie dynamiquement en prenant une entrée donnée x(t) ∈ R, un état caché h(t) ∈ R^n et une sortie y(t) ∈ R comme un état continu variable dans le temps. au temps t est :
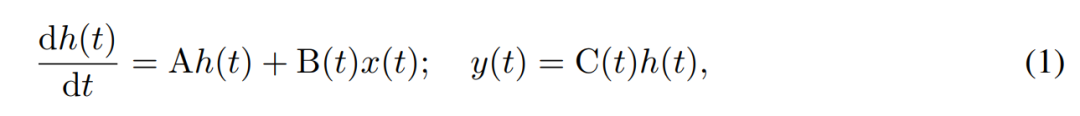
Ses paramètres sont la matrice système diagonale invariante dans le temps A∈R^(n×n), et les matrices d'entrée et de sortie variables dans le temps B (t)∈R^ (n× 1) et C (t)∈R^(1×n).
Pour modéliser des séries temporelles discrètes telles que les octets, la dynamique temporelle continue dans (1) doit être approchée par discrétisation. Cela produit une récurrence latente en temps discret, avec de nouvelles matrices A, B et C à chaque pas de temps, c'est-à-dire
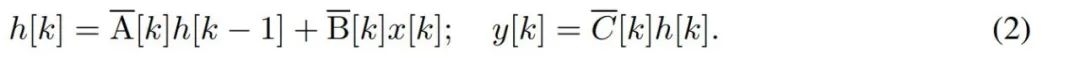
Notez que (2) est similaire à la version linéaire des réseaux de neurones récurrents, que l'on peut trouver dans le langage Cette boucle est appliquée lors de la génération du modèle. La discrétisation nécessite que chaque position d'entrée ait un pas de temps, à savoir Δ[k], correspondant à x [k] = x (t_k) de 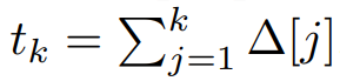 . Les matrices en temps discret A, B et C peuvent alors être calculées à partir de Δ[k]. La figure 2 montre comment Mamba modélise des séquences discrètes.
