
Maison >Périphériques technologiques >IA >Apprentissage universel en quelques étapes : une solution pour un large éventail de tâches de prédiction denses
Apprentissage universel en quelques étapes : une solution pour un large éventail de tâches de prédiction denses

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-26 22:46:091731parcourir
ICLR (International Conference on Learning Representations) est reconnue comme l'une des conférences académiques internationales les plus influentes sur l'apprentissage automatique.
Lors de la conférence ICLR 2023 de cette année, Microsoft Research Asia a publié les derniers résultats de recherche dans les domaines de la robustesse de l'apprentissage automatique, de l'intelligence artificielle responsable et d'autres domaines.
Parmi eux, les résultats de la coopération en matière de recherche scientifique entre Microsoft Research Asia et le Korea Advanced Institute of Science and Technology (KAIST) dans le cadre de la coopération académique des deux parties ont reçu le prix ICLR 2023 Exceptionnel pour leur clarté, leur perspicacité, leur créativité et leur impact durable potentiel.

Adresse papier : https://arxiv.org/abs/2303.14969
VTM : Le premier apprenant sur quelques échantillons adapté à toutes les tâches de prédiction dense
Les tâches de prédiction dense sont la vision par ordinateur. classe importante de tâches dans le domaine, telles que la segmentation sémantique, l'estimation de la profondeur, la détection des contours et la détection des points clés, etc. Pour de telles tâches, l’annotation manuelle des étiquettes au niveau des pixels se heurte à des coûts prohibitifs. Par conséquent, comment apprendre à partir d’une petite quantité de données étiquetées et faire des prédictions précises, c’est-à-dire l’apprentissage sur de petits échantillons, est un sujet très préoccupant dans ce domaine. Ces dernières années, la recherche sur l’apprentissage par petits échantillons a continué de faire des percées, en particulier certaines méthodes basées sur le méta-apprentissage et l’apprentissage contradictoire, qui ont attiré beaucoup d’attention et ont été bien accueillies par la communauté universitaire.
Cependant, les méthodes d'apprentissage de petits échantillons de vision par ordinateur existantes sont généralement destinées à un type spécifique de tâches, telles que les tâches de classification ou les tâches de segmentation sémantique. Ils exploitent souvent des connaissances antérieures et des hypothèses spécifiques à ces tâches dans la conception de l'architecture du modèle et du processus de formation, et ne conviennent donc pas à une généralisation à des tâches de prédiction denses arbitraires. Les chercheurs de Microsoft Research Asia souhaitaient explorer une question centrale : existe-t-il un apprenant généraliste capable d'apprendre des tâches de prédiction denses pour des segments arbitraires d'images invisibles à partir d'un petit nombre d'images étiquetées.
Le but d'une tâche de prédiction dense est d'apprendre un mappage entre les images d'entrée et les étiquettes annotées en pixels, qui peuvent être définies comme :
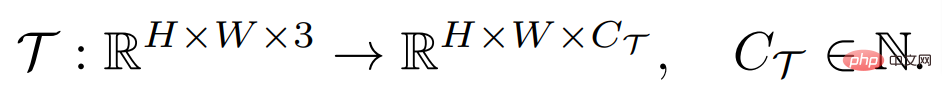
où H et W sont la hauteur et la largeur de l'image respectivement, l'image d'entrée contient généralement trois canaux RVB et C_Τ représente le nombre de canaux de sortie. Différentes tâches de prédiction dense peuvent impliquer différents numéros de canal de sortie et attributs de canal. Par exemple, la sortie d'une tâche de segmentation sémantique est binaire multicanal, tandis que la sortie d'une tâche d'estimation de profondeur est une valeur continue à canal unique. Un apprenant F général à quelques échantillons, pour une telle tâche Τ, étant donné un petit nombre d'ensembles de supports d'échantillons étiquetés S_Τ (y compris N groupes d'échantillons X^i et d'étiquettes Y^i), peut apprendre de manière invisible en interrogeant l'architecture de l'image. Cette structure est capable de gérer des tâches de prédiction arbitrairement denses et partage les paramètres requis pour la plupart des tâches afin d'obtenir des connaissances généralisables, permettant l'apprentissage de toute tâche invisible avec un petit nombre d'échantillons.
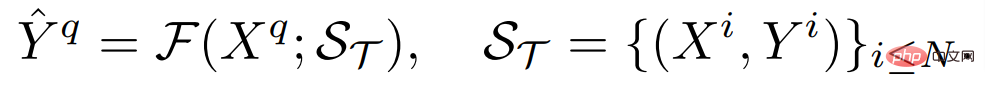 Deuxièmement, l'apprenant doit ajuster de manière flexible son mécanisme de prédiction pour résoudre des tâches invisibles avec diverses sémantiques tout en étant suffisamment efficace pour éviter le surapprentissage.
