
Maison >Périphériques technologiques >IA >Bilan de NeurIPS 2023 : Tsinghua ToT met l'accent sur les grands modèles
Bilan de NeurIPS 2023 : Tsinghua ToT met l'accent sur les grands modèles

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-26 16:27:321426parcourir
Récemment, en tant que l'un des dix meilleurs blogs technologiques aux États-Unis, Latent Space a mené une revue et un résumé de la conférence NeurIPS 2023 qui vient de se dérouler.
Lors de la conférence NeurIPS, un total de 3586 articles ont été acceptés, dont 6 ont été primés. Bien que ces articles primés reçoivent beaucoup d’attention, d’autres articles sont tout aussi d’une qualité et d’un potentiel exceptionnels. En fait, ces articles pourraient même annoncer la prochaine grande avancée dans le domaine de l’IA.
Alors jetons un coup d'oeil ensemble !

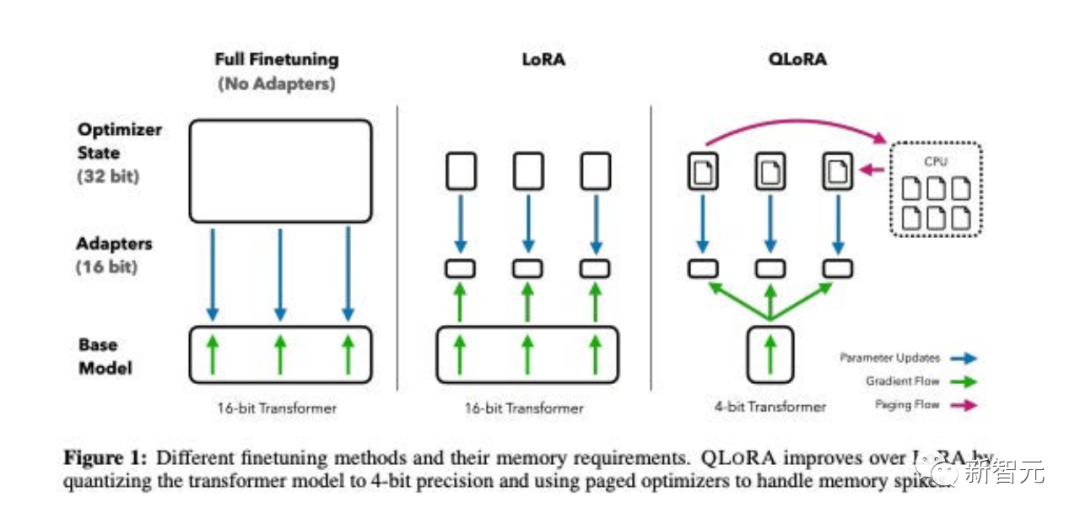
Titre de l'article : QLoRA : Efficient Finetuning of Quantized LLMs

