
Maison >Périphériques technologiques >IA >Avertissement! Détection LiDAR longue distance
Avertissement! Détection LiDAR longue distance

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-02-02 11:33:311240parcourir
1. Introduction
Après la tenue du Tucson AI Day l'année dernière, j'ai toujours eu l'idée de résumer notre travail en perception à longue distance sous forme de texte. Il m'est arrivé d'avoir du temps récemment, alors j'ai décidé d'écrire un article pour enregistrer le processus de recherche au cours des dernières années. Le contenu couvert dans cet article peut être trouvé dans la vidéo Tucson AI Day [0] et dans nos articles publiés publiquement, mais il ne contient pas de détails techniques spécifiques ni de secrets techniques.
Comme nous le savons tous, Tucson se concentre sur la technologie de conduite autonome de camions. Les camions ont des distances de freinage plus longues et des changements de voie plus longs que les voitures. En conséquence, Tucson dispose d’un avantage unique pour rivaliser avec d’autres entreprises de conduite autonome. En tant que membre de Tucson, je suis responsable de la technologie de détection LiDAR, et je vais maintenant présenter en détail le contenu associé à l'utilisation du LiDAR pour la détection longue distance.
Lorsque l'entreprise a rejoint l'entreprise, la solution de détection LiDAR traditionnelle était généralement la solution BEV (Bird's Eye View). Cependant, BEV n'est pas ici l'abréviation du célèbre véhicule électrique à batterie, mais fait référence à une solution qui projette des nuages de points LiDAR dans l'espace BEV et combine des têtes de convolution 2D et de détection 2D pour la détection de cibles. Personnellement, je pense que la technologie de détection LiDAR utilisée par Tesla devrait être appelée « la technologie de fusion des caméras multi-vues dans l'espace BEV ». Pour autant que je sache, le premier enregistrement de la solution BEV est l'article "MV3D" publié par Baidu lors de la conférence CVPR17 [1]. De nombreux travaux de recherche ultérieurs, y compris les solutions réellement utilisées par de nombreuses entreprises que je connais, adoptent tous la méthode de projection de nuages de points LiDAR dans l'espace BEV pour la détection de cibles, et peuvent être classés comme solutions BEV. Cette solution est largement utilisée dans des applications pratiques. Pour résumer, lorsque j'ai rejoint l'entreprise pour la première fois, la solution de détection LiDAR traditionnelle projetait généralement le nuage de points LiDAR dans l'espace BEV, puis combinait une convolution 2D et une tête de détection 2D pour la détection de cibles. La technologie de détection LiDAR utilisée par Tesla peut être appelée « la technologie de fusion de caméras multi-vues dans l'espace BEV ». L'article « MV3D » publié par Baidu lors de la conférence CVPR17 était un des premiers exemples de la solution BEV. Par la suite, de nombreuses entreprises ont également adopté des solutions similaires pour la détection de cibles.
