
Maison >Périphériques technologiques >IA >Kai-Fu Lee a participé à Zero One Wish, qui a publié un grand modèle multimodal open source de classe mondiale.
Kai-Fu Lee a participé à Zero One Wish, qui a publié un grand modèle multimodal open source de classe mondiale.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-25 11:09:051165parcourir
En tête des deux listes faisant autorité en chinois et en anglais, Kai-Fu Lee a remis la grand modèle multimodalfeuille de réponses !
Cela fait moins de trois mois depuis la sortie de ses premiers grands modèles open source Yi-34B et Yi-6B.

Le modèle s'appelle Yi Vision Language (Yi-VL), et il est désormais officiellement open source à l'échelle mondiale.
Les deux appartiennent à la série Yi et ont également deux versions :
Yi-VL-34B et Yi-VL-6B.
Jetons d'abord un coup d'œil à deux exemples pour découvrir les performances de Yi-VL dans divers scénarios tels que des dialogues graphiques :

Yi-VL a fait une analyse détaillée de l'ensemble de l'image, expliquant non seulement le contenu et même le "plafond" sont pris en charge.
En chinois, Yi-VL peut également exprimer clairement et précisément :

De plus, les résultats officiels des tests ont également été donnés.
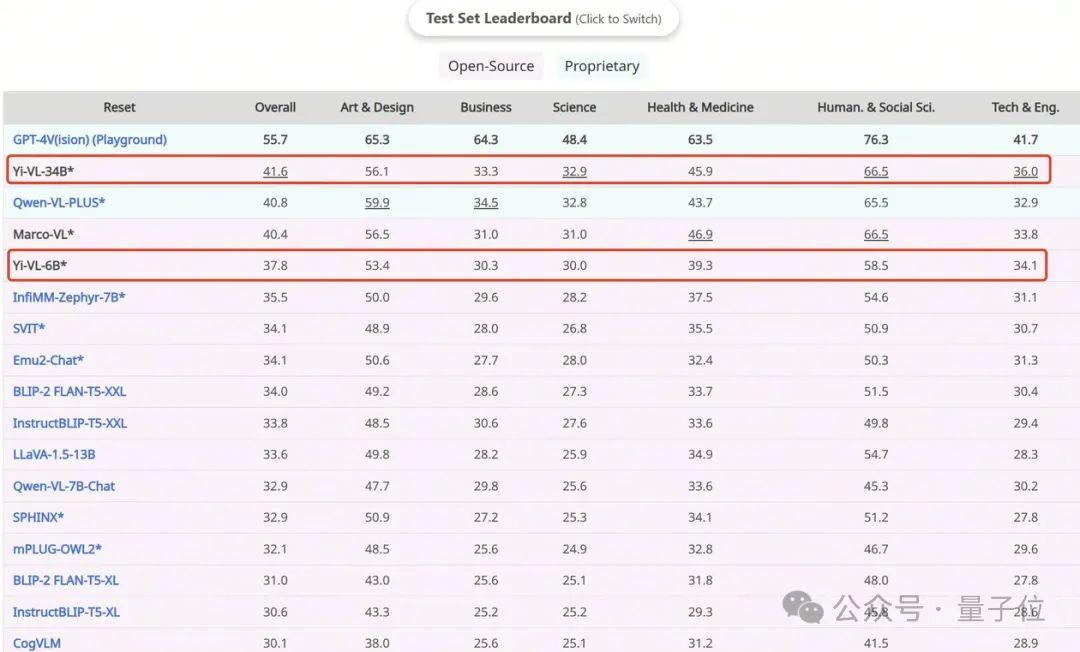
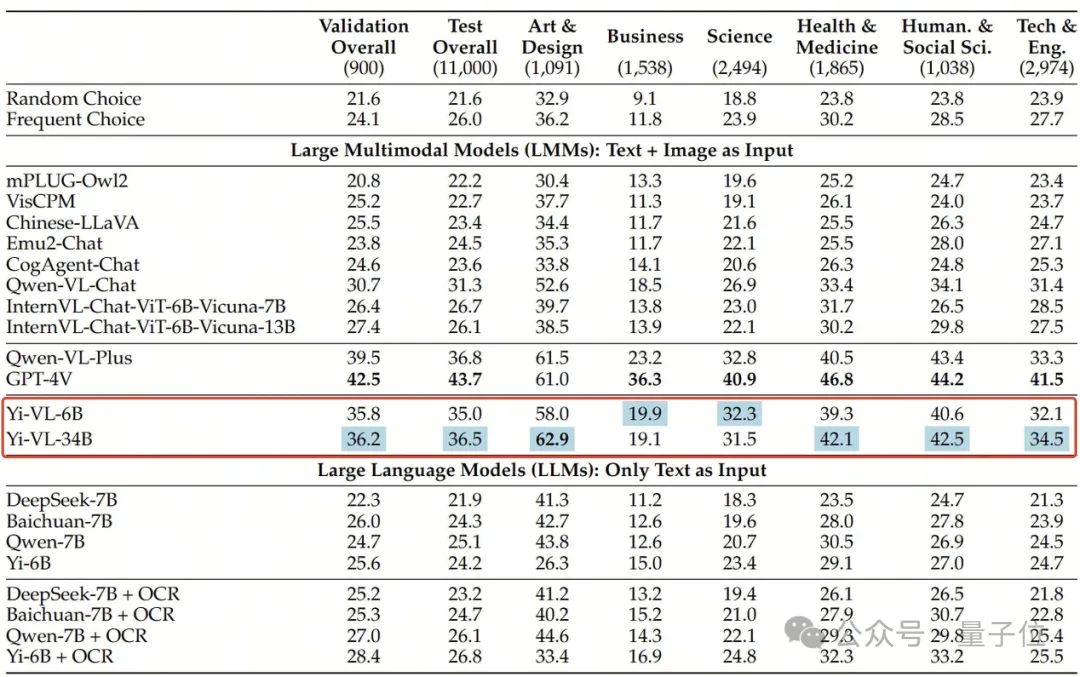
Yi-VL-34B a une précision de 41,6% sur l'ensemble de données anglais MMMU, juste derrière GPT-4V avec une précision de 55,7%, surpassant une série de grands modèles multimodaux.
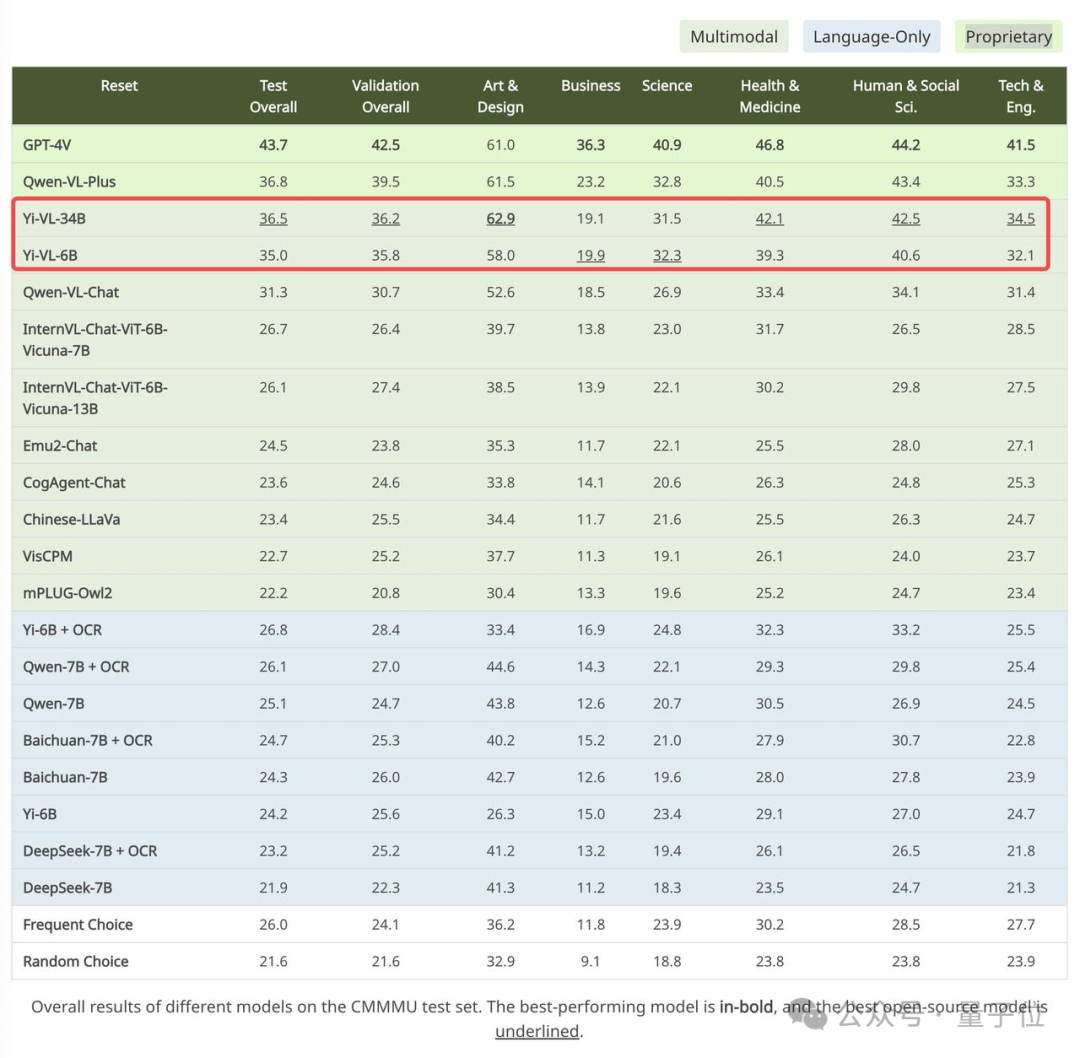
Sur l'ensemble de données chinois CMMMU, la précision du Yi-VL-34B est de 36,5%, ce qui est en avance sur les modèles multimodaux open source de pointe actuels.