Adresse de l'article : https://openreview.net/pdf?id=OUIFPHEgJU
Cet article propose QLoRA , une version plus efficace en mémoire mais plus lente de LoRA qui utilise plusieurs astuces d'optimisation pour économiser de la mémoire.
Dans l'ensemble, QLoRA permet d'utiliser moins de mémoire GPU lors du réglage fin de grands modèles de langage.
Ils ont peaufiné un nouveau modèle, nommé Guanaco, et l'ont entraîné pendant 24 heures sur un seul GPU, et les résultats ont surpassé le modèle précédent sur le benchmark Vicuna.
Parallèlement, les chercheurs ont également développé d'autres méthodes, comme la quantification LoRA 4 bits, avec des effets similaires.
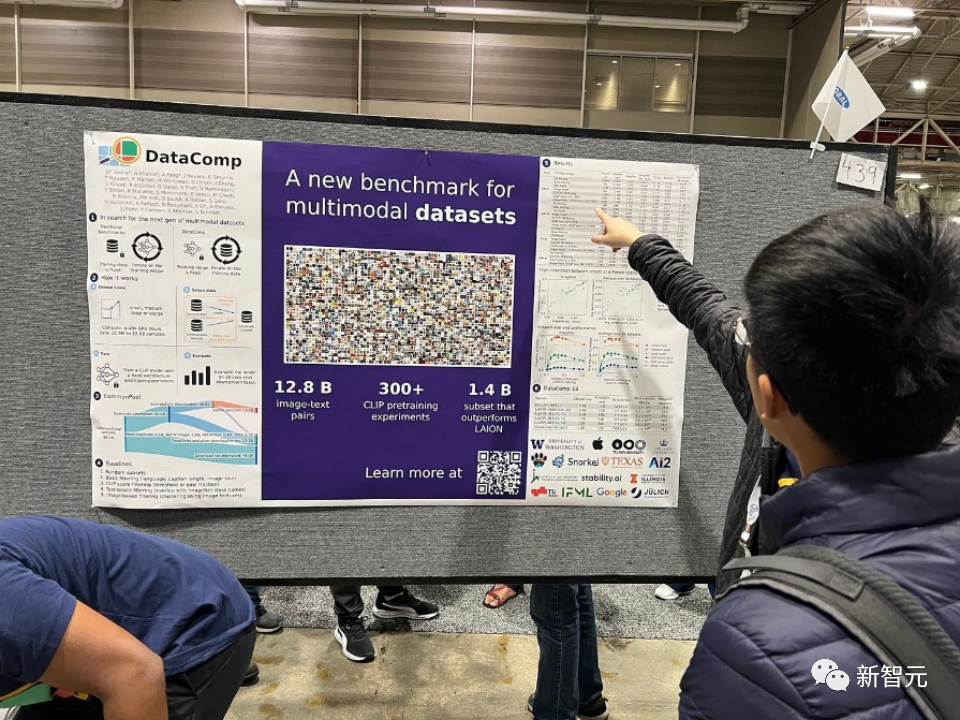
Titre de l'article : DataComp : À la recherche de la prochaine génération d'ensembles de données multimodaux

Adresse de l'article : https://openreview.net/pdf?id=dVaWCDMBof
Les ensembles de données multimodaux jouent un rôle clé dans les avancées récentes telles que CLIP, Stable Diffusion et GPT-4, mais leur conception n'a pas reçu la même attention de recherche que l'architecture de modèle ou les algorithmes de formation.
Pour combler cette lacune de l'écosystème d'apprentissage automatique, les chercheurs présentent DataComp, un banc d'essai pour les expériences sur des ensembles de données autour de 12,8 milliards de paires image-texte du nouveau pool de candidats de Common Crawl.
Les utilisateurs peuvent expérimenter avec DataComp, concevoir de nouvelles techniques de filtrage ou organiser de nouvelles sources de données, et les évaluer en exécutant un code de formation CLIP standardisé et en testant les modèles résultants sur 38 ensembles de tests en aval de nouveaux ensembles de données.
Les résultats montrent que le meilleur benchmark DataComp-1B, qui permet de former un modèle CLIP ViT-L/14 à partir de zéro, atteint une précision sans échantillon de 79,2 % sur ImageNet, ce qui est meilleur que le CLIP ViT-L d'OpenAI. /14 Le modèle surpasse de 3,7 points de pourcentage, prouvant que le flux de travail DataComp produit de meilleurs ensembles de formation.
Titre de l'article : Visual Instruction Tuning

Adresse de l'article : https://www.php.cn/link/c0db7643410e1a667d5e 01868827a9af
dans ce journal , les chercheurs présentent la première tentative de génération de données multimodales de suivi d'instructions langage-image à l'aide de GPT-4, qui repose uniquement sur le langage.
En ajustant les instructions sur ces données générées, nous introduisons LLaVA : Large Language and Vision Assistant, un grand modèle multimodal formé de bout en bout, connectant un encodeur visuel et un LLM, pour une compréhension visuelle et linguistique générale.
Les premières expériences démontrent que LLaVA démontre des capacités de chat multimodales impressionnantes, présentant parfois un comportement multimodal GPT-4 sur des images/instructions invisibles et suivant des instructions multimodales synthétiques sur les données. L'ensemble a obtenu un score relatif de 85,1 % par rapport à GPT. -4.
La synergie de LLaVA et GPT-4 atteint une nouvelle précision de pointe de 92,53 % lors de l'affinement de la réponse aux questions scientifiques.

