
Maison >Périphériques technologiques >IA >Le taux de précision est inférieur à 20 %, GPT-4V/Gemini ne sait pas lire les bandes dessinées ! Premier benchmark de séquence d'images open source
Le taux de précision est inférieur à 20 %, GPT-4V/Gemini ne sait pas lire les bandes dessinées ! Premier benchmark de séquence d'images open source

- 王林avant
- 2024-02-01 19:06:131105parcourir
Le GPT-4V d’OpenAI et le grand modèle de langage multimodal Gemini de Google ont attiré l’attention de l’industrie et du monde universitaire. Ces modèles démontrent une compréhension approfondie de la vidéo dans plusieurs domaines, démontrant son potentiel sous différents angles. Ces avancées sont largement considérées comme une étape importante vers l’intelligence artificielle générale (AGI).
Mais si je vous dis que GPT-4V peut même mal interpréter le comportement des personnages de bandes dessinées, laissez-moi vous demander : Yuanfang, qu'en pensez-vous ?
Jetons un coup d'œil à cette mini série de bandes dessinées :
 Photos
Photos
Si vous laissez la plus haute intelligence du monde biologique - les êtres humains, c'est-à-dire les amis lecteurs, la décrire, vous le ferez le plus diront probablement :
 Photos
Photos
Alors voyons ce que la plus haute intelligence du monde des machines - c'est-à-dire GPT-4V - décrira en ce qui concerne cette mini série de bandes dessinées ?
 Photos
Photos
GPT - 4V, en tant qu'intelligence artificielle reconnue comme se situant au sommet de la chaîne du mépris, a en fait menti de manière flagrante.
Ce qui est encore plus scandaleux, c'est que même si GPT-4V reçoit des extraits d'images réelles, il reconnaîtra également de manière absurde le comportement d'une personne parlant à une autre personne en montant les escaliers alors que deux personnes tenant des « armes » se battent. Ludique (photo ci-dessous).
 Photos
Photos
Les Gémeaux ne sont pas loin derrière. Le même clip d'image montre le processus d'un homme qui a du mal à monter à l'étage, se dispute avec sa femme et est enfermé dans la maison.
 Photos
Photos
Ces exemples proviennent des derniers résultats de l'équipe de recherche de l'Université du Maryland et de Caroline du Nord à Chapel Hill, qui a lancé Mementos, une référence d'inférence pour les séquences d'images conçues spécifiquement pour MLLM.
Tout comme Memento de Nolan a redéfini la narration, Mementos redéfinit les limites des tests d’intelligence artificielle.
En tant que nouveau test de référence, il remet en question la compréhension par l’intelligence artificielle des séquences d’images comme les fragments de mémoire.
 Photos
Photos
Lien papier : https://arxiv.org/abs/2401.10529
Page d'accueil du projet : https://mementos-bench.github.io
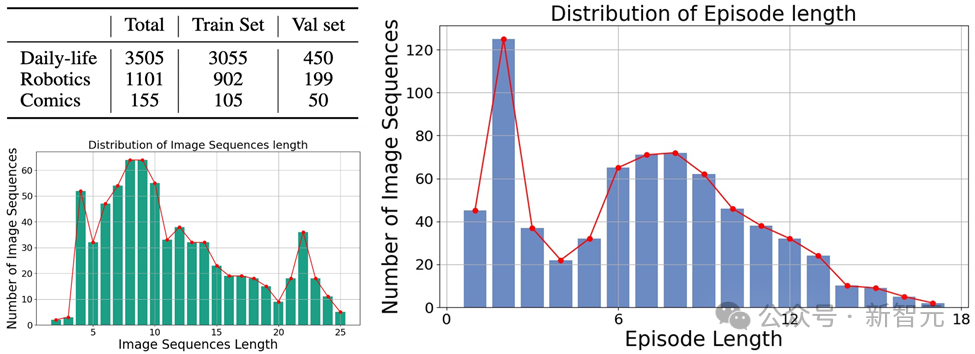
Mementos est le premier conçu spécifiquement pour MLLM Un benchmark pour le raisonnement de séquence d'images qui se concentre sur l'hallucination d'objets et l'hallucination comportementale de grands modèles sur des images consécutives.