. Les matrices en temps discret A, B et C peuvent alors être calculées à partir de Δ[k]. La figure 2 montre comment Mamba modélise des séquences discrètes.
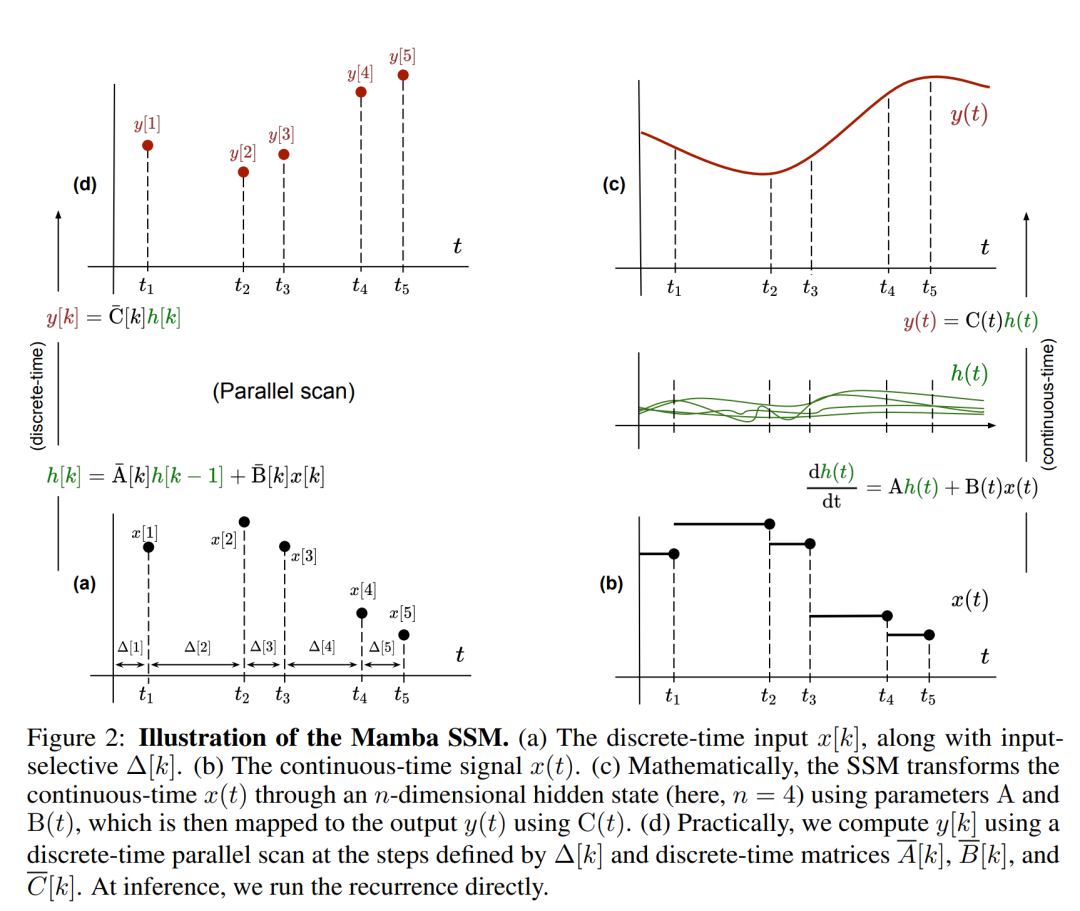
Dans Mamba, le terme SSM est sélectif en entrée, c'est-à-dire que B, C et Δ sont définis comme des fonctions de l'entrée x [k]∈R^d :
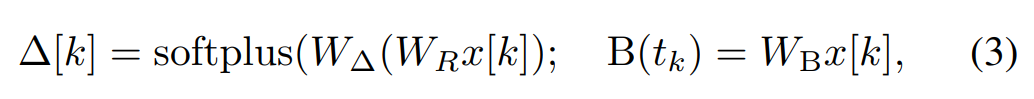
où W_B ∈ R^(n×d) (C est défini de la même manière), W_Δ ∈ R^(d×r) et W_R ∈ R^(r×d) (pour certains r ≪d) sont des poids apprenables, et softplus garantit positivité. Notez que pour chaque dimension d'entrée d, les paramètres SSM A, B et C sont les mêmes, mais le nombre de pas de temps Δ est différent ; cela se traduit par une taille d'état caché de n × d pour chaque pas de temps k.
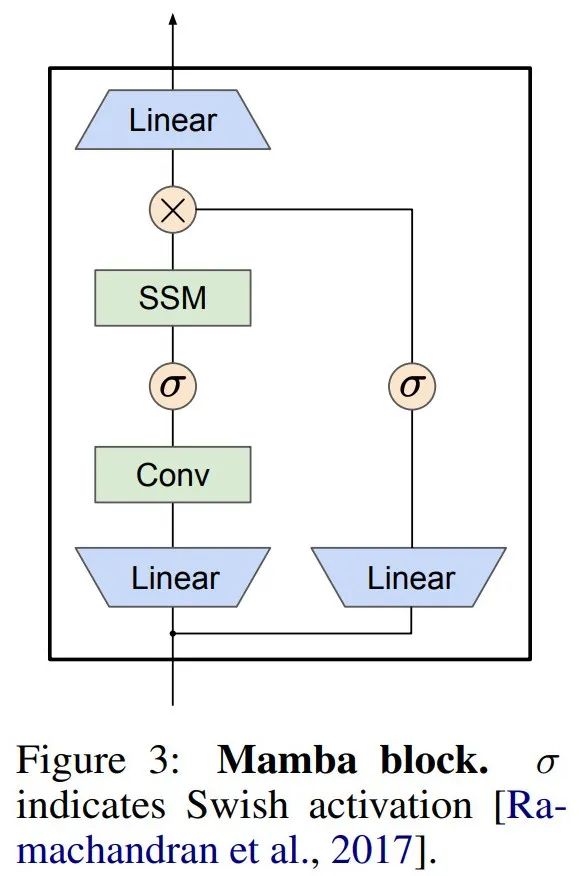
Mamba intègre cette couche SSM dans un modèle de langage de réseau neuronal complet. Plus précisément, le modèle utilise une série de couches de déclenchement inspirées des précédents SSM bloqués. La figure 3 montre l'architecture Mamba qui combine une couche SSM avec un réseau neuronal sécurisé.