Deuxièmement, l'apprenant doit ajuster de manière flexible son mécanisme de prédiction pour résoudre des tâches invisibles avec diverses sémantiques tout en étant suffisamment efficace pour éviter le surapprentissage.
Par conséquent, des chercheurs de Microsoft Research Asia ont conçu et mis en œuvre le jeton visuel d'apprenant sur petit échantillon correspondant à VTM (Visual Token Matching), qui peut être utilisé pour toute tâche de prédiction dense. Il s'agit du
- le premier apprenant sur petits échantillons
- adapté à toutes les tâches de prédiction intensives ouvre une nouvelle façon de penser pour le traitement des tâches de prédiction intensives et des méthodes d'apprentissage sur petits échantillons en vision par ordinateur. Ce travail a remporté le ICLR 2023 Outstanding Paper Award
- .
La conception de VTM s'inspire de l'analogie avec le processus de pensée humaine : étant donné un petit nombre d'exemples d'une nouvelle tâche, les humains peuvent rapidement attribuer des sorties similaires à des entrées similaires en fonction de la similitude entre les exemples, et peuvent également attribuer des sorties similaires. à des entrées similaires en fonction de la similitude entre les exemples. Le contexte varie à quels niveaux l'entrée et la sortie sont similaires. Les chercheurs ont mis en œuvre un processus d’analogie pour la prédiction dense utilisant une correspondance non paramétrique basée sur les niveaux de correctifs. Grâce à la formation, le modèle est inspiré pour capturer les similitudes dans les patchs d'image.
Étant donné un petit nombre d'exemples étiquetés pour une nouvelle tâche, VTM ajustera d'abord sa compréhension de la similarité en fonction de l'exemple donné et de l'étiquette de l'exemple, en verrouillant les correctifs d'image des correctifs d'image d'exemple qui sont similaires à l'image. patch à prédire, prédisez les étiquettes des patchs d'image invisibles en combinant leurs étiquettes.

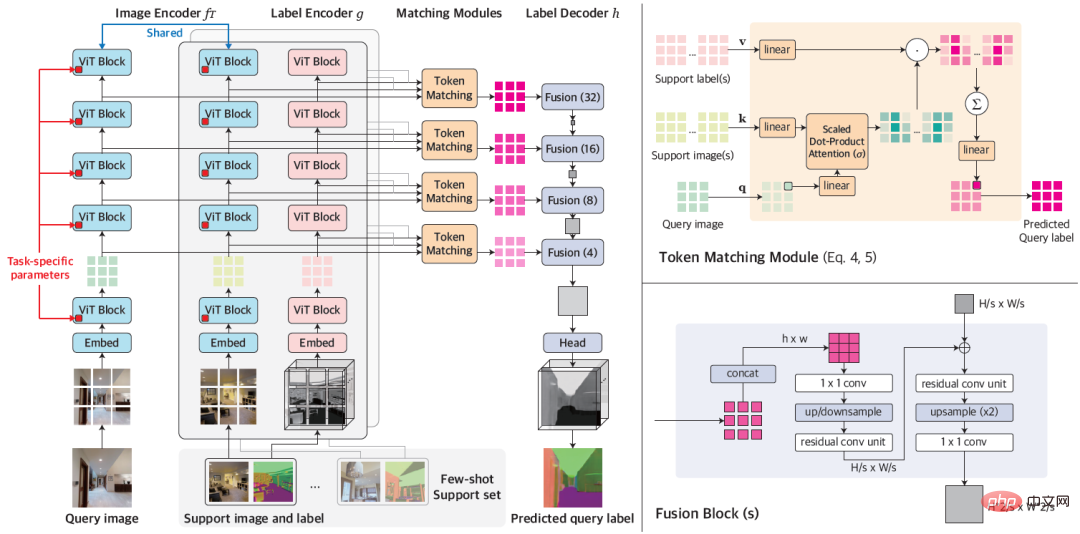
Figure 1 : Architecture globale de VTM
VTM adopte une architecture d'encodeur-décodeur en couches pour obtenir une correspondance non paramétrique basée sur des blocs d'images à plusieurs niveaux. Il se compose principalement de quatre modules, à savoir l'encodeur d'image f_Τ, l'encodeur d'étiquette g, le module d'appariement et le décodeur d'étiquette h. Étant donné une image de requête et un ensemble de supports, l'encodeur d'image extrait d'abord indépendamment les représentations au niveau du patch d'image pour chaque requête et image de support. L'encodeur de balises extraira de la même manière chaque balise prenant en charge les balises. Compte tenu des étiquettes à chaque niveau, le module de correspondance effectue une correspondance non paramétrique et le décodeur d'étiquettes déduit finalement l'étiquette de l'image de requête.
