
Maison >Périphériques technologiques >IA >En découvrant la baguette magique de l'assistant LLM, l'équipe chinoise de l'UIUC révèle les trois avantages majeurs des données de code
En découvrant la baguette magique de l'assistant LLM, l'équipe chinoise de l'UIUC révèle les trois avantages majeurs des données de code

- 王林avant
- 2024-01-29 09:24:16786parcourir
La taille du modèle de langage (LLM) et les données de formation à l'ère des grands modèles ont augmenté, y compris le langage naturel et le code.
Le code est l'intermédiaire entre les humains et les ordinateurs, convertissant les objectifs de haut niveau en étapes intermédiaires exécutables. Il présente les caractéristiques de norme grammaticale, de cohérence logique, d’abstraction et de modularité.
Une équipe de recherche de l'Université de l'Illinois à Urbana-Champaign a récemment publié un rapport de synthèse résumant les multiples avantages de l'incorporation de code dans les données de formation LLM.

Lien papier : https://arxiv.org/abs/2401.00812v1
Plus précisément, en plus d'améliorer la capacité du LLM en génération de code, les avantages incluent également les trois points suivants :
1. Aide à débloquer les capacités de raisonnement du LLM, lui permettant d'être appliqué à une série de tâches en langage naturel plus complexes
2. Guide LLM pour générer des étapes intermédiaires structurées et précises, qui peuvent ensuite être appelées ; les fonctions permettent de se connecter aux extrémités d'exécution externes ;
3. L'environnement de compilation et d'exécution du code peut être utilisé pour fournir des signaux de rétroaction plus diversifiés pour une amélioration ultérieure du modèle.
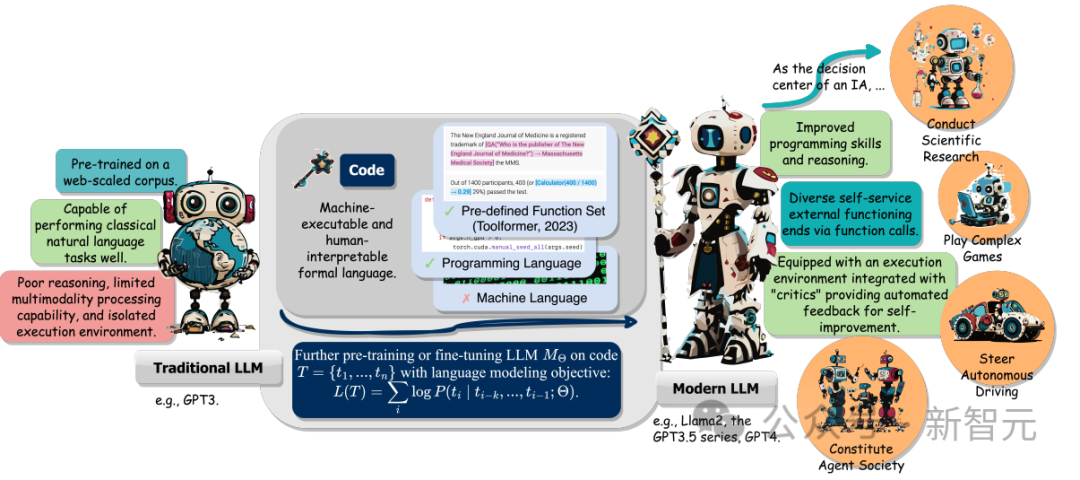
De plus, les chercheurs ont également suivi la capacité de LLM à comprendre les instructions, à décomposer les objectifs, à planifier et à exécuter des actions et à extraire des commentaires lorsqu'il agit en tant qu'agent intelligent (IA) pour jouer un rôle clé dans les tâches en aval.
Enfin, l'article propose également des défis clés et des orientations de recherche futures dans le domaine de "l'amélioration du LLM avec du code".
