
Maison >Périphériques technologiques >IA >Les données sont reines ! Comment construire étape par étape un algorithme de conduite autonome efficace à partir des données ?
Les données sont reines ! Comment construire étape par étape un algorithme de conduite autonome efficace à partir des données ?

- PHPzavant
- 2024-02-02 12:03:14921parcourir
Écrit avant et compréhension personnelle de l'auteur
La prochaine génération de technologie de conduite autonome devrait s'appuyer sur une intégration spécialisée et une interaction entre la perception intelligente, la prédiction, la planification et le contrôle de bas niveau. Il y a toujours eu un énorme goulot d'étranglement dans la limite supérieure des performances des algorithmes de conduite autonome. Les universitaires et l'industrie conviennent que la clé pour surmonter ce goulot d'étranglement réside dans la technologie de conduite autonome centrée sur les données. La simulation AD, la formation de modèles en boucle fermée et le moteur Big Data AD ont récemment acquis une expérience précieuse. Cependant, il existe un manque de connaissances systématiques et de compréhension approfondie de la manière de créer une technologie AD efficace centrée sur les données pour réaliser l’auto-évolution des algorithmes AD et une meilleure accumulation de Big Data AD. Pour combler cette lacune en matière de recherche, nous accorderons ici une attention particulière à la dernière technologie de conduite autonome basée sur les données, en nous concentrant sur une classification complète des ensembles de données de conduite autonome, comprenant principalement les jalons, les fonctionnalités clés, les paramètres de collecte de données, etc. En outre, nous avons mené un examen systématique du pipeline de Big Data AD en boucle fermée de référence existant à la frontière de l'industrie, y compris le processus, les technologies clés et la recherche empirique du cadre en boucle fermée. Enfin, les orientations de développement futures, les applications potentielles, les limites et les préoccupations sont discutées afin de susciter des efforts conjoints de la part du monde universitaire et de l'industrie pour promouvoir le développement ultérieur de la conduite autonome.
En résumé, les principales contributions sont les suivantes :
- Présentation de la première taxonomie complète d'ensembles de données de conduite autonome classés par générations jalons, tâches modulaires, suites de capteurs et fonctions clés
- Basé sur un modèle d'apprentissage profond et d'intelligence artificielle générative ; un examen systématique des pipelines de conduite autonome basés sur les données en boucle fermée les plus avancés et des technologies clés associées
- donne une étude empirique du fonctionnement du pipeline basé sur le Big Data en boucle fermée dans les applications industrielles de conduite autonome ; actuel Les avantages et les inconvénients du pipeline
- et des solutions, ainsi que les futures orientations de recherche sur la conduite autonome centrée sur les données.
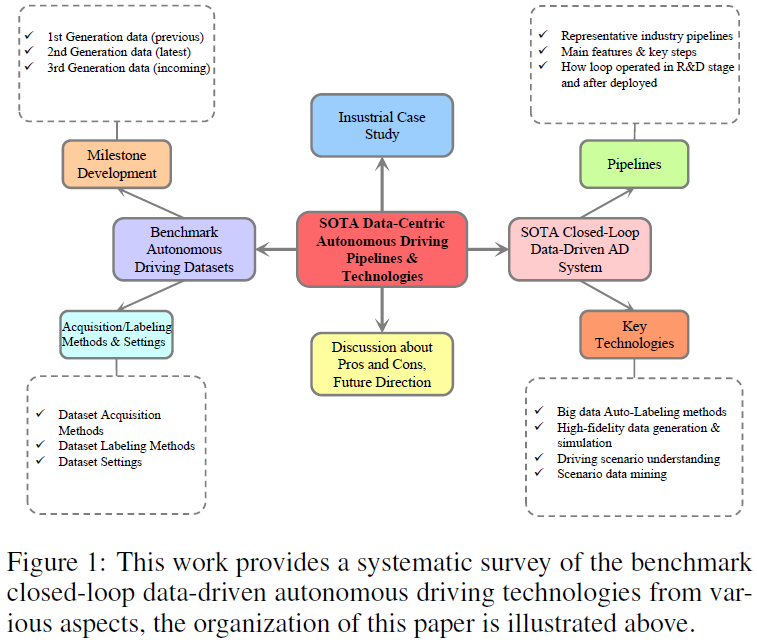
L'évolution de l'ensemble de données sur la conduite autonome reflète les avancées technologiques et les ambitions croissantes dans le domaine. Les premières recherches AVT menées à l'Institute of Advancement et dans le cadre du programme PATH de l'Université de Californie à Berkeley, à la fin du XXe siècle, ont jeté les bases des données de base des capteurs, mais elles étaient limitées par le niveau technologique de l'époque. Les deux dernières décennies ont été marquées par des progrès significatifs, grâce aux progrès de la technologie des capteurs, de la puissance de calcul et des algorithmes sophistiqués d’apprentissage automatique. En 2014, la Society of Automotive Engineers (SAE) a annoncé au public un système de conduite autonome systématique à six niveaux (L0-L5), largement reconnu par les progrès de la recherche et du développement en matière de conduite autonome. Poussées par l’apprentissage profond, les méthodes basées sur la vision par ordinateur ont dominé la perception intelligente. L'apprentissage par renforcement profond et ses variantes apportent des améliorations cruciales en matière de planification et de prise de décision intelligentes. Récemment, les grands modèles de langage (LLM) et les modèles de langage visuel (VLM) ont démontré leur puissante compréhension des scènes, leur raisonnement et leur prédiction du comportement de conduite, ainsi que leurs capacités de prise de décision intelligente, ouvrant de nouvelles possibilités pour le développement futur de la conduite autonome.