Il s'agit de différents types d'images, couvrant trois grandes catégories : les images du monde réel, les images de robots et les images d'animation.
Et contient 4 761 séquences d'images diverses de différentes longueurs, chacune avec des annotations humaines décrivant les principaux objets et leur comportement dans la séquence.
 Photos
Photos
Les données sont actuellement open source et sont toujours en cours de mise à jour.
Types d'hallucinations
Dans l'article, l'auteur explique deux types d'hallucinations que MLLM produira dans Mementos : l'hallucination d'objet et l'hallucination comportementale.
Comme son nom l'indique, l'hallucination d'objet consiste à imaginer un objet (objet) inexistant, tandis que l'hallucination comportementale consiste à imaginer des actions et des comportements que l'objet n'a pas exécutés.
Méthode d'évaluation
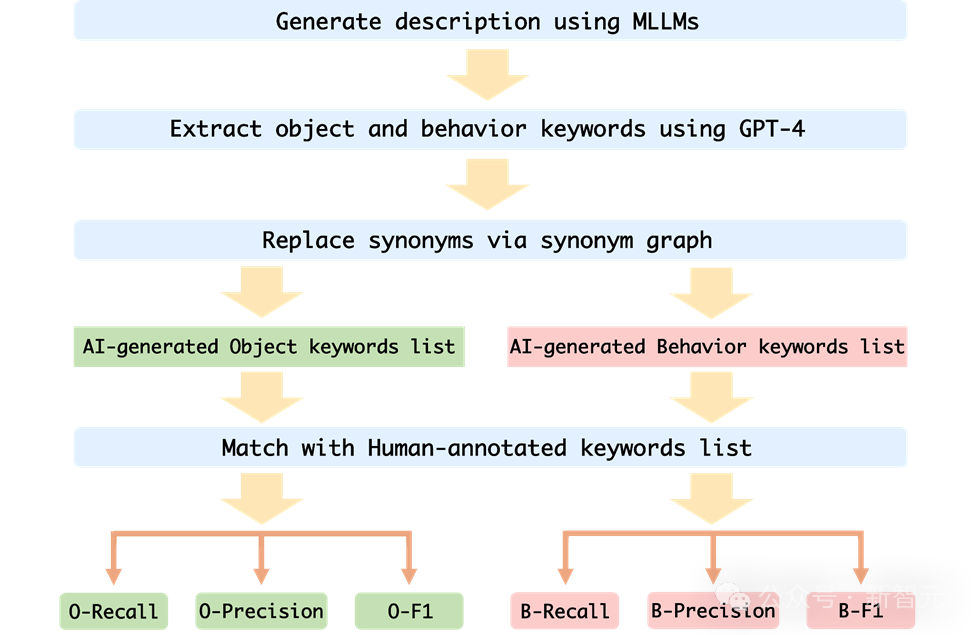
Afin d'évaluer avec précision l'hallucination comportementale et l'hallucination d'objet de MLLM sur Mementos, l'équipe de recherche a choisi de faire correspondre le mot-clé à la description de l'image générée par MLLM et à la description de l'annotation humaine.
Afin d'évaluer automatiquement les performances de chaque MLLM, l'auteur utilise la méthode de test auxiliaire GPT-4 pour évaluer :
 Images
Images
1 L'auteur prend la séquence d'images et les mots d'invite comme entrée dans MLLM, et génère la description correspondante correspondant à la séquence d'images ;
2. Demander à GPT-4 d'extraire les mots-clés d'objet et de comportement dans la description générée par l'IA
3 Obtenir deux listes de mots-clés d'objet générées par l'IA et la liste de mots-clés d'objet générée par l'IA. Liste de mots clés de comportement générée par l'IA ;
4. Calculez le taux de rappel, le taux de précision et l'indice F1 de la liste de mots-clés d'objet et de la liste de mots-clés de comportement générée par l'IA et la liste de mots-clés annotée humaine.