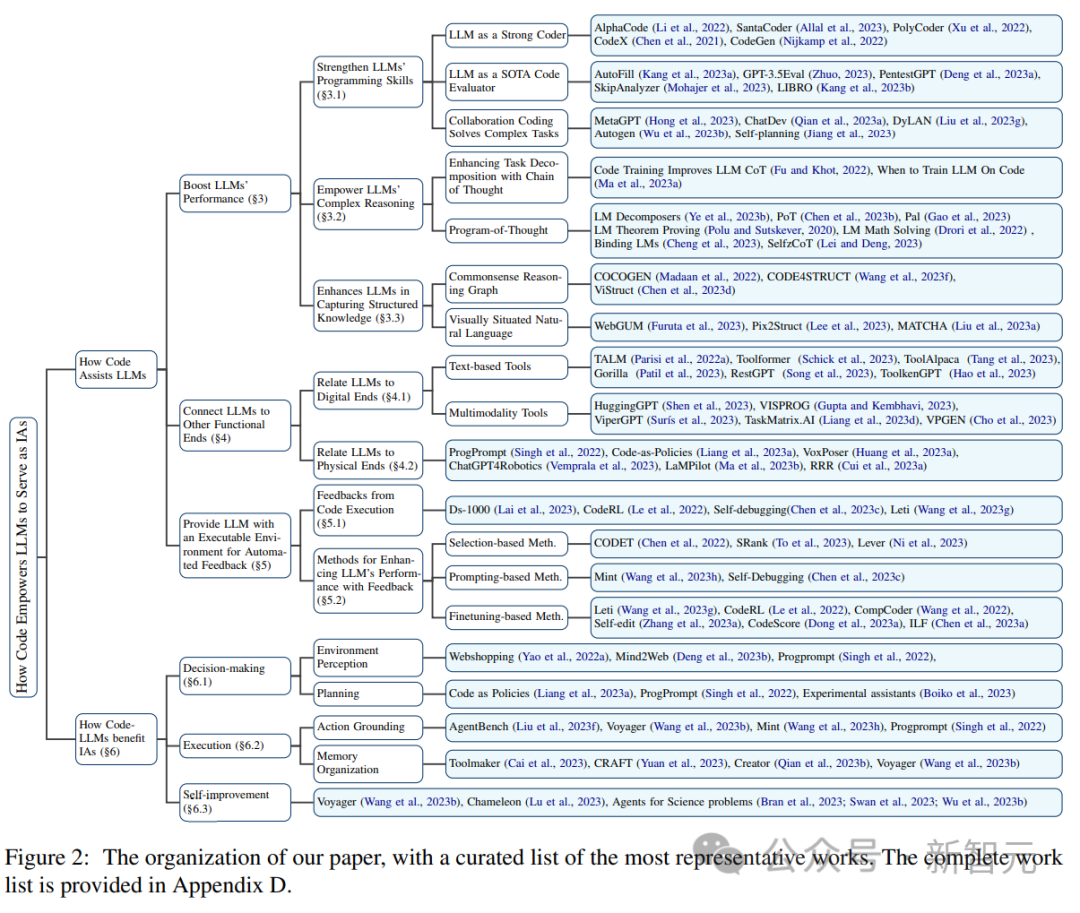
La pré-formation au code améliore les performances du LLM
En prenant le Codex GPT d'OpenAI comme exemple, après la pré-formation au code pour LLM, la portée des tâches LLM peut être élargie en plus du traitement du langage naturel, le modèle. peut également être utilisé pour la théorie mathématique, générer du code, effectuer des tâches de programmation courantes, récupérer des données, etc.
La tâche de génération de code a deux caractéristiques : 1) la séquence de code doit être exécutée efficacement, elle doit donc avoir une logique cohérente, 2) chaque étape intermédiaire peut être soumise à une vérification logique étape par étape.
L'utilisation et l'intégration de code dans la pré-formation peuvent améliorer les performances de la technologie LLM Chain of Thought (CoT) dans les tâches traditionnelles en aval du langage naturel, indiquant que la formation au code peut améliorer la capacité de LLM à effectuer un raisonnement complexe.