Évolution importante des ensembles de données de conduite autonomeLa figure 2 montre l'évolution importante des ensembles de données de conduite autonome open source par ordre chronologique. Des progrès significatifs ont conduit à la classification des ensembles de données traditionnels en trois générations, caractérisées par des progrès significatifs en termes de complexité, de volume, de diversité de scènes et de granularité des annotations, poussant le domaine vers une nouvelle frontière de maturité technologique. Plus précisément, l'axe horizontal représente le calendrier de développement. L'en-tête de chaque ligne comprend le nom de l'ensemble de données, la modalité du capteur, la tâche appropriée, l'emplacement de collecte de données et les défis associés. Pour comparer davantage les ensembles de données d'une génération à l'autre, nous utilisons des graphiques à barres de couleurs différentes pour visualiser les tailles des ensembles de données perçues et prédites/planifiées. Les premières étapes, la première génération lancée en 2012, dirigées par KITTI et Cityscapes, ont fourni des images haute résolution pour les tâches de perception et ont servi de base aux progrès de référence dans les algorithmes de vision. Passant à la deuxième génération, des ensembles de données tels que NuScenes, Waymo et Argoverse 1 ont introduit une méthode multi-capteurs qui combine les données des caméras embarquées, des cartes de haute précision (cartes HD), du lidar, du radar, du GPS, de l'IMU, Les trajectoires et les objets environnants, intégrés ensemble, sont essentiels à la modélisation complète de l’environnement de conduite et aux processus de prise de décision. Plus récemment, NuPlan, Argoverse 2 et Lyft L5 ont considérablement élevé la barre en matière d'impact, en fournissant une échelle de données sans précédent et en favorisant un écosystème propice à la recherche de pointe. Caractérisés par leur taille massive et l'intégration de capteurs multimodaux, ces ensembles de données ont joué un rôle important dans le développement d'algorithmes pour les tâches de détection, de prédiction et de planification, ouvrant la voie à des modèles avancés End2End ou de conduite autonome hybride. En 2024, nous inaugurerons la troisième génération d’ensembles de données sur la conduite autonome. Soutenu par VLM, LLM et d'autres technologies d'intelligence artificielle de troisième génération, l'ensemble de données de troisième génération met en évidence l'engagement de l'industrie à relever les défis de plus en plus complexes de la conduite autonome, tels que les problèmes de distribution de données à longue traîne, la détection hors distribution, analyse de cas d'angle, etc.
Acquisition, configuration et fonctionnalités clés de l'ensemble de données
Le tableau 1 résume la configuration de l'acquisition et de l'annotation des données de l'ensemble de données de perception très influent, y compris les scénarios de conduite, les suites de capteurs et les annotations. Nous rapportons la météo/le nombre total de catégories de temps/de conditions de conduite. , où le temps comprend généralement du soleil/nuageux/brouillard/pluie/neige/autre (les conditions extrêmes de la journée incluent généralement le matin, l'après-midi et le soir). Les conditions de conduite incluent généralement les rues de la ville, les artères, les rues secondaires, les zones rurales et les autoroutes ; , tunnels, parkings, etc. Plus les scénarios sont diversifiés, plus l’ensemble de données est puissant. Nous rapportons également la région où l'ensemble de données a été collecté, notée (Asie), UE (Europe), NA (Amérique du Nord), SA (Amérique du Sud), AU (Australie), AF (Afrique). Il convient de noter que Mapillary est collecté via AS/EU/NA/SA/AF/AF, et DAWN est collecté à partir des moteurs de recherche d'images Google et Bing. Pour la suite de capteurs, nous avons examiné les caméras, le lidar, le GPS, l'IMU, etc. FV et SV dans le tableau 1 sont respectivement les abréviations de caméra de vue frontale et de caméra de vue de rue. Une configuration de caméra panoramique à 360° se compose généralement de plusieurs caméras de vue frontale, de caméras de vue rares et de caméras de vue latérale. Nous pouvons observer qu’avec le développement de la technologie AD, le type et le nombre de capteurs inclus dans l’ensemble de données augmentent et les modèles de données deviennent de plus en plus diversifiés. En ce qui concerne l'annotation des ensembles de données, les premiers ensembles de données utilisaient généralement des méthodes d'annotation manuelle, tandis que les récents NuPlan, Argoverse 2 et DriveLM ont adopté la technologie d'annotation automatique pour le Big Data AD. Nous pensons que la transition de l’annotation manuelle traditionnelle à l’annotation automatique constitue une tendance majeure de la conduite autonome centrée sur les données à l’avenir.