Résultats de l'évaluation
L'auteur a évalué les performances des MLLM dans le raisonnement d'images séquentielles sur Mementos et a mené une évaluation détaillée de neuf derniers MLLM, dont GPT4V et Gemini.
MLLM est invité à décrire les événements se produisant dans la séquence d'images afin d'évaluer la capacité de raisonnement de MLLM pour des images continues.
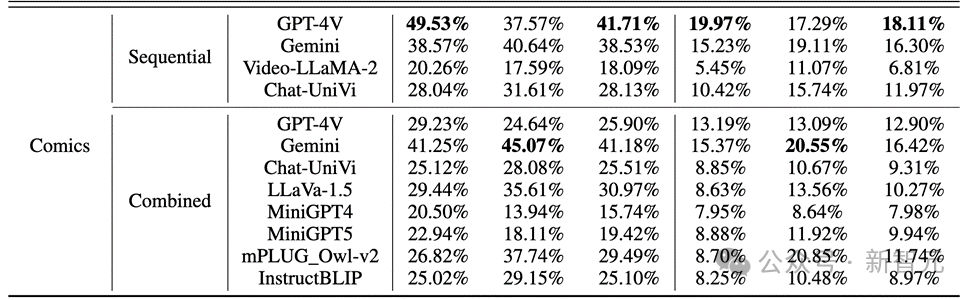
Les résultats ont révélé que, comme le montre la figure ci-dessous, la précision de GPT-4V et Gemini pour le comportement des personnages dans l'ensemble de données de bandes dessinées était inférieure à 20 %.
 Photos
Photos
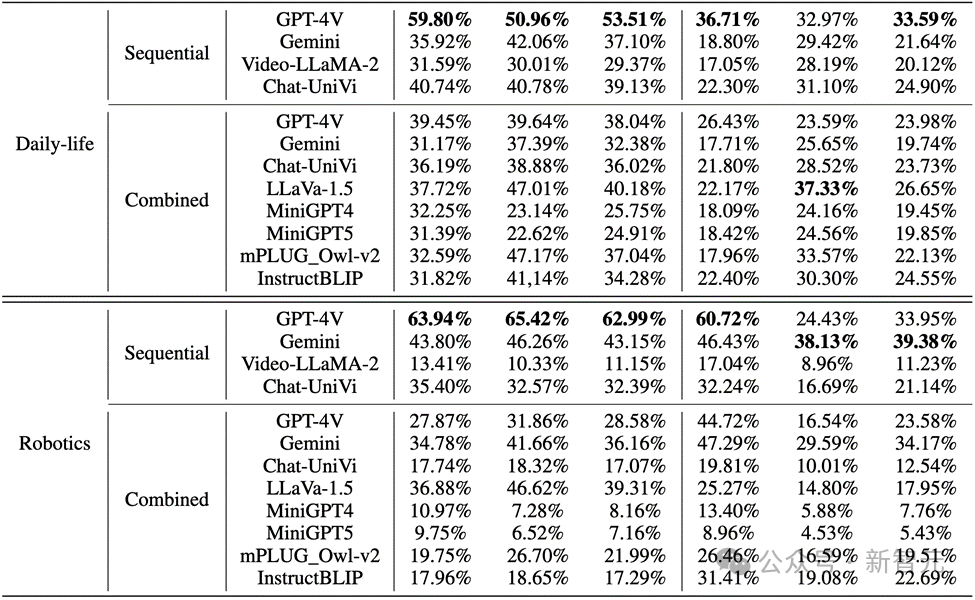
Dans les images du monde réel et les images de robots, les performances de GPT-4V et Gemini ne sont pas satisfaisantes :
 Photos
Photos
Points clés
1 Lors de l'évaluation de plusieurs Quand il. En ce qui concerne les modèles de langage modaux à grande échelle, GPT-4V et LLaVA-1.5 sont respectivement les modèles les plus performants dans les MLLM boîte noire et open source. GPT-4V surpasse tous les autres MLLM en termes de capacité de raisonnement pour comprendre les séquences d'images, tandis que LLaVA-1.5 est presque à égalité, voire dépasse, le modèle de boîte noire Gemini pour la compréhension des objets.
