
Maison >Périphériques technologiques >IA >Le classement des coûts d'inférence à grande échelle mené par la haute efficacité de Jia Yangqing est publié
Le classement des coûts d'inférence à grande échelle mené par la haute efficacité de Jia Yangqing est publié

- 王林avant
- 2024-01-26 14:15:34703parcourir
"Les API de grands modèles sont-elles une affaire déficitaire ?"
Avec la mise en pratique de la technologie des grands modèles de langage, de nombreuses entreprises technologiques ont lancé des API de grands modèles que les développeurs peuvent utiliser. Cependant, on ne peut s'empêcher de commencer à se demander si une entreprise basée sur de grands modèles peut être pérenne, d'autant plus qu'OpenAI dépense 700 000 $ par jour.
Ce jeudi, la startup d'IA Martian l'a soigneusement calculé pour nous.
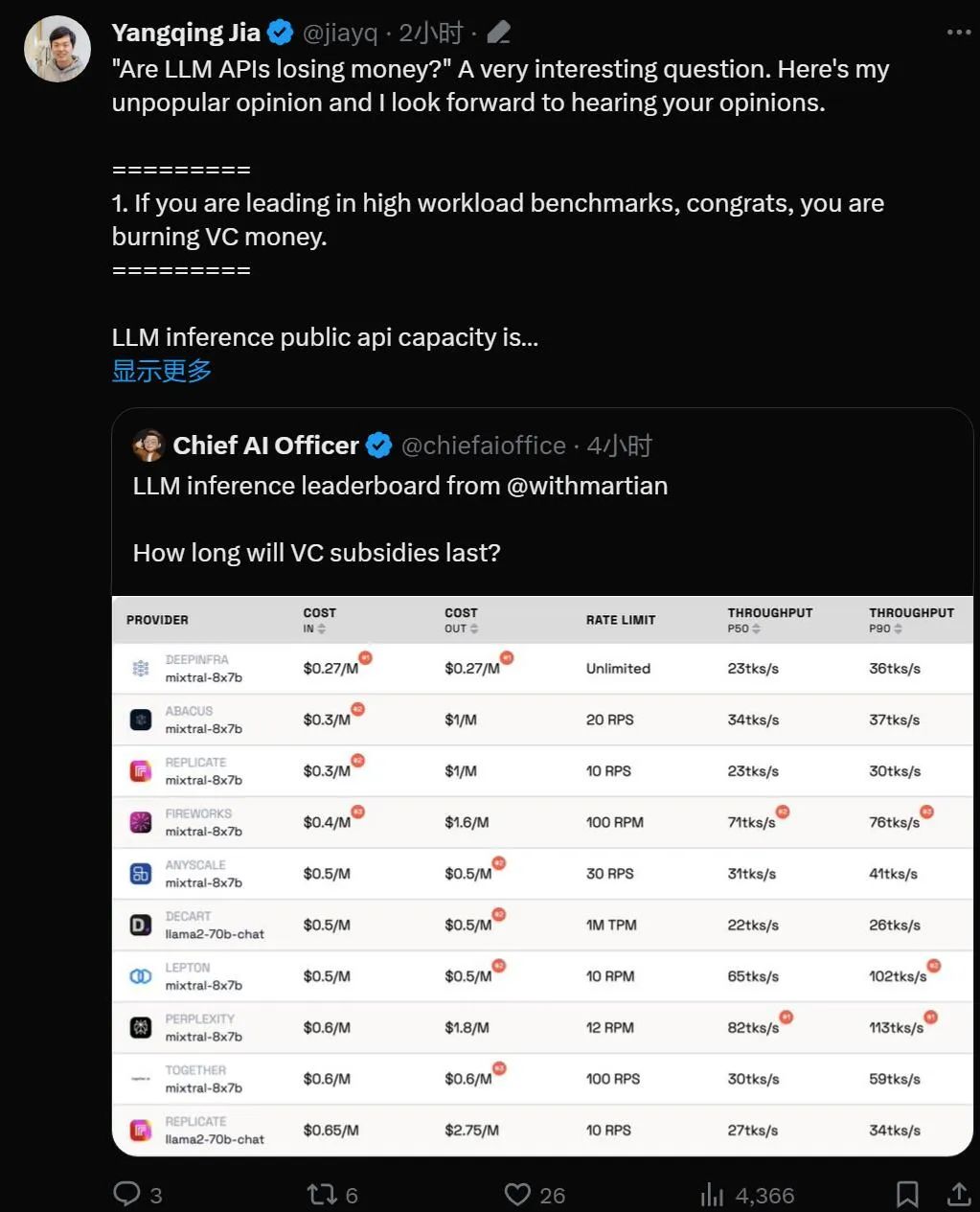
Lien de classement : https://leaderboard.withmartian.com/
Le classement des fournisseurs d'inférence LLM est un classement open source de produits d'inférence API pour les grands modèles. Il évalue le coût et les limites de débit. , débit et P50 et P90 TTFT pour les points de terminaison publics Mixtral-8x7B et Llama-2-70B-Chat de chaque fournisseur.