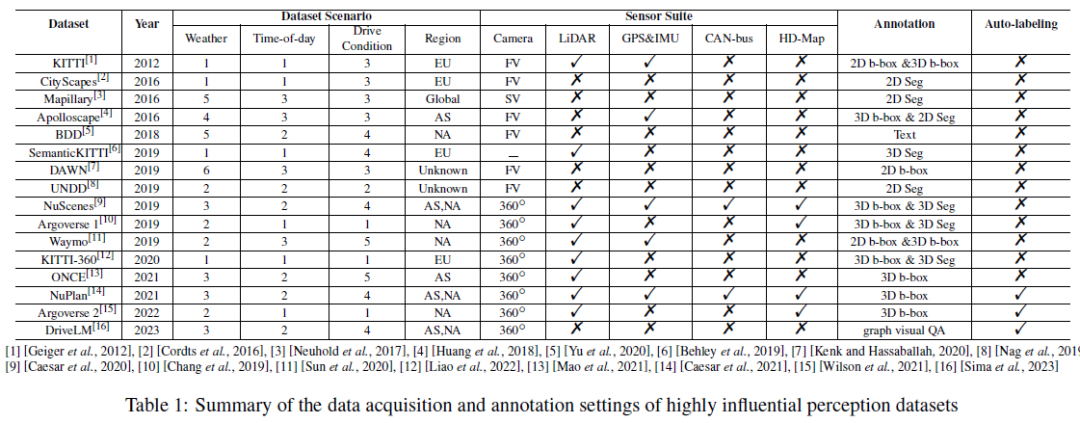
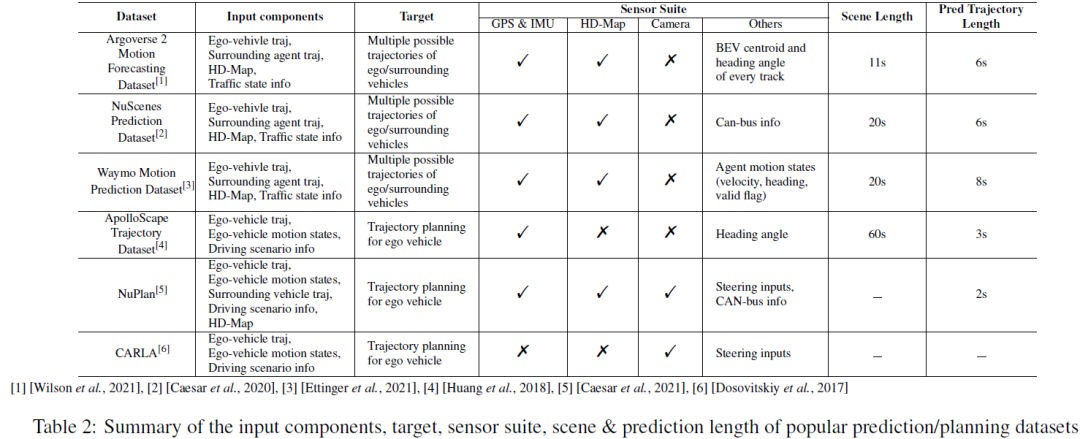
Pour les tâches de prédiction et de planification, nous résumons les composants d'entrée/sortie, les suites de capteurs, les longueurs de scène et les longueurs de prédiction des ensembles de données principaux dans le tableau 2. Pour les tâches de prédiction/prédiction de mouvement, les composants d'entrée incluent généralement la trajectoire historique du propre véhicule, la trajectoire historique des agents environnants, des cartes de haute précision et des informations sur l'état du trafic (c'est-à-dire l'état des feux de circulation, l'identification de la route, les panneaux d'arrêt, etc. ). Le résultat cible est constitué de plusieurs trajectoires les plus probables (telles que les 5 ou les 10 premières trajectoires) du véhicule autonome et/ou des sujets environnants sur une courte période de temps. Les tâches de prédiction de mouvement adoptent généralement un paramètre de fenêtre temporelle glissante pour diviser la scène entière en plusieurs fenêtres temporelles plus courtes. Par exemple, NuScenes utilise les 2 dernières secondes de données GT et des cartes de haute précision pour prédire la trajectoire des 6 prochaines secondes, tandis que Argoverse 2 utilise les 5 secondes historiques de vérité terrain et des cartes de haute précision pour prédire la trajectoire des 6 prochaines secondes. secondes. NuPlan, CARLA et ApoloScape sont les ensembles de données de tâches de planification les plus populaires. Les composants d'entrée comprennent des trajectoires historiques de véhicules autonomes et environnants, des états de mouvement de véhicules autonomes et des représentations de scènes de conduite. Alors que NuPlan et ApoloScape ont été obtenus dans le monde réel, CARLA est un ensemble de données simulées. CARLA contient des images routières prises lors de simulations de conduite dans différentes villes. Chaque image de route est associée à un angle de braquage, qui représente l'ajustement nécessaire pour maintenir le véhicule en mouvement. La longueur de prédiction du plan peut varier en fonction des exigences des différents algorithmes.