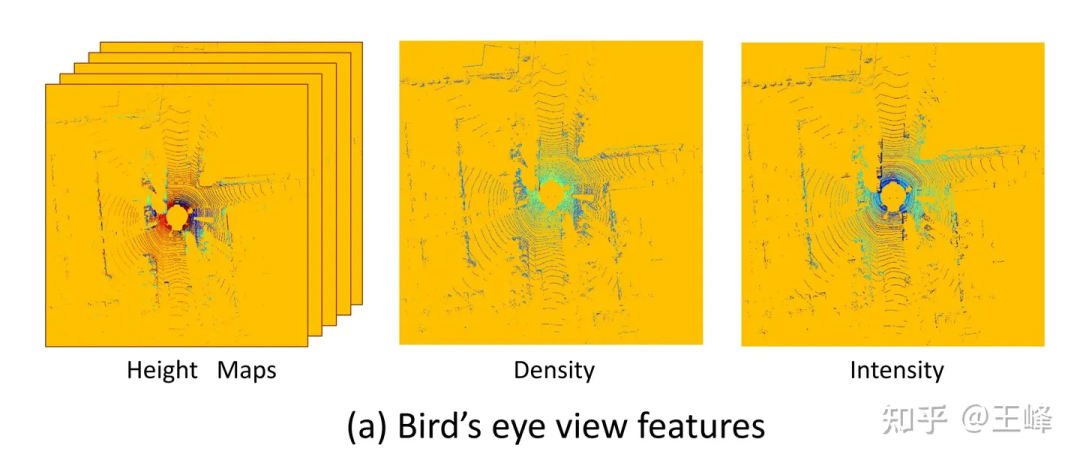 La fonction de perspective BEV utilisée par MV3D[1]
La fonction de perspective BEV utilisée par MV3D[1]
Un avantage majeur de la solution BEV est qu'elle peut appliquer directement des détecteurs 2D matures, mais elle présente également un inconvénient fatal : elle limite la plage de détection. Comme vous pouvez le voir sur l'image ci-dessus, puisqu'un détecteur 2D doit être utilisé, il doit former une carte de caractéristiques 2D. À ce stade, un seuil de distance doit être défini pour celui-ci. En fait, il y a encore des points LiDAR en dehors de la plage. de l'image ci-dessus, mais a été écarté par cette opération de troncature. Est-il possible d’augmenter le seuil de distance jusqu’à ce que l’emplacement soit couvert ? Ce n'est pas impossible à faire, mais le LiDAR a très peu de nuages de points au loin en raison de problèmes tels que le mode de balayage, l'intensité de la réflexion (atténuation avec la distance à la quatrième puissance), l'occlusion, etc., ce n'est donc pas rentable.
La communauté universitaire n'a pas prêté beaucoup d'attention à cette question du système BEV, principalement en raison des limites de l'ensemble des données. La plage d'annotation des ensembles de données grand public actuels est généralement inférieure à 80 mètres (comme les 50 mètres de nuScenes, les 70 mètres de KITTI et les 80 mètres de Waymo). Dans cette plage de distance, la taille de la carte des caractéristiques BEV n'a pas besoin d'être grande. Cependant, dans l'industrie, le LiDAR de moyenne portée utilisé peut généralement atteindre une portée de balayage de 200 mètres, et ces dernières années, certains LiDAR à longue portée ont été lancés, qui peuvent atteindre une portée de balayage de 500 mètres. Il convient de noter que la superficie et la quantité de calcul de la carte caractéristique augmentent quadratiquement à mesure que la distance augmente. Dans le cadre du projet BEV, la quantité de calcul requise pour gérer une portée de 200 mètres est déjà considérable, sans parler d'une portée de 500 mètres. Par conséquent, ce problème nécessite plus d’attention et de résolution dans l’industrie.
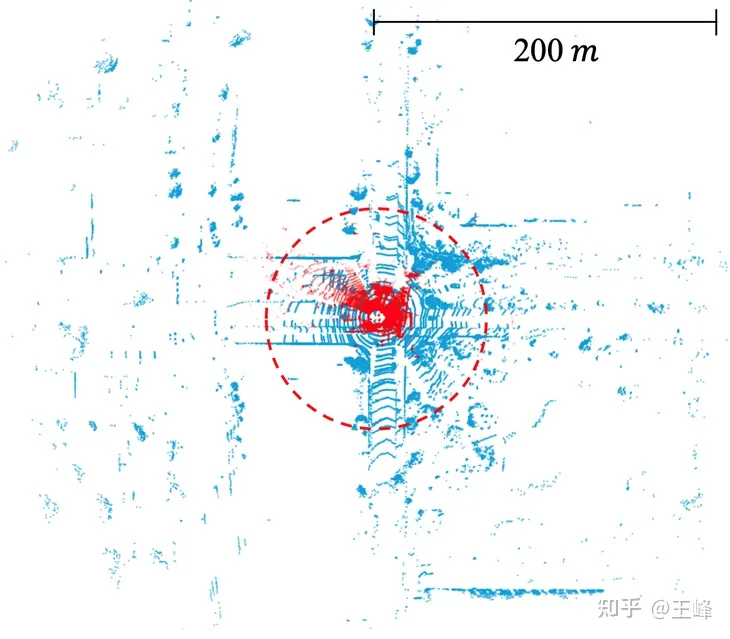
La plage de numérisation du lidar dans l'ensemble de données publiques. KITTI (point rouge, 70 m) contre Argoverse 2 (point bleu, 200 m)
Après avoir reconnu les limites de la solution BEV, nous avons finalement trouvé une alternative réalisable après des années de recherche. Le processus de recherche n’a pas été facile et nous avons connu de nombreux revers. Généralement, les articles et les rapports mettent uniquement l’accent sur les réussites et ne mentionnent pas les échecs, mais l’expérience de l’échec est également très précieuse. Nous avons donc décidé de partager notre parcours de recherche à travers un blog. Ensuite, je le décrirai étape par étape selon la chronologie.