Bien qu'ils soient en concurrence les uns avec les autres, Martian a constaté que les services de grand modèle de chaque entreprise sont coût, il existe des différences significatives en termes de débit et de limitation de débit. Ces différences dépassent la différence de coût 5x, la différence de débit 6x et les différences de limite de débit encore plus importantes. Le choix de différentes API est essentiel pour obtenir les meilleures performances, même si cela fait partie des activités commerciales.
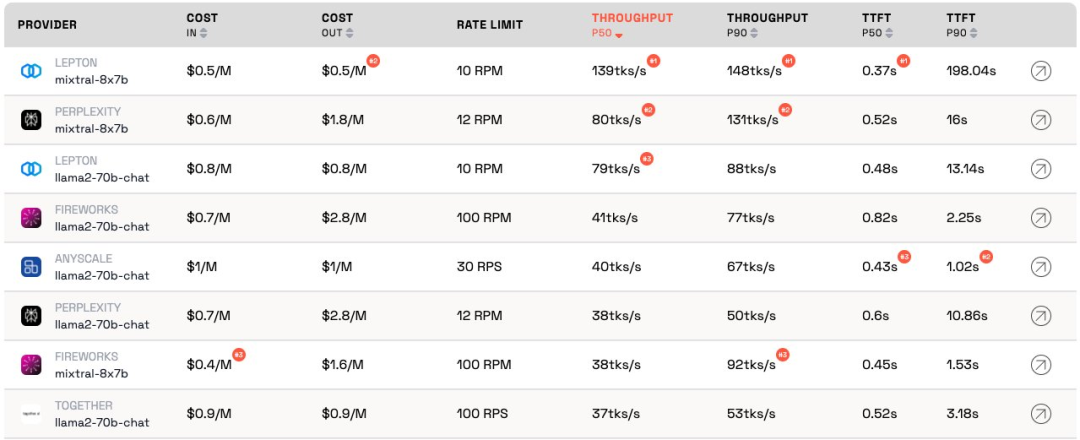
Selon le classement actuel, le service fourni par Anyscale a le meilleur débit sous une charge de service moyenne de Llama-2-70B. Pour les charges de service importantes, Together AI a obtenu de meilleurs résultats avec les débits P50 et P90 sur Llama-2-70B et Mixtral-8x7B.
De plus, LeptonAI de Jia Yangqing a montré le meilleur débit lors de la gestion de petites charges de tâches avec des entrées courtes et des signaux de sortie longs. Son débit P50 de 130 tks/s est le plus rapide parmi les modèles actuellement proposés par tous les fabricants du marché.
Jia Yangqing, un spécialiste bien connu de l'IA et fondateur de Lepton AI, a commenté immédiatement après la publication du classement. Voyons ce qu'il a dit.

Jia Yangqing a d'abord expliqué l'état actuel de l'industrie dans le domaine de l'intelligence artificielle, puis a affirmé l'importance des tests de référence et a enfin souligné que LeptonAI aidera les utilisateurs à trouver la meilleure stratégie de base en matière d'IA.