Système de conduite autonome basé sur les données en boucle fermée
Nous passons maintenant de l'ère précédente de la conduite autonome définie par logiciel et algorithme à la nouvelle ère inspirante de la conduite autonome collaborative basée sur le Big Data et les modèles intelligents . Le système basé sur les données en boucle fermée vise à combler le fossé entre la formation des algorithmes AD et son application/déploiement dans le monde réel. Contrairement aux approches traditionnelles en boucle ouverte, dans lesquelles les modèles sont entraînés passivement sur des ensembles de données collectées lors de la conduite de clients humains ou d'essais routiers, les systèmes en boucle fermée interagissent de manière dynamique avec l'environnement réel. Cette approche répond au défi de la variation de la distribution : les comportements appris à partir d'ensembles de données statiques peuvent ne pas se traduire par la nature dynamique des scénarios de conduite réels. Les systèmes en boucle fermée permettent aux AV d'apprendre des interactions et de s'adapter à de nouvelles situations, en s'améliorant grâce à des cycles itératifs d'action et de feedback.
Cependant, la création d'un système AD en boucle fermée centré sur les données réelles reste un défi en raison de plusieurs problèmes clés : Le premier problème est lié à la collecte de données AD. Dans la collecte de données réelles, la plupart des échantillons de données sont des scénarios de conduite courants/normaux, tandis que les données sur les courbes et les scénarios de conduite anormales sont presque impossibles à collecter. Deuxièmement, des efforts supplémentaires sont nécessaires pour explorer des méthodes d’annotation automatique précises et efficaces pour les données AD. Troisièmement, afin d'atténuer le problème des mauvaises performances des modèles AD dans certaines scènes en environnement urbain, il convient de mettre l'accent sur l'exploration des données de scène et la compréhension de la scène.
Pipeline de conduite autonome en boucle fermée SOTA
Le secteur de la conduite autonome construit activement une plate-forme Big Data intégrée pour faire face aux défis posés par l'accumulation de grandes quantités de données AD. C’est ce que l’on peut appeler à juste titre la nouvelle infrastructure de l’ère de la conduite autonome basée sur les données. Dans notre enquête sur les systèmes en boucle fermée basés sur les données développés par les principales sociétés/instituts de recherche AD, nous avons découvert plusieurs points communs :
- Ces pipeline suivent généralement un cycle de workflow, comprenant : (I) l'acquisition de données, (II) le stockage des données, (III) la sélection et le prétraitement des données, (IV) l'annotation des données, (V) la formation du modèle AD, (VI) simulation/validation des tests et (VII) déploiement dans le monde réel.
- Pour la conception de boucles fermées au sein du système, les solutions existantes choisissent soit de mettre en place séparément « boucle fermée données » et « boucle fermée modèle », soit de mettre en place différentes étapes de cycles : « étape R&D boucle fermée » et « étape déploiement ». boucle fermée".
- En outre, l'industrie a également souligné les problèmes de distribution à long terme des ensembles de données AD du monde réel et les défis liés à la gestion des cas particuliers. Tesla et NVIDIA sont des pionniers de l'industrie dans ce domaine, et leur architecture de système de données constitue une référence importante pour le développement de ce domaine.
Plate-forme NVIDIA MagLev AV Figure 3 (à gauche)) suit "Collecter → Sélectionner → Étiqueter → Entraîner le dragon" en tant que programme, qui est un flux de travail reproductible qui peut réaliser un apprentissage actif de SDC et effectuer une annotation intelligente dans la boucle. MagLev comprend principalement deux pipeline en boucles fermées. Le premier cycle est centré sur les données de conduite autonome, depuis l'ingestion de données et la sélection intelligente, en passant par l'annotation et l'annotation, puis la recherche et l'entraînement de modèles. Le modèle formé est ensuite évalué, débogué et finalement déployé dans le monde réel. La deuxième boucle fermée est le système de support de l'infrastructure de la plate-forme, y compris la dorsale du centre de données et l'infrastructure matérielle. Cette boucle comprend un traitement sécurisé des données, des KPI DNN et système évolutifs, des tableaux de bord pour le suivi et le débogage. Il prend en charge le cycle complet de développement audiovisuel, garantissant une amélioration continue et l'intégration des données du monde réel et des retours de simulation pendant le processus de développement.