2. Bien que Video-LLaMA-2 et Chat-UniVi soient conçus pour la compréhension vidéo, ils ne présentent pas de meilleurs avantages que LLaVA-1.5.
3. Tous les MLLM fonctionnent nettement mieux que le raisonnement comportemental sur les trois indicateurs du raisonnement objet dans les séquences d'images, ce qui indique que les MLLM actuels ne sont pas forts dans la capacité à déduire de manière autonome des comportements à partir d'images consécutives.
4. Le modèle boîte noire est plus performant dans le domaine de la robotique, tandis que le modèle open source est relativement performant dans le domaine de la vie quotidienne. Cela peut être lié au changement de distribution des données d'entraînement.
5. Les limites des données de formation conduisent à de faibles capacités d'inférence des MLLM open source. Cela démontre l'importance des données de formation et leur impact direct sur les performances du modèle.
Raisons d'erreur
L'analyse de l'auteur des raisons pour lesquelles les modèles de langage multimodaux actuels à grande échelle échouent lors du traitement du raisonnement de séquence d'images identifie principalement trois raisons d'erreur :
1 La relation entre les objets et les illusions comportementales Interaction.
L'étude émet l'hypothèse qu'une reconnaissance incorrecte des objets entraînera une reconnaissance inexacte des actions ultérieures. L'analyse quantitative et les études de cas montrent que les hallucinations d'objets peuvent conduire dans une certaine mesure à des hallucinations comportementales. Par exemple, lorsque MLLM identifie par erreur une scène comme étant un court de tennis, il peut décrire un personnage jouant au tennis, même si ce comportement n'existe pas dans la séquence d'images.
2. L'impact de la cooccurrence sur les hallucinations comportementales
MLLM a tendance à générer des combinaisons comportementales courantes dans le raisonnement par séquence d'images, ce qui exacerbe le problème des hallucinations comportementales. Par exemple, lors du traitement d'images provenant du domaine robotique, MLLM peut décrire de manière incorrecte un bras de robot ouvrant un tiroir après avoir « saisi la poignée », même si l'action réelle consistait à « saisir le côté du tiroir ».
3. Effet boule de neige de l'illusion comportementale
Au fur et à mesure que la séquence d'images avance, les erreurs peuvent progressivement s'accumuler ou s'intensifier, ce que l'on appelle l'effet boule de neige. Dans le raisonnement de séquence d'images, si des erreurs surviennent tôt, ces erreurs peuvent s'accumuler et s'amplifier dans la séquence, entraînant une précision réduite dans la reconnaissance des objets et des actions.
Par exemple
 Photo
Photo
Comme le montre la figure ci-dessus, les raisons de l'échec du MLLM incluent l'hallucination d'objet et la corrélation entre l'hallucination d'objet et l'hallucination comportementale, ainsi que comportements concomitants.
Par exemple, après avoir expérimenté l'hallucination d'objet de « court de tennis », MLLM a ensuite montré l'hallucination comportementale de « tenir une raquette de tennis » (corrélation entre l'hallucination d'objet et l'hallucination comportementale) et le comportement de cooccurrence de « avoir l'air de jouer au tennis ». " .
 Photos
Photos
En regardant l'échantillon dans l'image ci-dessus, vous pouvez voir que MLLM pense à tort que la chaise est plus inclinée vers l'arrière et pense que la chaise est cassée.
Ce phénomène révèle que MLLM peut également produire l'illusion qu'une action s'est produite sur l'objet pour les objets statiques dans la séquence d'images.