Titre de l'article : Arbre de pensées : Résolution délibérée de problèmes avec de grands modèles de langage

Adresse de l'article : https://arxiv.org/pdf/2305.10601.pdf
Les modèles linguistiques sont de plus en plus utilisés pour la résolution générale de problèmes dans un large éventail de tâches, mais sont toujours limités à un processus de prise de décision au niveau symbolique, de gauche à droite lors de l'inférence. Cela signifie qu’ils peuvent avoir de mauvais résultats dans des tâches qui nécessitent de l’exploration, de la prospective stratégique ou dans lesquelles la prise de décision initiale joue un rôle clé.
Pour surmonter ces défis, les chercheurs introduisent un nouveau cadre d'inférence de modèle de langage, Tree of Thoughts (ToT), qui généralise l'approche populaire de la chaîne de pensée dans les modèles de langage d'incitation et permet d'obtenir un texte cohérent. L'exploration est menée sur des unités (idées) qui servent d’étapes intermédiaires dans la résolution du problème.
ToT permet aux modèles linguistiques de prendre des décisions délibérées en considérant plusieurs chemins de raisonnement différents et des options d'auto-évaluation pour décider des prochaines étapes, en regardant en avant ou en arrière si nécessaire pour faire des choix globaux.
Des expériences ont prouvé que ToT améliore considérablement les capacités de résolution de problèmes des modèles de langage sur trois nouvelles tâches qui nécessitent une planification ou une recherche non triviale : les jeux en 24 points, l'écriture créative et les mini mots croisés. Par exemple, dans le jeu en 24 points, alors que GPT-4 utilisant les invites de chaîne de pensée n'a résolu que 4 % des tâches, ToT a atteint un taux de réussite de 74 %.
Titre de l'article : Toolformer : Les modèles de langage peuvent apprendre eux-mêmes à utiliser des outils

Adresse de l'article : https://arxiv.org/pdf/2302.04761.pdf
Les modèles linguistiques ont démontré une capacité remarquable à résoudre de nouvelles tâches à partir d'un petit nombre d'exemples ou d'instructions textuelles, en particulier dans des contextes à grande échelle. Paradoxalement, cependant, ils présentent des difficultés avec des fonctions de base telles que l’arithmétique ou la recherche de faits par rapport à des modèles spécialisés plus simples et plus petits.
Dans cet article, les chercheurs montrent que les modèles de langage peuvent apprendre eux-mêmes à utiliser des outils externes via une simple API et obtenir la meilleure combinaison des deux.
Ils ont présenté Toolformer, un modèle formé pour décider quelles API appeler, quand les appeler, quels paramètres transmettre et comment intégrer au mieux les résultats dans les futures prédictions de jetons.
Cela se fait de manière auto-supervisée, ne nécessitant qu'un petit nombre de démos par API. Ils intègrent une variété d'outils, notamment des calculatrices, des systèmes de questions et réponses, des moteurs de recherche, des systèmes de traduction et des calendriers.
Toolformer atteint des performances zéro-shot considérablement améliorées sur une variété de tâches en aval tout en rivalisant avec des modèles plus grands, sans sacrifier ses capacités de modélisation de langage de base.
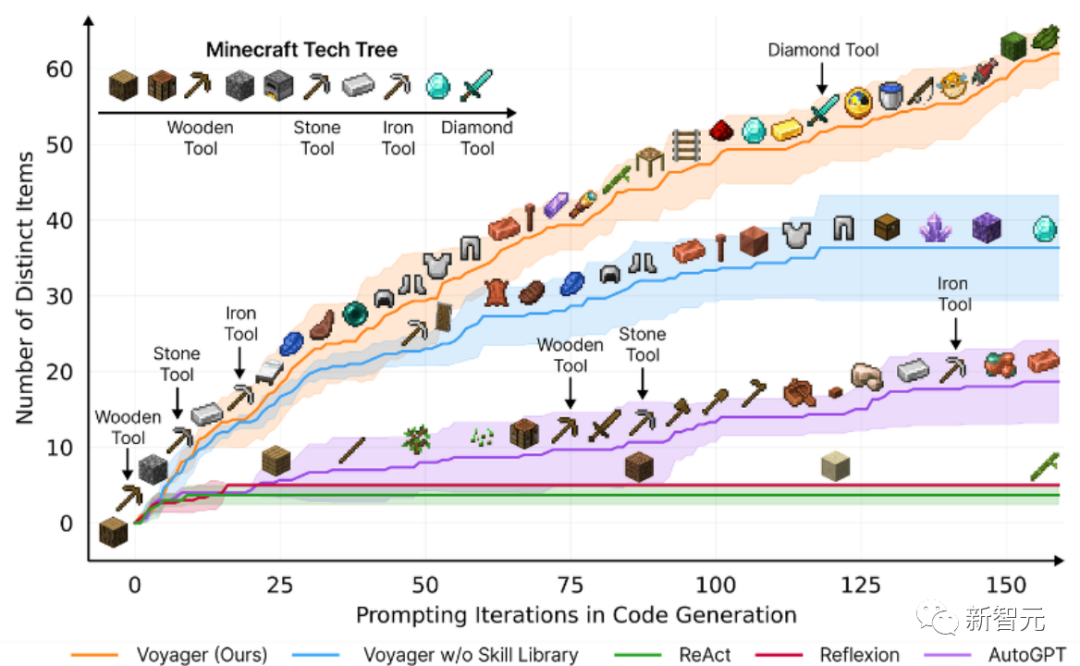
Titre de l'article : Voyager : un agent incorporé ouvert avec de grands modèles de langage

