
Maison >Périphériques technologiques >IA >LLaVA-1.6, qui rattrape Gemini Pro et améliore les capacités de raisonnement et d'OCR, est trop puissant
LLaVA-1.6, qui rattrape Gemini Pro et améliore les capacités de raisonnement et d'OCR, est trop puissant

- PHPzavant
- 2024-02-01 16:51:29822parcourir
En avril de l'année dernière, des chercheurs de l'Université du Wisconsin-Madison, de Microsoft Research et de l'Université de Columbia ont publié conjointement LLaVA (Large Language and Vision Assistant). Bien que LLaVA ne soit entraîné qu'avec un petit ensemble de données d'instructions multimodales, il montre des résultats d'inférence très similaires à ceux de GPT-4 sur certains échantillons. Puis, en octobre, ils ont lancé LLaVA-1.5, qui a actualisé le SOTA en 11 tests avec de simples modifications par rapport au LLaVA original. Les résultats de cette mise à niveau sont très intéressants, apportant de nouvelles avancées dans le domaine des assistants IA multimodaux.
L'équipe de recherche a annoncé le lancement de la version LLaVA-1.6, qui a apporté des améliorations majeures en termes de performances en matière de raisonnement, d'OCR et de connaissance du monde. Cette version de LLaVA-1.6 surpasse même le Gemini Pro dans plusieurs benchmarks.
- Adresse de démonstration : https://llava.hliu.cc/
- Adresse du projet : https://github.com/haotian-liu/LLaVA
Par rapport à LLaVA-1.5, LLaVA-1.6 présente les améliorations suivantes :
- Augmente la résolution de l'image d'entrée de 4 fois, prend en charge trois formats d'image, jusqu'à une résolution de 672x672, 336x1344, 1344x336. Cela permet à LLaVA-1.6 de capturer plus de détails visuels.
- LLaVA-1.6 bénéficie de meilleures capacités de raisonnement visuel et d'OCR grâce à des instructions visuelles améliorées pour ajuster le mélange des données.
- Meilleur dialogue visuel, plus de scènes, couvrant différentes applications. LLaVA-1.6 maîtrise davantage les connaissances du monde et possède une meilleure capacité de raisonnement logique.
- Utilisez SGLang pour un déploiement et une inférence efficaces.

Source de l'image : https://twitter.com/imhaotian/status/1752621754273472927
LLaVA-1.6 est affiné et optimisé sur la base de LLaVA-1.5. Il conserve la conception simple et les capacités efficaces de traitement des données de LLaVA-1.5, et continue d'utiliser moins d'un million d'échantillons de réglage d'instructions visuelles. En utilisant 32 cartes graphiques A100, le plus grand modèle 34B a été formé en 1 jour environ. De plus, LLaVA-1.6 utilise 1,3 million d'échantillons de données, et son coût de calcul/données de formation n'est que 100 à 1 000 fois supérieur à celui des autres méthodes. Ces améliorations font de LLaVA-1.6 une version plus efficace et plus rentable.
