
Maison >Périphériques technologiques >IA >Le modèle de texte pur entraîne une représentation « visuelle » ! Dernière recherche du MIT : les modèles de langage peuvent dessiner des images à l'aide de code
Le modèle de texte pur entraîne une représentation « visuelle » ! Dernière recherche du MIT : les modèles de langage peuvent dessiner des images à l'aide de code

- 王林avant
- 2024-02-01 21:12:121171parcourir
Un grand modèle de langage qui ne peut que « lire » a-t-il une perception visuelle réelle ? En modélisant les relations entre les chaînes, que peut exactement apprendre un modèle de langage sur le monde visuel ?
Récemment, des chercheurs du Laboratoire d'informatique et d'intelligence artificielle du MIT (MIT CSAIL) ont évalué des modèles de langage, en se concentrant sur leurs capacités visuelles. Ils ont testé la capacité du modèle en lui demandant de générer et de reconnaître des concepts visuels de plus en plus complexes, depuis des formes et objets simples jusqu'à des scènes complexes. Les chercheurs ont également montré comment former un système d’apprentissage de représentation visuelle préliminaire à l’aide d’un modèle textuel uniquement. Avec cette recherche, ils ont jeté les bases d’un développement et d’une amélioration ultérieurs des systèmes d’apprentissage des représentations visuelles.

Lien papier : https://arxiv.org/abs/2401.01862
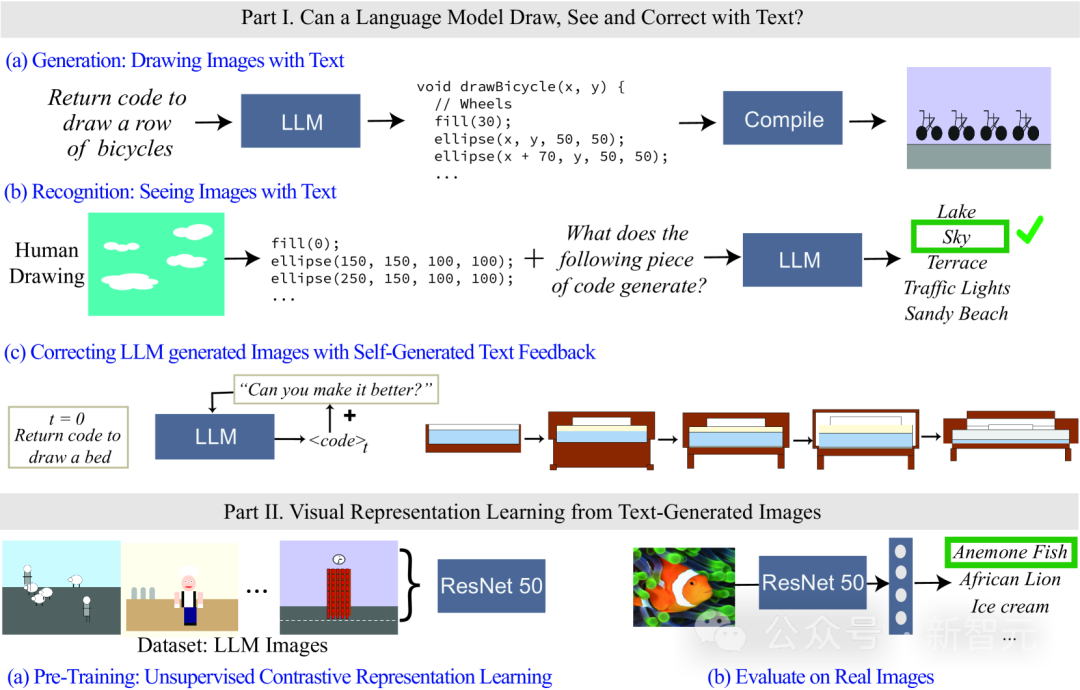
Étant donné que le modèle de langage ne peut pas traiter les informations visuelles, le code est utilisé pour restituer les images dans l'étude.
Bien que les images générées par LLM ne soient pas aussi réalistes que les images naturelles, à partir des résultats de génération et de l'autocorrection du modèle, il est capable de modéliser avec précision des chaînes/textes, ce qui permet au modèle de langage d'en apprendre davantage sur le monde visuel de nombreux concepts.
Les chercheurs ont également étudié des méthodes d'apprentissage auto-supervisé des représentations visuelles à l'aide d'images générées par des modèles de texte. Les résultats montrent que cette méthode a le potentiel d’être utilisée pour entraîner des modèles de vision et effectuer une évaluation sémantique d’images naturelles en utilisant uniquement LLM.
Concept visuel du modèle de langage
Posez d'abord une question : qu'est-ce que cela signifie pour les gens de comprendre le concept visuel de « grenouille » ?
Est-il suffisant de connaître la couleur de sa peau, combien de pattes il a, la position de ses yeux, à quoi il ressemble quand il saute, etc. ?
Les gens pensent souvent que pour comprendre le concept de grenouilles, il faut regarder des images de grenouilles et les observer sous plusieurs angles et scénarios réels.
Dans quelle mesure peut-on comprendre la signification visuelle de différents concepts si l'on observe uniquement le texte ?
Du point de vue de la formation du modèle, l'entrée de formation du grand modèle de langage (LLM) n'est constituée que de données textuelles, mais il a été prouvé que le modèle comprend des informations sur des concepts tels que la forme et la couleur, et peut même les convertir en vision. par transformation linéaire dans la représentation du modèle.
En d'autres termes, les modèles visuels et les modèles linguistiques sont très similaires en termes de représentation du monde.
Cependant, la plupart des méthodes existantes de caractérisation de modèle sont basées sur un ensemble d'attributs présélectionnés pour explorer les informations encodées par le modèle. Cette méthode ne peut pas étendre dynamiquement les attributs et nécessite également l'accès aux paramètres internes du modèle. .
Les chercheurs ont donc soulevé deux questions :
1. Que sait le modèle de langage sur le monde visuel ?
2. Est-il possible de former un système visuel pouvant être utilisé pour des images naturelles « en utilisant uniquement des modèles de texte » ?
Pour le savoir, les chercheurs ont mesuré quelles informations étaient incluses dans le modèle en testant différents modèles de langage lors du rendu (dessiner) et en reconnaissant (voir) des concepts visuels du monde réel. La capacité de capturer des attributs arbitraires sans avoir à former des classificateurs de fonctionnalités. individuellement pour chaque attribut.
Bien que les modèles de langage ne puissent pas générer d'images, les grands modèles tels que GPT-4 peuvent générer des codes pour le rendu des objets. Cet article utilise le processus d'invite textuelle -> code -> image pour augmenter progressivement la difficulté de rendu des objets pour mesurer le modèle. capacités.
Les chercheurs ont découvert que LLM est étonnamment efficace pour générer des scènes visuelles complexes composées de plusieurs objets et peut modéliser efficacement les relations spatiales, mais ne peut pas bien capturer le monde visuel, y compris les propriétés des objets, telles que les textures, la forme précise et contact superficiel avec d’autres objets dans l’image.
L'article évalue également la capacité du LLM à identifier les concepts perceptuels, les entrées de peintures représentées par des codes, et les codes incluent la séquence, la position et la couleur des formes, puis demande au modèle de langage de répondre au contenu visuel décrit dans les codes.