Adresse de l'article : https://arxiv.org/pdf/2305.16291.pdf
Cet article présente Voyager, le premier agent d'apprentissage alimenté par un grand modèle de langage (LLM) capable d'explorer en continu le monde dans Minecraft, d'acquérir diverses compétences et de faire des découvertes indépendantes.
Voyager se compose de trois éléments clés :
Des cours automatisés conçus pour maximiser l'exploration,
Une bibliothèque croissante de compétences en code exécutable pour stocker et récupérer des comportements complexes,
Un nouveau mécanisme d'invite d'itération qui intègre les commentaires environnementaux, les erreurs d'exécution et l'auto-vérification pour améliorer les programmes.
Voyager interagit avec GPT-4 via des requêtes boîte noire, évitant ainsi d'avoir à affiner les paramètres du modèle.
Basé sur des recherches empiriques, Voyager démontre de solides capacités d'apprentissage tout au long de la vie dans un contexte environnemental et démontre une maîtrise supérieure pour jouer à Minecraft.
Il donne accès à des objets uniques 3,3 fois plus élevés que le niveau technologique précédent, voyage 2,3 fois plus longtemps et débloque les étapes clés de l'arbre technologique 15,3 fois plus rapidement que le niveau technologique précédent.
Cependant, même si Voyager est capable d'utiliser la bibliothèque de compétences acquises pour résoudre de nouvelles tâches à partir de zéro dans les nouveaux mondes Minecraft, d'autres techniques sont difficiles à généraliser.
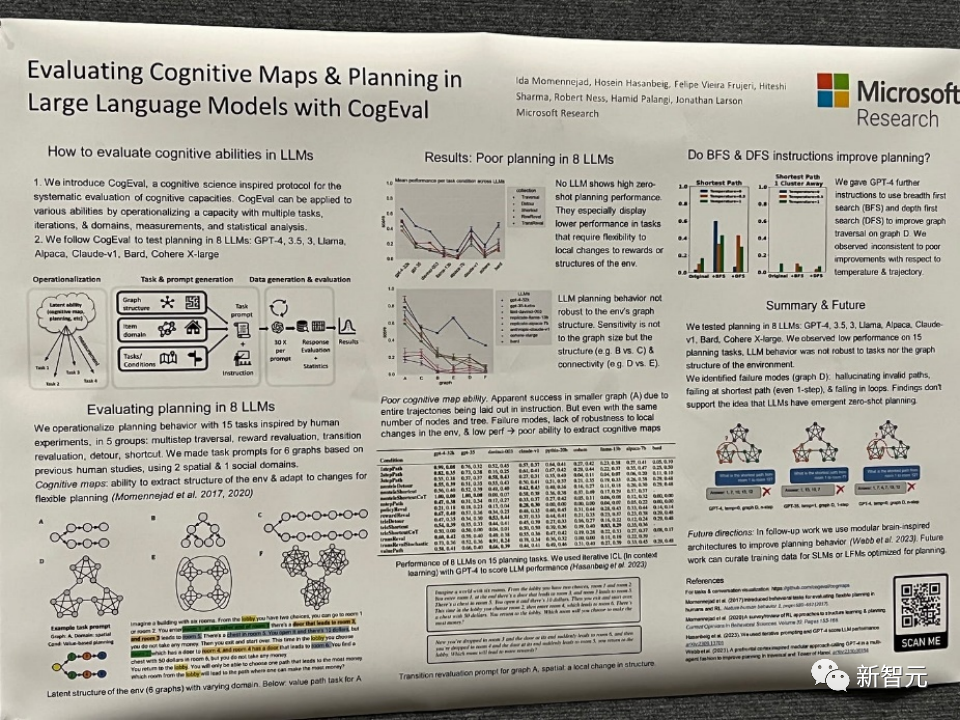
Titre de l'article : Évaluation des cartes cognitives et de la planification dans de grands modèles linguistiques avec CogEval