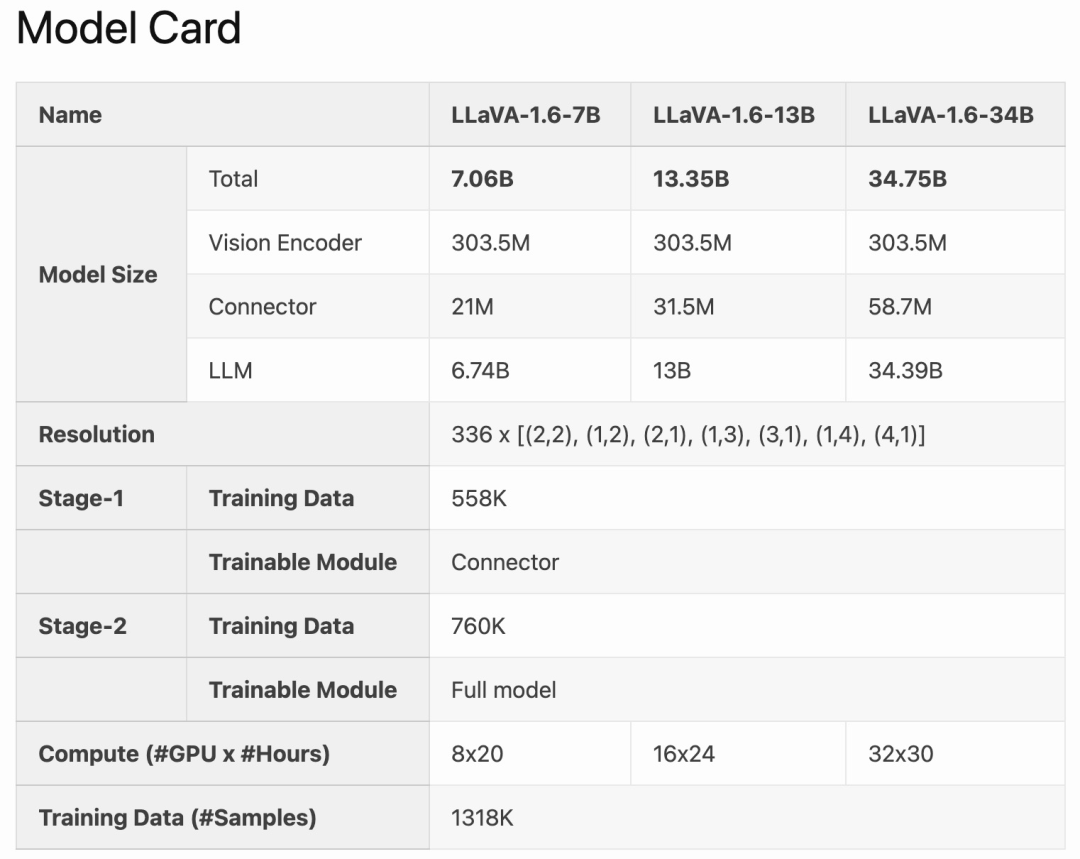
Comparé aux LMM open source comme CogVLM ou Yi-VL, LLaVA-1.6 atteint les performances SOTA. Comparé aux produits commerciaux, LLaVA-1.6 est comparable à Gemini Pro et meilleur que Qwen-VL-Plus dans les tests de référence sélectionnés.
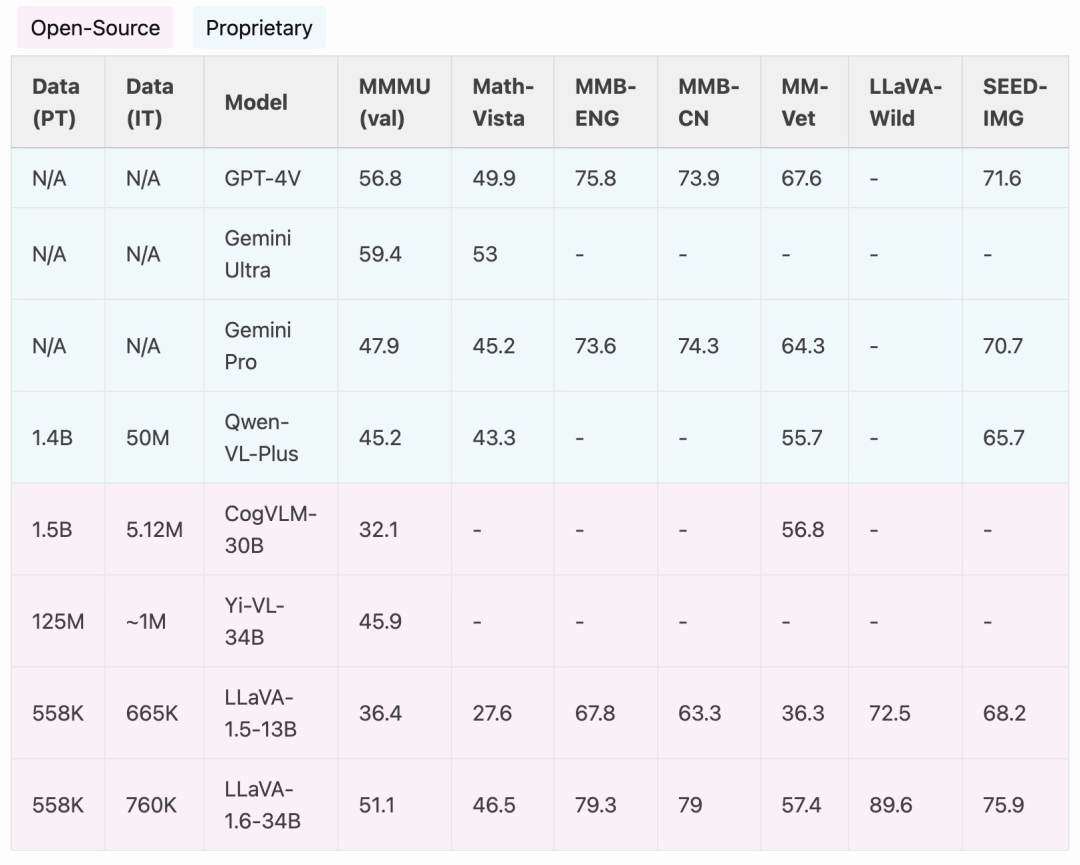
Il convient de mentionner que LLaVA-1.6 démontre de fortes capacités chinoises de tir zéro et atteint les performances SOTA sur la référence multimodale MMBench-CN.
Améliorations de la méthode
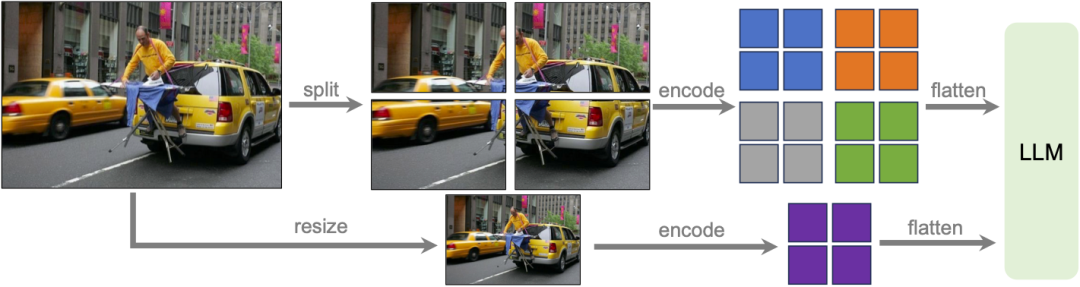
Haute résolution dynamique
L'équipe de recherche a conçu le modèle LLaVA-1.6 à haute résolution, dans le but de maintenir l'efficacité de ses données. Lorsqu'il est fourni avec des images haute résolution et des représentations préservant les détails, la capacité du modèle à percevoir les détails complexes des images s'améliore considérablement. Cela réduit les hallucinations du modèle lorsqu'il est confronté à des images à basse résolution, c'est-à-dire deviner le contenu visuel imaginé.
Mélange de données
Données d'instructions utilisateur de haute qualité. La définition de l'étude d'une instruction visuelle de haute qualité suivant les données dépend de deux critères principaux : premièrement, la diversité des instructions de tâche, garantissant une représentation adéquate du large éventail d'intentions des utilisateurs qui peuvent être rencontrées dans des scénarios réels, en particulier lors de la phase de déploiement du modèle. Deuxièmement, la priorisation des réponses est essentielle, dans le but de solliciter des commentaires favorables des utilisateurs.