1. L'API du grand modèle « brûle de l'argent »
Si le modèle est en tête dans les benchmarks à charge de travail élevée, alors félicitations, il « brûle de l'argent ».
LLM Raisonner sur la capacité d'une API publique, c'est comme gérer un restaurant : vous avez un chef et vous devez estimer le trafic client. Embaucher un chef coûte de l’argent. La latence et le débit peuvent être compris comme « la rapidité avec laquelle vous pouvez cuisiner pour les clients ». Pour une entreprise raisonnable, il faut un nombre « raisonnable » de chefs. En d’autres termes, vous souhaitez disposer d’une capacité capable de gérer le trafic normal, et non des rafales soudaines de trafic qui se produisent en quelques secondes. Une augmentation du trafic signifie attendre ; sinon, le « cuisinier » n'aura rien à faire.
Dans le monde de l'intelligence artificielle, le GPU joue le rôle de « chef ». Les charges de base sont éclatantes. Sous de faibles charges de travail, la charge de base est intégrée au trafic normal et les mesures fournissent une représentation précise de la façon dont le service fonctionne sous les charges de travail actuelles.
Les scénarios de charge de service élevée sont intéressants car ils provoquent des interruptions. Le benchmark n'est exécuté que quelques fois par jour/semaine, ce n'est donc pas le trafic régulier auquel on devrait s'attendre. Imaginez que 100 personnes se rendent dans votre restaurant local pour vérifier à quelle vitesse le chef cuisine. Les résultats seraient excellents. Pour emprunter la terminologie de la physique quantique, c’est ce qu’on appelle « l’effet observateur ». Plus l’interférence est forte (c’est-à-dire plus la charge d’éclatement est importante), plus la précision est faible. En d’autres termes : si vous imposez une charge soudaine et élevée à un service et constatez que le service répond très rapidement, vous savez que le service a une grande capacité inutilisée. En tant qu’investisseur, lorsque vous voyez cette situation, vous devriez vous demander : cette façon de brûler de l’argent est-elle responsable ?
2. Le modèle atteindra à terme des performances similaires
Le domaine de l'intelligence artificielle adore les compétitions, ce qui est effectivement intéressant. Tout le monde converge rapidement vers la même solution, et Nvidia finit toujours par gagner grâce au GPU. C'est grâce à d'excellents projets open source, vLLM en est un excellent exemple. Cela signifie qu'en tant que fournisseur, si votre modèle fonctionne bien moins bien que les autres, vous pouvez facilement rattraper votre retard en recherchant des solutions open source et en appliquant une bonne ingénierie.
3. "En tant que client, je ne me soucie pas du coût du fournisseur"
Pour les créateurs d'applications d'IA, nous avons de la chance : il y a toujours des fournisseurs d'API prêts à "brûler de l'argent". L'industrie de l'IA brûle de l'argent pour gagner du trafic, et la prochaine étape consiste à se soucier des profits.
Le benchmarking est une tâche fastidieuse et sujette aux erreurs. Pour le meilleur ou pour le pire, il arrive généralement que les gagnants vous félicitent et que les perdants vous blâment. Ce fut le cas lors de la dernière série d’analyses comparatives des réseaux neuronaux convolutifs. Ce n’est pas une tâche facile, mais l’analyse comparative nous aidera à multiplier par 10 l’infrastructure de l’IA.
Basé sur le cadre d'intelligence artificielle et l'infrastructure cloud, LeptonAI aidera les utilisateurs à trouver la meilleure stratégie de base en matière d'IA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que dois-je faire si Win10 ne trouve pas les Airpods ?
- Vous ne trouvez pas le modèle pré-entraîné pour la parole chinoise ? Les versions chinoises Wav2vec 2.0 et HuBERT arrivent
- Explication détaillée du modèle de pré-formation d'apprentissage profond en Python
- Premier article : Un nouveau paradigme pour la formation de modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D