L'essence du VTM est une méthode de méta-apprentissage. Sa formation se compose de plusieurs épisodes, chaque épisode simule un petit échantillon de problème d'apprentissage. La formation VTM utilise l'ensemble de données de méta-formation D_train, qui contient une variété d'exemples étiquetés de tâches de prédiction dense. Chaque épisode de formation simule un scénario d'apprentissage en quelques étapes pour une tâche spécifique T_train dans l'ensemble de données, dans le but de produire l'étiquette correcte pour l'image de requête étant donné l'ensemble de support. Grâce à l'expérience d'apprentissage à partir de plusieurs petits échantillons, le modèle peut acquérir des connaissances générales pour s'adapter à de nouvelles tâches de manière rapide et flexible. Au moment du test, le modèle doit effectuer un apprentissage en quelques étapes sur toute tâche T_test qui n'est pas incluse dans l'ensemble de données d'entraînement D_train.
Lorsqu'il s'agit de tâches arbitraires, étant donné que la dimension de sortie C_Τ de chaque tâche de méta-formation et de test est différente, cela devient un énorme défi de concevoir des paramètres de modèle général unifiés pour toutes les tâches. Pour fournir une solution simple et générale, les chercheurs ont transformé la tâche en sous-tâches C_Τ à canal unique, ont appris chaque canal séparément et ont modélisé chaque sous-tâche indépendamment à l'aide d'un modèle F partagé.
Afin de tester VTM, les chercheurs ont également spécialement construit une variante de l'ensemble de données Taskonomy pour simuler l'apprentissage de petits échantillons de tâches de prédiction denses et invisibles. Taskonomy contient diverses images intérieures annotées, à partir desquelles les chercheurs ont sélectionné dix tâches de prédiction denses avec différentes sémantiques et dimensions de sortie et les ont divisées en cinq parties pour une validation croisée. Dans chaque division, deux tâches sont utilisées pour l'évaluation à petite échelle (T_test) et les huit tâches restantes sont utilisées pour la formation (T_train). Les chercheurs ont soigneusement construit les partitions afin que les tâches de formation et de test soient suffisamment différentes les unes des autres, par exemple en regroupant les tâches périphériques (TE, OE) en tâches de test pour permettre l'évaluation des tâches avec une nouvelle sémantique.
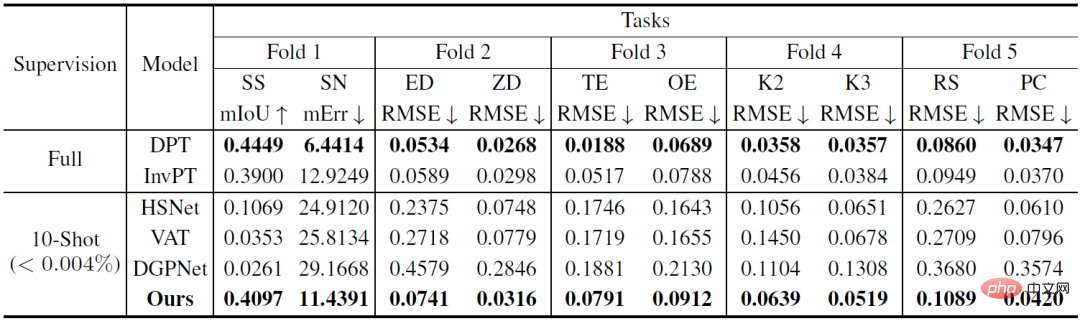
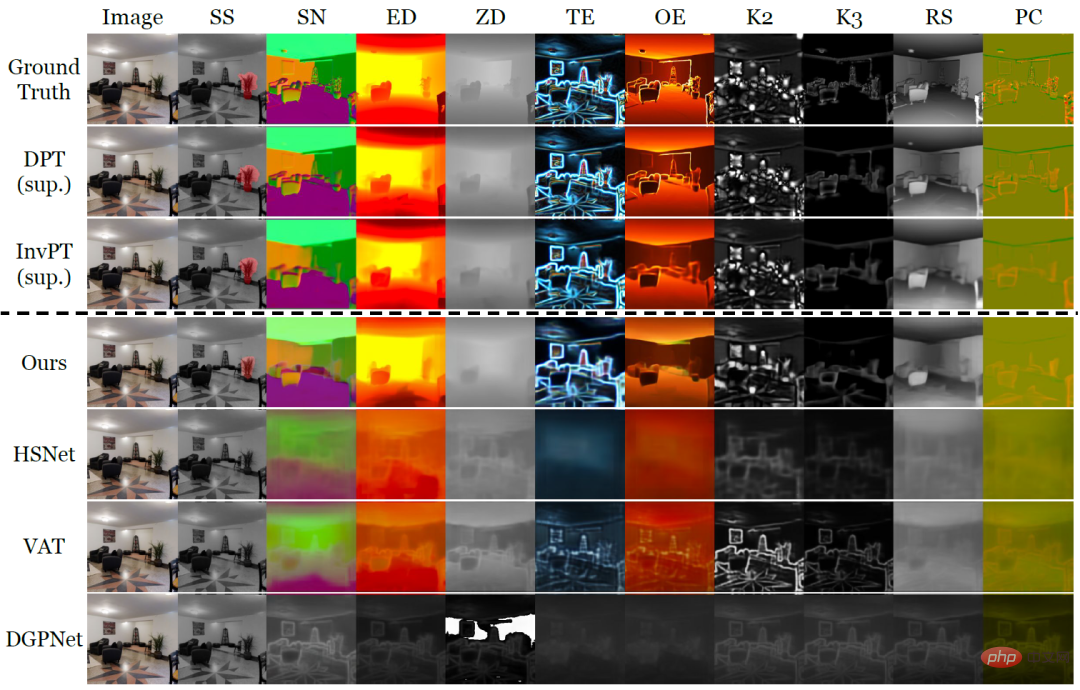
Tableau 1 : Comparaison quantitative sur l'ensemble de données Taskonomy (ligne de base de quelques tirs). Après des tâches de formation provenant d'autres partitions, un apprentissage en 10 coups a été effectué sur la tâche de partition à tester, où des lignes de base entièrement supervisées ont été formées. et évalué sur chaque pli (DPT) ou tous les plis (InvPT)