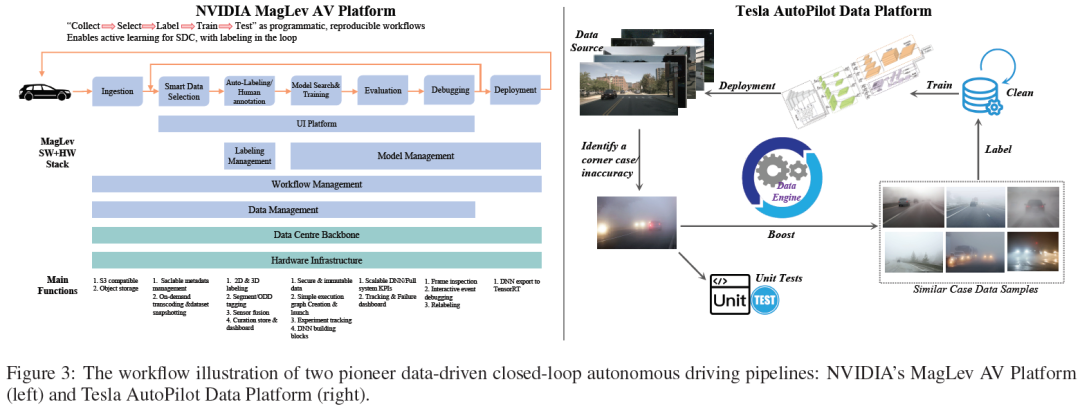
La plate-forme de données de conduite autonome Tesla (Figure 3 (à droite)) est une autre plate-forme AD représentative, qui met l'accent sur l'utilisation d'un pipeline en boucle fermée basé sur le Big Data pour améliorer considérablement les performances du modèle de conduite autonome. pipelineCommence par la collecte de données sources, généralement issues de l'apprentissage de la flotte Tesla, de la collecte de données côté véhicule déclenchée par un événement et du mode ombre. Les données collectées seront stockées, gérées et examinées par des algorithmes de plateforme de données ou des experts humains. Chaque fois qu'un cas d'angle/une inexactitude est découvert, le moteur de données récupère et fait correspondre des échantillons de données très similaires au cas d'angle/à l'inexactitude de la base de données existante. Parallèlement, des tests unitaires seront développés pour reproduire le scénario et tester rigoureusement la réponse du système. Les échantillons de données récupérés sont ensuite annotés par des algorithmes d'annotation automatique ou des experts humains. Les données bien annotées seront ensuite renvoyées à la base de données AD, qui sera mise à jour pour générer de nouvelles versions d'ensembles de données de formation pour les modèles de détection/prédiction/planification/contrôle AD. Après la formation du modèle, la vérification, la simulation et les tests réels, de nouveaux modèles AD plus performants seront publiés et déployés.
Génération et simulation de données AD haute fidélité basées sur l'IA générative
La plupart des échantillons de données AD collectés dans le monde réel sont des scénarios de conduite courants/normaux, dont nous avons déjà un grand nombre d'échantillons similaires dans la base de données. Cependant, pour collecter certains types d’échantillons de données AD à partir d’acquisitions réelles, nous aurions besoin de conduire pendant une durée exponentielle, ce qui n’est pas réalisable dans les applications industrielles. Par conséquent, les méthodes de génération et de simulation de données de conduite autonome haute fidélité ont attiré une grande attention de la communauté universitaire. CARLA est un simulateur open source pour la recherche sur la conduite autonome qui peut générer des données de conduite autonome dans divers paramètres spécifiés par l'utilisateur. La force de CARLA réside dans sa flexibilité, permettant aux utilisateurs de créer différentes conditions routières, scénarios de circulation et dynamiques météorologiques, ce qui facilite la formation et les tests complets du modèle. Cependant, en tant que simulateur, son principal inconvénient est le manque de domaines. Les données AD générées par CARLA ne peuvent pas simuler entièrement les effets physiques et visuels du monde réel ; les caractéristiques dynamiques et complexes de l'environnement de conduite réel ne sont pas représentées.
Récemment, des modèles mondiaux ont été utilisés pour la génération de données AD haute fidélité avec leurs concepts intrinsèques plus avancés et leurs performances plus prometteuses. Un modèle mondial peut être défini comme un système d’intelligence artificielle qui construit une représentation interne de l’environnement qu’il perçoit et utilise la représentation apprise pour simuler des données ou des événements dans l’environnement. L’objectif d’un modèle général du monde est de représenter et de simuler des situations et des interactions telles que les humains matures les rencontrent dans le monde réel. Dans le domaine de la conduite autonome, GAIA-1 et DriveDreamer sont des chefs-d'œuvre de génération de données basées sur des modèles mondiaux. GAIA-1 est un modèle d'intelligence artificielle générative qui réalise la génération d'image/vidéo à image/vidéo en prenant des images/vidéos brutes en entrée avec du texte et des invites d'action. Les modalités d'entrée de GAIA-1 sont codées dans une séquence unifiée de jetons. Ces annotations sont traitées par un transformateur autorégressif au sein du modèle mondial pour prédire les annotations d'image ultérieures. Le décodeur vidéo reconstruit ensuite ces annotations en sorties vidéo cohérentes avec une résolution temporelle améliorée, permettant la génération de contenu visuel dynamique et riche en contexte. DriveDreamer adopte de manière innovante un modèle de diffusion dans son architecture, en se concentrant sur la capture de la complexité des environnements de conduite réels. Son pipeline de formation en deux étapes permet d'abord au modèle d'apprendre les contraintes de trafic structurées, puis de prédire les états futurs, garantissant ainsi une solide compréhension environnementale adaptée aux applications de conduite autonome.