Scan parallèle de récurrence linéaire. Au moment de la formation, les auteurs ont accès à l'intégralité de la séquence x, permettant un calcul plus efficace de la récurrence linéaire. Les recherches de Smith et al. [2023] démontrent que la récurrence séquentielle dans le SSM linéaire peut être calculée efficacement à l'aide d'analyses parallèles efficaces. Pour Mamba, l'auteur mappe d'abord la récurrence aux séquences de tuples L, où e_k = , puis définit un opérateur d'association
, puis définit un opérateur d'association  tel que
tel que 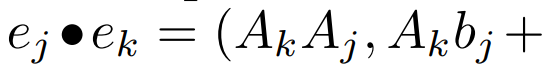
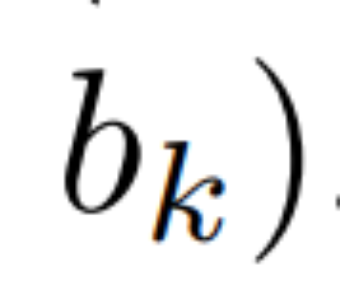 . Enfin, ils appliquent des balayages parallèles pour calculer la séquence
. Enfin, ils appliquent des balayages parallèles pour calculer la séquence 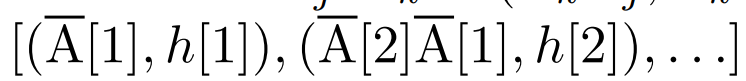 . En général, cela prend
. En général, cela prend 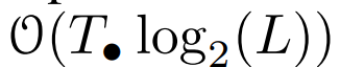 temps, en utilisant des processeurs L/2, où
temps, en utilisant des processeurs L/2, où 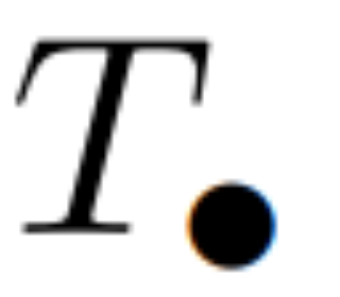 est le coût de la multiplication matricielle. Notez que A est une matrice diagonale et que la récurrence linéaire peut être calculée en parallèle dans le temps
est le coût de la multiplication matricielle. Notez que A est une matrice diagonale et que la récurrence linéaire peut être calculée en parallèle dans le temps 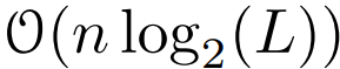 et l'espace O (nL). Les analyses parallèles utilisant des matrices diagonales fonctionnent également très efficacement, ne nécessitant que O (nL) FLOP.
et l'espace O (nL). Les analyses parallèles utilisant des matrices diagonales fonctionnent également très efficacement, ne nécessitant que O (nL) FLOP.