En apprenant implicitement de la forme structurée du code, Code LLM montre également de meilleures performances dans les tâches de raisonnement structurel de bon sens, telles que celles liées au balisage, au HTML et à la compréhension des diagrammes.
Prise en charge des fonctions/extrémités de fonction
Des résultats de recherche récents montrent que la connexion des LLM à d'autres extrémités de fonction (c'est-à-dire l'amélioration des LLM avec des outils externes et des modules d'exécution) aide les LLM à effectuer des tâches de manière plus précise et plus fiable.
Ces objectifs fonctionnels permettent aux LLM d'acquérir des connaissances externes, de participer à plusieurs données modales et d'interagir efficacement avec l'environnement.

À partir de travaux connexes, les chercheurs ont observé une tendance commune, à savoir que les LLM génèrent des langages de programmation ou utilisent des fonctions prédéfinies pour établir des connexions avec d'autres terminaux fonctionnels, c'est-à-dire le paradigme « centré sur le code ».
Contrairement au processus pratique fixe d'appels d'outils strictement codés en dur dans le mécanisme d'inférence LLM, le paradigme centré sur le code permet à LLM de générer dynamiquement des jetons et des modules d'exécution d'appels avec des paramètres adaptables, fournissant à LLM d'autres interactions de terminal fonctionnel. une méthode simple et claire qui améliore la flexibilité et l'évolutivité de ses applications.
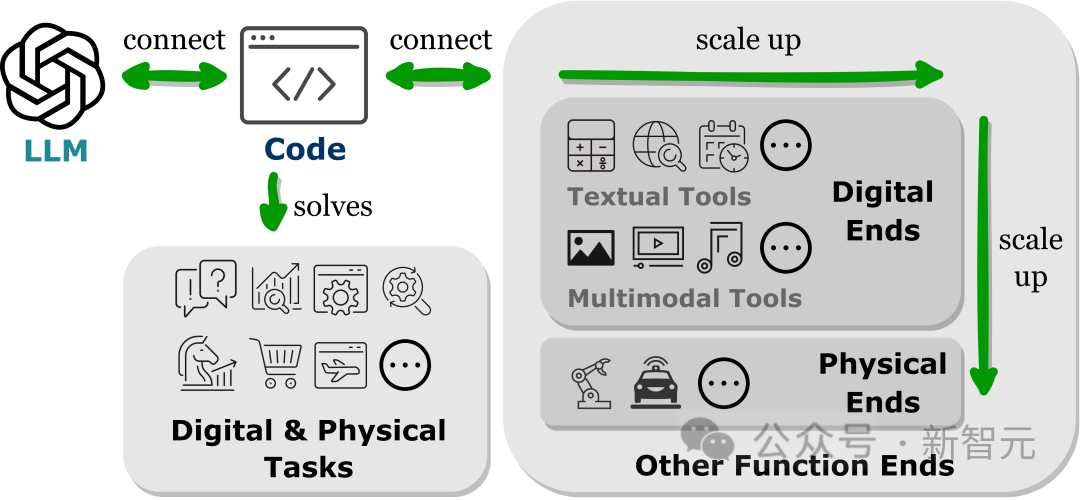
Il est important de noter que ce paradigme permet à LLM d'interagir avec de nombreux terminaux fonctionnels selon différentes modalités et domaines ; en augmentant le nombre et la variété de terminaux fonctionnels accessibles, LLM peut gérer des tâches plus complexes.
Cet article étudie principalement les outils textuels et multimodaux connectés au LLM, ainsi que la fin fonctionnelle du monde physique, y compris la robotique et la conduite autonome, démontrant la polyvalence du LLM dans la résolution de problèmes dans divers modes et domaines.