Méthode d'étiquetage automatique pour les ensembles de données de conduite autonome
Un étiquetage des données de haute qualité est essentiel au succès et à la fiabilité. Jusqu'à présent, l'annotation de donnéespipeline peut être divisée en trois types, allant de l'annotation manuelle traditionnelle à l'annotation semi-automatique en passant par les méthodes d'annotation entièrement automatiques de pointe, comme le montre la figure 4. L'annotation de données AD est généralement considérée en tant que /Modèle spécifique à la tâche. Le flux de travail commence par une préparation minutieuse des exigences relatives à la tâche d'annotation et à l'ensemble de données d'origine. Ensuite, l'étape suivante consiste à générer les résultats d'annotation initiaux à l'aide d'experts humains, d'algorithmes d'annotation automatique ou de grands modèles End2End. Ensuite, la qualité des annotations est vérifiée par des experts humains ou par des algorithmes de contrôle de qualité automatisés basés sur des exigences prédéfinies. Si les résultats d'annotation de ce cycle échouent au contrôle de qualité, ils sont à nouveau renvoyés au cycle d'annotation et ce travail d'annotation est répété jusqu'à ce qu'ils répondent aux exigences prédéfinies. Enfin, nous pouvons obtenir un ensemble de données AD étiqueté prêt à l’emploi.

proposé par Uber explore pour la première fois les marqueurs compatibles AD à l'échelle spatio-temporelle. Dans le domaine de la conduite autonome, le marquage de la boîte englobante de cible 3D à l'échelle spatiale et le marquage d'horodatage 1D correspondant à l'échelle de temps sont appelés marquage 4D. Le pipeline Auto4D commence par un nuage de points lidar continu pour établir les trajectoires initiales des objets. La trajectoire est affinée par la branche de taille cible, qui code et décode la taille cible à l'aide d'observations cibles. Dans le même temps, la branche de trajectoire de mouvement code les observations de trajectoire et le mouvement, permettant au décodeur de trajectoire d'affiner la trajectoire avec une taille de cible constante.
L'étiquetage automatique de scènes statiques 3D peut être considéré comme une génération HDMap, où les voies, les limites de route, les passages pour piétons, les feux de circulation et d'autres éléments pertinents de la scène de conduite doivent être étiquetés. Dans ce domaine, il existe plusieurs travaux de recherche intéressants : les méthodes basées sur la vision, telles que MVMap, NeMO ; les méthodes basées sur le lidar, telles que VMA ; les méthodes de reconstruction de scènes 3D pré-entraînées, telles que OccBEV, OccNet/ADPT, ALO. VMA est un travail récemment proposé pour l'étiquetage automatique de scènes statiques 3D. Le cadre VMA utilise des nuages de points lidar agrégés à plusieurs voyages et participatifs pour reconstruire des scènes statiques et les segmenter en unités à traiter. L'annotateur d'unité basé sur MapTR code l'entrée brute dans des cartes de caractéristiques par interrogation et décodage, générant ainsi des séquences de points sémantiquement typées. Le résultat de VMA est une carte vectorisée, qui sera affinée grâce à une annotation en boucle fermée et une vérification manuelle pour fournir une carte de haute précision satisfaisante pour la conduite autonome.
Étude empirique
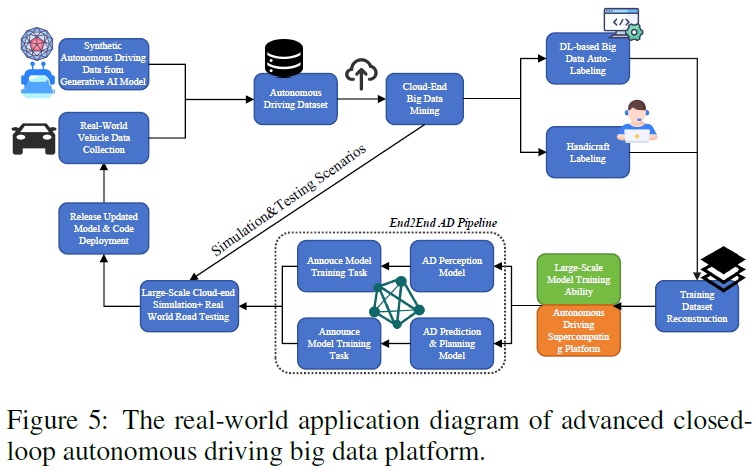
Nous proposons une étude empirique pour mieux illustrer la plate-forme avancée de données AD en boucle fermée mentionnée dans cet article. Le diagramme de processus complet est présenté à la figure 5. Dans ce cas, l'objectif des chercheurs est de développer un pipeline AD big data en boucle fermée basé sur l'IA générative et divers algorithmes basés sur l'apprentissage profond, permettant ainsi la phase de développement de l'algorithme de conduite autonome et la phase de mise à niveau OTA (après le monde réel). déploiement) pour réaliser une boucle fermée de données. Plus précisément, le modèle d'intelligence artificielle généré est utilisé pour (1) générer des données AD haute fidélité pour des scénarios spécifiques basés sur des invites textuelles fournies par les ingénieurs. (2) Étiquetage automatique des mégadonnées AD pour préparer efficacement les étiquettes de vérité terrain.