Les résultats expérimentaux ont révélé que le LLM est tout le contraire des humains : pour les humains, le processus d'écriture de code est difficile, mais il est facile de vérifier le contenu des images alors qu'il est difficile pour le modèle de le faire ; interpréter/reconnaître le contenu du code Mais cela peut générer des scènes complexes.
De plus, les résultats de la recherche prouvent également que la capacité de génération visuelle des modèles de langage peut être encore améliorée grâce à des corrections basées sur le texte.
Les chercheurs utilisent d'abord un modèle de langage pour générer du code qui illustre le concept, puis saisissent continuellement l'invite « améliorer son code généré » (améliorer le code généré) comme condition pour modifier le code. amélioré grâce à cette approche itérative Effet visuel.

Ensembles de données de capacité visuelle : pointage vers des scènes
Les chercheurs ont construit trois ensembles de données de description de texte pour mesurer la capacité du modèle à créer, reconnaître et modifier le code de rendu d'image, avec une complexité allant de faible à élevée. Formes et combinaisons simples. , objets et scènes complexes.

1. Formes et leurs compositions
contient des compositions de formes de différentes catégories, telles que des points, des lignes, des formes 2D et des formes 3D, avec 32 types de propriétés différentes telles que la couleur, texture, position et disposition spatiale.
L'ensemble complet de données contient plus de 400 000 exemples, dont 1 500 sont utilisés pour des tests expérimentaux.
2. Objets
Contient les 1000 objets les plus courants de l'ensemble de données ADE 20K, qui est plus difficile à générer et à reconnaître car il contient des combinaisons de formes plus complexes.
3. Les scènes
se composent de descriptions de scènes complexes, comprenant plusieurs objets et différents emplacements, et sont obtenues en échantillonnant de manière aléatoire et uniforme 1 000 descriptions de scènes à partir de l'ensemble de données MS-COCO.
Les concepts visuels de l'ensemble de données sont décrits dans le langage. Par exemple, la scène est décrite comme "une journée d'été ensoleillée sur une plage, avec un ciel bleu et un océan calme". .
Pendant le processus de test, il a été demandé à LLM de générer du code et de compiler les images rendues basées sur la scène représentée.
Résultats expérimentaux
Les tâches d'évaluation du modèle se composent principalement de trois :
1. Générer/dessiner du texte : Évaluer la capacité de LLM à générer du code de rendu d'image correspondant à un concept spécifique.
2. Reconnaître/afficher du texte : Testez les performances de LLM dans la reconnaissance des concepts visuels et des scènes représentés dans le code. Nous testons les représentations codées des dessins humains sur chaque modèle.
3. Correction des dessins à l'aide du retour textuel : évaluez la capacité de LLM à modifier de manière itérative son code généré à l'aide du retour en langage naturel qu'il génère.
L'invite de saisie du modèle dans le test est la suivante : écrivez du code dans le langage de programmation [nom du langage de programmation] qui dessine un [concept]
Puis compilez et restituez en fonction du code de sortie du modèle, et visuellement générer l'image La qualité et la diversité sont évaluées :
1. Fidélité