Environnement exécutable qui fournit un retour automatique
Les LLM présentent des performances au-delà de leurs paramètres d'entraînement, en partie grâce à la capacité du modèle à absorber les signaux de retour, en particulier dans les applications non statiques du monde réel.
Cependant, le choix du signal de rétroaction doit être prudent, car les signaux bruyants peuvent gêner les performances du LLM sur les tâches en aval.
De plus, les coûts de main d'œuvre étant élevés, il est crucial de recueillir automatiquement les feedbacks tout en maintenant la fidélité.
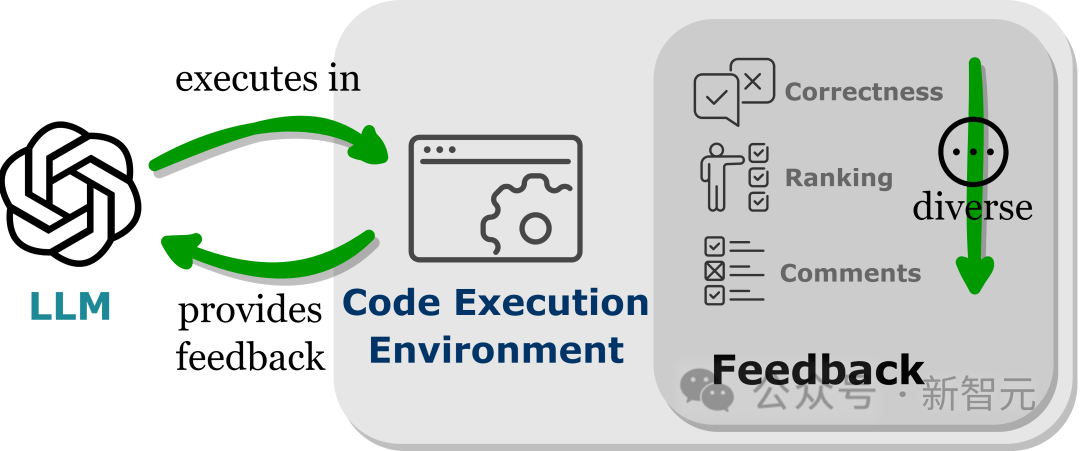
L'intégration de LLM dans l'environnement d'exécution de code peut obtenir un retour automatique des conditions ci-dessus.
Étant donné que l'exécution du code est en grande partie déterministe, les retours que les LLM obtiennent des résultats de l'exécution du code restent fidèles à la tâche cible ; l'interpréteur de code fournit également un chemin automatisé permettant aux LLM d'interroger les commentaires internes sans avoir besoin de travail manuel. Annotation peut être utilisé pour déboguer et optimiser le code d’erreur généré par les LLM.
De plus, l'environnement de code permet aux LLM d'intégrer une variété de formulaires de commentaires externes, y compris, mais sans s'y limiter, des commentaires sur l'exactitude binaire, des explications en langage naturel des résultats et un classement des valeurs de récompense, permettant ainsi une approche hautement personnalisable pour améliorer les performances.

Défis actuels
La relation causale entre la pré-formation au code et l'amélioration de l'inférence des LLM
Bien qu'il semble intuitif que certaines propriétés des données de code puissent contribuer aux capacités d'inférence des LLM, le l’étendue exacte de son impact sur l’amélioration des capacités de raisonnement reste incertaine.
Dans la prochaine étape des travaux de recherche, il sera important d'étudier si ces attributs de code peuvent réellement améliorer les capacités d'inférence des LLM formés dans les données de formation.
S'il est vrai qu'une pré-formation sur des propriétés spécifiques du code peut améliorer directement les capacités de raisonnement des LLM, alors comprendre ce phénomène sera la clé pour améliorer davantage les capacités de raisonnement complexes des modèles actuels.
Des capacités de raisonnement ne se limitent pas au code
Malgré l'amélioration des capacités de raisonnement obtenue grâce à la pré-formation au code, le modèle de base ne dispose toujours pas des capacités de raisonnement de type humain attendues d'une véritable intelligence artificielle générale.