2. Solution basée sur des points
Lors du CVPR19, les Chinois de Hong Kong ont publié un détecteur de nuages de points appelé PointRCNN [2]. Contrairement aux méthodes traditionnelles, PointRCNN effectue des calculs directement sur les données de nuages de points sans les convertir au format BEV (bird's eye view). Par conséquent, cette solution basée sur un nuage de points peut théoriquement réaliser une détection longue distance.
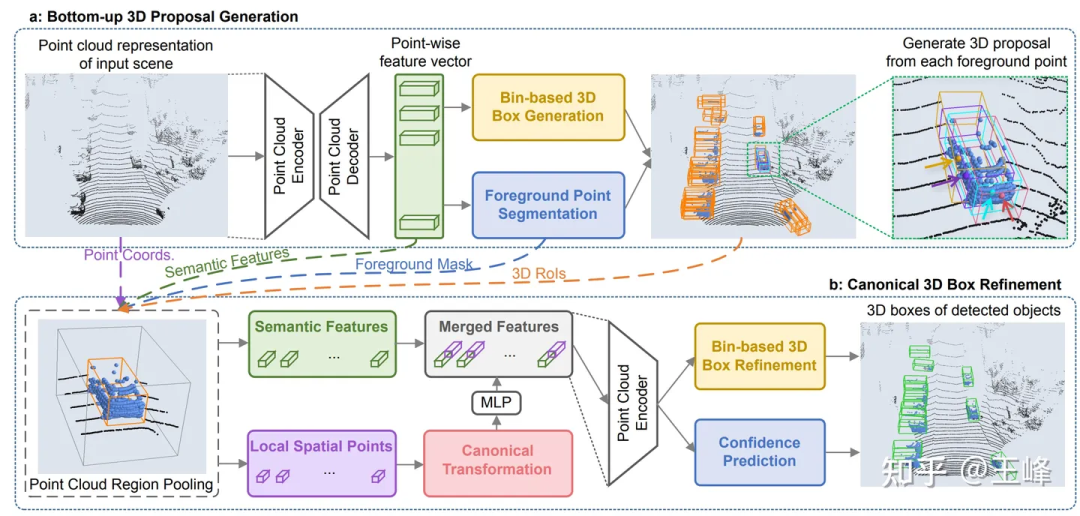
Mais nous avons découvert un problème après l'avoir essayé. Le nombre de nuages de points dans une image de KITTI peut être sous-échantillonné à 16 000 points pour la détection sans grande perte de points. Cependant, notre combinaison LiDAR contient plus de 100 000 points dans une image. , 10 fois évidemment, la précision de la détection sera grandement affectée. Si le sous-échantillonnage n'est pas effectué, il y a même des opérations O(n^2) dans le squelette de PointRCNN. Par conséquent, même si cela ne prend pas bev, le montant du calcul est toujours insupportable. Ces opérations fastidieuses sont principalement dues à la nature désordonnée du nuage de points lui-même, ce qui signifie que tous les points doivent être parcourus, qu'il s'agisse d'un sous-échantillonnage ou d'une récupération de voisinage. Étant donné que de nombreuses opérations sont impliquées et qu'il s'agit toutes d'opérations standard qui n'ont pas été optimisées, il n'y a aucun espoir d'optimisation en temps réel à court terme, cette voie a donc été abandonnée.