À quoi ressemble Yi-VL ?
Yi-VL est développé sur la base du modèle de langage Yi. Vous pouvez voir les puissantes capacités de compréhension de texte basées sur le modèle de langage Yi. Il vous suffit d'aligner les images pour obtenir un bon modèle de langage visuel multimodal. le modèle Yi-VL, l'un des principaux points forts.
Dans conception d'architecture, le modèle Yi-VL est basé sur l'architecture open source LLaVA et contient trois modules principaux :
- Vision Transformer (appelé ViT) pour l'encodage d'images, en utilisant l'open source OpenClip ViT -Modèle H/14 Initialisez les paramètres entraînables et apprenez à extraire des caractéristiques de paires « image-texte » à grande échelle, donnant au modèle la capacité de traiter et de comprendre les images.
- Le module Projection offre la possibilité d'aligner spatialement les caractéristiques de l'image et les caractéristiques du texte sur le modèle. Ce module est constitué d'un perceptron multicouche (MLP) contenant des normalisations de couches . Cette conception permet au modèle de fusionner et de traiter plus efficacement les informations visuelles et textuelles, améliorant ainsi la précision de la compréhension et de la génération multimodales. L'introduction des grands modèles linguistiques Yi-34B-Chat et Yi-6B-Chat fournit à Yi-VL de puissantes capacités de compréhension et de génération du langage. Cette partie du modèle utilise une technologie avancée de traitement du langage naturel pour aider Yi-VL à comprendre en profondeur les structures linguistiques complexes et à générer une sortie de texte cohérente et pertinente.
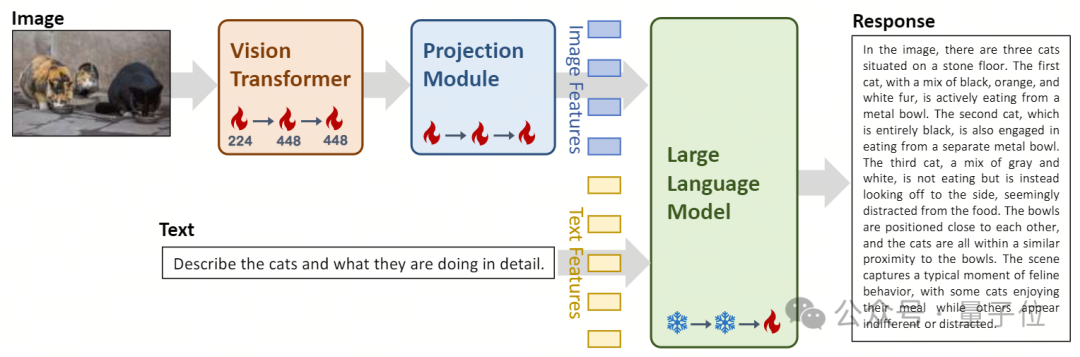 △Illustration : Conception de l'architecture du modèle Yi-VL et aperçu du processus de la méthode de formation
△Illustration : Conception de l'architecture du modèle Yi-VL et aperçu du processus de la méthode de formation
Dans la
méthode de formation, le processus de formation du modèle Yi-VL est divisé en trois étapes, visant à améliorer globalement le visuel et qualité visuelle du modèle Capacité de traitement du langage. Dans la première étape, un ensemble de données couplées « image-texte » de 100 millions est utilisé pour entraîner les modules ViT et Projection.
À ce stade, la résolution de l'image est réglée sur 224x224 pour améliorer les capacités d'acquisition de connaissances de ViT dans des architectures spécifiques tout en obtenant un alignement efficace avec de grands modèles de langage.
Dans la deuxième étape, la résolution de l'image de ViT est augmentée à 448x448, ce qui permet au modèle de mieux reconnaître les détails visuels complexes. Environ 25 millions de paires « image-texte » sont utilisées à cette étape.