Le diagramme montre deux boucles fermées. L'une des étapes les plus importantes est la phase de développement de l'algorithme de conduite autonome, qui commence par la collecte de données synthétiques de conduite autonome pour générer des modèles d'intelligence artificielle et des échantillons de données obtenus à partir de la conduite dans le monde réel. Ces deux sources de données sont intégrées dans un ensemble de données autonome et exploitées dans le cloud pour obtenir des informations précieuses. Ensuite, l'ensemble de données entre dans un double chemin d'étiquetage : un étiquetage automatique basé sur l'apprentissage en profondeur ou un étiquetage manuel manuel, garantissant la rapidité et la précision de l'annotation. Les données étiquetées sont ensuite utilisées pour entraîner le modèle sur une plate-forme de supercalcul de conduite autonome de grande capacité. Ces modèles sont testés sur des simulations et sur des routes réelles pour évaluer leur efficacité, conduisant à la sortie et au déploiement ultérieur de modèles de conduite autonome. Le plus petit concerne la phase de mise à niveau OTA après le déploiement dans le monde réel, qui implique des simulations cloud à grande échelle et des tests dans le monde réel pour collecter les inexactitudes/cas particuliers de l'algorithme AD. Les inexactitudes/cas mineurs identifiés sont utilisés pour éclairer la prochaine itération de tests et de mises à jour du modèle. Par exemple, supposons que nous découvrions que notre algorithme AD fonctionne mal dans un scénario de conduite de tunnel. Les courbes de tracé des tunnels identifiées seront immédiatement annoncées au Ring et mises à jour lors de la prochaine itération. Le modèle d'intelligence artificielle générative utilise des descriptions pertinentes de scènes de conduite de tunnel sous forme d'invites textuelles pour générer des échantillons de données de conduite de tunnel à grande échelle. Les données générées et les ensembles de données brutes seront intégrés aux simulations, aux tests et aux mises à jour des modèles. La nature itérative de ces processus est essentielle pour optimiser les modèles afin de s'adapter aux environnements difficiles et aux nouvelles données, tout en maintenant une précision et une fiabilité élevées des capacités de conduite autonome.
Discutez
de nouveaux ensembles de données de conduite autonome de la troisième génération et au-delà. Bien que les modèles de base tels que LLM/VLM aient connu du succès dans la compréhension du langage et la vision par ordinateur, il reste difficile de les appliquer directement à la conduite autonome. Il y a deux raisons à cela : D'une part, ces LLM/VLM doivent avoir la capacité d'intégrer et de comprendre pleinement le big data AD multi-sources (telles que les images/vidéos FOV, les points nuageux lidar, les cartes haute définition, données GPS/IMU, etc.), ce qui est plus efficace que Il est encore plus difficile de comprendre les images que nous voyons dans notre vie quotidienne. D'un autre côté, l'ampleur et la qualité des données existantes dans le domaine de la conduite autonome ne sont pas comparables à celles d'autres domaines (tels que la finance et les soins médicaux), ce qui rend difficile la prise en charge de la formation et de l'optimisation de LLM/VLM de plus grande capacité. Les mégadonnées destinées à la conduite autonome sont actuellement limitées en termes d'échelle et de qualité en raison de la réglementation, des problèmes de confidentialité et du coût. Nous pensons qu’avec les efforts conjoints de toutes les parties, la prochaine génération de Big Data AD sera considérablement améliorée en termes d’échelle et de qualité.
Prise en charge matérielle des algorithmes de conduite autonome. Les plates-formes matérielles actuelles ont réalisé des progrès significatifs, notamment avec l'émergence de processeurs spécialisés tels que les GPU et les TPU, qui fournissent l'énorme puissance de calcul parallèle essentielle aux tâches d'apprentissage profond. Les ressources informatiques hautes performances des infrastructures embarquées et cloud sont essentielles au traitement en temps réel des flux de données massifs générés par les capteurs des véhicules. Malgré ces progrès, il existe encore des limites en termes d’évolutivité, d’efficacité énergétique et de vitesse de traitement face à la complexité croissante des algorithmes de conduite autonome. L’interaction utilisateur-véhicule guidée VLM/LLM est un cas d’application très prometteur. Sur la base de cette application, des Big Data comportementales spécifiques à l'utilisateur peuvent être collectées. Cependant, les appareils VLM/LLM embarqués nécessiteront des normes élevées de ressources informatiques matérielles, et les applications interactives devraient avoir une faible latence. Par conséquent, il pourrait y avoir des modèles de conduite autonome légers à grande échelle dans le futur, ou la technologie de compression LLM/VLM sera étudiée plus en détail.