En plus du code, un grand nombre d'autres sources de données textuelles ont le potentiel d'améliorer les capacités d'inférence LLM, où les caractéristiques inhérentes du code, telles que l'absence d'ambiguïté, l'exécutabilité et la structure séquentielle logique, fournissent des lignes directrices pour la collecte. ou créer ces ensembles de données.
Mais si nous continuons à nous en tenir au paradigme de la formation de modèles linguistiques sur de grands corpus avec des objectifs de modélisation linguistique, il sera difficile d'avoir un langage lisible séquentiellement qui soit plus abstrait qu'un langage formel : très structuré, étroitement lié à langages symboliques, et Existant en grand nombre dans l’environnement des réseaux numériques.
Les chercheurs estiment que l'exploration de modèles de données alternatifs, d'objectifs de formation diversifiés et de nouvelles architectures offrira davantage d'opportunités pour améliorer davantage les capacités d'inférence de modèles.
Défis liés à l'application du paradigme centré sur le code
Dans les LLM, le principal défi de l'utilisation du code pour se connecter à différents terminaux fonctionnels est d'apprendre les méthodes d'appel correctes de différentes fonctions, y compris la sélection de la bonne fonction (fonction) terminal et en passant les arguments corrects au moment approprié.
Par exemple, pour une tâche simple (navigation dans une page Web), étant donné un ensemble limité de primitives d'action, telles que le mouvement de la souris, le clic et le défilement de la page, puis donnez quelques exemples (quelques plans), une base solide LLM nécessite souvent que LLM maîtrise avec précision l’utilisation de ces primitives.
Pour les tâches plus complexes dans des domaines gourmands en données tels que la chimie, la biologie et l'astronomie, qui impliquent des appels à des bibliothèques Python spécifiques à un domaine contenant de nombreuses fonctions complexes avec différentes fonctions, améliorez l'apprentissage des LLM pour appeler correctement ces fonctions fonctionnelles. une orientation prospective qui permet aux LLM d’effectuer des tâches de niveau expert dans des domaines précis.
Apprenez de plusieurs séries d'interactions et de commentaires
Les LLM nécessitent souvent de multiples interactions avec les utilisateurs et l'environnement, se corrigeant constamment pour améliorer l'exécution de tâches complexes.
Bien que l'exécution de code fournisse des retours fiables et personnalisables, un moyen idéal pour exploiter pleinement ces retours n'a pas encore été établi.
Bien que la méthode actuelle basée sur la sélection soit utile, elle ne peut pas garantir des performances améliorées et est inefficace ; la méthode basée sur la récursivité s'appuie fortement sur la capacité d'apprentissage du contexte de LLM, ce qui peut limiter son applicabilité bien que la méthode de réglage fin ; a réalisé des progrès continus, mais la collecte et le réglage des données nécessitent beaucoup de ressources et sont difficiles à utiliser dans la pratique.
Les chercheurs pensent que l'apprentissage par renforcement peut être un moyen plus efficace d'utiliser les commentaires et de s'améliorer, en fournissant un moyen dynamique de s'adapter aux commentaires grâce à des fonctions de récompense soigneusement conçues, répondant potentiellement aux limites de la technologie actuelle.
Mais de nombreuses recherches sont encore nécessaires pour comprendre comment concevoir des fonctions de récompense et comment intégrer de manière optimale l'apprentissage par renforcement avec les LLM pour accomplir des tâches complexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- tutoriel de base du logiciel ai
- qu'est-ce que l'IA
- Intégrez efficacement les modèles de langage, les réseaux de neurones graphiques et le cadre de formation de graphes de texte GLEM pour obtenir un nouveau SOTA.
- Formation personnalisée de modèles d'apprentissage profond à l'aide de techniques d'apprentissage par transfert
- Premier article : Un nouveau paradigme pour la formation de modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D