Dans la troisième étape, les paramètres de l'ensemble du modèle sont ouverts à la formation, dans le but d'améliorer les performances du modèle dans l'interaction de chat multimodale. Les données de formation couvrent diverses sources de données, avec un total d'environ 1 million de paires « image-texte », garantissant l'étendue et l'équilibre des données.
L'équipe technique de Zero-One Everything a également vérifié qu'elle pouvait rapidement entraîner une compréhension efficace des images et des graphiques fluides en s'appuyant sur les puissantes capacités de compréhension du langage et de génération du modèle de langage Yi en utilisant d'autres méthodes de formation multimodales telles que BLIP, Flamingo, EVA, etc. Un modèle graphique-texte multimodal pour le dialogue textuel.
Les modèles de la série Yi peuvent être utilisés comme modèles de langage de base pour les modèles multimodaux, offrant ainsi une nouvelle option à la communauté open source. Dans le même temps, l'équipe multimodale zéro-un explore la pré-formation multimodale à partir de zéro pour approcher et dépasser le GPT-4V plus rapidement et atteindre le premier niveau d'échelon mondial.
Actuellement, le modèle Yi-VL a été ouvert au public sur des plateformes telles que Hugging Face et ModelScope. Les utilisateurs peuvent personnellement expérimenter les performances de ce modèle dans divers scénarios tels que des dialogues graphiques et textuels.
Au-delà d'une série de grands modèles multimodaux
Dans le nouveau benchmark multimodal MMMU, les deux versions Yi-VL-34B et Yi-VL-6B ont bien fonctionné.
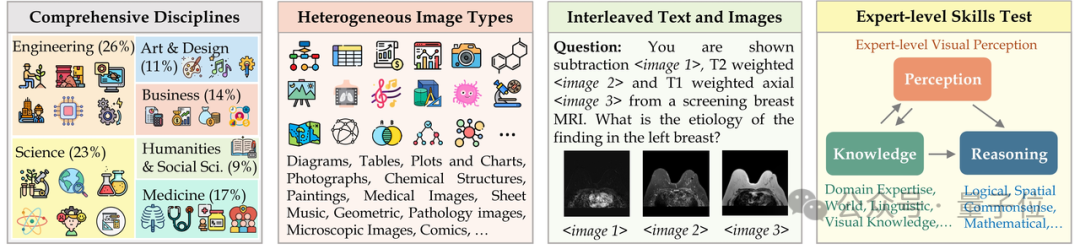
MMMU (Nom complet : Massive Multi-discipline Multi-modal Understanding & Reasoning)L'ensemble de données contient 11 500 sujets issus de six disciplines principales (art et design, commerce, sciences, santé et médecine, sciences humaines et sociales, et technologie et ingénierie) des problèmes impliquant des types d'images très hétérogènes et des informations texte-image entrelacées imposent des exigences extrêmement élevées aux capacités avancées de perception et de raisonnement du modèle.
Et Yi-VL-34B a surpassé avec succès une série de grands modèles multimodaux avec une précision de 41,6% sur cet ensemble de test, juste derrière le GPT-4V(55,7%), montrant une puissante capacité à comprendre et appliquer des connaissances interdisciplinaires.
De même, sur l'ensemble de données CMMMU créé pour la scène chinoise, le modèle Yi-VL montre l'avantage unique de « mieux comprendre les Chinois ».
CMMMU contient environ 12 000 questions multimodales chinoises dérivées d'examens universitaires, de quiz et de manuels.

Parmi eux, GPT-4V a une précision de 43,7 % sur cet ensemble de tests, suivi de Yi-VL-34B avec une précision de 36,5 %, ce qui est en avance sur l'actuel multimodal open source de pointe. des modèles.
Adresse du projet :
[1]https://huggingface.co/01-ai
[2]https://www.modelscope.cn/organization/01ai
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les propriétés du modèle de boîte en CSS ? Introduction aux propriétés liées au modèle de boîte CSS
- La formation ViT et MAE réduit la quantité de calcul de moitié ! Sea et l'Université de Pékin ont proposé conjointement l'optimiseur efficace Adan, qui peut être utilisé pour les modèles profonds
- Volcano Engine aide Shenzhen Technology à lancer le premier modèle de pré-entraînement moléculaire 3D du secteur, Uni-Mol
- Utiliser de grands modèles pour créer un nouveau paradigme pour la formation aux résumés de texte
- Zoom garantit la transparence dans l'utilisation des données et garantit que la formation en IA est soumise à l'autorisation de l'utilisateur