Calculez la fidélité entre l'image générée et la description réelle en récupérant la meilleure description de l'image. Le score CLIP est d'abord utilisé pour calculer l'accord entre chaque image et toutes les descriptions potentielles dans la même catégorie (forme/objet/scène), puis le classement des vraies descriptions est rapporté en pourcentage (par exemple, un score de 100 % signifie que le vrai concept est classé en premier).
2. Diversité
Pour évaluer la capacité du modèle à restituer différents contenus, les scores de diversité LPIPS sont utilisés sur des paires d'images qui représentent le même concept visuel.
3. Réalisme
Pour une collection échantillonnée d'images 1K d'ImageNet, utilisez la distance de création de Fréchet (FID) pour quantifier la différence de distribution entre les images naturelles et les images générées par LLM.
Dans l'expérience de comparaison, le modèle obtenu par Stable Diffusion a été utilisé comme référence.
Que peut visualiser le LLM ?
Les résultats de la recherche ont montré que LLM peut visualiser des concepts du monde réel à partir de l'ensemble de la hiérarchie visuelle, combiner deux concepts non liés (comme un gâteau en forme de voiture), générer des phénomènes visuels (tels que des images floues) et parvenir à interpréter correctement l'espace. Relations (telles que « une rangée de vélos » disposées horizontalement).
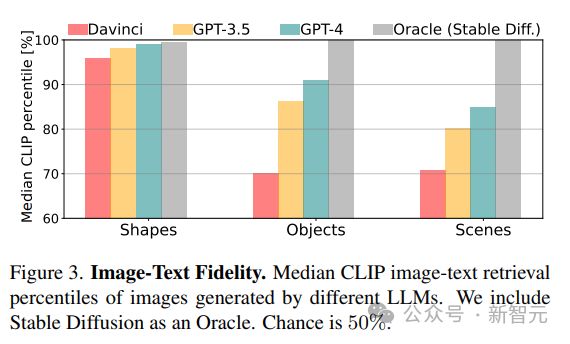
Comme prévu, d'après les résultats du score CLIP Voir, le les capacités du modèle diminuent à mesure que la complexité conceptuelle augmente des formes aux scènes.
Pour des concepts visuels plus complexes, tels que dessiner des scènes contenant plusieurs objets, GPT-3.5 et GPT-4 sont meilleurs que python-matplotlib et python-turtle pour dessiner des scènes avec des descriptions complexes en utilisant le traitement et tikz plus précis .
Pour les objets et les scènes, la partition CLIP montre que les concepts incluant « personnes », « véhicules » et « scènes extérieures » sont les plus faciles à dessiner. Cette capacité à restituer des scènes complexes vient de l'expressivité du code de rendu. Le modèle réside dans les capacités de programmation de chacun au sein du scénario et dans la qualité de la représentation interne des différents concepts impliqués.
Qu'est-ce que LLM ne peut pas visualiser ?
Dans certains cas, le modèle est difficile à dessiner même pour des concepts relativement simples, et les chercheurs ont résumé trois modes de défaillance courants :
1. Le modèle de langage ne peut pas gérer un ensemble de formes et de concepts spécifiques. organisation de l'espace ;
2. Dessin approximatif et manque de détails, le plus souvent observés dans Davinci, en particulier lors de l'utilisation de matplotlib et du codage de tortue ;
3. La description est incomplète, corrompue ou ne représente qu'un sous-ensemble d'un. concept (une catégorie typique de scénarios).
4. Tous les modèles ne peuvent pas dessiner de figures.
Diversité et réalisme
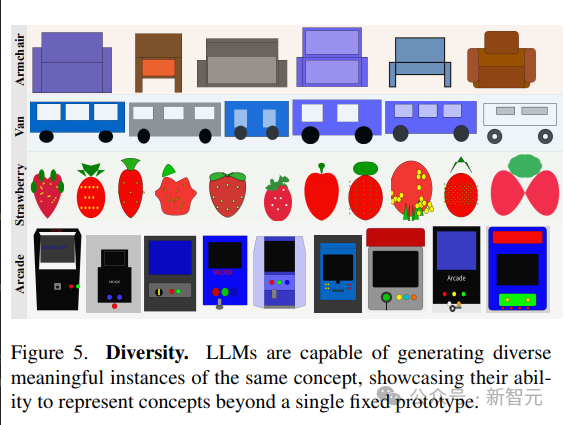
Les modèles linguistiques démontrent la capacité de générer différentes visualisations du même concept.
Afin de générer différents échantillons de la même scène, l'article compare deux stratégies :
1. Échantillonnage répété à partir du modèle
2. Échantillonnage d'une fonction paramétrée qui permet de modifier les paramètres à créer ; une nouvelle intrigue du concept.