Cependant, cette recherche n'est pas vaine. Bien que la quantité de calcul du backbone soit trop importante, sa deuxième étape n'est effectuée qu'au premier plan, la quantité de calcul est donc encore relativement faible. Après avoir appliqué directement le deuxième étage de PointRCNN au détecteur de premier étage du schéma BEV, la précision du cadre de détection sera grandement améliorée. Au cours du processus de candidature, nous avons également découvert un petit problème. Après l'avoir résolu, nous l'avons résumé et publié dans un article [3] publié sur CVPR21. Vous pouvez également le consulter sur ce blog :
Wang Feng : LiDAR. R- CNN : Un détecteur 3D à deux étages rapide et polyvalent
3. Solution Range-View
Après l'échec de la solution Point-based, nous avons tourné notre attention vers Range View Les LiDAR à l'époque étaient tous mécaniques. ceux en rotation. Par exemple, un lidar à 64 lignes scannera 64 lignes de nuages de points avec différents angles d'inclinaison. Par exemple, si chaque ligne scanne 2048 points, une image de portée 64*2048 peut être formée.
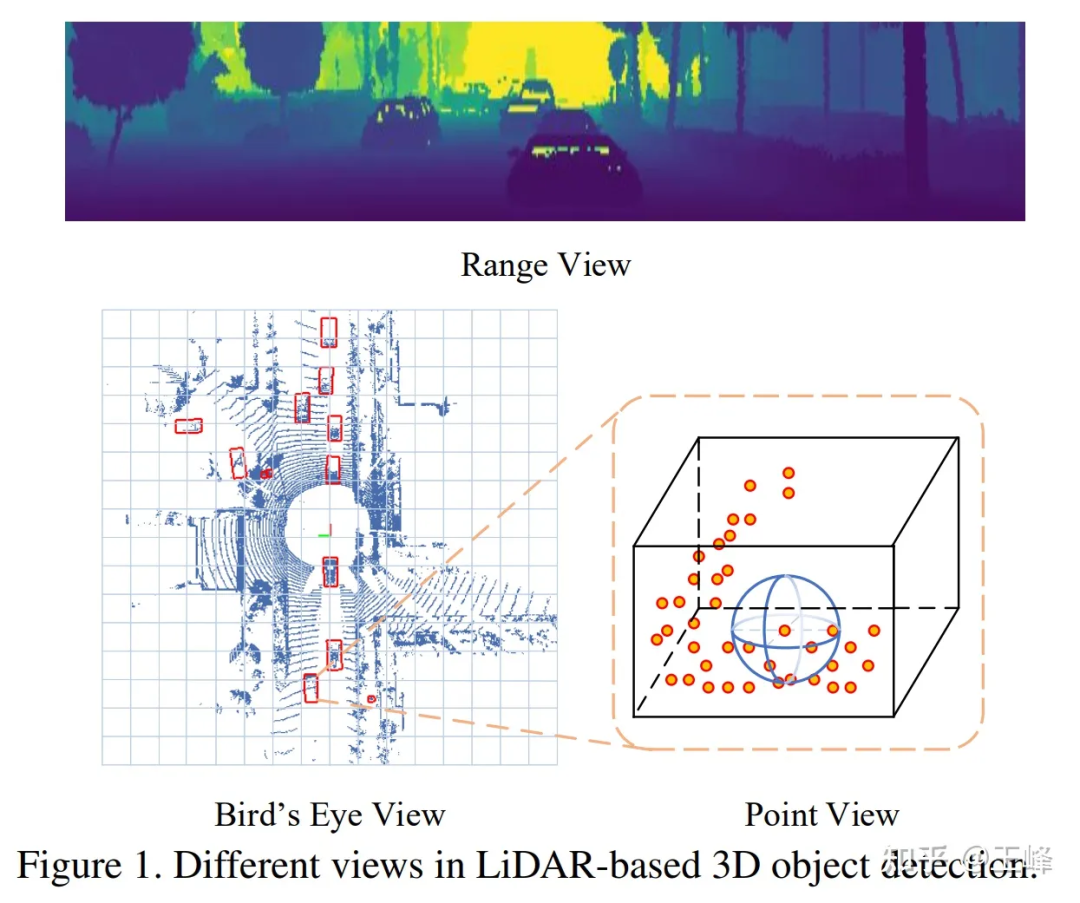 Comparaison de RV, BEV et PV
Comparaison de RV, BEV et PV
Dans Range View, le nuage de points n'est plus clairsemé mais densément disposé ensemble. Les cibles distantes sont seulement plus petites sur l'image de distance, mais elles ne seront pas jetées, donc. il peut théoriquement être détecté.
Peut-être parce qu'elle ressemble plus à l'image, la recherche sur le RV est en fait antérieure à celle sur le BEV. Le premier enregistrement que j'ai pu trouver provient également de l'article de Baidu [4]. Baidu est en réalité l'Académie militaire de conduite autonome de Whampoa. est RV La première application de BEV vient de Baidu.
J'ai donc essayé à ce moment-là. Par rapport à la méthode BEV, l'AP du RV a chuté de 30 à 40 points... J'ai trouvé que la détection sur l'image de plage 2D était en fait correcte, mais la sortie La 3D. l'effet de cadre est très mauvais. À cette époque, lorsque nous avons analysé les caractéristiques du RV, nous avons estimé qu'il présentait tous les inconvénients des images : des échelles d'objets non uniformes, des caractéristiques mixtes de premier plan et d'arrière-plan et des caractéristiques de cible à longue distance peu claires. avantage des riches fonctionnalités sémantiques des images, j'étais donc relativement pessimiste quant à cette solution à l'époque.
Parce que les employés formels doivent quand même faire le travail de mise en œuvre, il est préférable de laisser ces questions exploratoires aux stagiaires. Plus tard, j'ai recruté deux stagiaires pour étudier ce problème ensemble. Lorsque je l'ai essayé sur l'ensemble de données publiques, j'ai également perdu 30 points... Heureusement, les deux stagiaires ont été plus capables grâce à une série d'efforts et de références à d'autres. Quelques détails de l'article, les points ont été portés à un niveau similaire à la méthode BEV traditionnelle, et l'article final a été publié sur ICCV21 [5].
Bien que les points aient été augmentés, le problème n'a pas été complètement résolu à cette époque, il est devenu un consensus selon lequel le lidar a besoin d'une fusion multi-images pour améliorer le rapport signal/bruit. -Les cibles à distance doivent empiler des images pour augmenter la quantité d'informations. Dans la solution BEV, la fusion multi-trames est très simple. Il suffit d'ajouter un horodatage au nuage de points d'entrée puis de superposer plusieurs trames. L'ensemble du réseau peut être amélioré sans le modifier. Cependant, sous RV, de nombreuses astuces ont été modifiées et rien. a été obtenu.
Et à cette époque, le LiDAR est également passé de la rotation mécanique à l'état solide/semi-solide en termes de solutions techniques matérielles. La plupart des LiDAR solides/semi-solides ne peuvent plus former une image de distance, et la construction forcée d'une image de distance le fera. perdre des informations, donc cette voie a finalement été abandonnée.
4. Schéma Sparse Voxel
Comme mentionné précédemment, le problème avec le schéma basé sur les points est que la disposition irrégulière des nuages de points oblige à parcourir tous les nuages de points, ce qui entraîne des calculs excessifs. Schéma BEV Les données sont organisées mais il y a trop de zones vides, ce qui entraîne des calculs excessifs. En combinant les deux, il semble possible d'effectuer une voxélisation dans des zones pointillées pour la rendre régulière, et de ne pas l'exprimer dans des zones non pointillées pour éviter des calculs invalides. C'est la solution des voxels clairsemés.
Parce que Yan Yan, l'auteur de SECOND[6], a rejoint Tucson, nous avons essayé l'épine dorsale de la conv clairsemée au début. Cependant, comme spconv n'est pas une opération standard, le spconv implémenté par nous-mêmes est encore trop lent et insuffisant. La détection s'effectue en temps réel, parfois même plus lentement que la conv. dense, elle est donc mise de côté pour le moment.
Plus tard, le premier LiDAR capable de scanner 500 m : Livox Tele15 est arrivé, et l'algorithme de détection LiDAR longue portée était imminent. J'ai essayé la solution BEV mais elle était trop chère, j'ai donc réessayé la solution spconv car Tele15 Le fov est. relativement étroit et le nuage de points au loin est également très clairsemé, donc spconv peut à peine atteindre des performances en temps réel.
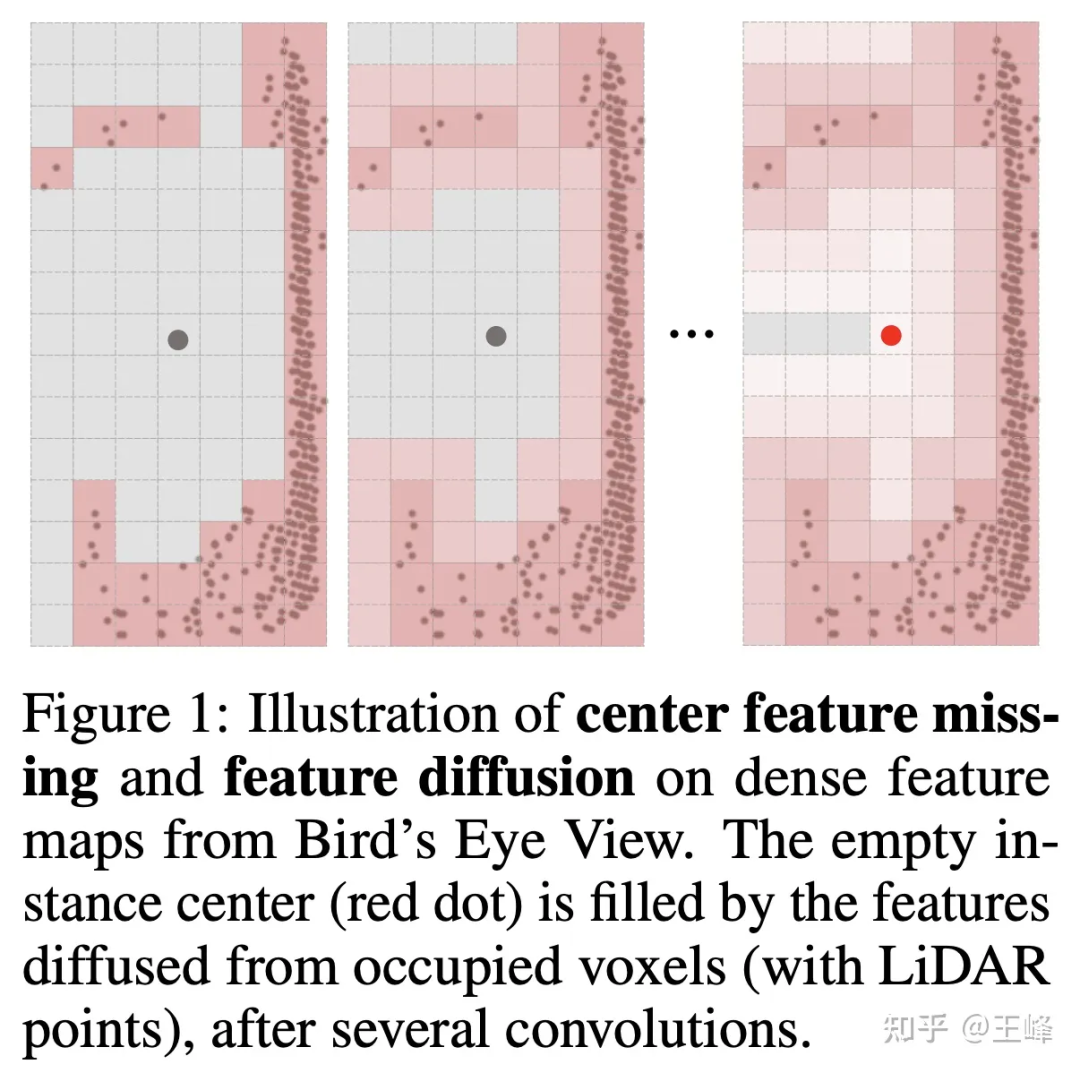
Mais si vous ne prenez pas bev, la tête de détection ne peut pas utiliser l'ancre ou l'attribution de centre plus mature dans la détection 2D. Ceci est principalement dû au fait que le lidar scanne la surface de l'objet et que la position centrale n'est pas nécessairement un point (comme). illustré dans la figure ci-dessous), sans point, il est naturellement impossible d'attribuer une cible au premier plan. En fait, nous avons essayé de nombreuses méthodes d'attribution en interne. Nous n'entrerons pas ici dans les détails des méthodes réelles utilisées par l'entreprise. Le stagiaire a également essayé un schéma d'attribution et l'a publié sur NIPS2022 [7].
明月不谙愿 : Détecteur d'objets 3D entièrement clairsemés
Mais si vous souhaitez appliquer cet algorithme à une combinaison LiDAR de 500 m en avant, 150 m en arrière et à gauche et à droite, c'est encore insuffisant. Il se trouve que le stagiaire s'est inspiré des idées de Swin Transformer et a écrit un article sur Sparse Transformer avant de courir après la popularité [8]. Il a également fallu beaucoup d'efforts pour améliorer petit à petit plus de 20 points (merci). au stagiaire pour m'avoir guidé, tql ). À cette époque, je sentais que la méthode Transformer était encore très adaptée aux données de nuages de points irréguliers, je l'ai donc également essayée sur l'ensemble de données de l'entreprise.
Malheureusement, cette méthode n'a toujours pas réussi à battre la méthode BEV sur l'ensemble de données de l'entreprise, et la différence est proche de 5 points. Avec le recul, il se peut qu'il y ait des astuces ou des compétences de formation que je ne maîtrise pas. raison pour laquelle la capacité d'expression de Transformer n'est pas plus faible que la conv, mais je n'ai pas réessayé plus tard. Cependant, à l'heure actuelle, la méthode d'affectation a été optimisée et a réduit de nombreux calculs, j'ai donc voulu réessayer spconv. Le résultat surprenant est que le remplacement direct du Transformer par spconv peut obtenir la même précision que la méthode BEV à courte distance. En fait, il peut également détecter des cibles à longue distance.
C'est également à cette époque que Yan Yan a réalisé la deuxième version de spconv[9]. La vitesse a été grandement améliorée, le retard de calcul n'était donc plus un goulot d'étranglement. Enfin, la perception LiDAR longue distance a surmonté tous les obstacles et a pu le faire. La voiture a démarré en temps réel.
Plus tard, nous avons mis à jour l'agencement LiDAR et augmenté la portée de balayage à 500 m en avant, 300 m en arrière et 150 m à gauche et à droite. Cet algorithme fonctionne également bien, je pense qu'à mesure que la puissance de calcul continue d'augmenter à l'avenir, le délai de calcul diminuera. . Cela devient de moins en moins problématique.
L'effet de détection longue distance final est présenté ci-dessous. Vous pouvez également regarder la position vers 01:08:30 de la vidéo Tucson AI Day pour voir l'effet de détection dynamique :
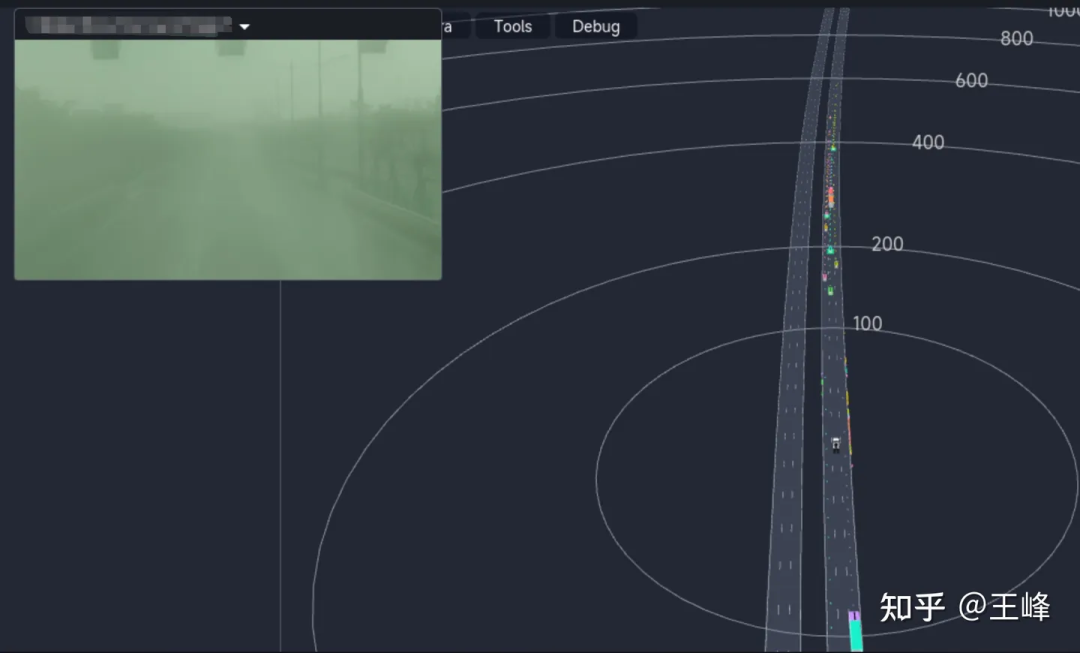
Bien qu'il s'agisse de la fusion finale. résultat, mais comme la visibilité de l'image brumeuse était très faible ce jour-là, les résultats provenaient essentiellement de la perception LiDAR.
V. Postscript
De la méthode basée sur les points à la méthode des images de distance, en passant par les méthodes Transformer et Sparse Conv basées sur un voxel clairsemé, l'exploration de la perception à longue distance ne peut pas être considérée comme une navigation fluide, elle est simplement une route pleine d'épines. Au final, c’est effectivement grâce à l’amélioration continue de la puissance de calcul et aux efforts continus de nombreux collègues que nous avons franchi cette étape. Je voudrais remercier Wang Naiyan, scientifique en chef de Tucson, ainsi que tous les collègues et stagiaires de Tucson. La plupart des idées et des mises en œuvre techniques n'ont pas été réalisées par moi. J'ai vraiment honte. Elles servent davantage de lien entre le passé et le futur.
Je n’avais pas écrit un article aussi long depuis longtemps. Il a été écrit comme un compte rendu sans former une histoire touchante. Ces dernières années, de moins en moins de collègues insistent pour faire du L4, et les collègues du L2 se sont progressivement tournés vers la recherche purement visuelle. La détection LiDAR est progressivement marginalisée visiblement à l'œil nu, même si je reste fermement convaincu qu'un capteur à portée directe supplémentaire est un meilleur choix. , mais les initiés de l’industrie semblent de plus en plus en désaccord. Alors que je vois de plus en plus de BEV et d'occupation sur les CV du sang frais, je me demande combien de temps la détection LiDAR peut continuer, et combien de temps je peux persister. L'écriture d'un tel article peut également servir de commémoration.
Je pleure tard dans la nuit, je ne comprends pas de quoi je parle, désolé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!