Résultats expérimentaux
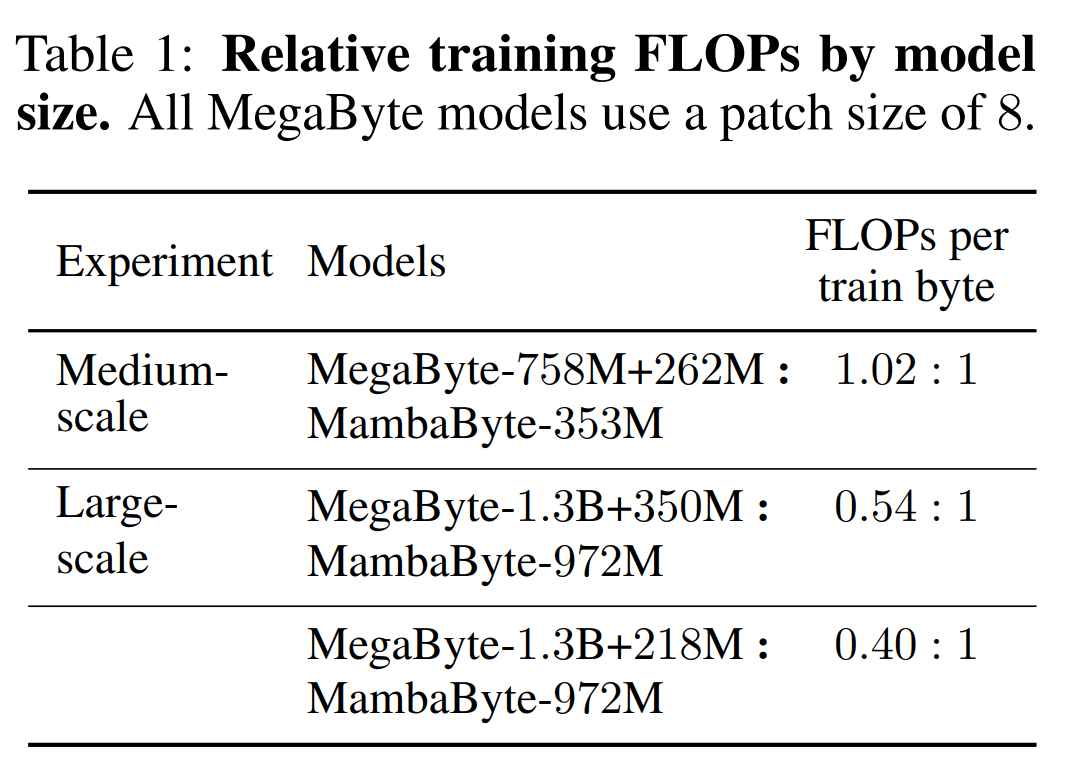
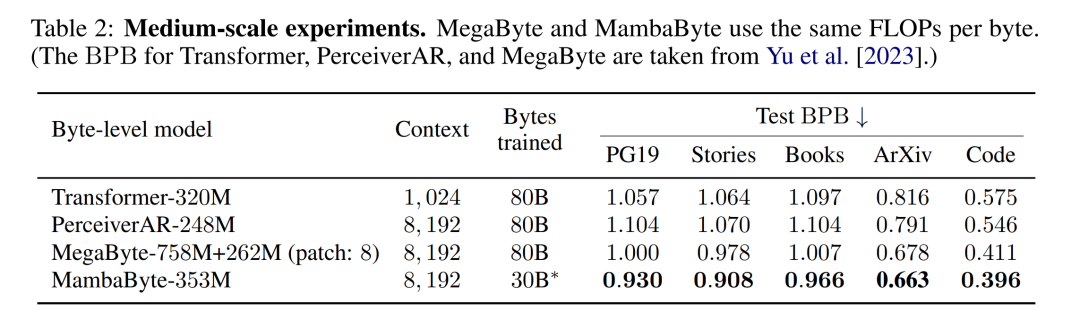
Le tableau 2 montre les bits par octet (BPB) pour chaque ensemble de données. Dans cette expérience, les modèles MegaByte758M+262M et MambaByte utilisent le même nombre de FLOP par octet (voir tableau 1). Les auteurs ont constaté que MambaByte surpassait systématiquement MegaByte sur tous les ensembles de données. De plus, les auteurs notent qu'en raison de contraintes de financement, ils n'ont pas pu entraîner MambaByte sur la totalité des 80 Mo d'octets, mais MambaByte a quand même surpassé MegaByte avec 63 % de calculs en moins et 63 % de données d'entraînement en moins. De plus, MambaByte-353M surpasse Transformer et PerceiverAR à l’échelle des octets.