Le Tableau 1 et la Figure 2 démontrent quantitativement et qualitativement les performances d'apprentissage sur petit échantillon de VTM et des deux types de modèles de base sur dix tâches de prédiction denses respectivement. Parmi elles, DPT et InvPT sont les deux méthodes d'apprentissage supervisé les plus avancées. DPT peut être formé indépendamment pour chaque tâche, tandis qu'InvPT peut former conjointement toutes les tâches. Puisqu'il n'existait pas de méthode dédiée aux petits échantillons développée pour les tâches générales de prédiction dense avant VTM, les chercheurs ont comparé VTM avec trois méthodes de pointe de segmentation sur petits échantillons, à savoir DGPNet, HSNet et TVA, et les ont étendues pour gérer A. espace d'étiquette général pour les tâches de prédiction denses. VTM n'a pas eu accès à la tâche de test T_test pendant la formation et n'a utilisé qu'un petit nombre (10) d'images étiquetées au moment du test, mais il a obtenu les meilleurs résultats parmi tous les modèles de base à petite échelle et a bien performé sur de nombreuses tâches par rapport à la pleine compétitivité. modèles de base supervisés.
Figure 2 : Comparaison qualitative de méthodes d'apprentissage en quelques coups sur une nouvelle tâche avec seulement dix images étiquetées sur les dix tâches de prédiction dense de Taskonomy. Là où d’autres méthodes ont échoué, VTM a réussi à apprendre toutes les nouvelles tâches avec une sémantique différente et des représentations d’étiquettes différentes.
Dans la figure 2, au-dessus de la ligne pointillée se trouvent les véritables étiquettes et les deux méthodes d'apprentissage supervisé DPT et InvPT respectivement. Sous la ligne pointillée se trouve la méthode d’apprentissage sur petit échantillon. Notamment, d’autres bases de référence sur petit échantillon ont souffert d’un sous-apprentissage catastrophique sur les nouvelles tâches, tandis que VTM a réussi à apprendre toutes les tâches. Les expériences démontrent que VTM peut désormais fonctionner de manière tout aussi compétitive avec des références entièrement supervisées sur un très petit nombre d'exemples étiquetés (
Pour résumer, bien que l'idée sous-jacente de VTM soit très simple, elle possède une architecture unifiée qui peut être utilisée pour des tâches de prédiction arbitrairement denses, puisque l'algorithme de correspondance englobe essentiellement toutes les tâches et structures d'étiquettes (par exemple, continu ou discret). De plus, VTM n'introduit qu'un petit nombre de paramètres spécifiques à la tâche pour obtenir une résistance et une flexibilité au surajustement. À l’avenir, les chercheurs espèrent explorer davantage l’impact du type de tâche, du volume et de la distribution des données sur les performances de généralisation du modèle au cours du processus de pré-formation, nous aidant ainsi à créer un apprenant véritablement universel sur un petit échantillon.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI