
Maison >Périphériques technologiques >IA >Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu
Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu

- PHPzavant
- 2024-01-25 11:36:191350parcourir
Titre original : Radocc : Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
Lien papier : https://arxiv.org/pdf/2312.11829.pdf
Affiliation de l'auteur : FNii, CUHK-Shenzhen SSE, CUHK-Shenzhen Huawei Noah's Ark Laboratory
Conférence : AAAI 2024

Idée de papier :
La prédiction d'occupation 3D est une tâche émergente qui vise à estimer l'état d'occupation et la sémantique de scènes 3D à l'aide d'images multi-vues. Cependant, la perception de scènes basée sur l’image se heurte à des défis importants pour obtenir des prédictions précises en raison du manque d’a priori géométriques. Cet article aborde ce problème en explorant la distillation des connaissances intermodales dans cette tâche, c'est-à-dire que nous utilisons un modèle multimodal plus puissant pour guider le modèle visuel pendant le processus de formation. En pratique, cet article observe que l'application directe de l'alignement des caractéristiques ou des logits, proposée et largement utilisée dans la perception à vol d'oiseau (BEV), ne donne pas de résultats satisfaisants. Pour surmonter ce problème, cet article présente RadOcc, un paradigme de distillation assistée par rendu pour la prédiction d'occupation 3D. En utilisant un rendu de volume différentiable, nous générons des cartes de profondeur et sémantiques en perspective et proposons deux nouveaux critères de cohérence entre la sortie rendue des modèles d'enseignant et d'élève. Plus précisément, la perte de cohérence en profondeur aligne les distributions de terminaison des rayons de rendu, tandis que la perte de cohérence sémantique imite la similarité intra-segment guidée par le modèle de base visuel (VLM). Les résultats expérimentaux sur l'ensemble de données nuScenes démontrent l'efficacité de la méthode proposée dans cet article pour améliorer diverses méthodes de prédiction d'occupation 3D. Par exemple, la méthode proposée dans cet article améliore la ligne de base de cet article de 2,2 % dans la métrique mIoU et atteint 2,2 %. dans le benchmark Occ3D 50%.
Principales contributions :
Cet article présente un paradigme de distillation assistée par rendu appelé RadOcc pour la prédiction d'occupation 3D. Il s'agit du premier article explorant la distillation intermodale des connaissances en 3D-OP, fournissant des informations précieuses sur l'application des techniques de distillation BEV existantes dans cette tâche.
Les auteurs proposent deux nouvelles contraintes de distillation, à savoir la profondeur de rendu et la cohérence sémantique (RDC et RSC). Ces contraintes améliorent efficacement le processus de transfert de connaissances en alignant les matrices de distribution de lumière et de corrélation guidées par le modèle de base de vision. La clé de cette approche consiste à utiliser des informations approfondies et sémantiques pour guider le processus de rendu, améliorant ainsi la qualité et la précision des résultats de rendu. En combinant ces deux contraintes, les chercheurs ont réalisé des améliorations significatives, apportant de nouvelles solutions pour le transfert de connaissances dans les tâches de vision.
Équipé de la méthode proposée, RadOcc affiche des performances de pointe en matière de prédiction d'occupation dense et clairsemée sur les benchmarks Occ3D et nuScenes. De plus, des expériences ont prouvé que la méthode de distillation proposée dans cet article peut améliorer efficacement les performances de plusieurs modèles de base.
Conception de réseau :
Cet article est le premier à étudier la distillation des connaissances intermodales pour la tâche de prédiction d'occupation 3D. Basé sur la méthode de transfert de connaissances utilisant la cohérence BEV ou logits dans le domaine de détection BEV, cet article étend ces techniques de distillation à la tâche de prédiction d'occupation 3D, visant à aligner les caractéristiques du voxel et les logits du voxel, comme le montre la figure 1 (a). Cependant, des expériences préliminaires montrent que ces techniques d'alignement sont confrontées à des défis importants dans les tâches 3D-OP, en particulier la première méthode qui introduit un transfert négatif. Ce défi peut provenir de la différence fondamentale entre la détection d'objets 3D et la prédiction d'occupation, qui, en tant que tâche de perception plus fine, nécessite de capturer des détails géométriques ainsi que des objets d'arrière-plan.
Pour relever les défis ci-dessus, cet article propose RadOcc, une nouvelle méthode de distillation de connaissances multimodales utilisant le rendu de volume différentiable. L'idée principale de RadOcc est d'aligner les résultats de rendu générés par le modèle d'enseignant et le modèle d'étudiant, comme le montre la figure 1(b). Plus précisément, cet article utilise les paramètres intrinsèques et extrinsèques de la caméra pour effectuer un rendu volumique des caractéristiques du voxel (Mildenhall et al. 2021), ce qui permet à cet article d'obtenir des cartes de profondeur et des cartes sémantiques correspondantes à partir de différents points de vue. Pour obtenir un meilleur alignement entre les sorties rendues, cet article introduit de nouvelles pertes de cohérence de profondeur de rendu (RDC) et de cohérence sémantique de rendu (RSC). D'une part, la perte RDC renforce la cohérence de la distribution des rayons, ce qui permet au modèle Student de capturer la structure sous-jacente des données. D'autre part, la perte RSC tire parti du modèle de base visuel (Kirillov et al. 2023) et utilise des segments pré-extraits pour la distillation par affinité. Cette norme permet aux modèles d'apprendre et de comparer les représentations sémantiques de différentes régions d'image, améliorant ainsi leur capacité à capturer des détails fins. En combinant les contraintes ci-dessus, la méthode proposée dans cet article exploite efficacement la distillation des connaissances intermodales, améliorant ainsi les performances et optimisant mieux le modèle étudiant. Cet article démontre l'efficacité de notre approche sur la prévision d'occupation dense et clairsemée, obtenant des résultats de pointe sur les deux tâches.
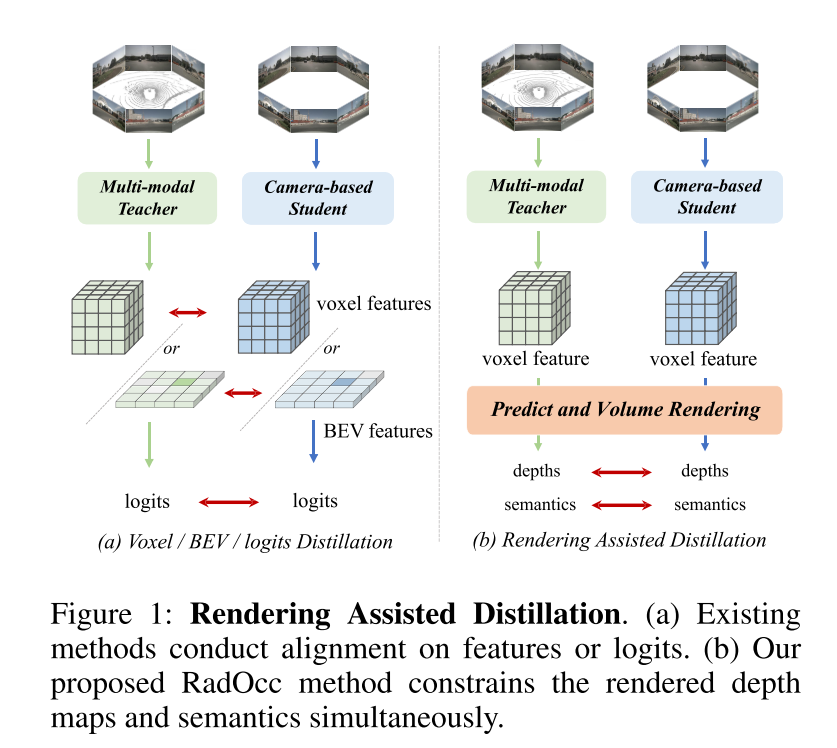
Figure 1 : Distillation assistée par rendu. (a) Les méthodes existantes alignent les caractéristiques ou les logits. (b) La méthode RadOcc proposée dans cet article contraint simultanément la carte de profondeur rendue et la sémantique. 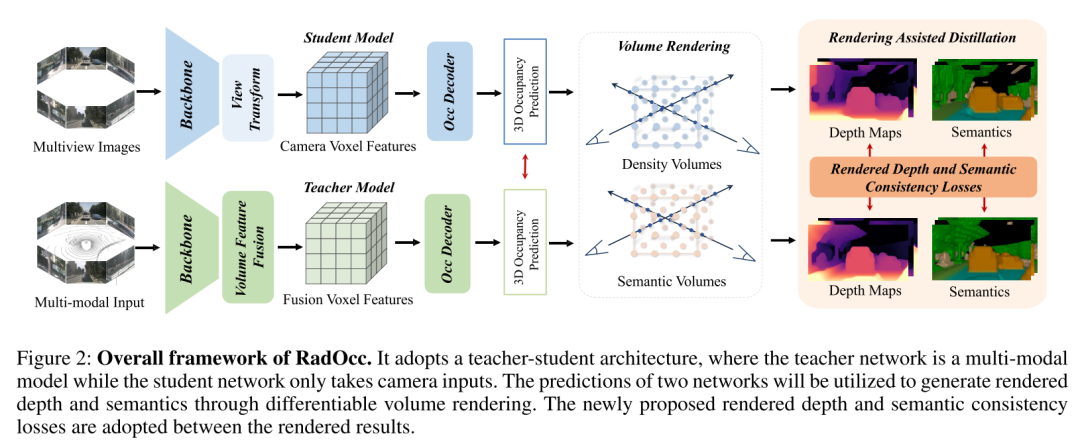 Figure 2 : Cadre global de RadOcc. Il adopte une architecture enseignant-élève, dans laquelle le réseau enseignant est un modèle multimodal et le réseau étudiant n'accepte que les entrées de caméra. Les prédictions des deux réseaux seront utilisées pour générer de la profondeur et de la sémantique du rendu grâce à un rendu de volume différentiable. Les pertes de profondeur de rendu et de cohérence sémantique nouvellement proposées sont adoptées entre les résultats de rendu.
Figure 2 : Cadre global de RadOcc. Il adopte une architecture enseignant-élève, dans laquelle le réseau enseignant est un modèle multimodal et le réseau étudiant n'accepte que les entrées de caméra. Les prédictions des deux réseaux seront utilisées pour générer de la profondeur et de la sémantique du rendu grâce à un rendu de volume différentiable. Les pertes de profondeur de rendu et de cohérence sémantique nouvellement proposées sont adoptées entre les résultats de rendu.
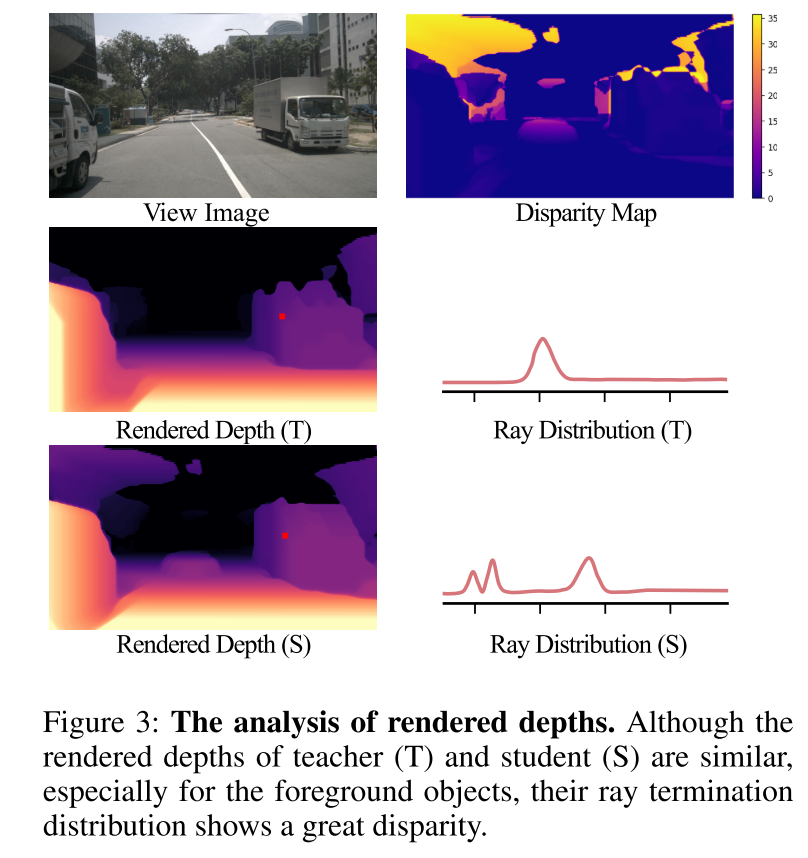
Figure 3 : Analyse de la profondeur du rendu. Bien que l'enseignant (T) et l'élève (S) aient des profondeurs de rendu similaires, en particulier pour les objets du premier plan, leurs distributions de terminaison lumineuse présentent de grandes différences.