La capacité du modèle à représenter diverses implémentations de concepts visuels se reflète dans le score de diversité élevé du LPIPS ; la capacité à générer des images diverses démontre que LLM est capable de représenter des concepts visuels de plusieurs manières, sans se limiter à un Prototype en série limitée.
Les images générées par LLM sont beaucoup moins réalistes que les images naturelles, et le modèle obtient des résultats très faibles en termes de métrique FID par rapport à Stable Diffusion, mais les modèles modernes fonctionnent mieux que les modèles plus anciens.
Apprentissage des systèmes visuels à partir du texte
Formation et évaluation
Les chercheurs ont utilisé le modèle visuel pré-entraîné obtenu par apprentissage non supervisé comme épine dorsale du réseau, en utilisant la méthode MoCo-v2 pour générer 1,3 million 384× en LLM Le modèle ResNet-50 est entraîné sur l'ensemble de données d'images 384 pour un total de 200 époques ; après l'entraînement, deux méthodes sont utilisées pour évaluer les performances du modèle entraîné sur chaque ensemble de données :
1. Classification ImageNet-1 k Entraînez la couche linéaire sur le squelette pendant 100 époques,
2 Utilisez la récupération des 5 voisins les plus proches (kNN) sur ImageNet-100.

Comme le montrent les résultats, le modèle formé en utilisant uniquement les données générées par LLM peut fournir de puissantes capacités de représentation pour les images naturelles sans avoir besoin de former des couches linéaires.
Analyse des résultats
Les chercheurs ont comparé les images générées par LLM avec celles générées par des programmes existants, y compris des programmes génératifs simples tels que les levaves mortes, les fractales et StyleGAN, pour générer des images très diverses.
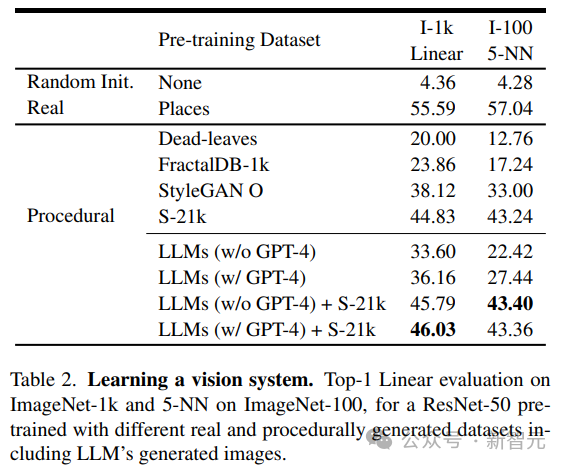
À en juger par les résultats, la méthode LLM est meilleure que les levaves mortes et les fractales, mais pas encore sota ; après inspection manuelle des données, les chercheurs ont attribué cette infériorité au manque de texture dans la plupart des LLM ; images générées.
Pour résoudre ce problème, les chercheurs ont combiné l'ensemble de données Shaders-21k avec des échantillons obtenus à partir de LLM pour générer des images riches en textures.
Comme le montrent les résultats, cette solution peut améliorer considérablement les performances et surpasser les autres solutions générées par un programme.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Fonctions du modèle TCP/IP à quatre couches
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?
- Vous ne trouvez pas le modèle pré-entraîné pour la parole chinoise ? Les versions chinoises Wav2vec 2.0 et HuBERT arrivent
- Comment résoudre les limites de l'entraînement de précision mixte de grands modèles
- Formation personnalisée de modèles d'apprentissage profond à l'aide de techniques d'apprentissage par transfert