 Photos
Photos
Dans l'affichage de la séquence d'images ci-dessus du bras robotique, le bras robotique atteint à côté de la poignée, et MLLM croit à tort que le bras robotique a saisi la poignée, prouvant que MLLM générera l'image Combinaisons de comportements courants dans le raisonnement séquentiel, produisant ainsi des hallucinations.
 Photo
Photo
Dans le cas ci-dessus, le vieux maître ne conduisait pas le chien, MLLM croyait à tort que promener le chien nécessitait de conduire le chien, et le "saut à la perche pour chiens" était reconnu comme "La fontaine". a été créé."
Le grand nombre d'erreurs reflète la méconnaissance du MLLM avec le domaine de la bande dessinée. Dans le domaine de l'animation bidimensionnelle, le MLLM peut nécessiter une optimisation et une pré-formation substantielles.
En annexe, l'auteur présente chaque catégorie principale. en détail les cas de défaillance et mené une analyse approfondie.
Résumé
Ces dernières années, les modèles linguistiques multimodaux à grande échelle ont démontré d'excellentes capacités dans la gestion de diverses tâches visuo-linguistiques.
Ces modèles, tels que GPT-4V et Gemini, sont capables de comprendre et de générer du texte lié aux images, favorisant grandement le développement de la technologie de l'intelligence artificielle.
Cependant, les benchmarks MLLM existants se concentrent principalement sur l'inférence basée sur une seule image statique, tandis que la capacité de déduire à partir de séquences d'images, cruciale pour comprendre notre monde en évolution, a été relativement peu étudiée.
Pour relever ce défi, les chercheurs proposent un nouveau benchmark "Mementos", qui vise à évaluer les capacités des MLLM en raisonnement d'images séquences.
Mementos contient 4761 séquences d'images diverses de différentes longueurs. En outre, l’équipe de recherche a également adopté la méthode auxiliaire GPT-4 pour évaluer les performances d’inférence de MLLM.
Grâce à une évaluation minutieuse de neuf derniers MLLM (dont GPT-4V et Gemini) sur Mementos, l'étude a révélé que ces modèles ont du mal à décrire avec précision les informations dynamiques d'une séquence d'images donnée, ce qui entraîne souvent des hallucinations des objets et de leurs comportements. /mauvaise expression.
L'analyse quantitative et les études de cas identifient trois facteurs clés qui influencent le raisonnement par images de séquence dans les MLLM :
1 Corrélation entre les illusions d'objet et de comportement
2.
3. Effets cumulatifs des hallucinations comportementales. Cette découverte est d'une grande importance pour comprendre et améliorer la capacité des MLLM à traiter des informations visuelles dynamiques. Le benchmark Mementos révèle non seulement les limites des MLLM actuels, mais fournit également des orientations pour les recherches et améliorations futures. Avec le développement rapide de la technologie de l'intelligence artificielle, l'application des MLLM dans le domaine de la compréhension multimodale deviendra plus étendue et plus approfondie. L’introduction du benchmark Mementos favorise non seulement la recherche dans ce domaine, mais nous offre également de nouvelles perspectives pour comprendre et améliorer la façon dont ces systèmes d’IA avancés traitent et comprennent notre monde complexe et en constante évolution. Références : https://github.com/umd-huanglab/MementosCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Sujet spécial ChatGPT : Les capacités et l'avenir des grands modèles de langage
- La première entreprise nationale, 360 Intelligent Brain, a réussi l'évaluation fiable des fonctions du grand modèle de langage AIGC de l'Académie chinoise des technologies de l'information et des communications.
- Cet article vous amènera à comprendre le grand modèle de langage universel développé indépendamment par Tencent - le grand modèle Hunyuan.
- Créez rapidement une grande base de connaissances sur l'IA en matière de modèles de langage en seulement trois minutes
- Le premier magasin phare de services de Huawei dans le sud de la Chine dévoilé : des robots intelligents aident les ingénieurs à obtenir automatiquement des pièces