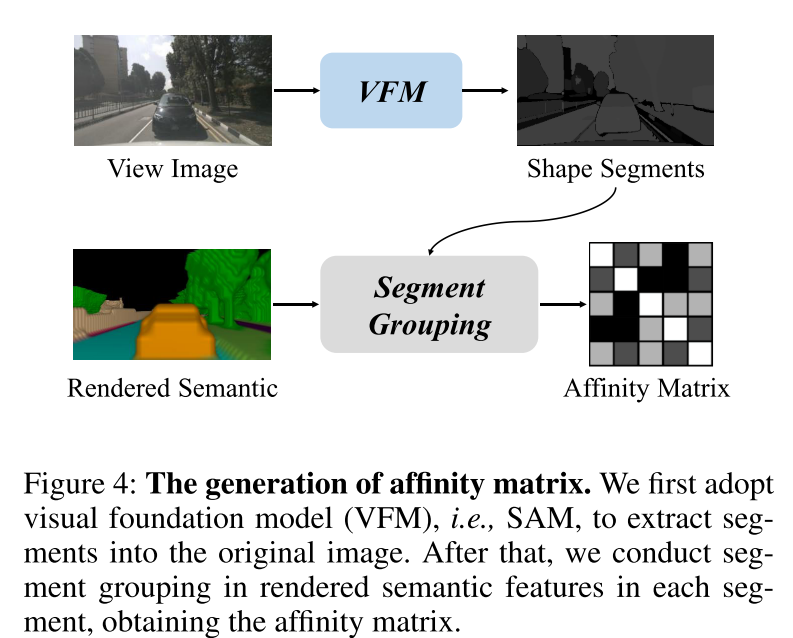
Figure 4 : Génération de matrice d'affinité. Cet article utilise d'abord le Vision Foundation Model (VFM), à savoir SAM, pour extraire des segments dans l'image originale. Ensuite, cet article effectue une agrégation de segments sur les caractéristiques sémantiques rendues dans chaque segment pour obtenir la matrice d'affinité.
Résultats expérimentaux :
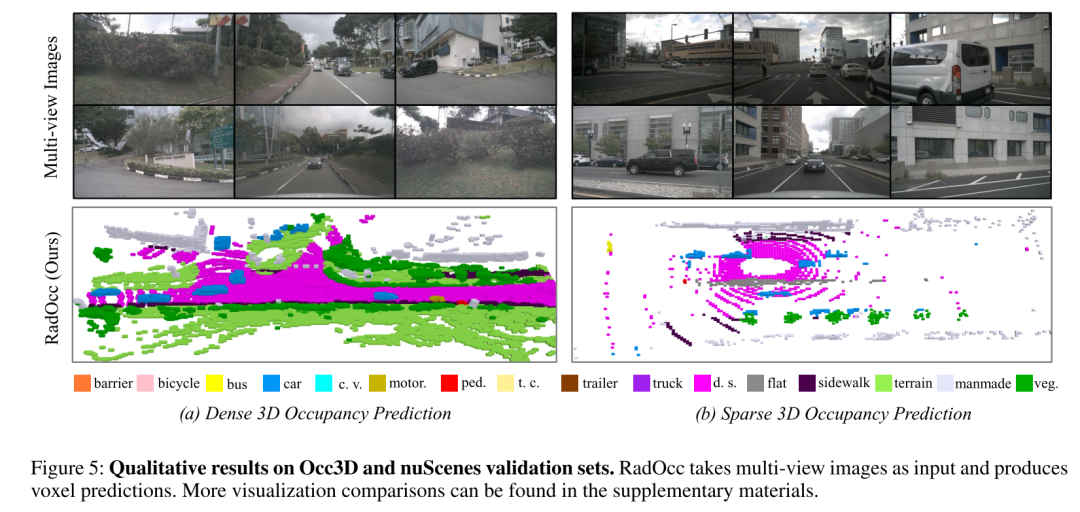

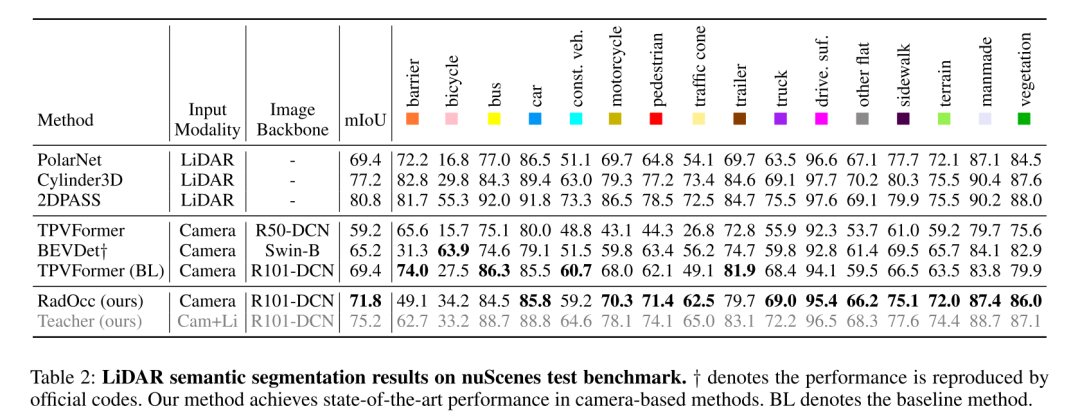
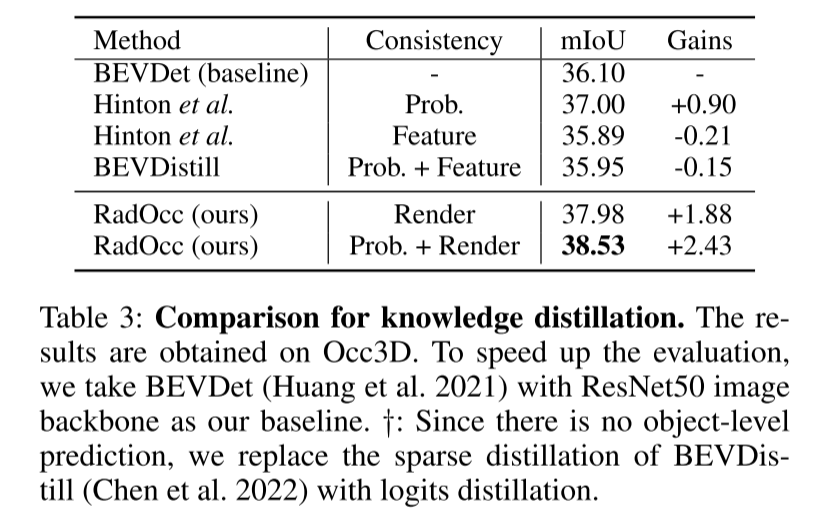

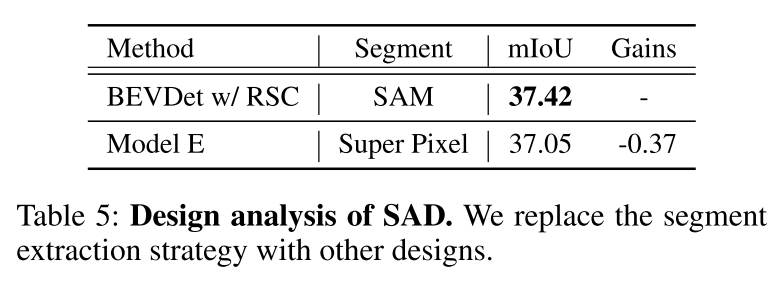
Résumé :
Cet article propose RadOcc , un roman 3D de distillation de connaissances multimodales pour le paradigme de prédiction d'occupation. Il utilise un modèle d'enseignant multimodal pour fournir des conseils géométriques et sémantiques au modèle visuel d'élève grâce à un rendu de volume différenciable. En outre, cet article propose deux nouveaux critères de cohérence, la perte de cohérence en profondeur et la perte de cohérence sémantique, pour aligner la distribution des rayons et la matrice d'affinité entre les modèles d'enseignant et d'élève. Des expériences approfondies sur les ensembles de données Occ3D et nuScenes montrent que RadOcc peut améliorer considérablement les performances de diverses méthodes de prédiction d'occupation 3D. Notre méthode obtient des résultats de pointe sur le benchmark du défi Occ3D et surpasse considérablement les méthodes publiées existantes. Nous pensons que notre travail ouvre de nouvelles possibilités d’apprentissage multimodal dans la compréhension des scènes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Partagez en utilisant HTML5 pour réaliser un sapin de Noël réaliste en 3D
- Effets spéciaux d'effet flop 3D recommandés (collection)
- Apprentissage universel en quelques étapes : une solution pour un large éventail de tâches de prédiction denses
- Comment utiliser les bibliothèques d'apprentissage automatique en Java pour réaliser une analyse et une prédiction intelligentes des données ?