Pourquoi MambaByte fonctionne-t-il mieux qu'un modèle beaucoup plus grand en si peu d'étapes de formation ? La figure 1 explore plus en détail cette relation en examinant des modèles avec le même nombre de paramètres. La figure montre que pour les modèles MegaByte de même taille de paramètre, le modèle avec moins de correctifs d'entrée fonctionne mieux, mais après avoir calculé la normalisation, ils fonctionnent de manière similaire. En fait, le Transformer complet, bien que plus lent en termes absolus, fonctionne également de manière similaire à MegaByte après normalisation informatique. En revanche, le passage à l’architecture Mamba peut améliorer considérablement l’utilisation des calculs et les performances du modèle.
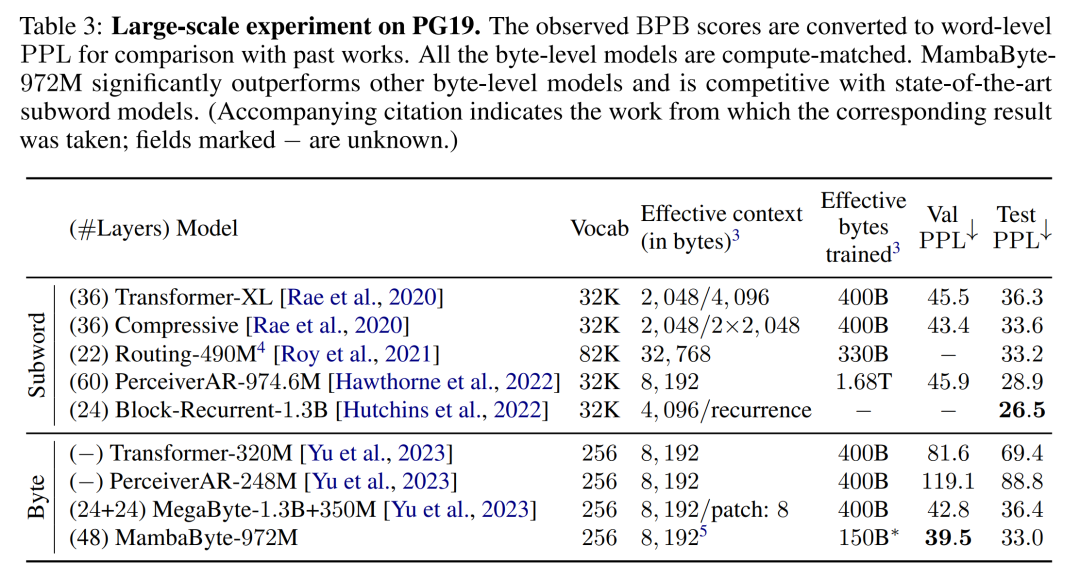
Sur la base de ces résultats, le tableau 3 compare des versions plus grandes de ces modèles sur l'ensemble de données PG19. Dans cette expérience, les auteurs ont comparé MambaByte-972M avec MegaByte-1.3B+350M et d'autres modèles au niveau octet ainsi qu'avec plusieurs modèles de sous-mots SOTA. Ils ont constaté que MambaByte-972M surpassait tous les modèles au niveau octet et était compétitif par rapport aux modèles de sous-mots, même lorsqu'il était formé sur seulement 150 octets.
Génération de texte. L'inférence autorégressive dans les modèles Transformer nécessite la mise en cache de l'intégralité du contexte, ce qui affecte considérablement la vitesse de génération. MambaByte n'a pas ce goulot d'étranglement car il ne conserve qu'un seul état caché variable dans le temps par couche, donc le temps par étape de génération est constant. Le tableau 4 compare la vitesse de génération de texte de MambaByte-972M et MambaByte-1.6B avec MegaByte-1.3B+350M sur un GPU PCIe A100 de 80 Go. Bien que MegaByte réduise considérablement le coût de génération grâce aux correctifs, ils ont observé que MambaByte est 2,6 fois plus rapide avec des paramètres similaires en raison de l'utilisation de la génération de boucles.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment implémenter la fonction contain dans les chaînes python
- Raisons pour lesquelles l'IA ne peut pas colorier en temps réel
- Le routage est la fonction principale de quelle couche dans le modèle osi
- Quel logiciel peut être utilisé pour ouvrir et modifier les fichiers ai ?
- Quel logiciel est le plugin Tencent Qqmail ?