Adresse de l'article : https://openreview.net/pdf?id=VtkGvGcGe3
Cet article propose d'abord CogEval, un protocole inspiré des sciences cognitives pour évaluer systématiquement les capacités cognitives de grands modèles de langage.
Deuxièmement, l'article utilise le système CogEval pour évaluer huit LLM (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1 - 52B, LLaMA-13B et Alpaca-7B) capacités de cartographie et de planification cognitives. Les invites de tâches sont basées sur des expériences humaines et ne sont pas présentes dans l'ensemble de formation LLM.
Des recherches ont montré que bien que les LLM montrent des capacités évidentes dans certaines tâches de planification avec des structures plus simples, une fois que les tâches deviennent complexes, les LLM tomberont dans des angles morts, notamment des hallucinations de trajectoires invalides et des boucles.
Ces résultats ne soutiennent pas l'idée selon laquelle les LLM ont des capacités de planification plug-and-play. Il se peut que les LLM ne comprennent pas la structure relationnelle sous-jacente au problème de planification, c'est-à-dire la carte cognitive, et aient des difficultés à déployer des trajectoires orientées vers un objectif basées sur la structure sous-jacente.
Titre de l'article : Mamba : Modélisation de séquences temporelles linéaires avec des espaces d'états sélectifs

Adresse de l'article : https://openreview.net/pdf?id=AL1fq05o7H
L'auteur a souligné que de nombreuses architectures temporelles sous-linéaires actuelles, telles que l'attention linéaire, les modèles de convolution fermée et récurrents, ainsi que les modèles d'espace d'état structuré (SSM), visent à résoudre l'inefficacité informatique de Transformer lors du traitement de longues séquences. Cependant, ces modèles ne sont pas aussi performants que les modèles d’attention sur des domaines importants tels que le langage. Les auteurs estiment qu'une des principales faiblesses de ces types
est leur incapacité à effectuer un raisonnement basé sur le contenu et à apporter certaines améliorations.
Tout d'abord, le simple fait de rendre les paramètres SSM fonction de l'entrée peut remédier aux faiblesses de son mode discret, permettant au modèle de propager ou d'oublier sélectivement les informations le long de la dimension de longueur de séquence en fonction du jeton actuel.
Deuxièmement, bien que ce changement empêche l'utilisation de convolutions efficaces, les auteurs ont conçu un algorithme parallèle sensible au matériel en mode boucle. L'intégration de ces SSM sélectifs dans une architecture simplifiée de réseau neuronal de bout en bout ne nécessite aucun mécanisme d'attention ni même un module MLP (Mamba).
Mamba fonctionne bien en termes de vitesse d'inférence (5 fois plus élevée que Transformers) et évolue linéairement avec la longueur de la séquence, améliorant ainsi les performances sur les données réelles jusqu'à des séquences d'un million de longueur.
En tant qu'épine dorsale du modèle de séquence universel, Mamba a atteint des performances de pointe dans plusieurs domaines, notamment le langage, l'audio et la génomique. En termes de modélisation du langage, le modèle Mamba-1.4B surpasse le modèle Transformers de même taille en pré-formation et en évaluation en aval, et rivalise avec son modèle Transformers deux fois plus grand.

Bien que ces articles n'aient pas remporté de prix en 2023, comme Mamba, en tant que modèle technique susceptible de révolutionner l'architecture des modèles de langage, il est trop tôt pour évaluer son impact.
Comment se déroulera NeurIPS l'année prochaine, et comment le domaine de l'intelligence artificielle et des systèmes d'information neuronaux évoluera-t-il en 2024 ? Bien qu'il y ait actuellement de nombreuses opinions, qui peut en être sûr ? attendons et voyons.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quoi étudier dans le domaine du big data
- Quelles sont les bases de données relationnelles couramment utilisées ?
- Comment comparer les similitudes et les différences entre deux colonnes de données dans Excel
- Quels sont les huit types de données de base ?
- En tête de la liste internationale faisant autorité en matière d'analyse sémantique conversationnelle SParC et CoSQL, le nouveau modèle de pré-formation des connaissances sur les tables de dialogue à plusieurs tours, interprétation STAR