Par conséquent, l'étude a considéré deux sources de données :
Données GPT-V existantes (LAION-GPT-V et ShareGPT-4V) ; Pour promouvoir davantage un meilleur dialogue visuel dans davantage de scénarios, l'équipe de recherche a collecté un petit ensemble de données de réglage d'instructions visuelles de 15 000 couvrant différentes applications, soigneusement filtré des échantillons pouvant présenter des problèmes de confidentialité ou être dangereux, et utilisé GPT-4V pour générer une réponse. Données multimodales de documents/graphiques. (1) Supprimez TextCap des données de formation car l'équipe de recherche a réalisé que TextCap utilise le même ensemble d'images de formation que TextVQA. Cela a permis à l'équipe de recherche de mieux comprendre les capacités OCR zéro tir du modèle lors de l'évaluation de TextVQA. Afin de maintenir et d'améliorer encore les capacités OCR du modèle, cette étude a remplacé TextCap par DocVQA et SynDog-EN. (2) Avec Qwen-VL-7B-Chat, cette étude ajoute en outre ChartQA, DVQA et AI2D pour une meilleure compréhension des tracés et des graphiques. L'équipe de recherche a également déclaré qu'en plus de Vicuna-1.5 (7B et 13B), elle envisage également d'adopter davantage de solutions LLM, notamment Mistral-7B et Nous-Hermes-2-Yi-34B, pour permettre à LLaVA de prend en charge un plus large éventail d'utilisateurs et plus de scènes. 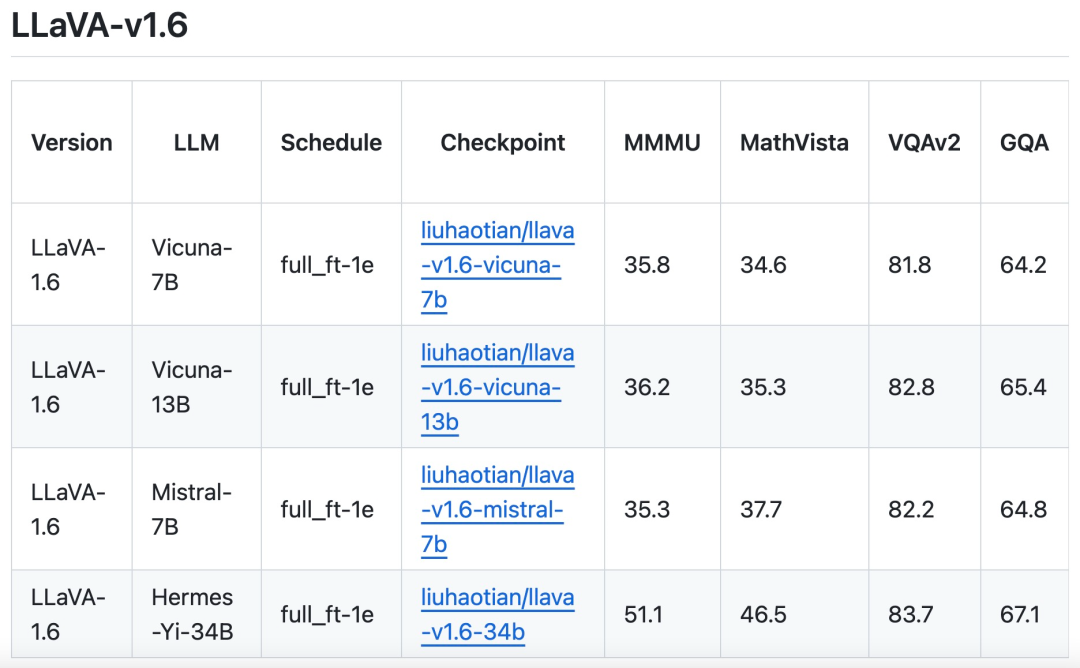
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?
- Application et recherche de recherche d'industrie basée sur un modèle de langage pré-entraîné
- Intégrez efficacement les modèles de langage, les réseaux de neurones graphiques et le cadre de formation de graphes de texte GLEM pour obtenir un nouveau SOTA.
- Les tests internes de Kimi Chat démarrent, Volcano Engine fournit des solutions d'accélération, prend en charge la formation et l'inférence du service de grands modèles Moonshot AI