Recommandations personnalisées de conduite autonome basées sur les données de comportement des utilisateurs. Les voitures intelligentes sont passées d'un simple moyen de transport à la dernière extension d'applications dans les scénarios de terminaux intelligents. Par conséquent, on s'attend à ce que les véhicules équipés de fonctionnalités avancées de conduite autonome soient capables d'apprendre les préférences comportementales du conducteur, telles que le style de conduite et les préférences d'itinéraire, à partir des enregistrements de données de conduite historiques. Cela permettra aux voitures intelligentes de mieux s’aligner sur les véhicules préférés des utilisateurs à l’avenir, car elles aideront les conducteurs à contrôler leur véhicule, à prendre des décisions de conduite et à planifier leur itinéraire. Nous appelons le concept ci-dessus un algorithme personnalisé de recommandation de conduite autonome. Les systèmes de recommandation ont été largement utilisés dans les domaines du commerce électronique, des achats en ligne, de la livraison de nourriture, des médias sociaux et des plateformes de diffusion en direct. Cependant, dans le domaine de la conduite autonome, les recommandations personnalisées en sont encore à leurs balbutiements. Nous pensons que dans un avenir proche, un système de données et un mécanisme de collecte de données plus appropriés seront conçus pour collecter des données volumineuses sur les préférences de comportement de conduite des utilisateurs avec la permission de l'utilisateur et le respect des réglementations en vigueur, obtenant ainsi des recommandations de conduite autonome personnalisées pour les utilisateurs. .
Sécurité des données et conduite autonome fiable. La quantité massive de données de conduite autonome pose des défis majeurs en matière de sécurité des données et de protection de la vie privée des utilisateurs. À mesure que les technologies des véhicules autonomes connectés (CAV) et de l'Internet des véhicules (IoV) se développent, les véhicules deviennent de plus en plus connectés, et la collecte de données détaillées sur les utilisateurs, depuis les habitudes de conduite jusqu'aux itinéraires fréquents, a soulevé des inquiétudes quant à une éventuelle utilisation abusive des informations personnelles. Nous recommandons le besoin de transparence concernant les types de données collectées, les politiques de conservation et le partage avec des tiers. Il souligne l’importance du consentement et du contrôle de l’utilisateur, notamment en honorant les demandes « ne pas suivre » et en offrant la possibilité de supprimer les données personnelles. Pour le secteur de la conduite autonome, protéger ces données tout en promouvant l’innovation nécessite le strict respect de ces directives, garantissant la confiance des utilisateurs et le respect de l’évolution de la législation sur la confidentialité.
Outre la sécurité et la confidentialité des données, un autre problème est de savoir comment parvenir à une conduite autonome digne de confiance. Avec le formidable développement de la technologie AD, les algorithmes intelligents et les modèles d'intelligence artificielle générative (tels que LLM, VLM) « agiront comme des facteurs déterminants » lors de l'exécution de décisions et de tâches de conduite de plus en plus complexes. Dans ce domaine, une question naturelle se pose : les humains peuvent-ils faire confiance aux modèles de conduite autonome ? À notre avis, la clé de la fiabilité réside dans l’interprétabilité des modèles de conduite autonome. Ils devraient être capables d’expliquer à un conducteur humain les raisons d’une décision, et pas seulement d’effectuer l’action de conduite. LLM/VLM devrait améliorer la conduite autonome fiable en fournissant un raisonnement avancé et des explications compréhensibles en temps réel.
Conclusion
Cette enquête fournit le premier examen systématique de l'évolution centrée sur les données dans la conduite autonome, y compris les systèmes Big Data, l'exploration de données et les technologies en boucle fermée. Dans cette enquête, nous développons d'abord une taxonomie des ensembles de données par génération de jalons, examinons le développement des ensembles de données AD tout au long de la chronologie historique et introduisons l'acquisition, la configuration et les fonctionnalités clés des ensembles de données. En outre, nous développons le système de conduite autonome basé sur les données en boucle fermée du point de vue académique et industriel. Le workflowpipeline, les processus et les technologies clés dans les systèmes en boucle fermée centrés sur les données sont discutés en détail. Grâce à des recherches empiriques, le taux d'utilisation et les avantages de la plate-forme AD en boucle fermée centrée sur les données dans le développement d'algorithmes et les mises à niveau OTA sont démontrés. Enfin, les avantages et les inconvénients des technologies de conduite autonome basées sur les données existantes ainsi que les futures orientations de recherche sont discutés en détail. L'accent est mis sur les nouveaux ensembles de données, la prise en charge matérielle, les recommandations AD personnalisées et la conduite autonome explicable après la troisième génération. Nous avons également exprimé nos inquiétudes quant à la fiabilité des modèles d'IA générative, à la sécurité des données et au développement futur de la conduite autonome.

Lien original : https://mp.weixin.qq.com/s/YEjWSvKk6f-TDAR91Ow2rA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les quatre modèles courants de développement de logiciels ?
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?
- La technologie de compression audio augmentera-t-elle le débit binaire du flux ?
- Conduite autonome et technologie de réseau intelligent en Java
- Comment définir la taille de la police du simulateur de foudre